https://hyungjung-lee.github.io/ai-ml/listen-attend-and-spell/
Introduction
LAS는 HMM 기반 기존 음성 인식 시스템과 달리 END-to-end연산. 거의 최초! 오
Speller, listener
hidden state로 연결
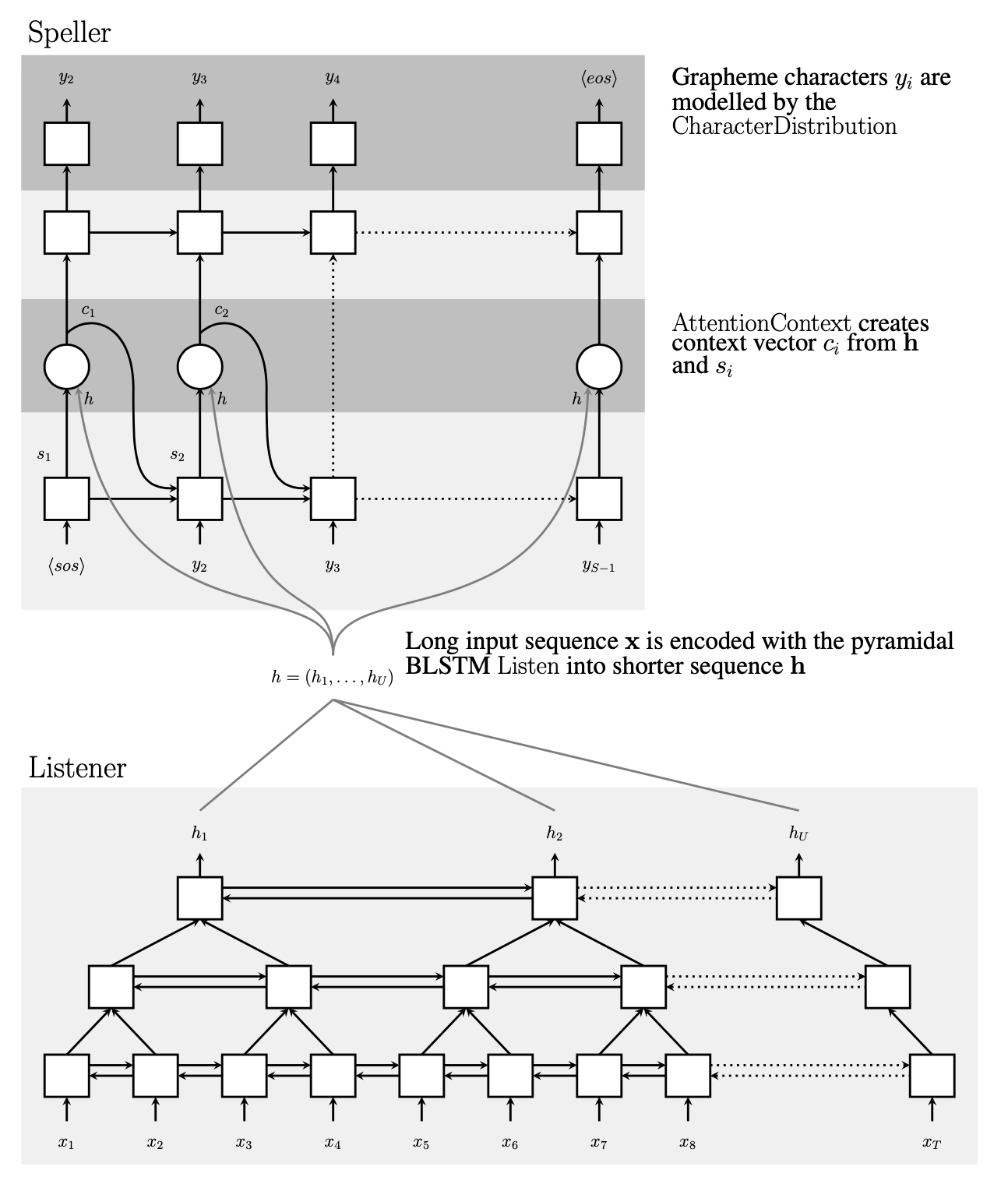
-
lister
- bilstm 기본으로 사용
- 어텐션 파라미터 줄이려고 차원을 한번씩 줄인다
=> 그럼 기본 정보가 소실되지 않을까? 지금이었으면 add 한번 해줬을 듯 (아 이전 PASE 논문 처럼!)
-
speller

이 전모델은 Dictionary에서 가져왔는데, 여기서는 이전 컨텍스에서 가져온다.근데 음소가 한정되어있으면 DICTIONARy에 다 넣어도 되는거 아냐?
-
Attend

position은 옛날이라서 없는듯. POSition 넣게된 이유는 matrix 계산해서 없는것. LSTM자체가 시간 순서.
-
Learning

단어 하나를 전 step보고 생성
과적합 막으려고 NOISe 줌
논문에서는 해당 구조가 깊은 deep learning structure 를 갖기 때문에 기존 GMM-HMM 을 통해 사전학습이 필요한지에 대해 확인하기 위해 실험을 했지만 improvement가 없었다고 한다.
사전 학습을 했다는건 초기값을 정해놨다는 건가?
- Decoding
- Rescoring
- 점수 주는 방식 빔 서치 위해서.
- 추가로 언어모델 사용.
그럼 따지면 asr 수식이랑 똑같은거 아닌가?!
experiments
노이즈 섞어서 20배 양 불렸다
40dim log-mel filter bank로 변경, 10ms 단위로 acoustic inputs 만들었다.
- 학습: Asynchronous stochastic gradient descent 적용
position이 필요없었다. 왜? 이게 뭔뜼? sequence에 따라 유사한 곳에 출력되었다?
lstm 때문 아니야?
-
Beam search width 차이 32개일 때 좋았다.
- oracle 많이쓰든디! 최적인값
-
lstm 깊이가 궁금인데
-
발화 길이
- error 현상 별로 성능비교?
- 단어수가 많아지면서 에러가 높아진다. 발아가 길어질 수록 높아진다.
중간에 저렇게 뚝 떨어지는 곳은 왜지왜지왜지??
-
word frequency?
- 빈번한 단어면 정확도가 높다.
- and, in은 frequency가 높은데도 잘 못함. 아 발음상 특징이 잘 없어서. 오오
- 한번 밖에 안나온 단어는 특이해가지고 잘나왔다.
=> 어떤 발음의 차이일지 궁금하다!! 특징이 없다는게 구분이 안간다는건데 된소리 이런거?
- 포지션..? 그게 그렇게 해석하는게 맞을까?! 문맥을 이해했다..?!?!!?!? 그건 lstm 때문...?
트리플에이인데 aaa로 했다.. .이건 그럼 틀린거 아니야?!?!??!?! 들리는 대로 해야하는 거 아냐 학습도 그렇게 한거잖아...
limitation
language model 사용하면 좋았을 것 같은데 자원적인 문제가 있어서 못했다. 같이 학습을 하면
이게 무슨뜻이지?
