이 내용은 윤성우의 열혈 자료구조를 학습한 내용입니다.1. 빠른 탐색을 보이는 해쉬 테이블
1-1. 테이블 자료구조의 이해
- 데이터가
key와value로 한 쌍을 이루며,key가 데이터의 저장 및 탐색의 도구가 된다.key가 존재하지 않는 ‘값(value)’은 저장할 수 없다.- 모든 키는 중복되지 않는다.
- 테이블은 사전 구조 또는 맵(map)이라 불린다.
- 테이블 자료구조의 탐색 연산은
O(1)의 시간 복잡도를 보인다.
1-2. 배열을 기반으로 하는 테이블
typedef struct _empInfo
{
int empNum; // 직원의 고유번호: key
int age; // 직원의 나이: value
} EmpInfo;
int main(void)
{
EmpInfo empInfoArr[1000]; // 직원들의 정보 저장 배열
EmpInfo ei;
int eNum;
printf("사번과 나이 입력: ");
scanf("%d %d", &(ei.empNum), &(ei.age));
empInfoArr[ei.empNum] = ei; // 저장
printf("확인하고픈 직원의 사번 입력: ");
scanf("%d", &eNum);
ei = empInfoArr[eNum]; // 탐색
printf("사번 %d, 나이 %d \n", ei.empNum, ei.age);
return 0;
}- 직원의 고유번호인 사번을
key로 하여 데이터를 저장하고 탐색할 수 있다.- 저장:
empInfoArr[ei.empNum] = ei; - 탐색:
ei = empInfoArr[eNum];
- 저장:
- 다만, 직원 고유번호의 범위가 커질수록 매우 큰 배열이 필요하기에 ‘해쉬’의 개념이 필요하다.
1-3. 테이블에 의미를 부여하는 해쉬 함수와 충돌문제
- 해쉬 함수(hash function)
- 넓은 범위의 키를 좁은 범위의 키로 변경하는 역할
- 합리적인 메모리 공간의 할당을 돕는다
✔️ 충돌문제(collision)
- 서로 다른 키가 해쉬 함수를 통과했을 때 같은 해쉬 값을 가질 수 있다.
- 만약, 해쉬 함수가 이라고 할 때,
20120003과20210103은03으로 같은 값을 가진다.
- 만약, 해쉬 함수가 이라고 할 때,
1-4. 어느 정도 갖춰진 테이블과 해쉬의 구현의 예
- 테이블에 저장할 대상에 대한 헤더파일
#ifndef __PERSON_H__ #define __PERSON_H__ #define STR_LEN 50 typedef struct _person { int ssn; // 주민등록번호 char name[STR_LEN]; // 이름 char addr[STR_LEN]; // 주소 } Person; int GetSSN(Person * p); void ShowPerInfo(Person * p); Person * MakePersonData(int ssn, char * name, char * addr); #endifPerson구조체 변수의 주소 값이 테이블에 저장될 값이다.- 구조체의 멤버
ssn을 ‘키’로 결정했다.
- 테이블의 슬롯(Slot)과 헤더 파일
-
슬롯: 테이블을 이루는, 데이터를 저장할 수 있는 각각의 공간
#ifndef __SLOT_H__ #define __SLOT_H__ #include "Person.h" typedef int Key; // 주민등록번호 typedef Person * Value; enum SlotStatus {EMPTY, DELETED, INUSE}; typedef struct _slot { Key key; Value val; enum SlotStatus status; // 슬롯의 상태를 나타내는 멤버 } Slot; #endif -
키: 주민등록번호
-
값:
Person구조체 변수의 주소 값 -
enum선언을 통해서 슬롯의 상태를 나타내는 상수를 정의했다.EMPTY: 이 슬롯에는 데이터가 저장된바 없다.DELETED: 이 슬롯에는 데이터가 저장된바 있으나 현재는 비워진 상태다.INUSE: 이 슬롯에는 현재 유효한 데이터가 저장되어 있다.
-
- 테이블의 헤더파일
#ifndef __TABLE_H__ #define __TABLE_H__ #include "Slot.h" #define MAX_TBL 100 typedef int HashFunc(Key k); typedef struct _table { Slot tbl[MAX_TBL]; HashFunc * hf; } Table; // 테이블의 초기화 void TBLInit(Table * pt, HashFunc * f); // 테이블에 키와 값을 저장 void TBLInsert(Table * pt, Key k, Value v); // 키를 근거로 테이블에서 데이터 삭제 Value TBLDelete(Table * pt, Key k); // 키를 근거로 테이블에서 데이터 탐색 Value TBLSearch(Table * pt, Key k); #endif- 직접 정의한 해쉬 함수를 테이블에 등록한다.
Slot의 배열로 테이블을 구성했다.
- 테이블의 구현
#include <stdio.h> #include <stdlib.h> #include "Table.h" void TBLInit(Table * pt, HashFunc * f) { int i; // 모든 슬롯 초기화 for(i=0; i<MAX_TBL; i++) (pt->tbl[i]).status = EMPTY; pt->hf = f; // 해쉬 함수 등록 } void TBLInsert(Table * pt, Key k, Value v) { int hv = pt->hf(k); pt->tbl[hv].val = v; pt->tbl[hv].key = k; pt->tbl[hv].status = INUSE; } Value TBLDelete(Table * pt, Key k) { int hv = pt->hf(k); if((pt->tbl[hv]).status != INUSE) { return NULL; } else { (pt->tbl[hv]).status = DELETED; return (pt->tbl[hv]).val; // 소멸 대상의 값 반환 } } Value TBLSearch(Table * pt, Key k) { int hv = pt->hf(k); if((pt->tbl[hv]).status != INUSE) return NULL; else return (pt->tbl[hv]).val; // 탐색 대상의 값 반환 }- 테이블의 초기화
- 키와 값 쌍의 삽입과 삭제
- 키를 이용한 테이블의 값 탐색
1-5. 좋은 해쉬 함수의 조건
- 해쉬 함수를 사용한 결과
아래 두 개의 그림은 테이블의 메모리 상황을 표현한 것이다.
검은 영역은 데이터가 채워진 슬롯을 의미하고, 반대로 흰 영역은 빈 슬롯을 의미한다.
- 좋은 해쉬 함수일 경우, 데이터의 저장 위치가 적당히 분산되어 있다. → ‘충돌’이 발생할 확률이 낮다.
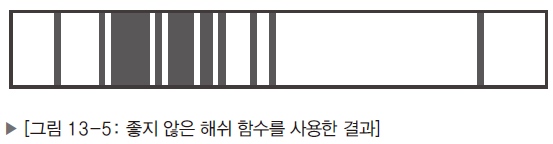
- 반면, 좋지 않는 해쉬 함수를 사용할 경우 테이블의 특정 영역에 데이터가 몰려있다.
일반적으로 좋은 해쉬 함수는 키의 일부분을 참조하여 해쉬 값을 만들지 않고, 키 전체를 참조하여 해쉬 값을 만들어 낸다.
🔻 해쉬 함수의 디자인 방법
좋은 해쉬 함수의 디자인 방법은 키의 특성에 따라 달라진다.
-
자릿수 선택 방법(Digit Selection)
- 키의 특정 위치에서 중복의 비율이 높거나 아예 공통으로 들어가는 값이 있다면 이들을 제외한 나머지를 가지고 해쉬 값을 생성한다.
N자리의 수로 이뤄진 키에서 다양한 해쉬 값 생성에 도움을 주는M자리의 수를 뽑아서 해쉬 값을 생성한다.
-
자릿수 폴딩 방법(Digit Folding)
- 숫자를 겹치게 하여 더한 결과를 해쉬 값으로 결정하는 방법
N자리 숫자 모두를 반영하여 결과를 얻는다.
- 다음의 6자리 수(
24 | 34 | 19)가 있을 때, 모두를 더한 값인80을 해쉬 값으로 사용한다.
- 숫자를 겹치게 하여 더한 결과를 해쉬 값으로 결정하는 방법
🚩 해쉬 함수를 디자인할 때에는 방법보다는 키의 특성과 저장공간의 크기를 고려하는 것이 우선이다.
2. 충돌 문제의 해결책
충돌이 발생했을 때, 충돌이 발생한 그 자리를 대신해서 빈 자리를 찾아야 한다. 다만 빈 자리를 찾는 방법에 따라서 해결책이 구분될 뿐이다.
2-1. 선형 조사법과 이차 조사법
- 선형 조사법(Linear Probing)
-
충돌이 발생했을 때 그 옆자리가 비었는지 살펴보고, 비었을 경우 그 자리에 대신 저장한다.
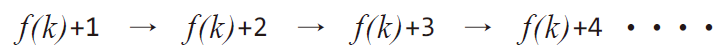
-
다만, 충돌 횟수가 증가함에 따라 클러스터(cluster) 현상, ‘특정 영역에 데이터가 집중적으로 몰리는 현상’이 발생하는 단점이 있다.
-
-
이차 조사법(Quadratic Probing)
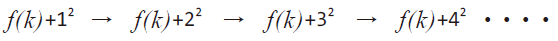
- 충돌 발생 시 칸 옆의 슬롯을 검사한다.
- 선형 조사법보다 멀리서 빈 공간을 찾는다.
🔻 슬롯의 상태 정보 관리
- 슬롯의 상태
EMPTY: 이 슬롯에는 데이터가 저장된바 없다.DELETED: 이 슬롯에는 데이터가 저장된바 있으나 현재는 비워진 상태다.INUSE: 이 슬롯에는 현재 유효한 데이터가 저장되어 있다.

위 그림과 같이 선형 조사법이 사용되고, 해쉬 함수가 인 테이블(배열)에 키 9와 2인 데이터를 차례로 저장하고, 키가 9인 데이터를 삭제한 경우를 생각해보자.
- 만약 삭제된 슬롯의 상태 정보를
EMPTY로 표현한다면, 키가2인 데이터를 탐색할 때 데이터가 존재하지 않는다고 판단하여 탐색을 종료한다. - 하지만
DELETED상태임을 확인한다면 충돌이 발생했음을 의심하여 선형 조사법에 근거한 탐색의 과정을 진행하여 키가2인 데이터를 탐색할 수 있다.
⇒ 선형, 이차 조사법과 같은 충돌의 해결책을 적용하기 위해서는 슬롯에 상태에 DELETED 를 포함시켜야 한다. 또한, 탐색의 과정에서도 이를 근거로 충돌을 의심하는 탐색의 과정을 포함시켜야 한다.
2-2. 이중 해쉬
✔️ 이차 조사법의 문제점
-
해쉬 값이 같으면, 충돌 발생 시 빈 슬롯을 찾기 위해서 접근하는 위치가 늘 동일하다.
-
이중 해쉬(Double Hash)
- 총 두 개의 해쉬 함수를 활용한다.
- 1차 해쉬 함수: 키를 근거로 저장위치를 결정하기 위한 것
- 2차 해쉬 함수: 충돌 발생 시 몇 칸 뒤를 살필지 결정하기 위한 것
- 2차 해쉬 값의 크기만큼 건너 뛰면서 빈 슬롯을 찾는다.
- 키가 다르면 건너 뛰는 길이도 달라진다. → 클러스터 현상의 발생 확률을 현저히 낮춘다.
- 총 두 개의 해쉬 함수를 활용한다.
✅ 예시
- 1차 해쉬 함수:
- 배열의 길이가 15인 경우
- 2차 해쉬 함수:
c는 배열의 길이(15)보다 작은 소수 중 하나로 결정한다.- 1을 더하는 이유: 2차 해쉬 값이 0이 되는 것을 막아 충돌 자리가 아닌 자리를 찾기 위해
c를 소수로 결정하는 이유: 클러스터 현상의 발생 확률을 현저히 낮춘다는 통계를 근거로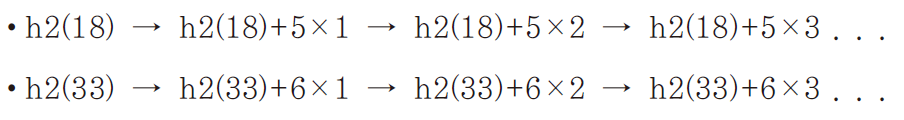
2-3. 체이닝(Chaining)
- 열린 어드레싱 방법(open addressing method)
- 충돌이 발생하면 다른 자리에 대신 저장한다.
- 닫힌 어드레싱 방법(closed addressing method)
- 충돌이 발생해도 자신의 자리에 저장한다.
여러 개의 자리를 마련하는 방법으로는 배열을 이용하는 방법과 연결 리스트를 이용하는 방법이 있다.
-
배열 기반 닫힌 어드레싱 모델

- 2차원 배열을 구성해서, 해쉬 값 별로 다수의 슬롯을 마련한다.
- 충돌이 발생하지 않을 경우 메모리 낭비가 심하다.
-
체이닝(Chaining)
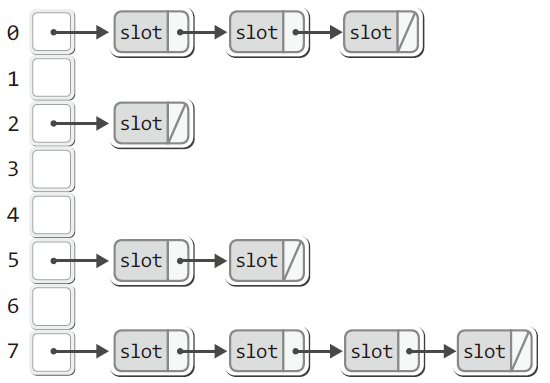
- 연결리스트를 이용해서 슬롯을 연결하는 닫힌 어드레싱 방법
- 하나의 해쉬 값에 다수의 데이터(슬롯)을 저장한다.
- 다만, 탐색을 위해서는 동일한 해쉬 값으로 묶여있는 연결된 슬롯을 모두 조사해야 한다.
2-4. 충돌 문제의 해결을 위한 체이닝의 구현
- 슬롯의 헤더 파일
#ifndef __SLOT2_H__ #define __SLOT2_H__ #include "Person.h" typedef int Key; typedef Person * Value; // enum SlotStatus {EMPTY, DELETED, INUSE}; typedef struct _slot { Key key; Value val; } Slot; #endif- 더 이상 슬롯의 상태 정보를 유지하지 않는다.
- 테이블의 헤더 파일
#ifndef __TABLE2_H__ #define __TABLE2_H__ #include "Slot2.h" #include "DLinkedList.h" #define MAX_TBL 100 typedef int HashFunc(Key k); typedef struct _table { List tbl[MAX_TBL]; // Slot tbl[MAX_TBL]; HashFunc * hf; } Table; void TBLInit(Table * pt, HashFunc * f); void TBLInsert(Table * pt, Key k, Value v); Value TBLDelete(Table * pt, Key k); Value TBLSearch(Table * pt, Key k); #endif- 테이블의 저장소였던 Slot형 배열을 List 형 배열(연결 리스트)로 바꾸었다.
- 해쉬 값 별로 연결 리스트를 구성한다.
🔻 연결 리스트와 구조체 Slot의 관계 설계
-
슬롯이 연결 리스트의 노드 역할을 한다.

typedef struct _slot // 구조체 Slot이 연결 리스트의 노드 역할을 겸하는 구조 { Key key; Value val; struct _slot * next; // 다음 노드를 가리키는 포인터 변수 } Slot; -
연결 리스트의 노드와 슬롯을 구분한다. (보다 좋은 구조)
-
노드에 슬롯의 주소 값을 저장하는 형태
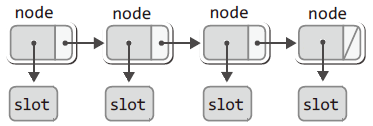
-
노드에 슬롯의 주소 값을 저장한다.
typedef Slot * Data; // 노드에 저장할 데이터는 Slot형 변수의 주소 값이다. typedef struct _node { Data data; struct _node * next; } Node;
-
-
🚩 슬롯이 노드의 멤버가 되게 한다.

-
노드의 데이터 부분이 슬롯이 되게 한다.
-
연결 리스트를 그대로 활용하는 좋은 모델이다.
typedef Slot Data; // 노드에 저장할 데이터는 Slot형 변수다. typedef struct _node { Data data; struct _node * next; } Node;
-
-
- 체이닝의 구현
#include <stdio.h> #include <stdlib.h> #include "Table2.h" #include "DLinkedList.h" void TBLInit(Table * pt, HashFunc * f) { int i; for(i=0; i<MAX_TBL; i++) ListInit(&(pt->tbl[i])); pt->hf = f; } void TBLInsert(Table * pt, Key k, Value v) { int hv = pt->hf(k); Slot ns = {k, v}; if(TBLSearch(pt, k) != NULL) // 키가 중복되었다면 { printf("키 중복 오류 발생 \n"); return; } else { LInsert(&(pt->tbl[hv]), ns); } } Value TBLDelete(Table * pt, Key k) { int hv = pt->hf(k); Slot cSlot; if(LFirst(&(pt->tbl[hv]), &cSlot)) { if(cSlot.key == k) { LRemove(&(pt->tbl[hv])); return cSlot.val; } else { while(LNext(&(pt->tbl[hv]), &cSlot)) { if(cSlot.key == k) { LRemove(&(pt->tbl[hv])); return cSlot.val; } } } } return NULL; } Value TBLSearch(Table * pt, Key k) { int hv = pt->hf(k); Slot cSlot; if(LFirst(&(pt->tbl[hv]), &cSlot)) { if(cSlot.key == k) { return cSlot.val; } else { while(LNext(&(pt->tbl[hv]), &cSlot)) { if(cSlot.key == k) return cSlot.val; } } } return NULL; }참고: 윤성우의 열혈 자료구조
