이 내용은 윤성우의 열혈 자료구조를 학습한 내용입니다.1. 우선순위 큐의 이해
1-1. 우선순위 큐와 우선순위의 이해
🔻 핵심 연산
enqueue: 우선순위 큐에 데이터를 삽입하는 행위dequeue: 우선순위 큐에서 데이터를 꺼내는 행위
큐와 달리 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나온다.
- 우선순위
- 데이터(정수)를 근거로 우선순위를 판단할 수 있어야 한다.
- 우선순위가 높은 데이터에 큰 값/작은 값을 부여하는 것은 결정하기 나름이다.
- 우선 순위가 같은 데이터는 존재할 수 있다.
1-2. 우선순위 큐의 구현 방법
숫자 1이 가장 높은 우선순위를 뜻하며, 이보다 값이 커질수록 우선순위는 낮아진다고 가정한다.
우선순위 큐를 구현하는 방법은 다음과 같이 세 가지로 구분할 수 있다.
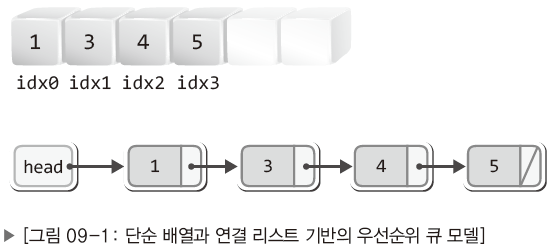
- 배열 기반
- 데이터의 우선순위가 높을수록 배열의 앞쪽에 데이터를 위치시킨다.
- 문제상황
- 데이터를 삽입/삭제 하는 과정에서 데이터를 한 칸씩 밀거나 당기는 연산을 수반해야 한다.
- 📌 삽입의 위치를 찾기 위해 배열에 저장된 모든 데이터와 우선순위를 비교해야 할 수 있다.
- 연결 리스트 기반
- 배열 기반 단점 중 두 번째 단점은 연결 리스트에도 존재한다.
- 힙(heap)을 이용
삽입의 위치를 찾기 위해 배열에 저장된 모든 데이터와 우선순위를 비교해야 할 수 있다.
⇒ 따라서, 우선순위 큐는 ‘힙’이라는 자료구조를 이용해서 구현하는 것이 일반적이다.
1-3. 힙(Heap)의 소개
힙은 ‘완전 이진 트리’이다.
-
힙의 정의
- 힙은 ‘이진 트리’이되 ‘완전 이진 트리’이다.
- 모든 노드에 저장된 값은 자식 노드에 저장된 값보다 크거나 같아야 한다.
- 루트 노드에 저장된 값이 가장 커야 한다.
-
힙의 종류
- 최대 힙(max heap)
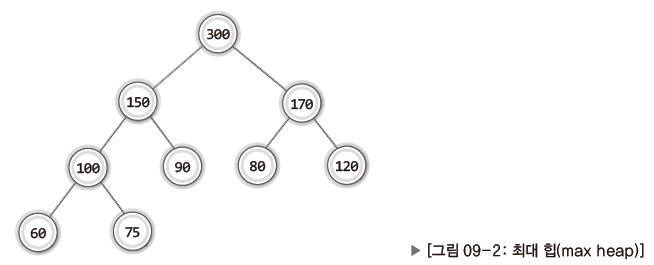
- 루트 노드로 올라갈수록 저장된 값이 커지는 완전 이진 트리
- 최소 힙(min heap)
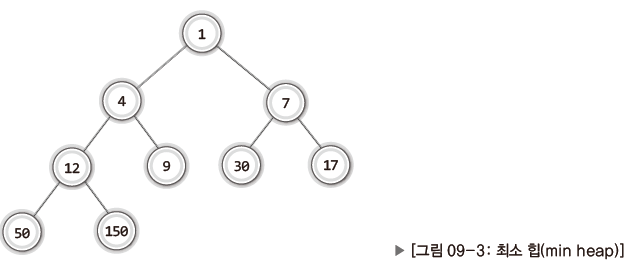
- 루트 노드로 올라갈수록 저장된 값이 작아지는 완전 이진 트리
- 최대 힙(max heap)
2. 힙의 구현과 우선순위 큐의 완성
2-1. 힙에서의 데이터 저장과정
‘최소 힙’을 기준으로 설명한다.
-
숫자가 작을수록 우선순위가 높다고 가정한다.
-
저장 과정
- 새로운 데이터는 우선순위가 제일 낮다는 가정하에서 ‘마지막 위치’에 저장한다.
- 마지막 위치: 마지막 레벨의 가장 오른쪽 위치
- 부모 노드와 우선순위를 비교해서 위치가 바뀌어야 한다면 바꿔준다.
- 제대로 된 위치를 찾을 때까지 2번을 반복한다.
- 새로운 데이터는 우선순위가 제일 낮다는 가정하에서 ‘마지막 위치’에 저장한다.
2-2. 힙에서의 데이터 삭제과정
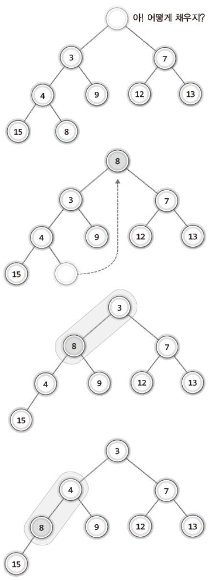
우선순위 큐의 삭제는 ‘가장 높은 우선순위의 데이터 삭제’를 의미한다.
- 삭제 과정
-
마지막 노드를 루트 노드의 자리로 옮긴 다음에, 자식 노드와의 비교를 통해서 제자리를 찾아가게 한다.
- 자식 중 우선순위가 높은 노드와 교환한다.
-
2-3. 삽입과 삭제의 과정에서 보인 성능의 평가
- 우선순위 큐의 성능(시간 복잡도)
삽입 삭제 배열 연결 리스트 힙
힙을 기반으로 하면 트리의 높이에 해당하는 수만큼만 비교연산을 진행하면 된다.
- 힙은 완전 이진 트리이므로, 힙에 저장할 수 있는 데이터의 수는 트리의 높이가 하나 증가할 때마다 두 배씩 증가한다.
→ 데이터의 수가 두 배 늘 때마다, 비교연산의 횟수는 1회 증가한다.
2-4. 힙의 구현에 어울리는 것: 연결 리스트 or 배열
‘힙’은 배열 기반으로 구현해야 한다.
- 연결 리스트 기반으로 힙을 구현하면, 새로운 노드를 힙의 ‘마지막 위치’에 추가하는 것이 쉽지 않다.
2-5. 배열을 기반으로 힙을 구현하는데 필요한 지식들
- 배열을 기반한 트리 구성
- 노드에 고유의 번호를 부여한다.
- 그 번호가 각 노드의 데이터가 저장 될 배열의 인덱스 값이 된다.
- 왼쪽 자식 노드의 인덱스 값:
부모 노드의 인덱스 값 × 2 - 오른쪽 자식 노드의 인덱스 값:
부모 노드의 인덱스 값 × 2 + 1 - 부모 노드의 인덱스 값:
자식 노드의 인덱스 값 ÷ 2
- 왼쪽 자식 노드의 인덱스 값:
2-6. 원리 이해 중심의 힙 구현: 헤더파일
- 헤더 파일
#ifndef __SIMPLE_HEAP_H__ #define __SIMPLE_HEAP_H__ #define TRUE 1 #define FALSE 0 #define HEAP_LEN 100 typedef char HData; typedef int Priority; typedef struct _heapElem { Priority pr; // 값이 작을수록 높은 우선순위 HData data; } HeapElem; typedef struct _heap { int numOfData; HeapElem heapArr[HEAP_LEN]; } Heap; void HeapInit(Heap * ph); int HIsEmpty(Heap * ph); void HInsert(Heap * ph, HData data, Priority pr); HData HDelete(Heap * ph); #endif
- 힙에 저장될 데이터의 모델을 정의한 구조체
typedef struct _heapElem { Priority pr; // 값이 작을수록 높은 우선순위 HData data; } HeapElem;- 우선순위 큐의 구현을 고려하여 우선순위 정보를 별도로 담음
2-7. 원리 이해 중심의 힙 구현: HDelete 함수
✅ 숙지할 내용
- 힙은 완전 이진 트리이다.
- 힙의 구현은 배열을 기반으로 하며 인덱스가 0인 요소는 비워둔다.
- 따라서 힙에 저장된 노드의 개수와 마지막 노드의 고유번호는 일치한다.
→ 마지막 노드의 인덱스 값을 쉽게 얻을 수 있다.
- 노드의 고유번호가 노드가 저장되는 배열의 인덱스 값이 된다.
- 우선순위를 나타내는 정수 값이 작을수록 높은 우선순위를 나타낸다고 가정한다
- 초기화와 empty
- 초기화
void HeapInit(Heap * ph) { ph->numOfData = 0; } - empty
int HIsEmpty(Heap * ph) { if(ph->numOfData == 0) return TRUE; else return FALSE; }
- 초기화
- Helper
- 부모 노드의 인덱스 값 반환
int GetParentIDX(int idx) { return idx/2; } - 왼쪽 자식 노드의 인덱스 값 반환
int GetLChildIDX(int idx) { return idx*2; } - 오른쪽 자식 노드의 인덱스 값 반환
int GetRChildIDX(int idx) { return GetLChildIDX(idx)+1; } - 자식 노드 중 우선 순위가 높은 자식의 인덱스 값 반환
int GetHiPriChildIDX(Heap * ph, int idx) { if(GetLChildIDX(idx) > ph->numOfData) // 자식노드가 존재하지 않는다면 return 0; else if(GetLChildIDX(idx) == ph->numOfData) // 자식 노드가 왼쪽 자식 노드 하나만 존재한다면 return GetLChildIDX(idx); else // 둘 다 존재한다면 { // 오른쪽 자식 노드의 우선순위가 높다면 if(ph->heapArr[GetLChildIDX(idx)].pr > ph->heapArr[GetRChildIDX(idx)].pr) return GetRChildIDX(idx); // 왼쪽 자식 노드의 우선순위가 높다면 else return GetLChildIDX(idx); } }numOfData는 마지막 노드의 고유번호이므로, 자식 노드의 값이 이보다 크면 존재하지 않는 자식 노드이다.- 하나뿐인 자식 노드는 왼쪽 자식 노드이다.
- 부모 노드의 인덱스 값 반환
힙의 마지막 노드를 루트 노드의 위치에 올린 다음에, 자식 노드와의 비교과정을 거치면서 아래로 내린다.
자신의 위치를 찾을 때까지 내린다.
- HDelete
HData HDelete(Heap * ph) { HData retData = (ph->heapArr[1]).data; // 반환을 위해서 삭제할 데이터 저장 HeapElem lastElem = ph->heapArr[ph->numOfData]; // 힙의 마지막 노드 저장 // parentIdx에는 마지막 노드가 저장될 위치정보가 담긴다. int parentIdx = 1; // 루트 노드가 위치해야 할 인덱스 값 저장 int childIdx; // 루트 노드의 우선순위가 높은 자식 노드를 시작으로 반복문 시작 while(childIdx = GetHiPriChildIDX(ph, parentIdx)) { if(lastElem.pr <= ph->heapArr[childIdx].pr) break; // 마지막 노드의 우선순위가 높으면 반복문 탈출 // 마지막 노드보다 우선순위 높으니, 비교대상 노드의 위치를 한 레벨 올림 ph->heapArr[parentIdx] = ph->heapArr[childIdx]; parentIdx = childIdx; // 마지막 노드가 저장될 위치정보를 한 레벨 내림 } // 반복문 탈출하면 parentIdx에는 마지막 노드의 위치정보가 저장됨 ph->heapArr[parentIdx] = lastElem; // 마지막 노드 최종 저장 ph->numOfData -= 1; return retData; }- 최종 목적지가 결정되면 단번에 마지막 노드를 옮긴다.
- 마지막 노드가 있어야 할 위치를
parentIdx에 저장된 인덱스 값을 갱신해가며 찾아간다.
2-8. 원리 이해 중심의 힙 구현: HInsert
새로운 데이터는 우선순위가 제일 낮다는 가정하에서 ‘마지막 위치’에 저장한다. 그리고 우선순위의 비교를 통해서 자신의 위치를 찾을 때까지 위로 올린다.
- HInsert
void HInsert(Heap * ph, HData data, Priority pr) { int idx = ph->numOfData+1; // 새 노드가 저장될 인덱스 값을 idx에 저장 HeapElem nelem = {pr, data}; // 새 노드의 생성 및 초기화 // 새 노드가 저장될 위치가 루트 노드의 위치가 아니라면 while문 반복 while(idx != 1) { // 새 노드와 부모 노드의 우선순위 비교 if(pr < (ph->heapArr[GetParentIDX(idx)].pr)) // 새 노드의 우선순위가 높다면 { // 부모 노드를 한 레벨 내림, 실제로 내림 ph->heapArr[idx] = ph->heapArr[GetParentIDX(idx)]; // 새 노드를 한 레벨 올림,실제로 올리지는 않고 인덱스 값만 갱신 idx = GetParentIDX(idx); } else // 새 노드의 우선순위가 높지 않다면 break; } ph->heapArr[idx] = nelem; // 새 노드를 배열에 저장 ph->numOfData += 1; }- 새로운 노드가 저장되어야 할 위치 정보를 변수
idx를 통해서 계속 갱신한다.
- 새로운 노드가 저장되어야 할 위치 정보를 변수
2-9. 제법 쓸만한 수준의 힙 구현: 힙의 변경
이전에 구성한 구조체와 함수들에서는 데이터를 입력하기 전 우선순위를 결정하고 그 값을 전달했다.
이는 대부분 데이터를 기준으로 결정되는 우선순위를 직접 결정하는 불편한 과정이다.
프로그래머가 힙의 우선순위 판단 기준을 설정할 수 있도록 변경한다.
- 구조체 변경
typedef struct _heap { PriorityComp * comp; // typedef int PriorityComp(HData d1, HData d2); int numOfData; HData heapArr[HEAP_LEN]; // typedef char HData; } Heap;- 우선순위를 저장하는
HeapElem을 삭제했다. PriorityComp * comp- 두 개의 데이터를 대상으로 우선순위의 높고 낮음을 판단하는 함수를 등록하기 위한 포인터 변수
- 우선순위를 저장하는
- PriorityComp
typedef int (*PriorityComp)(HData d1, HData d2);- 두 개의 데이터를 대상으로 우선순위의 높고 낮음을 판단하는 함수
첫 번째 인자의 우선순위 ≥ 두 번째 인자의 우선순위: 0보다 큰 값이 반환첫 번째 인자의 우선순위 ≤ 두 번째 인자의 우선순위: 0보다 작은 값 반환첫 번째 인자의 우선순위 = 두 번째 인자의 우선순위: 0 반환
- 초기화 함수 변경
void HeapInit(Heap * ph, PriorityComp pc) { ph->numOfData = 0; ph->comp = pc; // 우선순위 비교에 사용되는 함수의 등록 }
2-10. 제법 쓸만한 수준의 힙 구현: 힙의 변경사항 완성
int GetHiPriChildIDX(Heap * ph, int idx);int GetHiPriChildIDX(Heap * ph, int idx) { if(GetLChildIDX(idx) > ph->numOfData) return 0; else if(GetLChildIDX(idx) == ph->numOfData) return GetLChildIDX(idx); else { // if(ph->heapArr[GetLChildIDX(idx)].pr // > ph->heapArr[GetRChildIDX(idx)].pr) if(ph->comp(ph->heapArr[GetLChildIDX(idx)], ph->heapArr[GetRChildIDX(idx)]) < 0) // 두 번째 인자 우선순위가 더 크다. return GetRChildIDX(idx); else return GetLChildIDX(idx); } }
void HInsert(Heap * ph, HData data);void HInsert(Heap * ph, HData data) { int idx = ph->numOfData+1; while(idx != 1) { // if(pr < (ph->heapArr[GetParentIDX(idx)].pr)) if(ph->comp(data, ph->heapArr[GetParentIDX(idx)]) > 0) // 첫 번째 우선순위가 더 높음 { ph->heapArr[idx] = ph->heapArr[GetParentIDX(idx)]; idx = GetParentIDX(idx); } else { break; } } ph->heapArr[idx] = data; ph->numOfData += 1; }
HData HDelete(Heap * ph);HData HDelete(Heap * ph) { HData retData = ph->heapArr[1]; HData lastElem = ph->heapArr[ph->numOfData]; int parentIdx = 1; int childIdx; while(childIdx = GetHiPriChildIDX(ph, parentIdx)) { // if(lastElem.pr <= ph->heapArr[childIdx].pr) if(ph->comp(lastElem, ph->heapArr[childIdx]) >= 0) // 첫 번째 우선수위가 높거나 같음 break; ph->heapArr[parentIdx] = ph->heapArr[childIdx]; parentIdx = childIdx; } ph->heapArr[parentIdx] = lastElem; ph->numOfData -= 1; return retData; }
- main 함수
#include <stdio.h> #include "UsefulHeap.h" int DataPriorityComp(char ch1, char ch2) // 우선순위 비교함수 { return ch2-ch1; } int main(void) { Heap heap; HeapInit(&heap, DataPriorityComp); // 우선순위 비교함수 등록 HInsert(&heap, 'A'); HInsert(&heap, 'B'); HInsert(&heap, 'C'); printf("%c \n", HDelete(&heap)); HInsert(&heap, 'A'); HInsert(&heap, 'B'); HInsert(&heap, 'C'); printf("%c \n", HDelete(&heap)); // A while(!HIsEmpty(&heap)) printf("%c \n", HDelete(&heap)); // A B B C C return 0; }- 아스키 코드 값이 작은 문자의 우선순위가 더 높다.
2-11. 제법 쓸만한 수준의 힙을 이용한 우선순위 큐의 구현
✔️ ADT
void PQueueInit(PQueue * ppq, PriorityComp pc);- 우선순위 큐의 초기화
- 우선순위 큐 생성 후 제일 먼저 호출되어야 하는 함수
int PQIsEmpty(PQueue * ppq);- 우선순위 큐가 빈 경우 TRUE(1), 그렇지 않은경우 FALSE(0) 반환
void PEnqueue(PQueue * ppq, PQData data);- 우선순위 큐에 데이터 저장
PQData PDequeue(PQueue * ppq);- 우선순위가 가장 높은 데이터를 삭제
- 삭제된 데이터 반환
- 본 함수의 호출을 위해서는 데이터가 하나 이상 존재함이 보장되어야 한다.
- 헤더파일
#ifndef __PRIORITY_QUEUE_H__ #define __PRIORITY_QUEUE_H__ #include "UsefulHeap.h" typedef Heap PQueue; typedef HData PQData; void PQueueInit(PQueue * ppq, PriorityComp pc); int PQIsEmpty(PQueue * ppq); void PEnqueue(PQueue * ppq, PQData data); PQData PDequeue(PQueue * ppq); #endif
- 소스파일
#include "PriorityQueue.h" #include "UsefulHeap.h" void PQueueInit(PQueue * ppq, PriorityComp pc) { HeapInit(ppq, pc); } int PQIsEmpty(PQueue * ppq) { return HIsEmpty(ppq); } void PEnqueue(PQueue * ppq, PQData data) { HInsert(ppq, data); } PQData PDequeue(PQueue * ppq) { return HDelete(ppq); }
- main 함수
#include <stdio.h> #include "PriorityQueue.h" int DataPriorityComp(char ch1, char ch2) { return ch2-ch1; } int main(void) { PQueue pq; PQueueInit(&pq, DataPriorityComp); PEnqueue(&pq, 'A'); PEnqueue(&pq, 'B'); PEnqueue(&pq, 'C'); printf("%c \n", PDequeue(&pq)); PEnqueue(&pq, 'A'); PEnqueue(&pq, 'B'); PEnqueue(&pq, 'C'); printf("%c \n", PDequeue(&pq)); // A while(!PQIsEmpty(&pq)) printf("%c \n", PDequeue(&pq)); // A B B C C return 0; }
참고: 윤성우의 열혈 자료구조
