7.1 언어 모델을 사용한 문장 생성
언어 모델을 사용하여 문장을 생성하는 방법
7.1.1 언어 모델
: 지금까지 주어진 단어들에서 다음에 출현하는 단어의 확률분포를 출력함
- 결정적 방법: 확률이 가장 높은 단어를 선택함
- 확률적 방법: 각 후보 단어의 확률에 맞게 선택함 -> 매번 선택되는 단어가 달라질 수 있음
7.1.2 문장 생성 구현
RnnlmGen Class
# 문장 생성하는 RnnlmGen
class RnnlmGen(Rnnlm):
def generate(self, start_id, skip_ids=None, sample_size=100):
word_ids = [start_id]
x = start_id
while len(word_ids) < sample_size:
x = np.array(x).reshape(1, 1)
score = self.predict(x) # 각 단어의 점수를 출력함
p = softmax(score.flatten()) # 점수 정규화 -> 확률 분포값
sampled = np.random.choice(len(p), size=1, p=p) # 단어 샘플링
if (skip_ids is None) or (sampled not in skip_ids):
x = sampled
word_ids.append(int(x))
return word_idsCode
# example code
# coding: utf-8
import sys
sys.path.append('..')
from rnnlm_gen import RnnlmGen
from dataset import ptb
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = RnnlmGen()
model.load_params('../ch06/Rnnlm.pkl')
# start 문자와 skip 문자 설정
start_word = 'you' # 첫 단어
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$'] # 샘플링하지 않을 단어
skip_ids = [word_to_id[w] for w in skip_words]
# 문장 생성
word_ids = model.generate(start_id, skip_ids) # 단어 ID -> 배열 형태
txt = ' '.join([id_to_word[i] for i in word_ids]) # 단어 ID 배열 -> 문장 형태
txt = txt.replace(' <eos>', '.\n')
print(txt)Result
- 학습을 수행하지 않은 언어 모델의 경우,

# 모델의 가중치 초깃값으로 무작위한 값을 사용했기 때문에, 단어들의 의미 없이 엉터리로 나열됨
sampled = np.random.choice(len(p), size=1, p=p)- 학습을 수행한 언어 모델의 경우,

# 학습을 끝낸 가중치를 사용하므로, 주어와 동사가 올바른 순서로 짝지어진 문장들이 나옴
-> 학습된 단어의 정렬 패턴을 이용해(학습이 끝난 가중치를 통해) 새로운 문장을 생성 가능함7.1.3. 더 좋은 문장으로
단순한 언어 모델보다 더 좋은 언어 모델을 쓰면, 더 자연스러운 문장 생성 가능!
Code
# RnnlmGen보다 좋은 BetterRnnlmGen 사용
# coding: utf-8
import sys
sys.path.append('..')
from common.np import *
from rnnlm_gen import BetterRnnlmGen
from dataset import ptb
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
corpus_size = len(corpus)
model = BetterRnnlmGen()
model.load_params('../ch06/BetterRnnlm.pkl')
# start 문자와 skip 문자 설정
start_word = 'you'
start_id = word_to_id[start_word]
skip_words = ['N', '<unk>', '$']
skip_ids = [word_to_id[w] for w in skip_words]
# 문장 생성
word_ids = model.generate(start_id, skip_ids)
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print(txt)
model.reset_state()
start_words = 'the meaning of life is'
start_ids = [word_to_id[w] for w in start_words.split(' ')]
for x in start_ids[:-1]:
x = np.array(x).reshape(1, 1)
model.predict(x)
word_ids = model.generate(start_ids[-1], skip_ids)
word_ids = start_ids[:-1] + word_ids
txt = ' '.join([id_to_word[i] for i in word_ids])
txt = txt.replace(' <eos>', '.\n')
print('-' * 50)
print(txt)Result

# 문장 사용이 더 자연스러워짐7.2 seq2seq
2개의 RNN을 이용해 시계열 데이터를 다른 시계열 데이터로 변환하는 모델
7.2.1 seq2seq의 원리
seq2seq 모델
Encoder-Decoder 모델
- Encoder : 입력 데이터를 인코딩함
- Decoder : 인코딩된 데이터를 디코딩함
Encoder-Decoder를 사용하여, 한 문장(시퀀스)을 다른 문장(시퀀스)으로 변환하는 모델
seq2seq 모델 구조
ex. 나는 고양이다 -> I am a cat
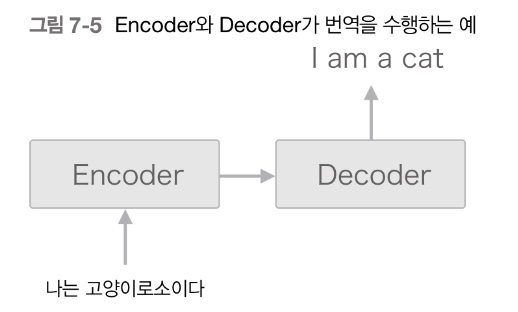
- Encoder에서 '나는 고양이다'라는 입력 문장을 받아 Context vector를 만든다.
- Context vector : 문장에 대한 정보가 응축되어 있는 벡터
= '나는 고양이다'에 대한 정보를 압축하고 있는 벡터
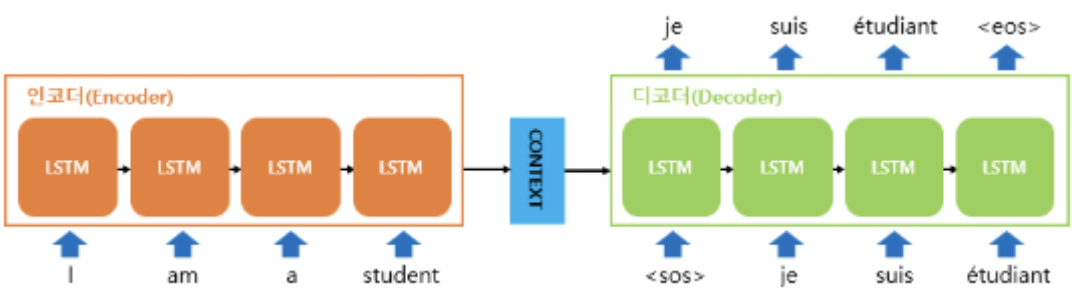
- Decoder에서 Context vector를 받아 최종적으로 'I am a cat'이라는 영어 문장을 생성한다. (다른 문장 생성)
Encoder
: 입력 문장을 통해 Context vector를 생성하는 언어 모델 형식
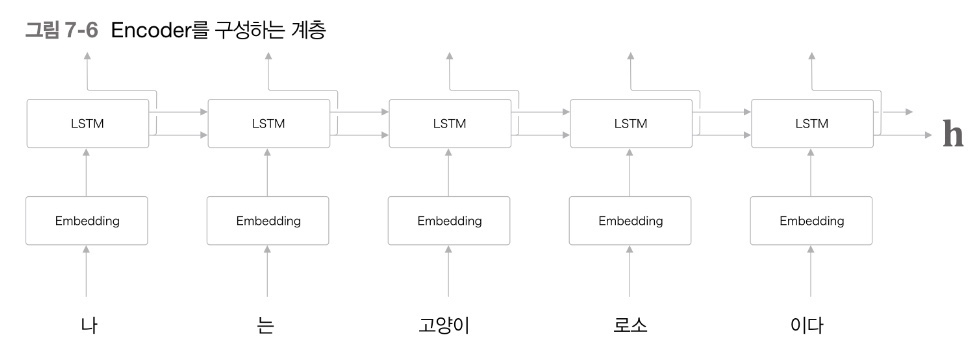
- 입력 문장을 단어 단위로 쪼개어 순서대로 입력 받는다.
- 오른쪽(시계 방향)과 위쪽으로 은닉 상태를 출력한다.
- 오른쪽에 LSTM layer가 있으므로 오른쪽 출력은 다음 LSTM layer로 전달됨
- 위쪽에 다른 layer가 없으므로 위쪽 출력은 폐기됨
- 마지막 단어가 마지막 LSTM layer에서 처리된 후, 마지막 LSTM의 은닉층인 Context vector가 생성된다.
- Context vector에서 입력 문장을 번역하는데 필요한 정보를 encoding한다.
- Encoding : 입력 문장을 Context vector(= 고정 길이 벡터)로 변환함
- seq2seq 모델에서 Context vector는 Encoder의 마지막 은닉층과 같은 역할을 수행함
Word Embeddings
: 모든 문자를 숫자화하여 벡터로 표현하는 방법
(딥러닝 모델은 문자보다 숫자를 사용했을 때 성능이 더 좋으므로)
Decoder
: Context vector를 통해 출력 문장을 예측하는 언어 모델 형식
- < sos > : 문장의 시작(start of string)
- < eos > : 문장의 끝(end of string)
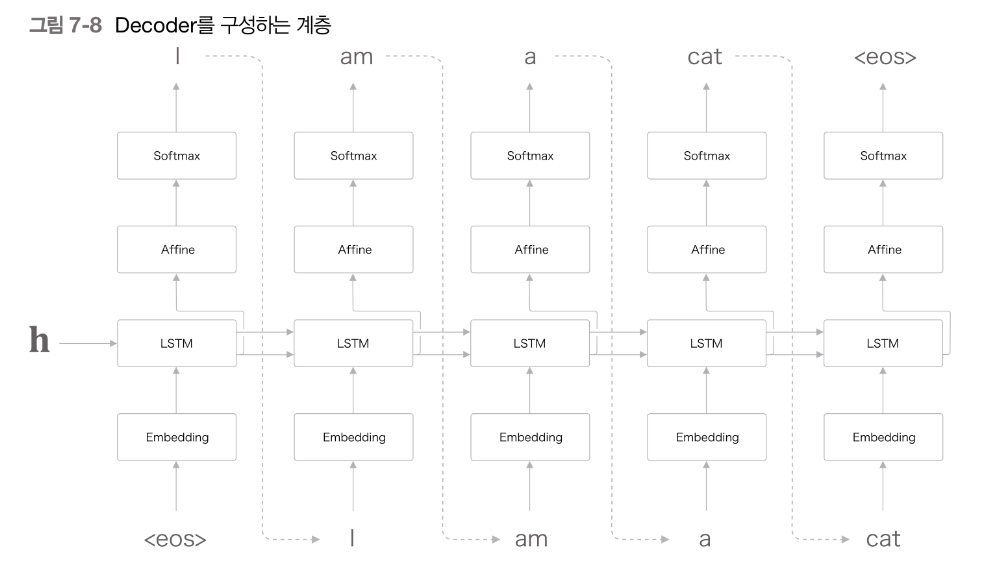
- Encoder로부터 Context vector와 < sos >를 전달받아 입력한다.
- 이 2개를 입력받아 그 다음에 등장할 확률이 가장 높은 첫 단어를 예측한다.
(softmax : 다양한 다어에 대한 벡터 값 중 확률이 가장 높은 단어를 선택함) - 이전 스텝의 예측 값을 입력값으로 받아 그 다음에 등장할 확률이 가장 높은 단어를 예측한다.
- 문장 내 모든 단어에 대해 반복한다.
seq2seq 전체 구조
: Encoder의 LSTM과 Decoder의 LSTM 사이에 Context vector를 은닉층으로 이어진 모델
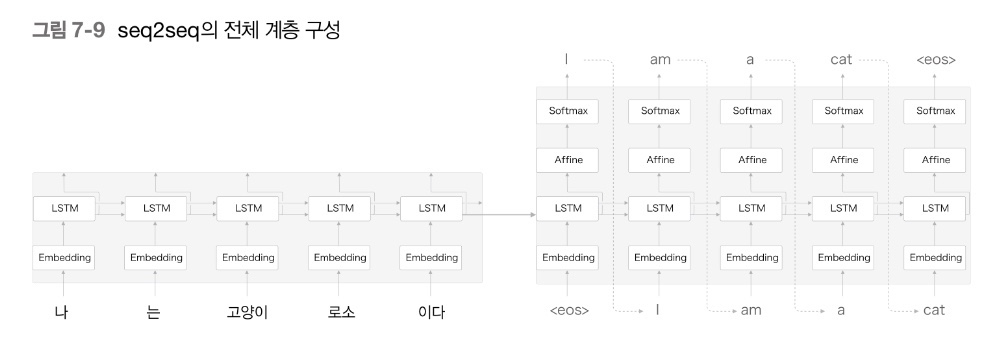
- Foward propagation : Encoder의 인코딩된 정보가 Context vector를 통해 Decoder로 전달됨
- Back propagation : Decoder의 기울기가 Context vector를 통해 Encoder로 전달됨
+) NLP 전처리 방법
-
문장 부호 제거: 특수 문자나 문장 부호들은 자연어 처리 과정에서 별다른 의미가 없으므로 제거해주는 것이 좋음
-
불용어 처리: 자주 등장하지만 문맥상 큰 의미가 없는 단어들 (예: the, a, an)은 불용어로 분류하여 제거해주는 것이 좋음
-
소문자 변환: 모든 단어를 소문자로 변환하여 대소문자 구분에 따른 처리 차이를 없애주는 것이 좋음
-
토큰화: 문장을 단어로 분리하는 작업으로, 일반적으로는 공백을 기준으로 단어를 분리함
7.2.2 시계열 데이터 변환용 장난감 문제
seq2seq 모델을 사용하여, 더하기 문제 풀어보기
- 기존 '숫자' 덧셈 방식
# 57 + 5 =62
x= 57
y= 5
print(x+y)
# 결과값
62- '문자' 덧셈 방식
# 57 + 5 =62
['57', '+', '62'] # 리스트 형식, 전부 다 문자로 처리함
# seq2seq 모델 거친 후
# 결과값
'62' # 문자열
7.2.3 가변 길이 시계열 데이터
가변 길이 시계열 데이터
Problem
숫자를 문자로 처리할 경우, 숫자의 자릿수에 따라 문자 수가 달라짐
= sample 마다 데이터의 시간, 방향, 크기가 모두 달라짐
Mini batch로 학습 시, sample의 데이터 shape이 모두 같아야함!
Solved!
Padding을 사용하자!
Padding
: 원래의 데이터에 빈 부분들을 의미 없는 데이터로 채워, 모든 데이터의 길이를 균일하게 맞추는 기법
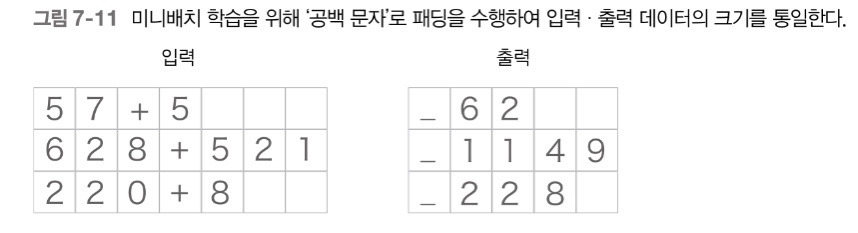
데이터의 크기를 통일시켜 가변 길이 데이터 처리 가능!
(정확도를 높이기 위해서는 패딩값이 결과에 반영되지 않도록 softmax with loss 계층에 마스크 기능을 추가하거나 lstm 계층에서 패딩 값이 들어오면 이전 시각의 입력을 그대로 출력하거나 등등의 작업이 필요함)
7.2.4 덧셈 데이터셋
Dataset
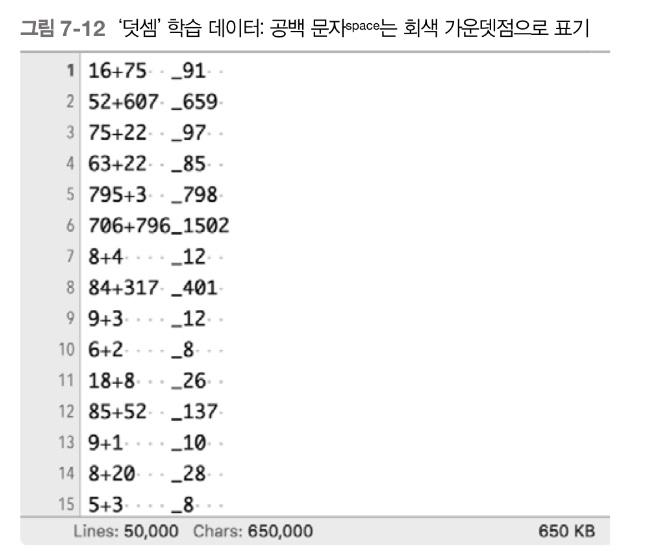
Code
# coding: utf-8
import sys
sys.path.append('..')
from dataset import sequence
(x_train, t_train), (x_test, t_test) = \
sequence.load_data('addition.txt', seed=1984)
char_to_id, id_to_char = sequence.get_vocab()
print(x_train.shape, t_train.shape)
print(x_test.shape, t_test.shape)
# (45000, 7) (45000, 5)
# (5000, 7) (5000, 5)
print(x_train[0])
print(t_train[0])
# [ 3 0 2 0 0 11 5]
# [ 6 0 11 7 5]
print(''.join([id_to_char[c] for c in x_train[0]]))
print(''.join([id_to_char[c] for c in t_train[0]]))
# 71+118
# _189- 71 + 118을 계산하는 것이 아닌 문자로 학습하여 71 + 118 다음에 189가 올 확률이 가장 높다고 계산하여 결과값을 반환함
References
- '밑바닥부터 시작하는 딥러닝2'
- '딥러닝을 이용한 자연어처리'
- https://bkshin.tistory.com/entry/NLP-13-%EC%8B%9C%ED%80%80%EC%8A%A4%ED%88%AC%EC%8B%9C%ED%80%80%EC%8A%A4seq2seq
