Tave_NLP 스터디
1.2.4 통계 기반 기법 개선하기
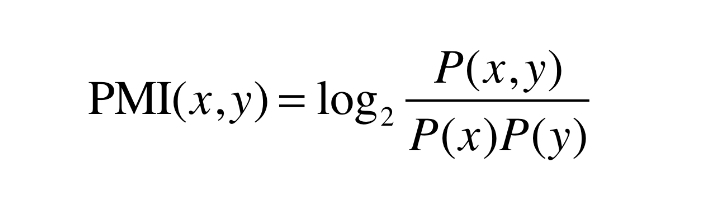
동시발생 행렬의 원소 : 두 단어가 동시에 발생한 횟수ex. the, car, drivethe + car : 동시발생 횟수 많음, 연관성 적음car + drive : 동시발생 횟수 적음, 연관성 높음Error! 관사와 같은 연관성 적은 단어가 동시발생 횟수만으로 연관성
2023년 3월 17일
2.4.3 개선판 word2vec 학습 - 4.4 word2vec 남은 주제
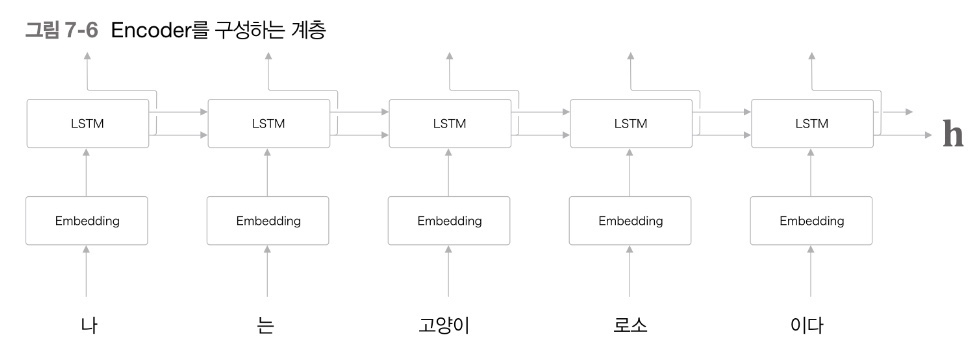
: 주변 단어들을 이용하여 중심 단어를 예측하는 모델: class SimpleCBOW에서 Embedding 계층과 Negative Sampling Loss 계층을 적용했음: 입력 데이터를 처리하는 역할각 단어의 인덱스를 입력으로 받아 해당 단어를 임베딩 벡터로 변환해당
2023년 3월 24일
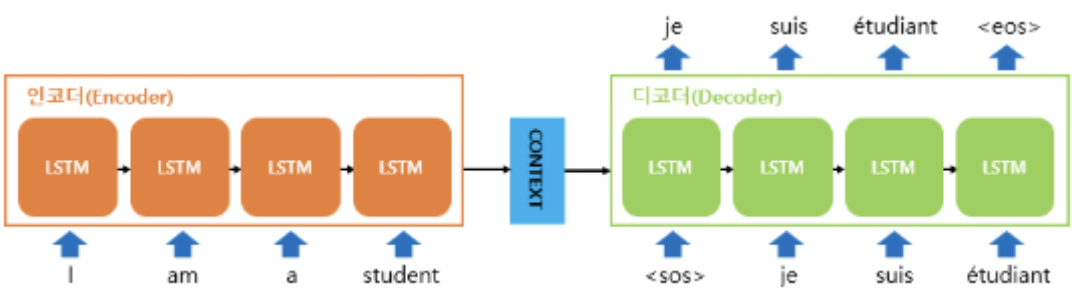
3.7.1 언어 모델을 사용한 문장 생성 - 7.2 seq2seq
언어 모델을 사용하여 문장을 생성하는 방법: 지금까지 주어진 단어들에서 다음에 출현하는 단어의 확률분포를 출력함결정적 방법: 확률이 가장 높은 단어를 선택함확률적 방법: 각 후보 단어의 확률에 맞게 선택함 -> 매번 선택되는 단어가 달라질 수 있음RnnlmGen Cla
2023년 4월 1일
4.8.1 Attention 구조
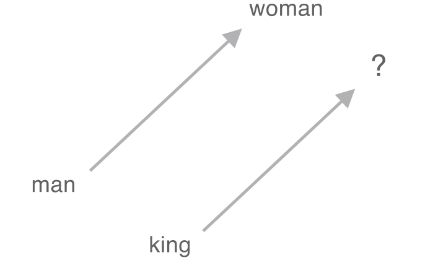
Attention을 이용하여 seq2seq가 가진 문제점을 해결할 수 있다.한계점 : Encoder에서 context vector (= 고정 길이 벡터)를 출력한다.입력 문장의 길이에 관계없이 항상 같은 길이의 벡터로 변환한다. 긴문장일 경우, 필요한 정보가 벡터에 다
2023년 4월 7일