8.1 Attention 구조
Attention을 이용하여 seq2seq가 가진 문제점을 해결할 수 있다.
8.1.1 seq2seq의 문제점
seq2seq
한계점 : Encoder에서 context vector (= 고정 길이 벡터)를 출력한다.
입력 문장의 길이에 관계없이 항상 같은 길이의 벡터로 변환한다. 긴문장일 경우, 필요한 정보가 벡터에 다 담기지 못한다.
8.1.2 Encoder 개선
개선점 : Encoder의 출력 벡터는 입력 문장의 길이에 따라 바뀌어야한다.
seq2seq : LSTM 계층의 마지막 hidden state의 벡터만을 Decoder에 전달한다.
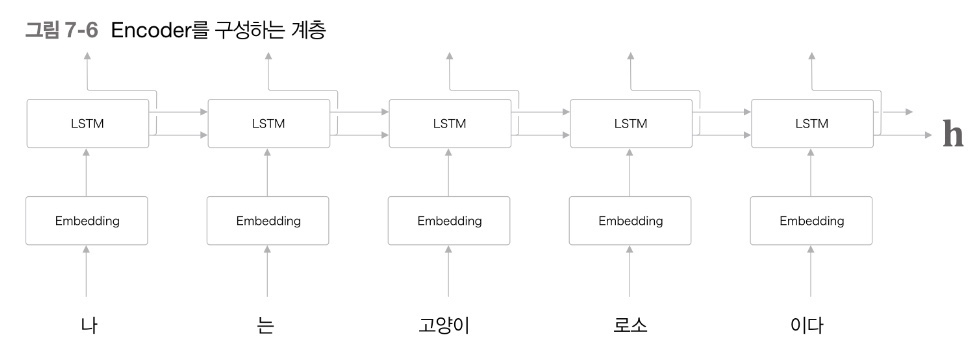
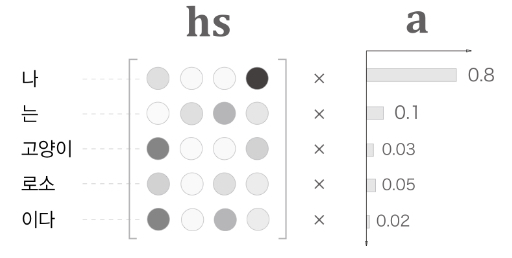
Attention : LSTM 계층의 모든 hidden state의 벡터를 Decoder에 전달한다.
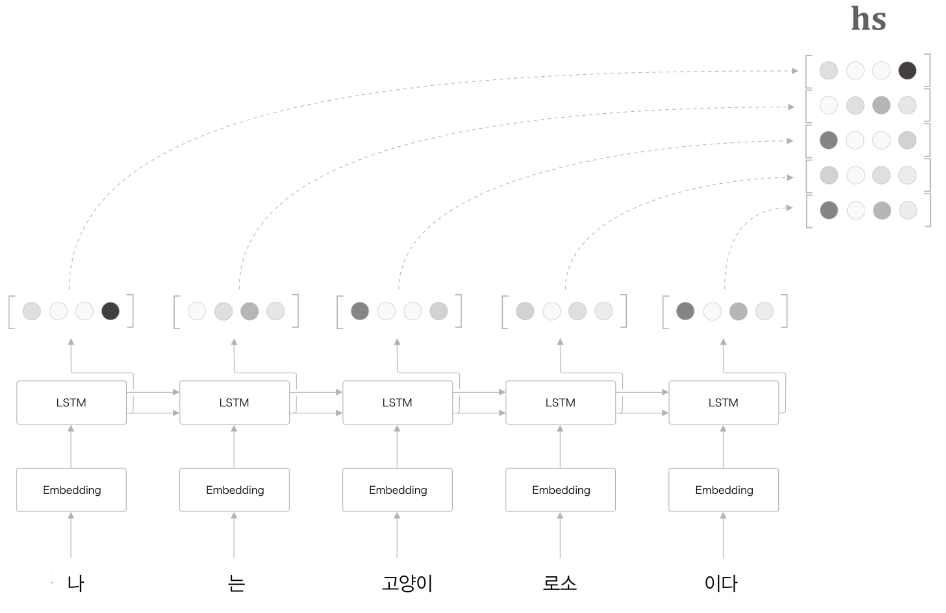
- 각 hidden state의 vector는 입력된 단어에 대한 정보가 가장 많이 들어간 vector다.
- hs 행렬 : 각 단어에 해당하는 벡터들의 집합
각 단어의 hidden state vector를 모두 이용하면 입력된 단어와 같은 수의 vector를 얻을 수 있다. 따라서, 더이상 고정 길이의 vector가 아니다.
8.1.2 Decoder 개선 #1
개선점 : Encoder에서 각 단어에 대응하는 LSTM의 hidden state vector들을 hs 행렬로 모아 출력한다.
seq2seq : Encoder의 마지막 hidden state vector만 Decoder의 첫 hidden state에 전달한다.
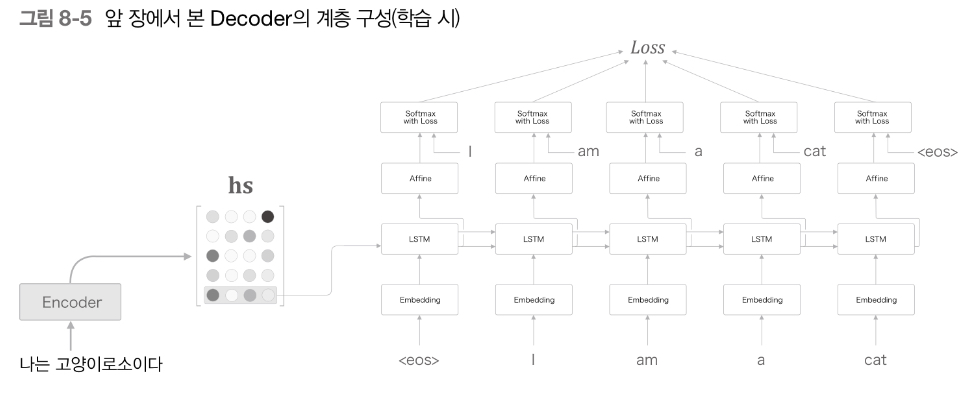
Attention : Encoder에서 각 단어에 대응하는 hs 행렬을 Decoder에 전달하여 시계열 변환한다.
- 필요한 정보에만 주목하여 그 정보로부터 시계열 변환을 수행한다.
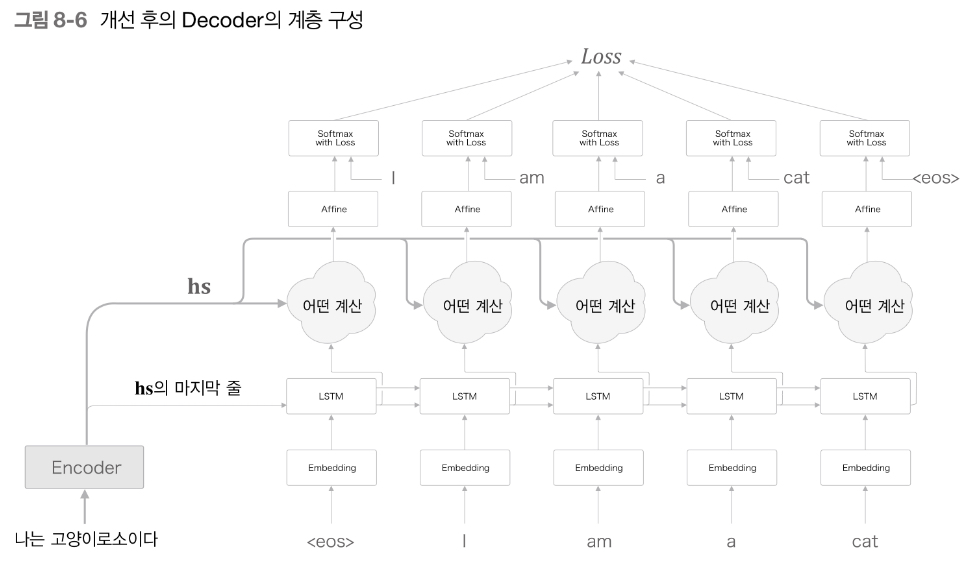
hs 행렬의 모든 정보를 활용할 수 있도록 Decoder를 개선했다.
Computation
Input
- Encoder로부터 출력된 hs 행렬
- 단어별 LSTM layer의 hidden state
Affine
- Input 중에 필요한 정보만 추출하여 Affine layer로 출력함
Softmax with loss
- 모든 벡터를 선택한 후, 가중치(= 각 단어의 중요도)를 계산함
- Softmax를 사용하여 확률값으로 나타냄
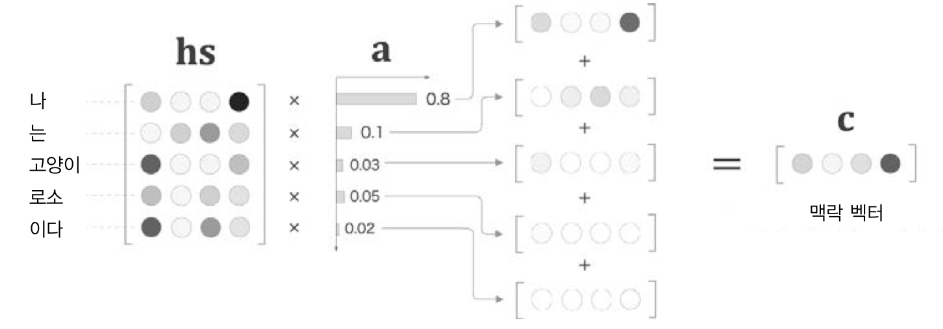
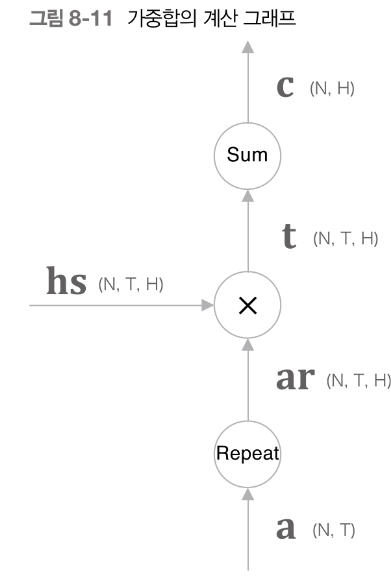
Context vector
- 가중치와 각 단어의 벡터 hs를 weighted sum(가중합)함
- 필요한 정보가 담겨있는 벡터로 학습됨
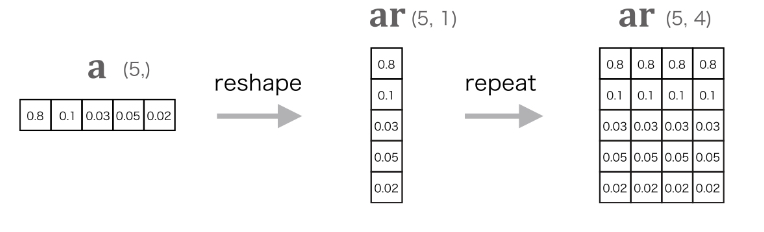
Weighted sum code
- Weighted sum을 구현하는 코드
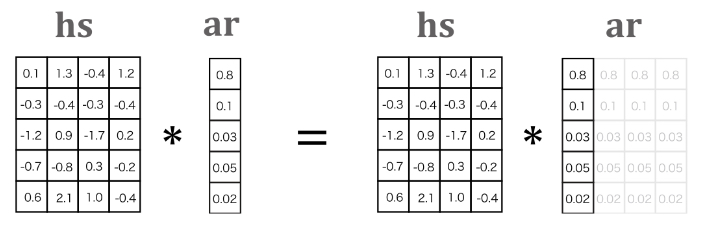
import numpy as np
N, T, H = 10, 5, 4
hs = np.random.randn(N, T, H)
a = np.random.randn(N, T)
ar = np.reshape(N, T, 1).repeat(H, axis=2)
# np.broadcast를 사용하는 경우
# ar = a.reshape(N, T, 1)
# weighted 구하는 방법
t = hs * ar
print(t.shape)
# (10, 5, 4)
# weighted sum 구하는 방법
c = np.sum(t, axis=1)
print(c.shape)
# (10, 4)- Weighted sum layer를 구현하는 코드
class WeightSum:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
def forward(self, hs, a):
N, T, H = hs.shape
ar = a.reshape(N, T, 1)#.repeat(T, axis=1)
t = hs * ar
c = np.sum(t, axis=1)
self.cache = (hs, ar)
return c
def backward(self, dc):
hs, ar = self.cache
N, T, H = hs.shape
dt = dc.reshape(N, 1, H).repeat(T, axis=1) # sum의 역전파
dar = dt * hs
dhs = dt * ar
da = np.sum(dar, axis=2) # repeat의 역전파
return dhs, da각 단어의 중요도를 나타내는 가중치를 이용하여 가중합을 구하고 가중합을 이용해 context vector를 구한다. Context vector를 구하는 방법은 알게되었는데, 가중치를 구하는 방법은?
8.1.4 Decoder 개선 #2
각 단어의 중요도를 데이터로부터 자동으로 학습할 수 있도록 설계해야한다.

- hs : Encoder의 출력 행렬
- h : Decoder LSTM layer의 hidden state vector
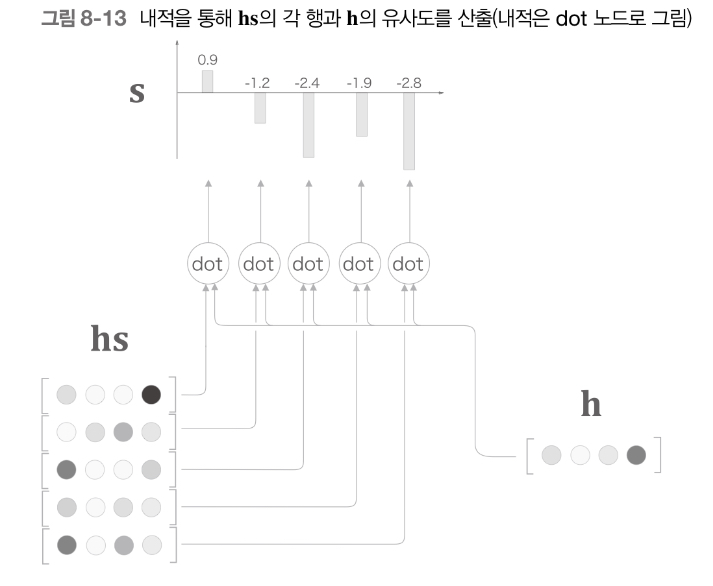
hs의 각 단어 벡터와 h 벡터 간의 벡터의 내적을 사용하여 두 벡터의 유사도를 계산한다.
가중치를 구하는 방법
- h와 hs의 각 단어 벡터와의 유사도를 구한다.
- s : 벡터의 유사도를 산출한 값
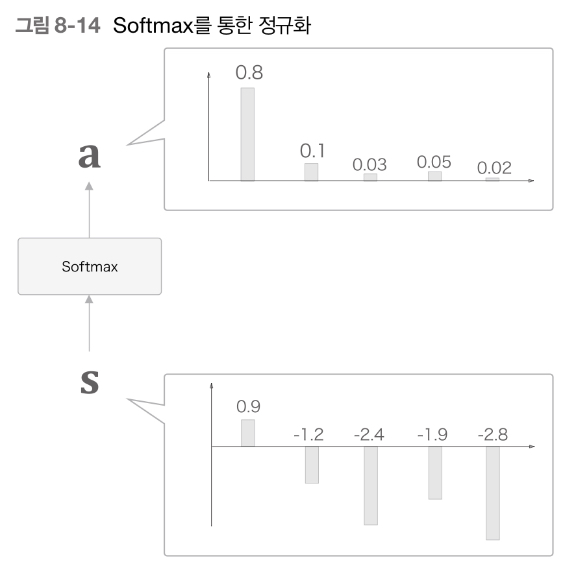
- s를 정규화하기위해 softmax를 적용한다.
- 각 단어의 가중치를 나타내는 a는 s에 softmax가 적용된 값이다.
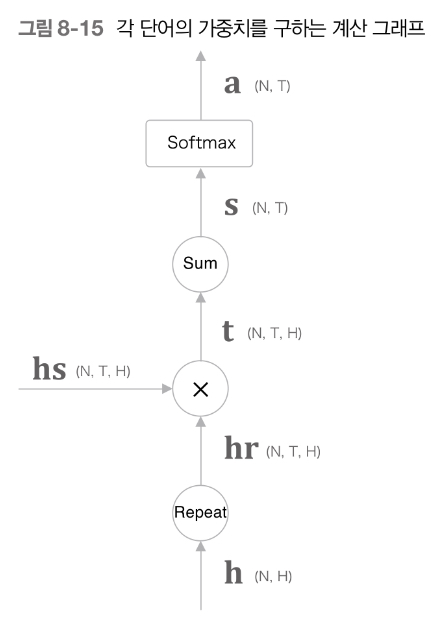
전체 흐름도
Attention Weight code
class AttentionWeight:
def __init__(self):
self.params, self.grads = [], []
self.softmax = Softmax()
self.cache = None
def forward(self, hs, h):
N, T, H = hs.shape
hr = h.reshape(N, 1, H)#.repeat(T, axis=1)
t = hs * hr
s = np.sum(t, axis=2)
a = self.softmax.forward(s)
self.cache = (hs, hr)
return a
def backward(self, da):
hs, hr = self.cache
N, T, H = hs.shape
ds = self.softmax.backward(da)
dt = ds.reshape(N, T, 1).repeat(H, axis=2)
dhs = dt * hr
dhr = dt * hs
dh = np.sum(dhr, axis=1)
return dhs, dhh와 hs의 각 단어 벡터와의 유사도를 이용하여 데이터로부터 가중치를 자동으로 계산할 수 있다.
