Summary
- background :
- QA system은 크게 (1) retrieval (2) reading comprehension 으로 이루어져 있음. 이 논문은 (1) retrieval에 집중!
- 기존 open-domain question answering은 sparse vector space에서 후보 답변을 어떻게 잘 retrieval (검색) 하느냐에 따라 성능이 좌지우지 됐다. (TF-IDF, BM25)
- goal : dense representation을 사용하여 효과적으로 retrieval하기
- result : a strong LuceneBM25 system을 9~19%로 retrieval accuracy 성능 높음.
- contribution : code와 dataset 공개 (https://github.com/facebookresearch/DPR)

Introduction
- Background
- simplified framwork
- 기존 QA system들은 복잡하고, 여러 components들이 포함되어 있었다.
- 하지만, 최근에는 simplified two-stage framework 제안하는 경우가 많다.
- (1)
Retriever: 검색 기반 시스템, question의 답변에 해당하는 passages subset을 선택 - (2)
Reader(Reading Comprehension): 검색 기반으로 좁혀진 document candidates에서 machine이 context를 파악하고, 정확한 답변을 identify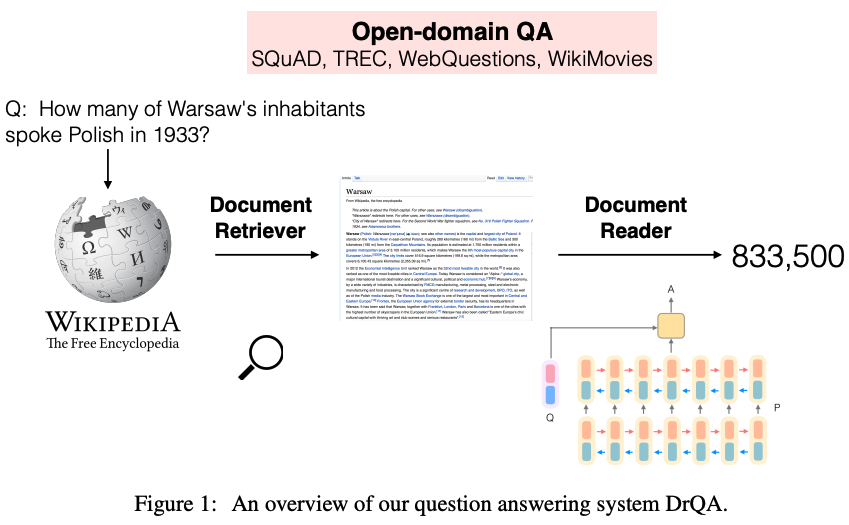
Chen, D., Fisch, A., Weston, J., & Bordes, A. (2017, July). Reading Wikipedia to Answer Open-Domain Questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1870-1879).
- (1)
- the needs of improving retrieval
- machine reading 방식으로 바꾸는 것이 reasonable하지만 성능은 매우 떨어짐 (80 -> 40%)
- Retrieval in dense vectors
- 이제까진 주로 tf-idf 같이 sparse vector 이용해서 keyword mathing 방식 등을 이용함. (high demension이니까 효율 낮겠지?) dense vector는 sparse vector 단점을 보완
- (1) 맥락 파악 good: term-base system 들은 동의어로 쓰였을 때 맥락 잘 파악 못할 수 있음
Q : "Who is the bad guy in lord of the rings?"
A : "Sala Baker is best known for portraying the villain Sauron in the Lord of the Rings trilogy." - (2) Learnable : 학습을 통해 embedding을 조정할 수 있다. ( => task specific representaion 가능)
- simplified framwork
- Limitation
- a large number of labeled pairs of question and contexts : Dense retrieval methods는 많은 데이터가 필요해서 tf-idf 등을 이용한 QA 시스템 성능을 뛰어넘지 못한다.
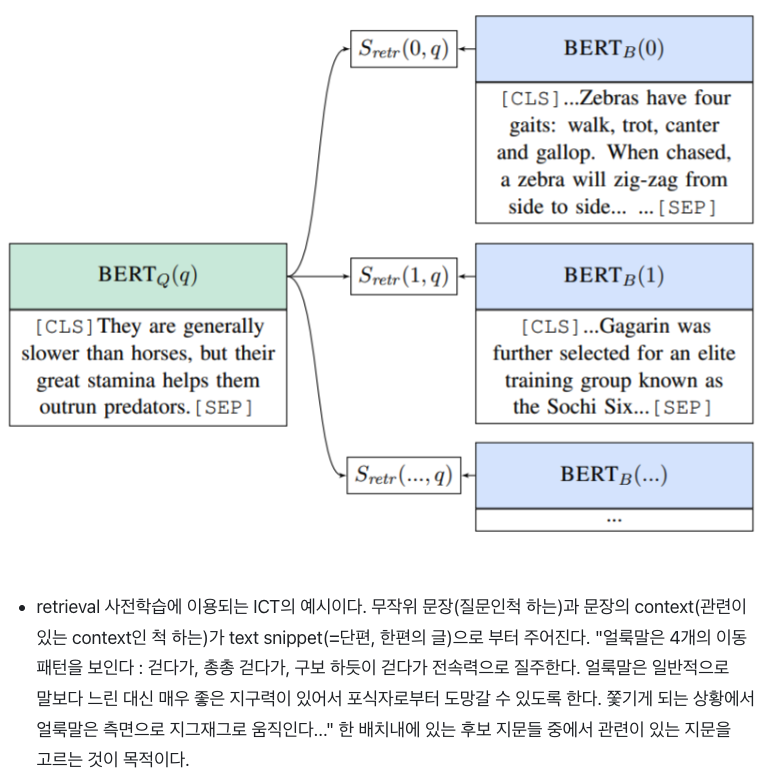
- DNN기반의 ORQA (Lee et al., 2019) 는 Inverse cloze task (ICT)에서 BM25 성능을 넘었지만 단점 존재
- (1) ICT 사전학습 방법은 계산량이 많고, 질문을 대체할 만한 pseudo-question들 한계 있음
- (2) context encoder가 fine tuning할 때 질문-답변 쌍을 사용하지 않기 때문에, 생성된 답변이 최적화 됐다고 할 수 없음.
Inverse cloze task (ICT) : 다른 랜덤 옵션들 사이에서 올바른 context를 예측
https://velog.io/@sangmandu/Latent-Retrieval-for-Weakly-SupervisedOpen-Domain-Question-Answering
Lee, K., Chang, M. W., & Toutanova, K. (2019, July). Latent Retrieval for Weakly Supervised Open Domain Question Answering. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 6086-6096).
- Research Question :
- Can we train a better dense embedding model using only pairs of questions and answers without additional pretraining?
- Goal :
- Developing the right training scheme using a relatively small number of question and passage pairs.
- Approach :
- Dense Passage Retriever (DPR) (BERT pretrained model + a dual-encoder architecture)
- Result :
- embeddings은 배치 안에서 모든 pair들을 비교하면서 question과 relevant passage vector의 inner product를 최대화 하면서 최적화 화더라.
- BM25 뿐만 아니라 ORQA도 결과 뛰어 넘음.
- Contribution :
- 심플한 fine-tuning 방식으로도 훌륭한 성능 도출
- we demonstrate that with the proper training setup, simply fine-tuning the question and passage encoders on existing question-passage pairs is sufficient to greatly outperform BM25.
- Our empirical results also suggest that additional pretraining may not be needed.
- multiple QA dataset에서 좋은 성능을 보임
- We verify that, in the context of open-domain question answering, a higher retrieval precision indeed translates to a higher end-to-end QA accuracy. By applying a modern reader model to the top retrieved passages, we achieve comparable or better results on multiple QA datasets in the open-retrieval setting, compared to several, much complicated systems.
- 심플한 fine-tuning 방식으로도 훌륭한 성능 도출
Dense Passage Retriever (DPR)
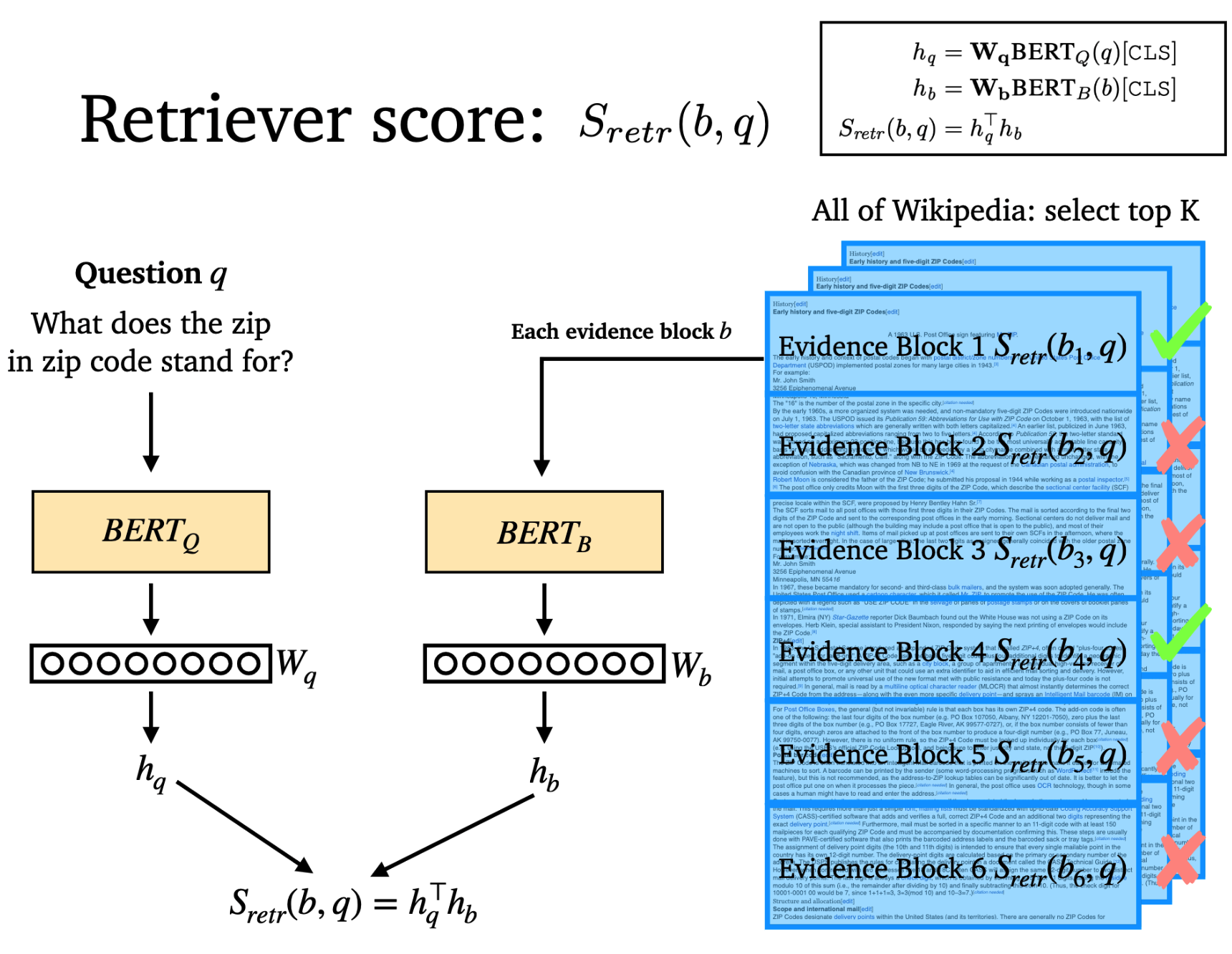
- Goal: M개의 text passages가 있을 때 DPR로 모든 passage를 low-dimensional space로 indexing하기. 그러면 input question과 관련된 top k passage를 retrieve하기 편리해진다. (M은 보통 21 million 개, k는 20-100개)
Overview
- 이 연구에서 reader 부분은 논외임! 참고용으로 사진만 첨부
https://github.com/danqi/acl2020-openqa-tutorial/blob/master/slides/part5-dense-retriever-e2e-training.pdf
- 1) E_P(p) : dense encoder - text passage를 d-dim으로 mapping하고 index를 build. 이 index는 retrieval에 사용.
- 2) E_Q(q) : dense encoder - input question을 d-dim으로 mapping. 여기서 나온 question vector를 이용해서 해당 vector와 가장 가까운 k개의 passage들을 retrieve한다.
- 3) sim(q,p) : question과 passage간 유사도 계산. 다른 복잡한 유사도 계산법이 있지만, 다음과 같이 분해가 가능해야(decomposable) 따로 떼어서 passage들의 representation들을 미리 계산해 놓을 수 있다. (자기들이 실험해봤을 때 성능들이 다 비슷해서 가장 간단한 inner product function을 고름).
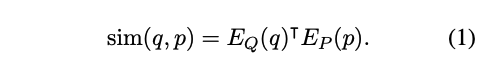
Encoders
- 2개의 independent한 prtrained BERT (base, uncased) 사용
[cls]token 사용 (d=768)
Inference
- E_P(p)로 모든 passage encoding하고 FAISS를 이용해서 indexing한다.
- 학습 시킨 E_Q(q)이용해서 question의 임베딩 v_q를 구하고, v_q와 가장 가짜운 top k개의 passage를 뽑는다.
FAISS : open-source library for similarity search and clustering of dense vectors https://github.com/facebookresearch/faiss
Facebook에서 만든 vector 유사도 구하는 library. L2 거리 (가장 작은값) 또는 내적 연산 (가장 큰값) 을 기반으로 유사한 벡터를 계산 https://beausty23.tistory.com/203?category=536818
Training
-
Training the encoders' Goal : 관련된 question과 passage embedding의 거리가 관련없는 pair의 거리에 비해 최소화될 수 있는 vector space를 creat하는 것! 그럼 the dot-product similarity (eq 1)가 good ranking function이 될 수 있다.
-
Training data: m개의 instances들로 이루어진 training 데이터 D. 여기서 한개의 instance는 한개의 question q_i와 한개의 relevant paggage p_i(+), n개의 irrelevant passages p_i(-)들로 이루어져있다.
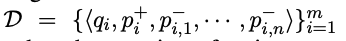
-
Objective Function
- relevant pair의 sim은 크고, irrelevent pair의 sim은 작게 해서 log의 진수의 값을 1로 맞춘다. 그럼 loss는 0
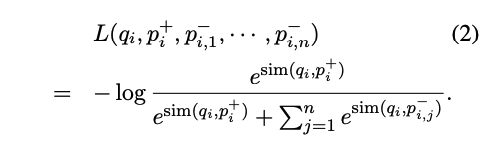
- relevant pair의 sim은 크고, irrelevent pair의 sim은 작게 해서 log의 진수의 값을 1로 맞춘다. 그럼 loss는 0
-
Positive and negative passages (어떻게 negative sample을 고를 것인가?)
- (1) random : any random passage from the corpus
- (2) BM25: top passages returned by BM25 which don't contain the answer but match most question tokens
- (3) Gold: positive passage paired with other questions which appear in the training set
- 뒷 장에서 실험 결과 같은 batch 안에서 gold passage를 negative로 고른 게 효과 좋았음.
-
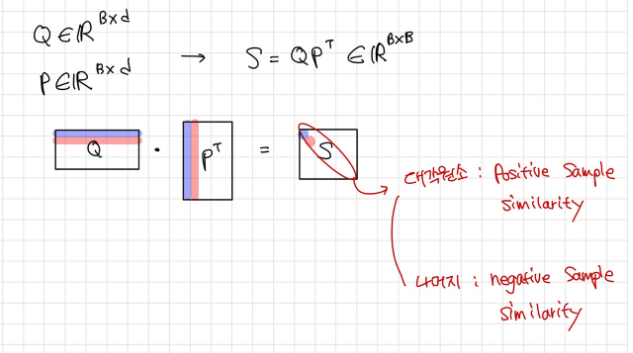
In-batch negatives
- minibatch에 B개만큼의 question과 relevant passage가 있다고 할 때, B-1개의 negative passage가 생긴다. (Gold 방식을 적용해본다면)
- 그럼 결과적으로 B^2의 training sample이 생기고, 이를 이용해서 training을 하게 된다.
- Q와 P는 각각 (BXd), similiary (BXB) q와 p를 모두 쌍쌍 지어본다면 BXB 개가 됌.
- Q와 P는 각각 (BXd), similiary (BXB) q와 p를 모두 쌍쌍 지어본다면 BXB 개가 됌.
Experimental Setup
Wikipedia Data Pre-processing
- answering question의 source data : English Wikipedia (2018년 12월 20일 자)
- 전처리
- DrQA의 코드 사용
- 전체 text : title [SEP] body
Question Answering Datasets
- ORQA 논문과 데이터셋 및 setting 동일하게 한다.
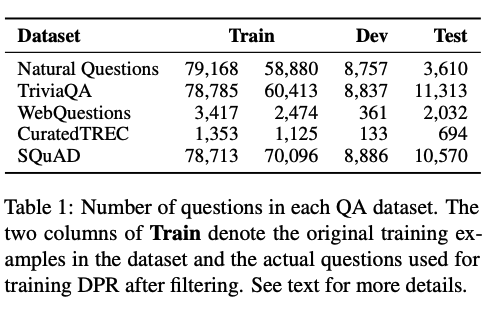
- NQ : google search queries와 wiki에서 관련 answer 찾은 거 annotation
- TriviaQA : web에서 scrap한 trivia question & answer (일반 상식 같은 가벼운 퀴즈)
- WQ : google suggest API사용해서 qusetion뽑고, Freebase에서 정답 entities 뽑음
- TREC : TREC QA tracks에서 question 가져옴 (web source). open-domain QA from unstructured corpora
- SQuAD v1.1 : reading comprehension benchmark dataset. wiki에서 질문 답
Experiments 1: Passage Retrieval
- evaluate the retrieval performance of DPR
- setting
- batch size : 128
- in-batch negative setting
- one additional BM25 negative passage per question (DPR + BM25) - 기본 gold setting에서 추가로 하나 더 negative passage 추가한다는 듯..???
- multi-dataset encoder : combining training data from all datasets excluding SQuAD.
Main Results
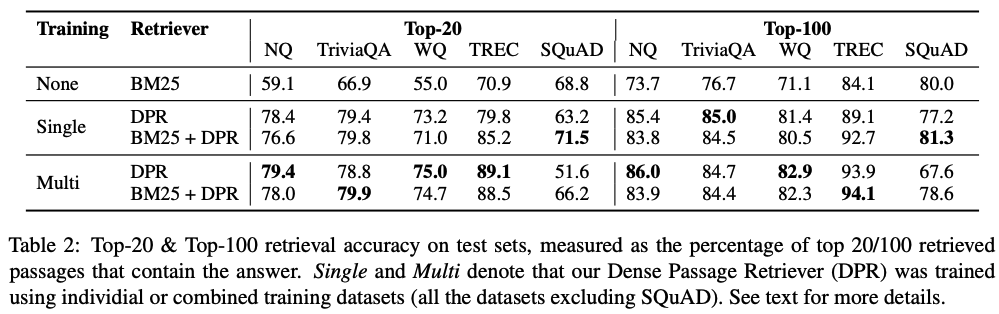
- DPR이 BM25보다 성능 높고, k가 작으면 gap 더 커짐.
- DPR + BM25 성능 높아짐.
- SQuAD에서 성능이 안 좋은 이유 추측
- 데이터셋 자체를 만들 때 답변을 본 후 질문을 만들었기 때문에 겹쳐 있는 단어가 많을 것. 단어 기반으로 하는 BM25가 advantage있음.
- 데이터셋이 500개 정도의 article에서 가져와서 training 데이터의 distribution이 bias 있을 것.
Ablation Study on Model Training
-
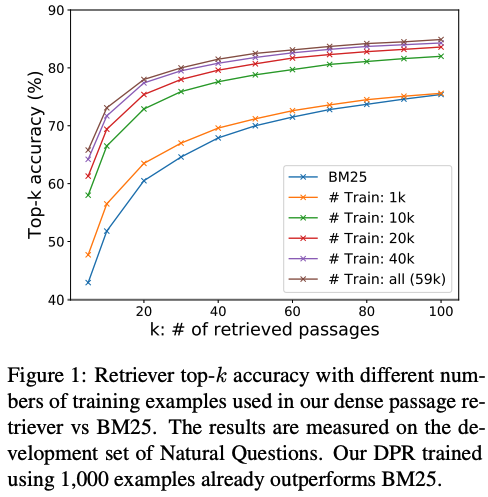
Sample efficinecy
- 얼마나 많은 데이터셋이 필요할까?
- 1000개만 있어도 이미 BM25를 뛰어 넘는다.
-
In-batch negative training
- training 방식 별로 비교
- in-batch negative training 방식 good
- memory-efficient, easy => 새로 데이터셋 만들지 않고 batch안에서 reuse하기 때문
- 첫번째 block의 gold-7과 중간 block의 gold-7 차이 => 전체 set에서 negative 찾기 Vs. mini batch 에서 negative passage찾기임.
- batch사이즈가 높아지면 성능도 높아짐.
- BM25 : given question에 대해 BM25에서 가장 score가 높은 친구를 'hard' negative passage로 추가 (same batch안에서 모든 question들에게 negative passage로 사용) (그럼 중복이 두개야? 잘 이해가 안가는 걸?)
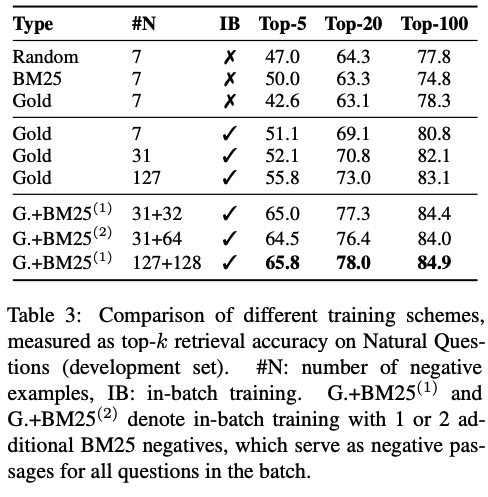
- BM25 : given question에 대해 BM25에서 가장 score가 높은 친구를 'hard' negative passage로 추가 (same batch안에서 모든 question들에게 negative passage로 사용) (그럼 중복이 두개야? 잘 이해가 안가는 걸?)
-
Impact of gold passages
- Appendix A 참고
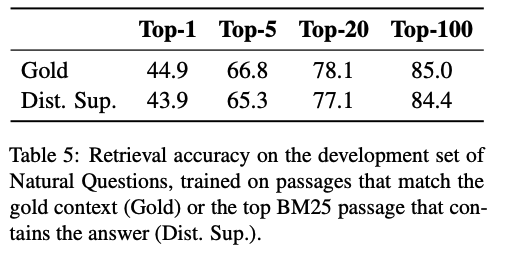
- Appendix A 참고
-
Similarity and Loss
- Appendix B 참고
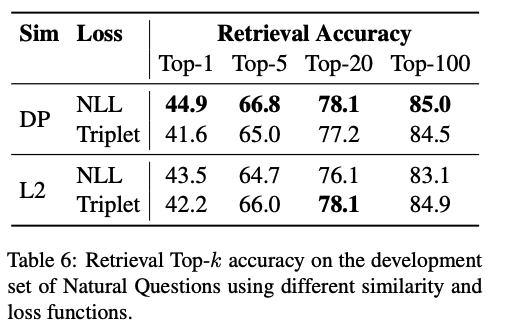
- Appendix B 참고
-
Cross-dataset generalization
Qualitative Analysis
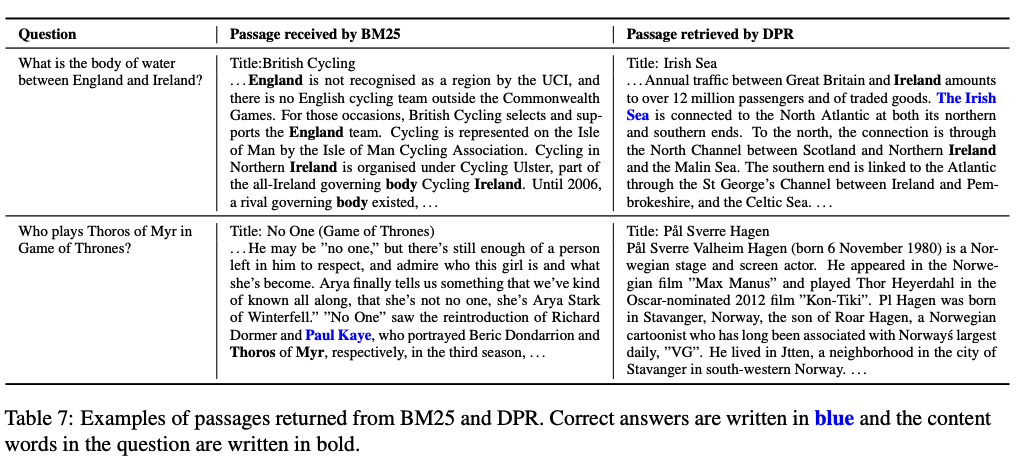
Run-time Efficiency
Experiments 2: Question Answering
- retrievers가 최종 QA 정확도에 얼마나 영향을 끼치는 지 확인
End-to-end QA system
Nick이 잘 설명해 주시지 않을까? 오이오이! Nick 난 믿고 있었다구!

Results
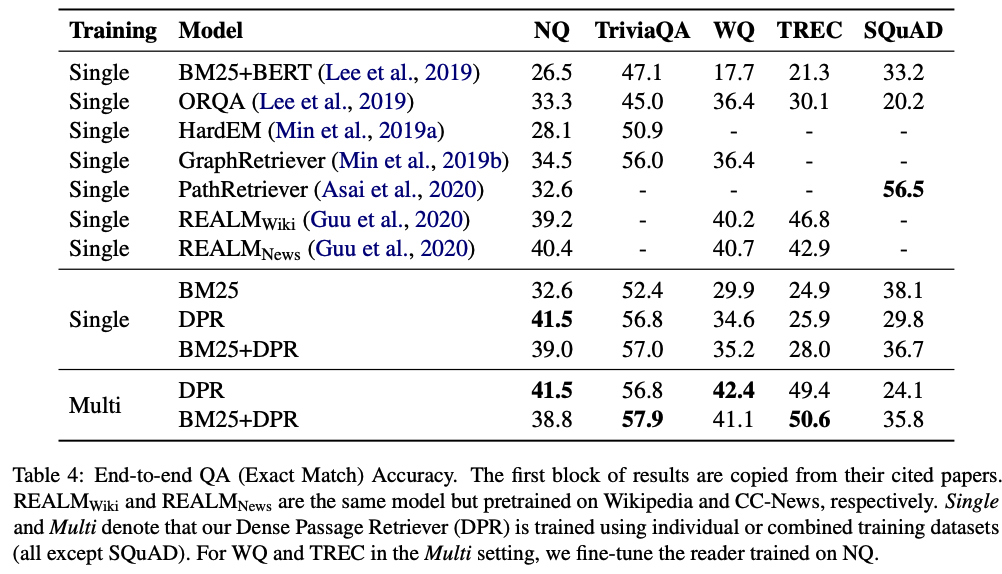
- 다른 베이스라인보다 성능이 좋았다.
Conclusion
- bi-encoder 구조의 간단한 모델을 fine-tuning만 해도 성능 good
- Random에 BM25를 negative sample로 추가한것이 성능 향상에 도움
- retrieval과 최종 QA성능 모두 성능 향상
Implementation
- official code : https://github.com/facebookresearch/DPR
- huggingface transformer : https://huggingface.co/docs/transformers/model_doc/dpr

Reference
