0. Summary
- Background : DNN으로 아직 sequences to sequence 다룬 적 없음
- Goal : end-to-end approach to sequence learning
- Method : LSTM encoder-decoder
- Experiment : en to fr translation (BLEU 34.8)
- Contribution : source sentence 의 순서를 반대 (reversing the words)로 해서 입력했더니 long sentence 무리 없이 optimization함.
Paper : https://proceedings.neurips.cc/paper/2014/file/a14ac55a4f27472c5d894ec1c3c743d2-Paper.pdf
1. Introduction
-
Background
- DNN의 장점 : parallel computation
A surprising example of the power of DNNs is their ability to sort N N-bit numbers using only 2 hidden layers of quadratic size [27].=> 이게 엄청난 이유가 뭘까? - DNN 활용한 기존 연구의 한계점: sequence 활용한 적 X
- 한정적인 task에 활용 (e.g., input, output이 고정된 사이즈의 vector로 인코딩)
- 하지만, 많은 문제들은 길이를 알 수 없는 sequence로 뽑아야 해결할 수 있는 문제들이 많음 (e.g., speech recognition, machine translation, and question answering)
- DNN의 장점 : parallel computation
-
Goal
- DNN 활용해서 sequential problem 해결하기
-
Challenge
- 관련 문제는 sequence length가 고정되어 있지 않음. DNN은 고정된 input, output 을 요구함.
- RNN은 long term dependecies 문제로 train 어려움.
-
Approach
- LSTM 활용:
long range temporal dependencies
1) 한 개의 LSTM이 one timestep마다 input sequence를 읽어서 하나의 fixed-dimensional vector representaion을 얻는다.
2) 또다른 LSTM이 해당 vector를 받아서 output sequence를 뽑는다.
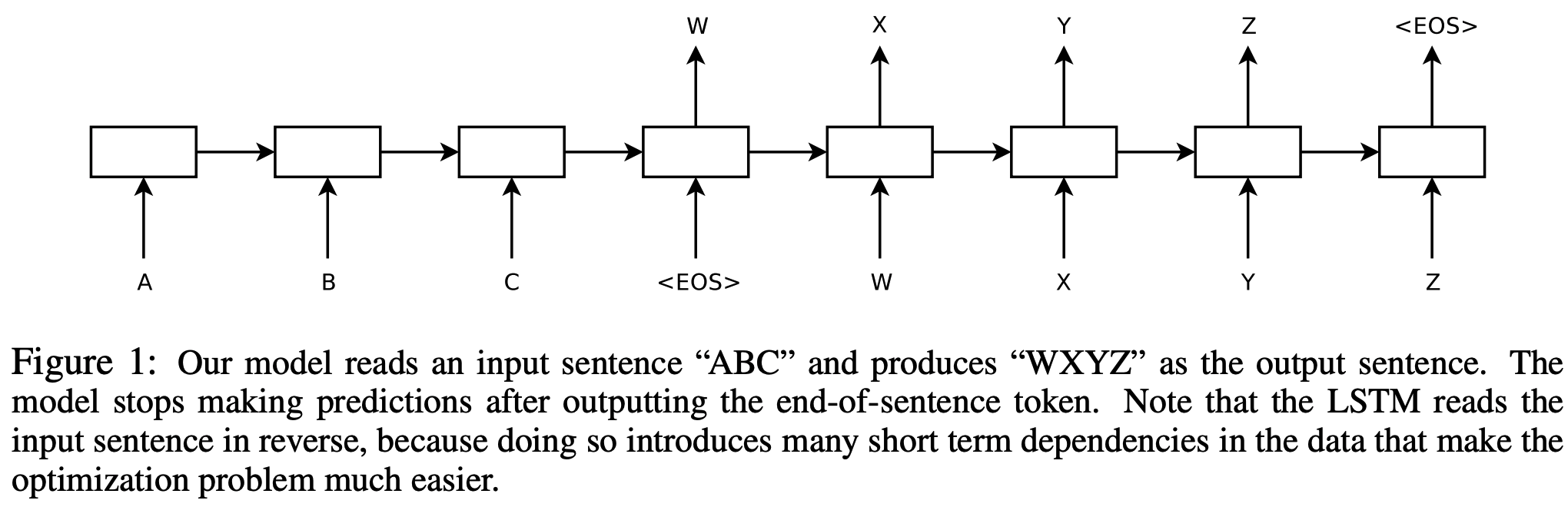
- LSTM 활용:
-
Contribution
- En -> Fr 번역에서 높은 성능을 보임
- source sentence 입력 시 순서를 반대로 넣어줬더니 long sentence 도 무리 없이 opimization함.
- LSTM은 다양한 길이의 input도 받을 수 있음. (긴 문장도 하나의 fixed vector로 만들기 때문에)
2. The model
- 기존 RNN과 LSTM 비교
- RNN
- input, output간의 alignment (fixed size)를 알고 있다면 RNN을 활용해서 sequence mapping하는 거 간편함. (RNN은 아래 수식 이용해서 iterating하면서 output 구함)
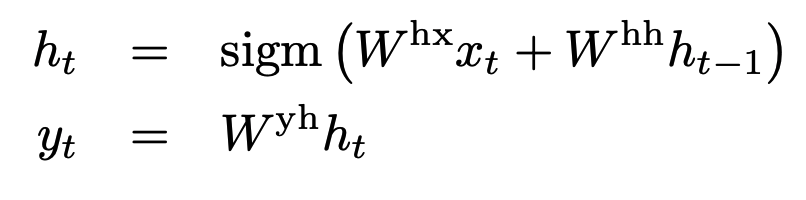
- input, output간의 alignment (fixed size)를 알고 있다면 RNN을 활용해서 sequence mapping하는 거 간편함. (RNN은 아래 수식 이용해서 iterating하면서 output 구함)
- LSTM
- RNN은 long term dependencies 문제가 있음.
- LSTM Objective function : input sequence가 주어졌을 때 output sequence 확률을 구하는데, 이 sequence 길이는 timestep마다 다름. LSTM은 input sequence의 last hidden state를 이용해서 고정된 vector를 얻는다. 그래서 sequence 사이즈가 달라도 괜찮음!
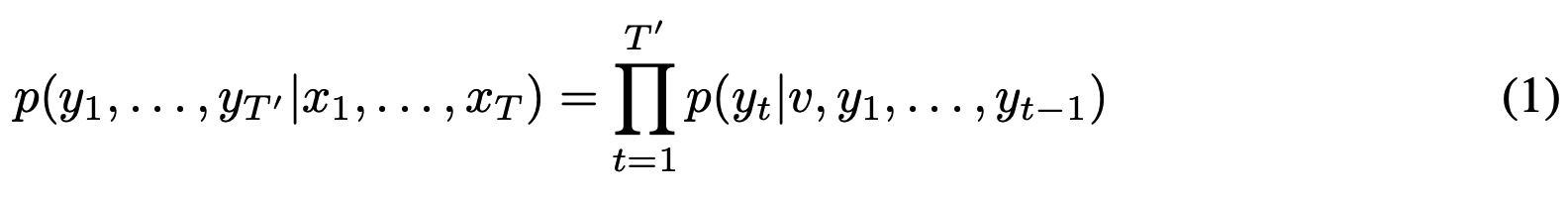
- RNN
- Proposed model
- 1) 2개의 LSTM 사용(One for input sequence, another for output sequence) : model의 파라미터 수를 늘릴 수 있고 (계산 비용 늘어나지 X), language pair를 동시에 학습할 수 있음.
- 2) 4 layer LSTM 사용: deep LSTM이 성능이 좋았음
- 3) input sequence의 단어 순서를 reverse함 (c,b,a => d,e,f) : a의 번역 단어가 d인데, 순서를 반대로 해서 둘의 거리를 좁혀, SGD가 input, output간의
establish communication을 가능하게 한다. (=> 가까운게 더 좋겠지..?)
- Objective Function
- MT task를 위한 loss 구하기
- S: source, T: target
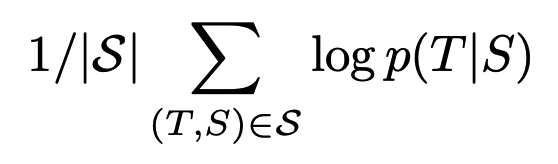
- training 이 끝나면, p분포를 가지고 가장 가능성 있는 translation을 도출

- S: source, T: target
- MT task를 위한 loss 구하기
3. Experiments
-
task : WMT'14 English to French MT task
-
Metric : BLEU (Bilingual Evaluation Understudy) (n-gram 기반 기계 번역 결과와 사람이 직접 번역한 결과 비교)
-
Experiment setting
-
1) Decoding: directly translate the input sentence without using a reference SMT system, 이때 beam search decoding 방식 적용
- Greedy decoding: 해당 시점에서 가장 확률이 높은 후보 선택. 시간 복잡도에서는 좋은데, 정확도는 낮음. 1,2위 후보간 차이가 별로 없어도 1등에만 관심있기 때문.
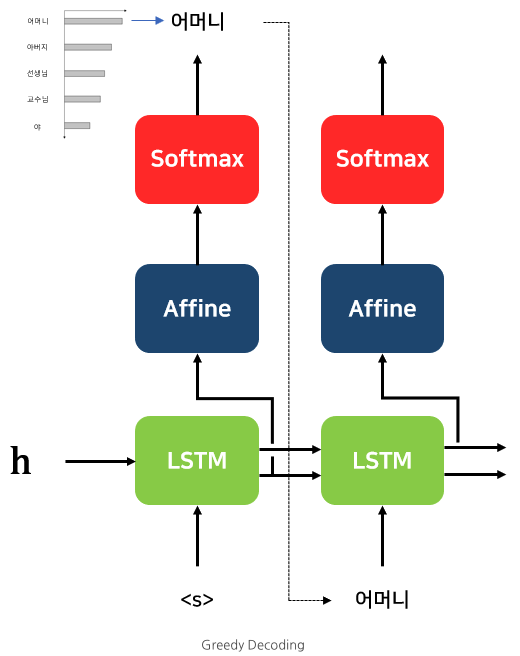
- Beam search: Greedy decoding 단점 보완. 해당 시점에서 나올 수 있는 경우(beam)의 수(k개)를 고려한 뒤 누적 확률이 가장 높은 경우를 선택.
- 처음 start에서 k개 빔을 뽑고, 각 빔마다 또 k개의 빔을 뽑음. 누적으로 확률값을 계산해서 가장 높은 애만 남김. 마지막 를 만날 때까지 계속 반복. (k개를 어느정도로 설정하냐에 따라 성능 달라짐)
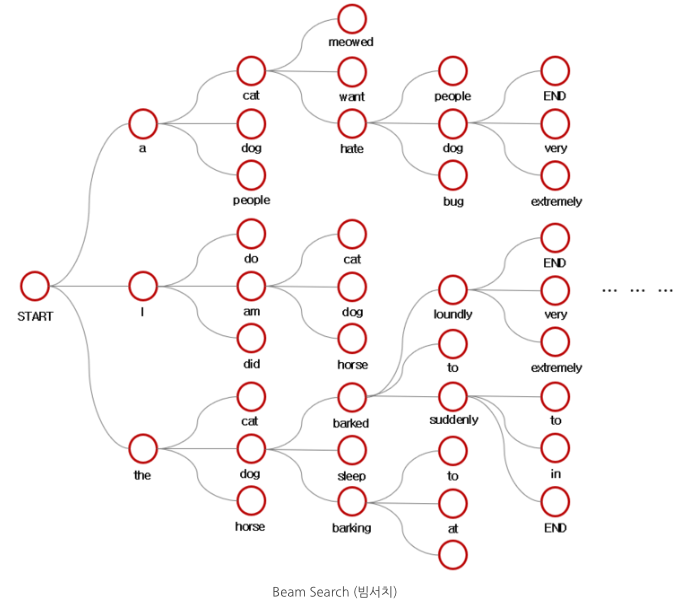
- 처음 start에서 k개 빔을 뽑고, 각 빔마다 또 k개의 빔을 뽑음. 누적으로 확률값을 계산해서 가장 높은 애만 남김. 마지막 를 만날 때까지 계속 반복. (k개를 어느정도로 설정하냐에 따라 성능 달라짐)
- Greedy decoding: 해당 시점에서 가장 확률이 높은 후보 선택. 시간 복잡도에서는 좋은데, 정확도는 낮음. 1,2위 후보간 차이가 별로 없어도 1등에만 관심있기 때문.
-
2) Rescoring: rescore the n-best lists of an SMT baseline
[원문] We also used the LSTM to rescore the 1000-best lists produced by the baseline system [29]. To rescore an n-best list, we computed the log probability of every hypothesis with our LSTM and took an even average with their score and the LSTM’s score.
 https://m.blog.naver.com/sooftware/221816126290
https://m.blog.naver.com/sooftware/221816126290 -
3) Reversing
- [원문] While we do not have a complete explanation to this phenomenon, we believe that it is caused by the introduction of many short term dependencies to the dataset. Normally, when we concatenate a source sentence with a target sentence, each word in the source sentence is far from its corresponding word in the target sentence.
- 왜 이게 좋은지 정확히 설명할 순 없지만, 우리는 dataset의 short term dependencies 때문이라고 생각한다.(source와 target사이 거리가 머니까)
-
4. Result
- 번역 성능
SOTA 못찍었지만, large MT task에서 phrase-based SMT baseline보다 성능이 뛰어난 최초의 pure neural translation system 이다!
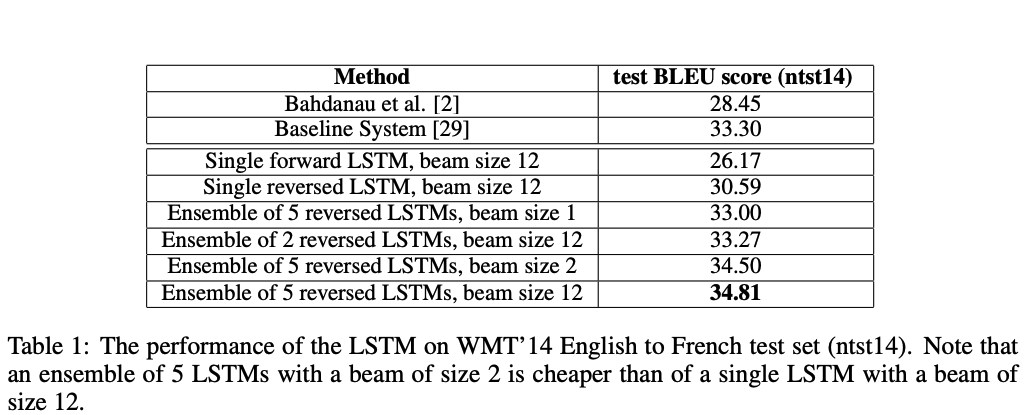

- SOTA model => Durrani, N., Haddow, B., Koehn, P., & Heafield, K. (2014, June). Edinburgh’s phrase-based machine translation systems for WMT-14. In Proceedings of the Ninth Workshop on Statistical Machine Translation (pp. 97-104).
=> 통계적 방식, Greedy coding 방식

https://en.wikipedia.org/wiki/Statistical_machine_translation#Phrase-based_translation
- SOTA model => Durrani, N., Haddow, B., Koehn, P., & Heafield, K. (2014, June). Edinburgh’s phrase-based machine translation systems for WMT-14. In Proceedings of the Ninth Workshop on Statistical Machine Translation (pp. 97-104).
- Long sentences 성능
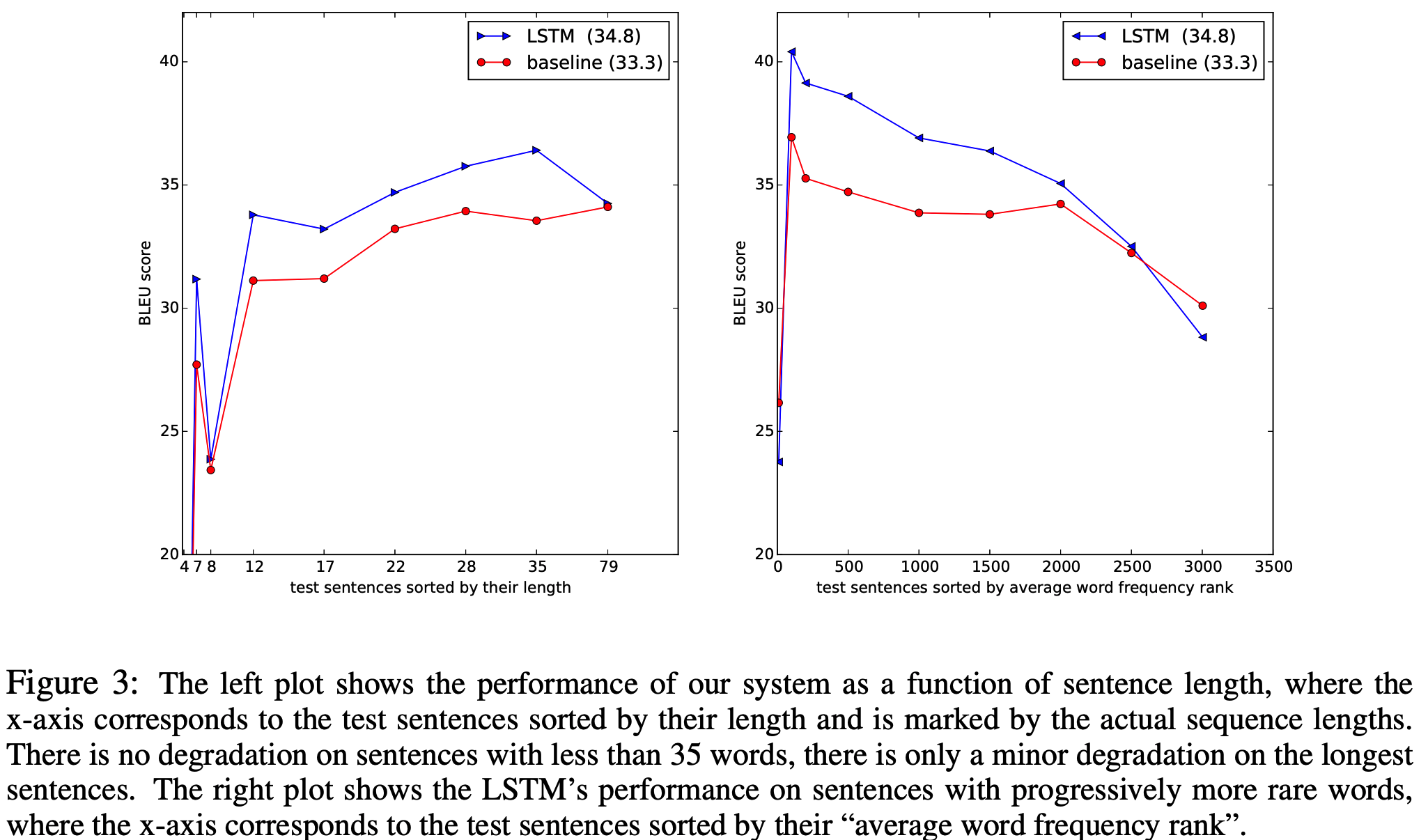
- order of words 중요
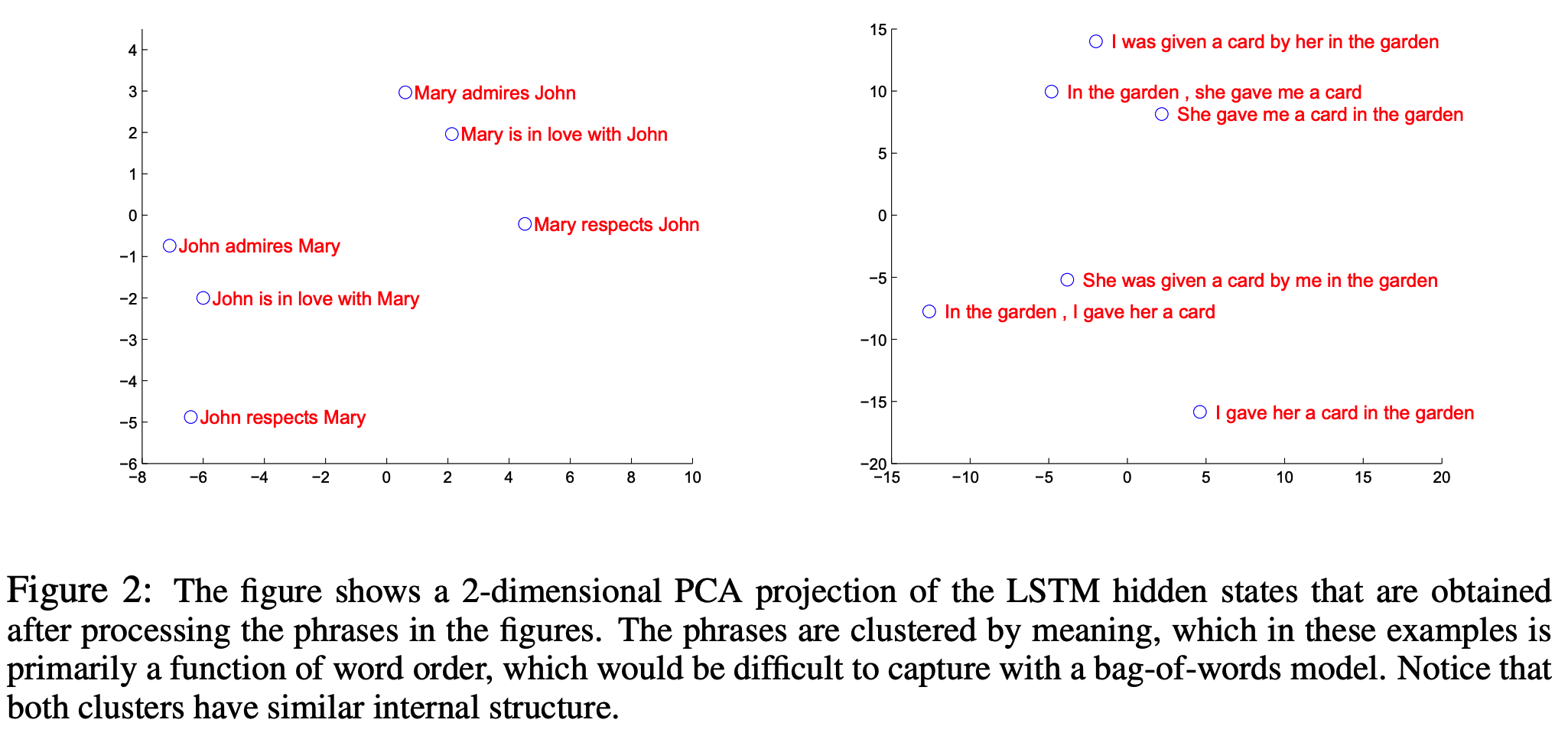
5. Conclusion
- 최초의 DNN 활용한 seq2seq 모델. 두 개의 LSTM 모델 사용!
- SOTA (statistical model)의 성능은 뛰어넘지 못했다는 한계점은 있음.
- Long sentence 잘한다.
- reverse 한 거 좋았다.
- 이후 연구
- Transformer (Attention is all you need) : long-term dependency 문제가 여전히 있어서 이를 극복
6. Implementation
- Teacher forcing : training 할 때, decode 과정에서 다음 입력값에 예측값을 주는 게 아니라 정답 target값을 줘서 교정을 해준다. 그럼 학습 초기에 안정적으로 학습할 수 있다고 함.
#!/usr/bin/env python
# coding: utf-8
# In[ ]:
# https://github.com/bentrevett/pytorch-seq2seq
# https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
# # 1 - Sequence to Sequence Learning with Neural Networks
#
# [Sequence to Sequence Learning with Neural Networks](https://arxiv.org/abs/1409.3215) paper.
# In[1]:
import re
import torch
import torch.nn as nn
import torch.optim as optim
#from torchtext.legacy.datasets import Multi30k
from torchtext.legacy.data import Example,Dataset,Field, BucketIterator
import spacy
import numpy as np
import random
import math
import time
from tqdm import tqdm
# In[2]:
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
# # 1. Preparing Data
# # dataset 출처 : https://github.com/jungyeul/korean-parallel-corpora
#
# # gz 푸는 방법
# import tarfile
# tar = tarfile.open("korean-english-park.train.tar.gz")
# tar.extractall()
# tar.close()
# In[3]:
with open("korean-english-park.train.en", "r") as f:
train_en = f.readlines()
with open("korean-english-park.test.en", "r") as f:
test_en = f.readlines()
with open("korean-english-park.train.ko", "r") as f:
train_ko = f.readlines()
with open("korean-english-park.test.ko", "r") as f:
test_ko = f.readlines()
# In[4]:
train_en[0], train_ko[0]
# In[60]:
test_en[0], test_ko[0]
# In[5]:
spacy_kor = spacy.load('ko_core_news_sm')
spacy_en = spacy.load('en_core_web_sm')
# In[ ]:
# ### Tokenizer function
# - These can be passed to torchtext and will take in the sentence as a string and return the sentence as a list of tokens.
# - We copy this by reversing the sentence after it has been transformed into a list of tokens.
# In[6]:
def clean_text(text):
"""
remove special characters from the input sentence to normalize it
Args:
text: (string) text string which may contain special character
Returns:
normalized sentence
"""
text = re.sub('[-=+,#/\?:^$.@*\"※~&%ㆍ!』\\‘|\(\)\[\]\<\>`…》]', '', text)
return text
# In[7]:
def tokenize_kor(text):
"""
Tokenizes korean text from a string into a list of strings (tokens) and reverses it
"""
return [tok.text for tok in spacy_kor.tokenizer(text)][::-1]
def tokenize_en(text):
"""
Tokenizes English text from a string into a list of strings (tokens)
"""
return [tok.text for tok in spacy_en.tokenizer(text)]
# In[9]:
[tok.text for tok in spacy_kor.tokenizer("나는 바보입니다 왜 이러세요")][::-1]
# ### Torchtext Fields
# - handle how data should be processed
# - field also appends the "start of sequence" and "end of sequence" tokens via the init_token and eos_token arguments, and converts all words to lowercase.
# In[10]:
SRC = Field(tokenize = tokenize_kor,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
TRG = Field(tokenize = tokenize_en,
init_token = '<sos>',
eos_token = '<eos>',
lower = True)
# In[11]:
def convert_to_dataset(SRC, TRG, train_src, train_tg):
# convert each row of DataFrame to torchtext 'Example' containing 'kor' and 'eng' Fields
list_of_examples = [Example.fromlist([clean_text(ko),clean_text(en)],
fields=[('src', SRC), ('trg', TRG)]) for ko,en in zip(train_src,train_tg)]
# construct torchtext 'Dataset' using torchtext 'Example' list
dataset = Dataset(examples=list_of_examples, fields=[('src', SRC), ('trg', TRG)])
return dataset
# In[102]:
train_data = convert_to_dataset(SRC, TRG, train_ko[:10000], train_en[:10000])
val_data = convert_to_dataset(SRC, TRG, test_ko,test_en)
test_data = convert_to_dataset(SRC, TRG, test_ko,test_en)
# In[103]:
print(f"Number of training examples: {len(train_data.examples)}")
print(f"Number of testing examples: {len(test_data.examples)}")
# In[104]:
print(vars(train_data.examples[0]))
# ### Build Vocab
# - The vocabulary is used to associate each unique token with an index (an integer).
# - The vocabularies of the source and target languages are distinct.
# - Using the min_freq argument, we only allow tokens that appear at least 2 times to appear in our vocabulary.
# - Tokens that appear only once are converted into an <unk> (unknown) token.
# - our vocabulary should only be built from the training set and not the validation/test set.
# In[105]:
SRC.build_vocab(train_data, min_freq = 1)
TRG.build_vocab(train_data, min_freq = 1)
# In[106]:
print(f"Unique tokens in source (kor) vocabulary: {len(SRC.vocab)}")
print(f"Unique tokens in target (en) vocabulary: {len(TRG.vocab)}")
# ### Iterator
# : BucketIterator instead of the standard Iterator as it creates batches in such a way that it minimizes the amount of padding in both the source and target sentences.
# In[17]:
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# In[107]:
BATCH_SIZE = 128
train_iterator,val_iterator, test_iterator = BucketIterator.splits(
(train_data, val_data, test_data),
batch_size = BATCH_SIZE,
device = device
,sort=False)
# # 2. Building the Seq2Seq Model
# ### Encoder
# : 2 layer LSTM. (The paper we are implementing uses a 4-layer LSTM, but in the interest of training time we cut this down to 2-layers.)
#
# $$\begin{align*}
# (h_t^1, c_t^1) &= \text{EncoderLSTM}^1(e(x_t), (h_{t-1}^1, c_{t-1}^1))\\
# (h_t^2, c_t^2) &= \text{EncoderLSTM}^2(h_t^1, (h_{t-1}^2, c_{t-1}^2))
# \end{align*}$$
#
# 
# In[108]:
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
#src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
#embedded = [src len, batch size, emb dim]
outputs, (hidden, cell) = self.rnn(embedded)
#outputs = [src len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#outputs are always from the top hidden layer
return hidden, cell
# ### Decoder
#
# : a 2-layer (4 in the paper) LSTM.
#
# 
# In[109]:
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
#input = [batch size]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#n directions in the decoder will both always be 1, therefore:
#hidden = [n layers, batch size, hid dim]
#context = [n layers, batch size, hid dim]
input = input.unsqueeze(0)
#input = [1, batch size]
embedded = self.dropout(self.embedding(input))
#embedded = [1, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
#output = [seq len, batch size, hid dim * n directions]
#hidden = [n layers * n directions, batch size, hid dim]
#cell = [n layers * n directions, batch size, hid dim]
#seq len and n directions will always be 1 in the decoder, therefore:
#output = [1, batch size, hid dim]
#hidden = [n layers, batch size, hid dim]
#cell = [n layers, batch size, hid dim]
prediction = self.fc_out(output.squeeze(0))
#prediction = [batch size, output dim]
return prediction, hidden, cell
# ### Seq2Seq
#
# For the final part of the implemenetation, we'll implement the seq2seq model. This will handle:
# - receiving the input/source sentence
# - using the encoder to produce the context vectors
# - using the decoder to produce the predicted output/target sentence
#
# 
#
# The teacher forcing ratio is used when training our model.
#
# **Note**: our decoder loop starts at 1, not 0. This means the 0th element of our `outputs` tensor remains all zeros. So our `trg` and `outputs` look something like:
#
# $$\begin{align*}
# \text{trg} = [<sos>, &y_1, y_2, y_3, <eos>]\\
# \text{outputs} = [0, &\hat{y}_1, \hat{y}_2, \hat{y}_3, <eos>]
# \end{align*}$$
#
# Later on when we calculate the loss, we cut off the first element of each tensor to get:
#
# $$\begin{align*}
# \text{trg} = [&y_1, y_2, y_3, <eos>]\\
# \text{outputs} = [&\hat{y}_1, \hat{y}_2, \hat{y}_3, <eos>]
# \end{align*}$$
# In[110]:
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.hid_dim == decoder.hid_dim, "Hidden dimensions of encoder and decoder must be equal!"
assert encoder.n_layers == decoder.n_layers, "Encoder and decoder must have equal number of layers!"
def forward(self, src, trg, teacher_forcing_ratio = 0.5):
#src = [src len, batch size]
#trg = [trg len, batch size]
#teacher_forcing_ratio is probability to use teacher forcing
#e.g. if teacher_forcing_ratio is 0.75 we use ground-truth inputs 75% of the time
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
#tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
#last hidden state of the encoder is used as the initial hidden state of the decoder
hidden, cell = self.encoder(src)
#first input to the decoder is the <sos> tokens
input = trg[0,:]
for t in range(1, trg_len):
#insert input token embedding, previous hidden and previous cell states
#receive output tensor (predictions) and new hidden and cell states
output, hidden, cell = self.decoder(input, hidden, cell)
#place predictions in a tensor holding predictions for each token
outputs[t] = output
#decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
#get the highest predicted token from our predictions
top1 = output.argmax(1)
#if teacher forcing, use actual next token as next input
#if not, use predicted token
input = trg[t] if teacher_force else top1
return outputs
# # 3. Training the Seq2Seq Model
# In[111]:
INPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
ENC_EMB_DIM = 256
DEC_EMB_DIM = 256
HID_DIM = 512
N_LAYERS = 2
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5
enc = Encoder(INPUT_DIM, ENC_EMB_DIM, HID_DIM, N_LAYERS, ENC_DROPOUT)
dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, HID_DIM, N_LAYERS, DEC_DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)
# In[112]:
def init_weights(m):
for name, param in m.named_parameters():
nn.init.uniform_(param.data, -0.08, 0.08)
model.apply(init_weights)
# In[113]:
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
# In[114]:
optimizer = optim.Adam(model.parameters())
# In[115]:
TRG_PAD_IDX = TRG.vocab.stoi[TRG.pad_token]
criterion = nn.CrossEntropyLoss(ignore_index = TRG_PAD_IDX)
# ### train loop
# In[116]:
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
optimizer.zero_grad()
output = model(src, trg)
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
# ### evaluation loop
# In[117]:
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
#trg = [trg len, batch size]
#output = [trg len, batch size, output dim]
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
#trg = [(trg len - 1) * batch size]
#output = [(trg len - 1) * batch size, output dim]
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
# In[118]:
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
# In[119]:
import matplotlib.pyplot as plt
plt.switch_backend('agg')
import matplotlib.ticker as ticker
import numpy as np
def showPlot(points):
plt.figure()
fig, ax = plt.subplots()
# this locator puts ticks at regular intervals
loc = ticker.MultipleLocator()#base=0.2
ax.yaxis.set_major_locator(loc)
plt.plot(points)
# In[120]:
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
print_every=3
plot_every=3
start = time.time()
plot_losses = []
print_loss_total = 0 # Reset every print_every
plot_loss_total = 0 # Reset every plot_every
for epoch in tqdm(range(N_EPOCHS)):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, CLIP)
#valid_loss = evaluate(model, valid_iterator, criterion)
print_loss_total += train_loss
plot_loss_total += train_loss
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
# if epoch % print_every == 0:
# print_loss_avg = print_loss_total / print_every
# print_loss_total = 0
# print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters),
# iter, iter / n_iters * 100, print_loss_avg))
if epoch % plot_every == 0:
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
showPlot(plot_losses)
# if valid_loss < best_valid_loss:
# best_valid_loss = valid_loss
# torch.save(model.state_dict(), 'tut1-model.pt')
# print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
# print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
# #print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')
# In[121]:
#model.load_state_dict(torch.load('tut1-model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
# In[ ]:
### 결과 출력
# In[157]:
for i, batch in enumerate(test_iterator):
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
# In[191]:
src = batch.src
trg = batch.trg
output = model(src, trg, 0) #turn off teacher forcing
for src_,trg_,out_ in zip(src.transpose(1,0),trg.transpose(1,0),output.transpose(1,0)):
src_list = []
trg_list = []
pred_list = []
for token in src_:
word = SRC.vocab.itos[token]
if word not in ['<sos>','<pad>','<eos>']:
src_list.append(word)
for token in trg_:
word = TRG.vocab.itos[token]
if word not in ['<sos>','<pad>','<eos>']:
trg_list.append(word)
for token in out_:
topv, topi = token.data.topk(1)
word = TRG.vocab.itos[topi.item()]
if word not in ['<sos>','<pad>','<eos>']:
pred_list.append(word)
print("src : ", src_list[::-1])
print("trg : ", trg_list)
print("predict : ", pred_list)
print()
# ### in detail
# In[68]:
val_iterator
# In[76]:
for i, batch in enumerate(val_iterator):
src = batch.src
trg = batch.trg
# In[79]:
i
# In[82]:
src.size(), trg.size()
# In[102]:
output = model(src, trg)
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
# In[109]:
topv, topi = output[0].data.topk(1)
# In[110]:
topi.item()
# In[117]:
TRG.vocab.itos[topi.item()]
Reference
- https://wikidocs.net/24996
- https://wikidocs.net/31695
- https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
- https://blog.naver.com/PostView.nhn?blogId=sooftware&logNo=221809101199&from=search&redirect=Log&widgetTypeCall=true&directAccess=false
- https://m.blog.naver.com/sooftware/221816126290
