Summary
- Background :
- BERT 같은 대규모 Language model (LM)이 NLP task에 좋은 성능을 보이고 있다.
- 하지만 knowledge graph (KG)를 통합하려는 시도는 잘 없었다.
- KG는 풍부한 structured knwledge를 제공해 language understanding에 도움이 된다.
- Challenge (KG를 잘 incorporating하기 위한):
- (1) Structured Knowledge Encoding: text에서 유용한 정보를 extract하고 encoding
- (2) Heterogeneous Information Fusion: language representation과 KG representaion 통합
- Approach:
- KG 내의 informative entities들을 이용하면 더 좋은 language representation을 뽑을 수 있을 것이다.
- Large-scale textual corpora와 KG를 둘다 사용해서 LM을 학습시켜, lexical 뿐만 아니라 knowledge information도 활용한다.
- Result:
- knowledge-driven task에서 좋은 성능을 보임.
- 여타 NLP task에서 BERT와 견줄만한 성능을 보임.
paper: https://aclanthology.org/P19-1139.pdf
github: https://github.com/thunlp/ERNIE
huggingface : https://huggingface.co/docs/transformers/model_doc/ernie
Background
# Pretrained Language model Familiy
(Ref : Liu, Z., Lin, Y., & Sun, M. (2020). Representation learning for natural language processing (p. 334). Springer Nature.)
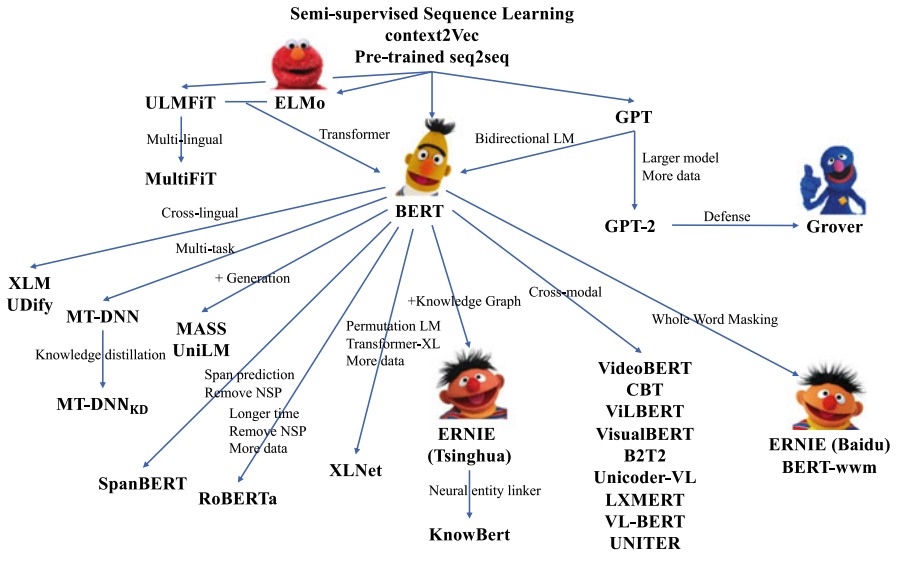
# Tsinghua's ERNIE vs Baidu's ERINE
| - | Tsinghua | Baidu |
|---|---|---|
| 연구목적 | knowledge Graph를 LM에 효과적으로 접목 | Tsinghua와 동일 |
| 인용횟수 (22.11.16 google scholar 기준) | 850회 | 584회 |
| 모델 | text와 knowledge entities 각각 embedding 뽑아서 fusion | BERT와 학습 방법은 동일하나 masking 과정에서 단어만 masking하지 않고 phrase 단위, entity 단위로 masking 하여 학습 (=knowledge masking) |
- *현재는 Baidu에서 ERINIE 2.0, 3.0 버전까지 출시
- ERNIE 1.0 : Enhanced Representation through Knowledge Integration (arxiv, 2019)
- ERNIE 2.0: A Continual Pre-training Framework for Language Understanding (AAAI, 2020)
: 여러가지 task를 동시에 학습하는 continual multitask training framework 제안 - ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation (arxiv, 2021)
: Task specific representation, Large-scale
Introduction
# Background
- Text 데이터에서 language information을 포착하기 위해 많은 시도들이 있어왔다.
- feature based approaches:
- fine-tuning based approaches :
- 특히, BERT는 다양한 NLP task에서 좋은 성과를 보이고 있다.
# 기존 연구 한계점
- language understanding을 위해 knowledge information을 통합하는 것을 고려한 경우는 없었다.
- 기존 LM 모델들은 entity를 UNK로 봐버린다.
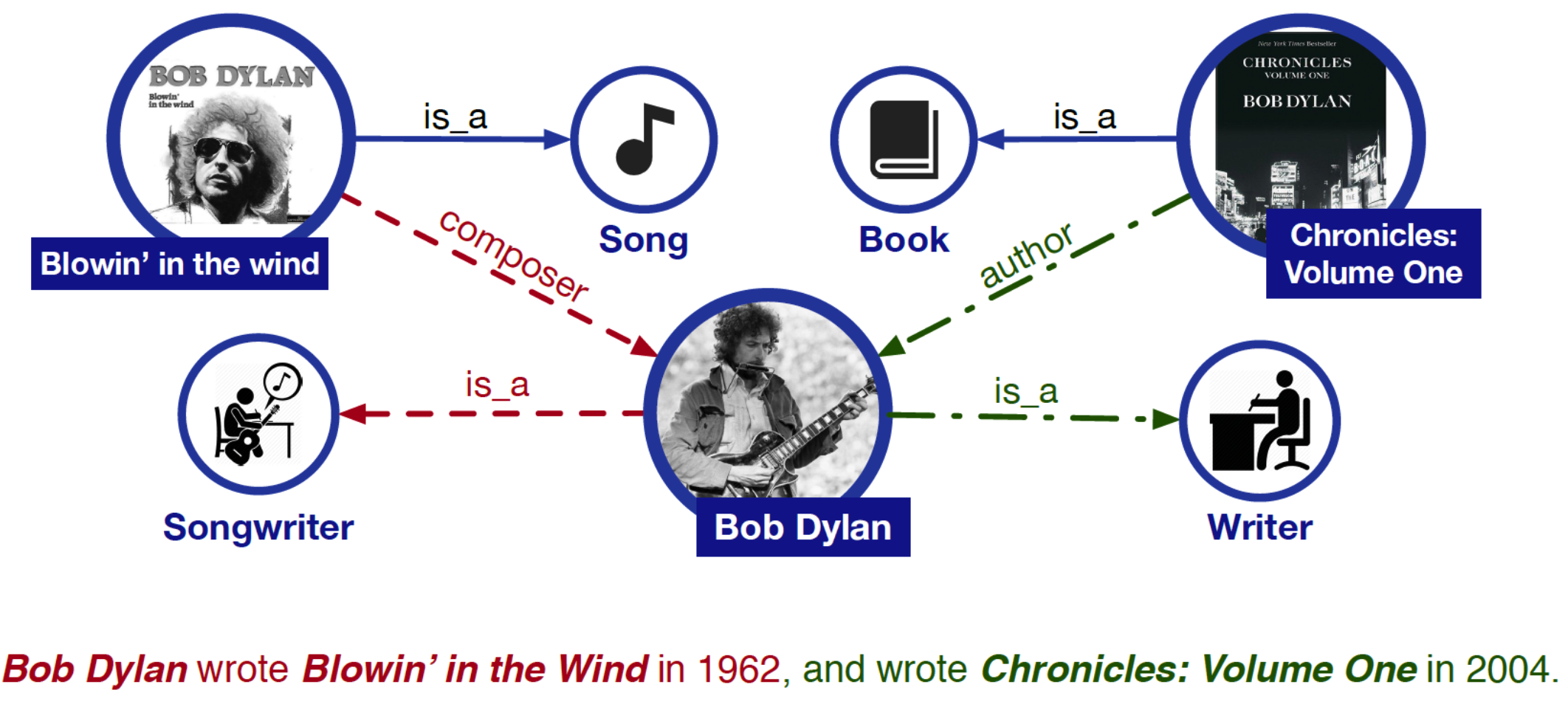
Example
- 아래 문장에서 "Blowin' in the Wind"는 음악이고, "Chronicles: Volumne one"은 책이라는 사전지식이 없다면, 해당 문장만 보고 Bob dylan이 작곡가인지, 작가인지 아니면 둘 다인지 파악하기 어려움.
- 해당 문장만을 가지고 relation classification task를 한다고 했을 때, composer와 author의 relation을 맞추라고 하면 아예 정보가 없기 때문에 둘 간의 relation을 뽑기는 거의 불가능.
# KG를 LM에 잘 통합하기 위한 Challenge
- Structured Knowledge Encoding :
text에서 KG안에 있는 정보와 연결될 entity를 어떻게 뽑을 것이며, 어떻게 그걸 잘 encoding해서 language representation을 뽑는데 도움을 줄 것인가?
- Heterogeneous Information Fusion:
language representation을 뽑는 것과 knowledge representaion을 training 시키는 과정이 다르기 때문에 둘은 서로 다른 vector space에 존재한다. 그렇다면 어떻게 lexical, syntactic, knowledge information을 효과적으로 fuse할 수 있는 objective function을 디자인할 것인가?
# Approach
- KG와 large corpora를 함께 학습시킨 pre-trained LM 개발!
=> We call this "ERNIE" (Enhanced Language Representation with Informative Entities)
- knowledge information extract 및 encoding:
(1) text에서 NER 뽑은 후 대응하는 KG 내 entities와 연결(align)하기
(2) knowledge embedding 알고리즘인 TransE (Bordes et al., 2013) 사용하여 KG의 graph structure encoding함.
(3) 여기서 나온 informative entity embeddings를 ERNIE input으로 사용
(4) text와 KG간에 alignment를 바탕으로 ERNIE는 entity representation과 language representation을 통합함. - New Masked LM & Nex Sentence Prediction for training:
(1) input text에서 random하게 entity를 골라 masking한 후 모델에게 적절한 entity를 KG에서 고르게 한다.
(2) 해당 방식은 기존의 BERT 방식과 다르게 local context만 보지 않고 context와 knowledge facts 둘다 고려하게 함으로써 knwledgeable language represention model을 구축한다.
# Evaluation
- Task : Knowledge-driven NLP task
- Entity typing
- Relation classification
- Result
- ERNIE > BERT on knowledge-driven task
- ERNIE ~= BERT on other common NLP task
Related work
NLP 모델 중에서 feature based, fine-tuning based approaches 많이들 있는데 KG 잘 통합한 연구는 없었다.
Methodology
# Notations
- token sequence: {w_1, ..., w_n}, w \in V (n: token sequence 길이)
- entity sequence: {e_1, ..., e_m}, e \in E (m: entity sequence 길이)
- n != m ; 모든 token이 KG의 entity와 align 되는 건 아니라서.
- alinement: f(w) = e
# Model Architecture
- Overall Framework : (1) Textual Encoder (2) Knowledgable Encoder
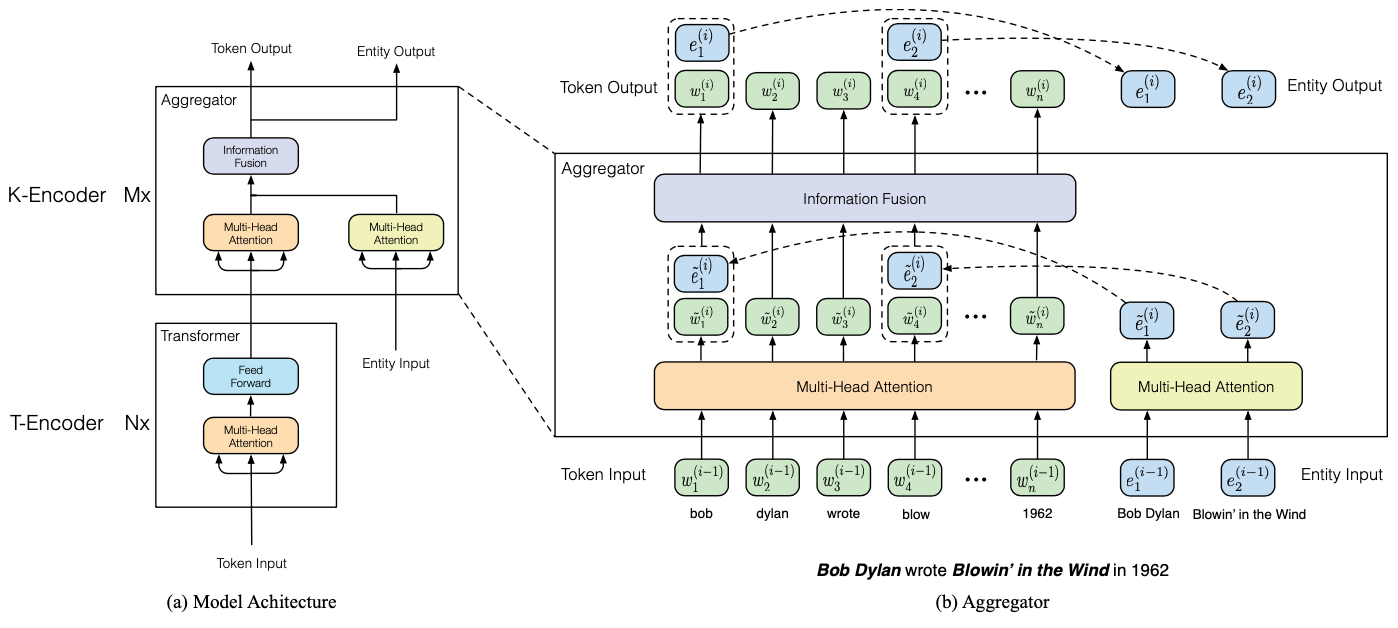
# Textual Encoder (T-Encoder)
-
T-Encoder : multi-layer bidirectional Transformer encoder (= N x transformer)
-
input embedding = token embedding + segment embedding + positional embedding
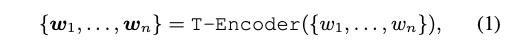
-
- entity 의 embedding은 TransE 알고리즘을 사용하여 출력
TransE
엔티티(head, tail)를 저차원의 임베딩으로 표현하기위해 학습하는 모델
- entity 의 embedding은 TransE 알고리즘을 사용하여 출력
# Knowledgeable Encoder (K-Encoder)
-
Overall
- K-Encoder : multi-layer multi-head attention + information fusion (=M x aggregator)
- 최종 output인 w^0, e^0 는 specific task를 할 때 사용(논문 figure에서는 next token 맞추기에 사용)
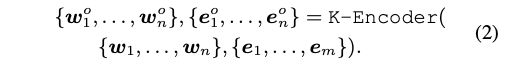
-
Detail
-
Multi-head attention : input embedding w와 e를 각각 multi-head attention에 입력. (첫 layer 이후에는 전단계에서 출력된 embedding을 input으로 받는다.)
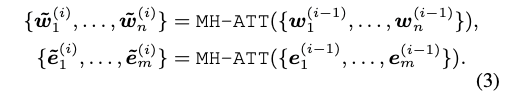
-
Information Fusion
- token과 aligned된 entity가 있을 때:
- mh-att에서 출력된 embedding을 sum하여 integrating한 hidden state h를 만든다.
- h를 이용해 다음 step의 token 및 entity를 구한다.
- sigma : non-linear activation function (GELU 사용)
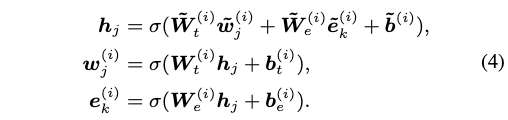
- token과 aligned된 entity가 없을 때:
- 만약 대응되는 entity가 없다면 sum하는 부분만 빼고 나머지는 동일
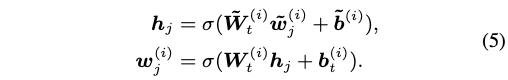
- 만약 대응되는 entity가 없다면 sum하는 부분만 빼고 나머지는 동일
- token과 aligned된 entity가 있을 때:
-
i번째 Aggregator 수식:
- 이걸 m번 하면 K-encoder (=2번 수식)
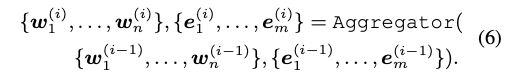
- 이걸 m번 하면 K-encoder (=2번 수식)
-
# Pre-training for Injecting Knowledge
- Goal: language representation에 knowledge injecting하기!
- Method : alingn된 token-entity 쌍이 있으면, entity를 masking해서 model한테 token만 보고 관련된 entity를 KG에서 찾아라! 훈련 시키기. (a.k.a denoising auto-encoder (dEA))
- (1) 5%:entity를 임의의 entity로 바꿔서 모델이 이를 바로 잡도록 학습
- (2) 15%: token-entity alignment를 골라서 entity를 masking 해서 token과 관련된 entity 찾도록 학습
- (3) 나머지(80%): masking 따로 하지 않고 token과 entity embedding을 잘 합쳐서 language representation 잘 뽑도록 학습
- Pre-traing Task:
- Masked language model (MLM), Next sentence prediction (NSP):
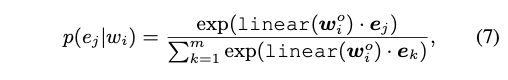
- Masked language model (MLM), Next sentence prediction (NSP):
- Objective function: cross-entropy
# Fine-tuning for Specific Tasks
- For relation classification
- Goal : 주어진 entity pair들의 relation을 맞춰라!
- Method : head entities와 tail entities 앞에 [HD], [TL] token을 추가해서 위치를 알려주고, 마지막에 [CLS] token의 임베딩을 사용해서 relation 맞추기.
- 고전 방식은 그냥 [CLS] 토큰만 사용 (figure에서 가장 위에 예시)
- For entity typing
- Goal : entity가 어떤 종류인지 맞춰라!
- Method : entity 앞에 [ENT] 토큰 추가해서 entity 위치 알려주기
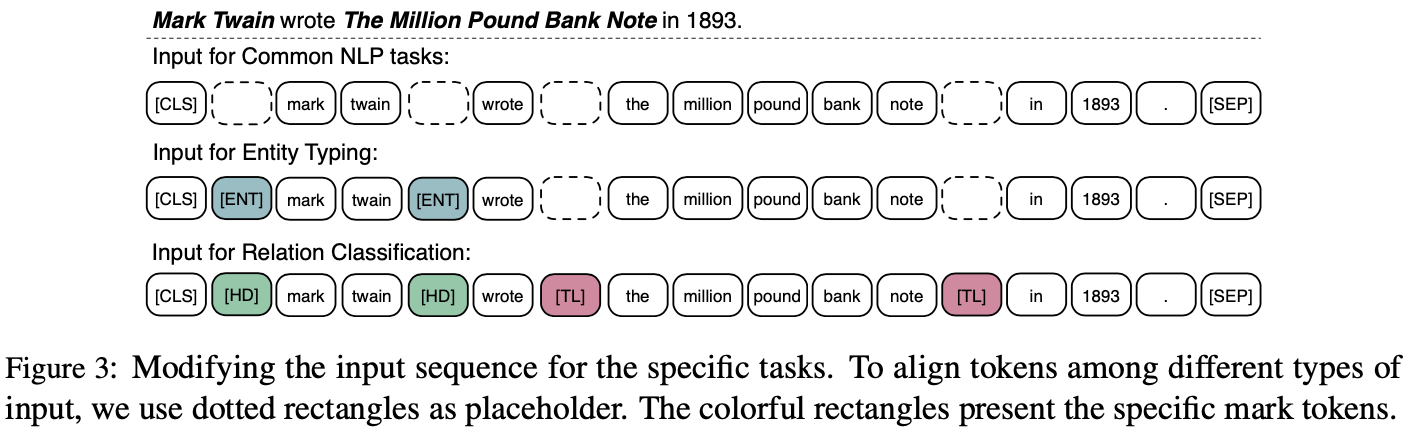
Experiments
# Pre-training Dataset
- parameter setting은 BERT와 동일
- Wiki 데이터 사용
- Wiki 데이터로 훈련된 TranE의 knowledge embedding 사용
# Fine-tuning Task 1: Entity Typing
-
Dataset: FIGER, Open Entity (둘다 human이 manual하게 annotation했다고 함)
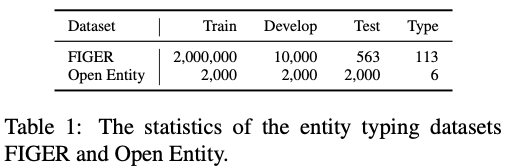
-
Baselines
- NFGEC (Shimaoka et al., 2016) : FIGER의 SOTA 모델, entity mention represention, context, extra hand-craft feature 들을 다 combine하여 사용
- UFET (Choi et al., 2018) : Open Entity의 SOTA 모델, bi-LSTM 사용
- BERT
-
Result
- FIGER를 이용한 baseline에서는 wrong label로 계속 학습하는 noisy label 문제가 있었는데, ERNIE는 KG에서 얻은 정보를 잘 주입함으로써 이를 개선함. Open Entity에서는 SOTA 달성
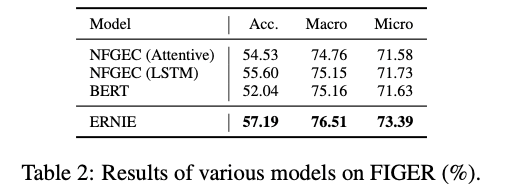
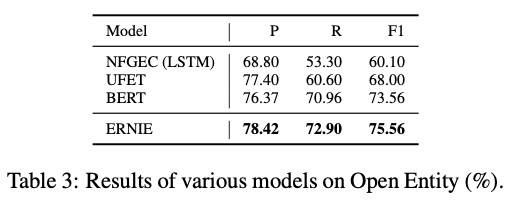
- FIGER를 이용한 baseline에서는 wrong label로 계속 학습하는 noisy label 문제가 있었는데, ERNIE는 KG에서 얻은 정보를 잘 주입함으로써 이를 개선함. Open Entity에서는 SOTA 달성
# Fine-tuning Task 2: Relation Classification
-
Dataset: FewRel은 few-shot learning setting임
-
Baselines
- CNN
- PA-LSTM (Zhang et al., 2017): position-aware attention mechanism
- C-GCN (Zhang et al., 2018): dependency tree 모델링해서 GCN 사용
- BERT
-
Result
- KG를 사용함으로써 적은 데이터로도 모델 학습을 할 수 있게한다.

- KG를 사용함으로써 적은 데이터로도 모델 학습을 할 수 있게한다.
# GLUE
- Dataset: GLUE benchmark
- 다양한 NLP task로 evaluation하려고
- Result
- BERT랑 비슷한 결과 도출, 이를 통해 information fusion을 하여도 textual information을 손실하지 않음.
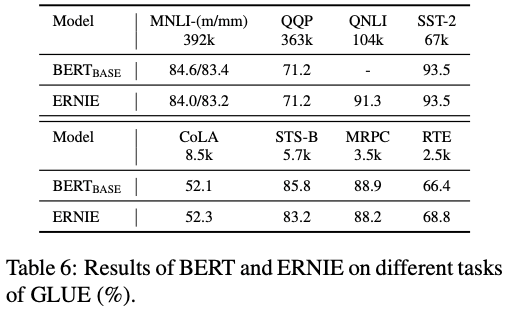
- BERT랑 비슷한 결과 도출, 이를 통해 information fusion을 하여도 textual information을 손실하지 않음.
# Ablation Study
- Goal: information fusion (entity), dEA가 미치는 성능 평가
- Result
- 해당 component 없으면 BERT와 성능 비슷하지만, 추가 되었을 때 성능 좋음.
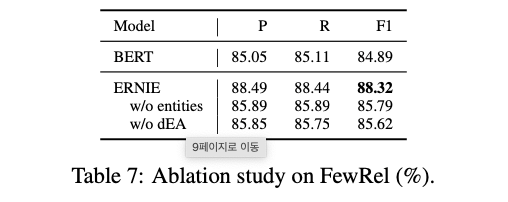
- 해당 component 없으면 BERT와 성능 비슷하지만, 추가 되었을 때 성능 좋음.
Conclusion
- LM 모델에 Knowledge information을 잘 통합하기 위해 모델 제안
- entity를 token과 alignment하여 pre-training 하는 방법 제시
- information fusion을 통해 heterogeneous information 잘 통합
- knowlegable task에서 좋은 성능을 보여주었음.
- few-shot learning setting에서 데이터가 적어도 Knowledge 정보를 활용하면 좋은 성능을 보여줄 수 있다는 것을 입증.
Implementation

누렁이님 블로그 잘 보고 있습니다 ^^ 활발한 업데이트 기대할게요 ~ !