paper:
Introduction & Summary
연구배경
-
LLM 발전 동향 (reference)
초기에는 LLM 성능 개선 위해 파라미터 개수 증가에 집중, 최근에는 추론 속도와 제한된 compute 예산을 고려하여 충분한 성능을 제공할 수 있는 작은 모델 선호. LLM의 alignment를 위해 대규모 데이터셋과 컴퓨팅 리소스 줄이려는 노력 진행 중.
- (1) GPT3 -> Instruct- GPT
- GPT-3(‘20)은 175B, GPT-4(‘23)는 1T의 거대한 파라미터을 가진 대표적인 SOTA LLM
- 학습 데이터 구축 및 학습에 막대한 비용 필요.
- 놀라운 성능에도, 학습 데이터셋에 포함된 사회적인 bias (인종, 성별, 가치관 등)가 그대로 GPT에 반영되는 경우 있음.
- 따라서 Instruc GPT 등장: Pre-training된 GPT 모델을 RLHF(Reinforcement Learning with Human Feedback)과 같은 방법을 사용하여 인간의 선호도 반영해서 개선
- 하지만 RLHF 역시, 관련 데이터 수집에 비용 많이 필요함.
- (2) Chinchilla ➜ LLaMA ➜ Alpaca (LLaMA + Self-Instruct)
- Google Deepmind Chinchilla(‘22): 제한된 FLOPS에서 최적 성능 달성하기 위한 모델 크기와 학습 token 조합 계산하는 방법 제안. 70B 파라미터로 280B 파라미터의 Gopher 모델보다 더 우수한 성능을 달성.
- 기존 LLM이 큰 파라미터 개수에 비해 과소 적합되어 있다는 것을 입증
- LLaMA: Meta는 추론에 유리하도록 GPT-3 175B보다 더 작으면서 성능은 우수한 LLaMA 발표. LLaMA는 RLHF이 적용되지 않아 챗봇으로 동작할 수 없어 추가 학습 필요
- Alpaca: 스탠포드 대학 Alpaca는 Self-Instruct 적용하여 기존 pre-training된 LLM(text-davinci-003)으로 instruction tuning용 데이터셋(52K)을 생성한 후, LLaMA 7B 모델을 52K 데이터셋으로 supervised fine-tuning함. 제한된 학습 예산(총 < $600)으로 사람이 생성한 데이터셋을 최소로 사용하여 고품질의 Instruction Following Model을 만들었음.
- Google Deepmind Chinchilla(‘22): 제한된 FLOPS에서 최적 성능 달성하기 위한 모델 크기와 학습 token 조합 계산하는 방법 제안. 70B 파라미터로 280B 파라미터의 Gopher 모델보다 더 우수한 성능을 달성.
- (1) GPT3 -> Instruct- GPT
- 기존 transfer learning 방식 for aligning language models
- (1) insturction tuning
: multi-million-example 데이터 가지고 튜닝 - (2) reinforcement learning from human feedback (RLHF)
: human annotator와의 interaction 수집한 데이터 가지고 튜닝
- (1) insturction tuning
기존 연구 한계
- 수백만 이상의 사람이 라벨링한 데이터
- 엄청난 컴퓨팅 연산
본 연구의 가설
Superficial Alignment Hypothesis: 모델이 가지고 있는 대부분의 지식과 capabilities들은 사전 훈련동안 모두 학습되었으며, alignment는 그저 user들이 선호하는 답변 형식을 가르치는 것 뿐임.
따라서, 파인 튜닝을 통한 'alignment'가 단순히 모델이 사용자와 상호작용하기 위한 스타일을 학습하는 것이라면 위 가설의 결론은 작은 파인 튜닝 데이터셋으로도 사전 학습 모델을 충분히 학습시킬 수 있다.
Approach
- 잘 엄선한 1천개 데이터만으로 파인 튜닝
Results
- 1천개로만 파인튜닝해도, 원하는 답변 형태 뽑아낼 수 있음
- trainig data에 없던 unseen tasks도 잘함
- RLHF 적용한 모델들 (DaVinci003, GPT-4), 많은 양의 학습데이터 사용해서 aligning한 모델들 (Alpaca)보다 더 뛰어나거나 비슷한 성능을 보임.
- dialogue 데이터 30개만 더 추가해서 파인튜닝하면, multi-turn도 엄청 잘함
Data: Alignment Data
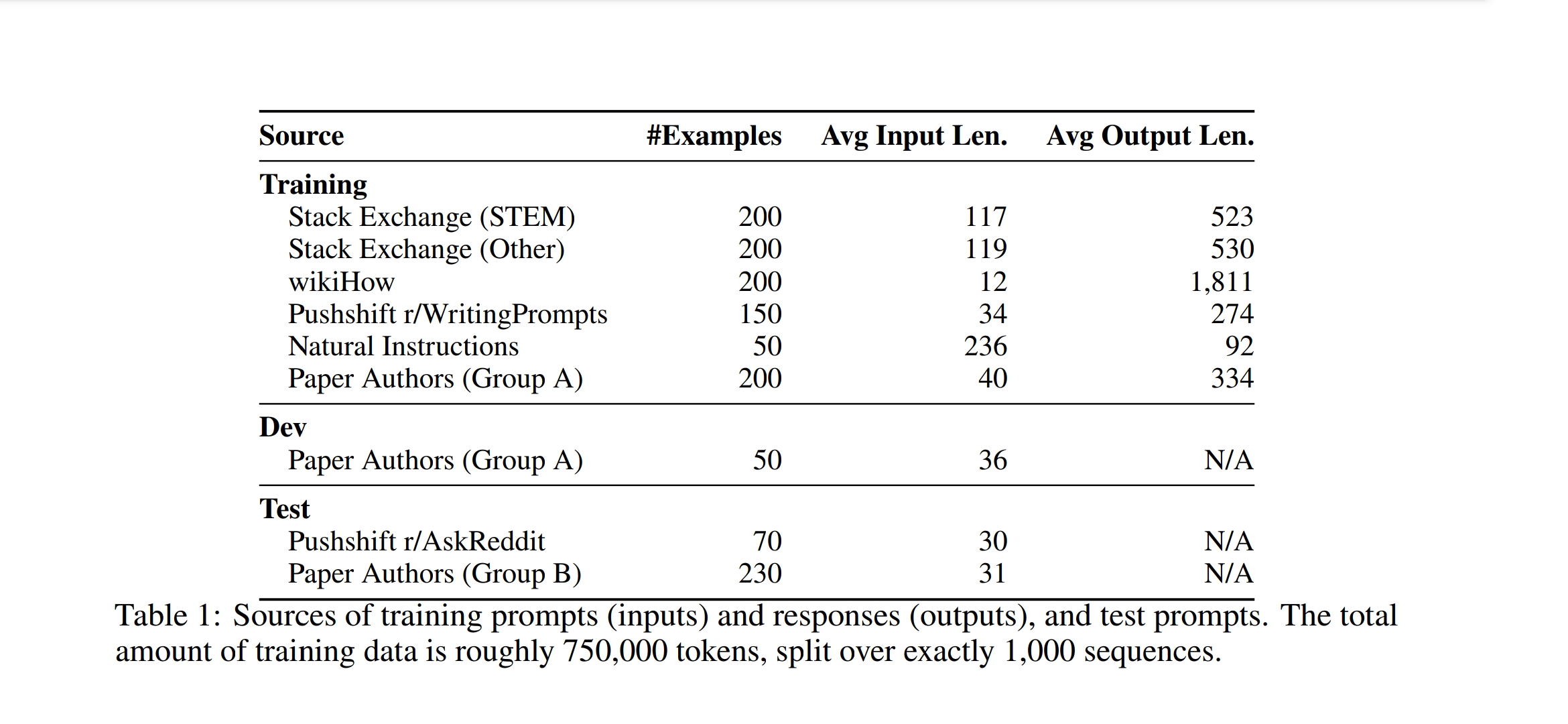
데이터셋 형태
- 1천개의 프롬프트/답변 쌍 데이터셋 구축
- output 형식 동일, input(프롬프트)만 다양한 주제 포함
- 학습 데이터 1천개, development (val) 50개, 테스트 셋 300개
데이터셋 종류 & 전처리
-
Community Questions & Answers
-
(1) Stack Exchange
- stack overflow같이 특정 주제를 가지고 대화 주고 받는 커뮤니티(exchanges) 총 179개 중
- STEM 관련 75개 exchanges
- Others 99개 exchanges
- 5개는 삭제
- 200개 질문과 답변 sampling
- temperature of =3, 여러 도메인에서 uniform하게 뽑힐 수 있도록
- highest score 받고+ self-contatined prompts (제곧내, 제목이 곧 내용)인 questions
- 그 중 높은 점수 받은 top answer
- 필터링 to conform with the style of a helpful AI assistant
- 1200자 미만 or 4096자 이상 제거
- 1인칭 시점 or 다른 답변 참조 삭제
- 이미지, 링크 등 삭제
- stack overflow같이 특정 주제를 가지고 대화 주고 받는 커뮤니티(exchanges) 총 179개 중
-
(2) wikiHow
- wiki 스타일의 onlie how-to articles 240,000개
- 200개 articles sampling
- category sampling
- title을 prompt로 사용, 답변을 response로
- 답변 형식 변경 : This article... => The follwing answer...
-
(3) Pushshift Reddit Dataset
- 레딧은 helping보단 entertainig으로 사용되는 경우가 많아서, 유머나, sarcastic한 답변이 많음.
- 그래서 r/AskReddit, r/WritingPrompts로 제한하고, manually 하게 고름
- r/AskReddit:
- 70개 self-contatined prompts
- 답변들이 reliable하지 않아서 훈련용으론 적합하지 않은 것 같아서 test 셋으로 사용
- r/WritingPrompts
- 소설의 premises를 던지고, 다른 user들이 창의적으로 끝맺는 답변 업로드.
- 150개 prompts 선택 (love peoms, short science fiction stroies)
- 얘네는 훈련용으로
-

- Manually Authored Examples
이렇게 데이터 만드는 거 노동력 많이 들어가지고, 최근 연구들은 데이터양 많이 생성해서 질보다는 양으로 승부봄. 하지만! 우리 연구에서는 다양성과 질이 더 좋다는 것을 알려줄거임~- (4) Paper Authors
- 데이터의 다양화를 위해, 수집된 데이터셋 외에 연구자들이 직접 prompt 제작
- groupA, groupB로 나눠서 각각 250개씩, 자신의 interests관련된 prompts 제작하라고 시킴
(주석으로, 다양성이 목표니까 두 그룹 정보 공유 못하게 해서 서로 다른 데이터 만드려고 한건데, 쉽지 않았다고 함..ㅋㅋㅋ 그래서 중복된 내용도 있었다고 함) - Group A
- 200개는 학습용, 50개는 dev 셋
- 답변 자기들이 직접 썼음.
- 답변 형식은 다 동일하게 함 (consistent format은 모델 성능 높인다는 연구 결과) => chain-of-thought에 더 도움될 것이라고 믿음
- toxicity or malevoloence 한 prompts도 학습에 포함함. 그래서 답변으로 이거 질문 잘못되었다. 답변할 수 없다! 이런 식으로 작성함
- Group B
- 230개 테스트 용

- 230개 테스트 용
- (5) Super-Natural Instructions(Wang et al., 2022b)
- 데이터 다양성, 견고함 늘리려고
- 50가지 NLG task (summarization, paraphrasing 등) 골라서, 태스크당 답변 1개씩 골랐음.
- 그런 다음 답변을 다른 학습 데이터셋 형태와 맞춤.
- (4) Paper Authors
Method: Training LIMA
학습방법
- LLaMA 65B을 1K 예시 학습 셋으로 fine-tuning
- 각 화자(speaker) 구별하기 위해 각 발화 끝에 End of Token(EOT) (EOS랑 비슷한 역할이지만, 구분을 두기 위해 EOT로 새로 만들었음)
- Fine-tuning 시 hyper-parameter
- AdaW optimizer 사용
- 15 epoch fine-tuning
- β1 = 0.9, β2 = 0.95
- Weight Decay = 0.1
- Learning rate는 warmup step 없이 초기 lr=1e-5로 설정하며, 학습이 끝날때까지 선형적으로 lr=1e-6까지 감쇠(decay)하도록 설정
- Batch Size = 32 examples (더 작은 모델은 64 examples)
- 2048 token보다 더 긴 텍스트는 잘라냄
- residual dropout 사용
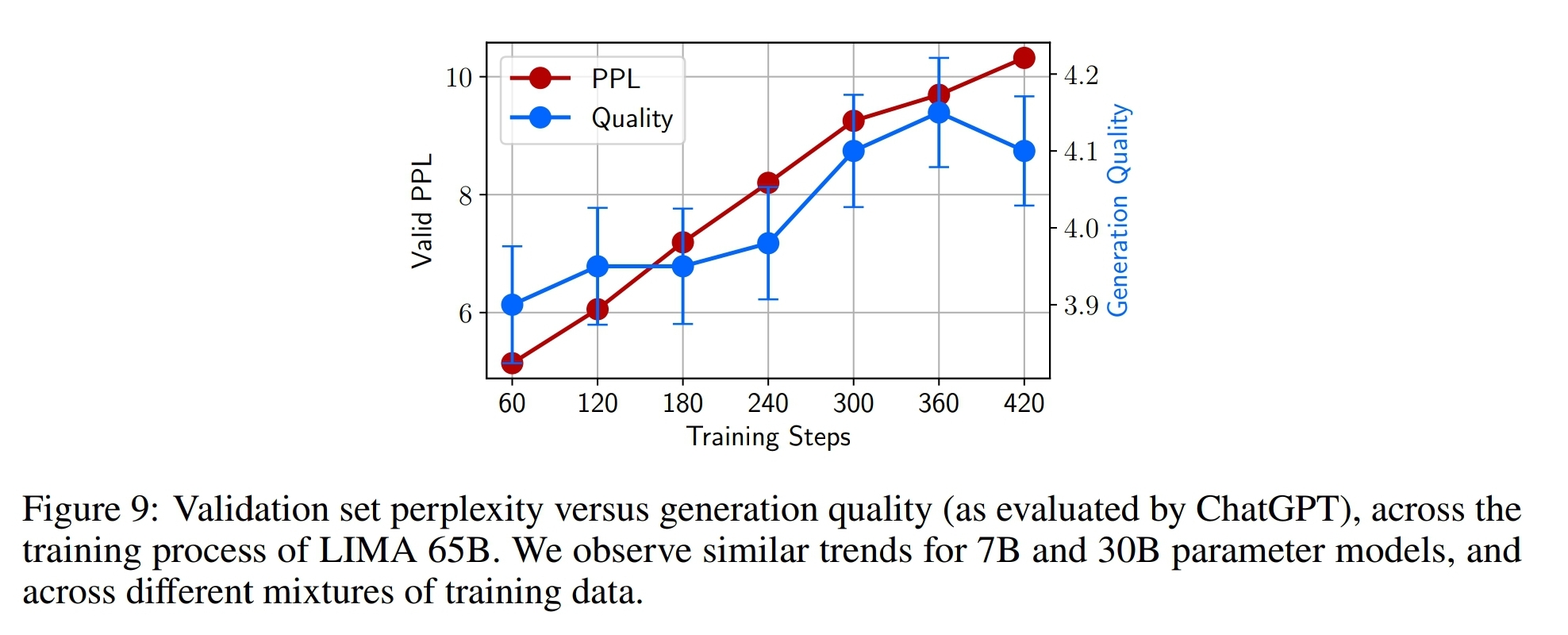
perplexity
-
Training step 늘릴 수록 perplexity 증가함.
-
perplexity는 NLG 태스크에서 답변 얼마나 다양하게 하는가 하나의 지표가 될 수 있는데, 실험을 해보니까 perplexity와 답변 질과는 연관 없었음.
-
그래서 developmet 셋으로 직접 평가해가며 5-10 epochs 사이에서 수동으로 모델 선정 (그냥 답변이 어떻게 잘 나왔나 본 듯. 어떤 기준으로 봤다는 얘기는 없음)
Experiment Setup
-
Baseline
- (1) Alpaca 65B: LLaMA 65B을 Alpaca의 52K 학습 데이터셋으로 fine-tuning
- (2) OpenAI DaVinci003: RLHF기반 LLM (GPT-3+RLHF)
- (3) OpenAI GPT-4: RLHF기반 SOTA LLM
- (4) Google Bard: PaLM2 기반 LLM
- (5) Anthropic의 Claude: RL으로 학습된 52B 모델
-
평가방식
- Generation: 테스트 프롬프트에 대해서 단일 응답 생성
- Human eval: annotators가 LIMA와 baseline 모델 출력 비교
- GPT-4: human-eval과 동일한 형태로 LIMA랑 baseline 비교

-
Inter-annotator agreement
- crowd workers, authors, gpt-4간의 선호도 차이 비교해 보기 위해서 50개 annotation examples로 agreement 평가함.
- crowd-crowd: 82%
- crowd-author: 81%
- author-author: 78%
- crowd-gpt: 78%
- author-gpt: 79%
Results
Human Evaluation

- LIMA보다 52배 큰 데이터셋 (1K vs 52K)으로 학습했음에도 불구하고 Alpaca보다 LIMA 선호도 승
- 더 우수한 alignment 방법으로 여겨지는 RHLF로 학습되었지만 LIMA 선호도 승
- Bard, Claude, GPT-4는 LIMA에 비해 더 높은 선호도를 보였음
하지만, GPT-4로 선호도 평가했을 때, GPT-4는 19%는 자기 답변보다 LIMA가 더 좋다고 답변한 것임!
Absolute assessment
-
베이스라인 모델들은 수백만개 프롬프트를 파인튜닝한거라 제대로된 비교가 안될 수 있다고 판단.
-
저자들은 50개 랜덤 예제를 골라서, LIMA가 답변한걸 다른 모델과의 비교가 아니라 LIMA 자체를 "absolute"하게 평가하겠다고 함.
-
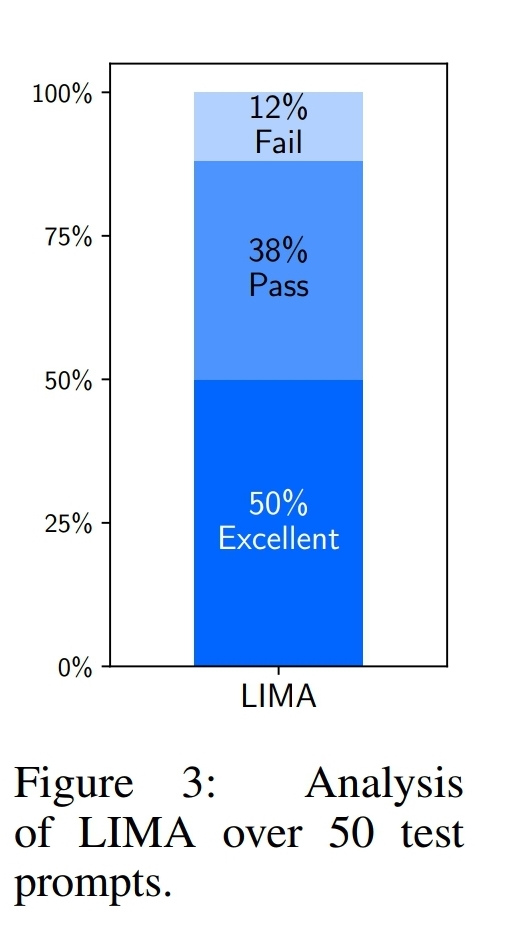
평가 라벨:
- Fail: 응답이 프롬프트의 요구사항을 만족하지 못함
- Pass: 응답이 프롬프트의 요구사항을 만족함
- Excellent: 모델이 프롬프트에 대해 우수한 응답을 제공함
-
결과:
- 50% sample에 대해 excellent로 평가
- 6개(12%) 제외한 응답이 pass이상
-
Out of Distribution:
- 위에서 LIMA가 pass이상 받은 43개의 답변들을 보면 학습데이터랑 형태들이 비슷한 경우였음.
- 그래서 LIMA가 답변 잘 못한 7개 sample이랑 추가로 13개 (총 20개)의 out-of-distribution examples들에 대해 분석을 해봤음.
- 결과적으로, 응답 20% Fail, 35% Pass, 45% Excellent 받음.
- 작은 데이터셋이긴 한데, 훈련 데이터셋에 없는 것도 잘하는 거 같으니 generalize 능력이 있다고 생각해~

- 작은 데이터셋이긴 한데, 훈련 데이터셋에 없는 것도 잘하는 거 같으니 generalize 능력이 있다고 생각해~
-
Safety:
- training set에 13개, test에 30개의 safety관련 examples이 있음. LIMA가 얼마나 잘 답변하는지 체크함.
- 80%는 safety하게 답변함.
- 유명인 주소 알려줘~ 는 답변 거부
- but, implicit한 경우에는 unsafe response함.

Ablations on Data Diversity, Quality, and Quantity
-
실험 설정
- 양보다는 질이다! 라는거 밝히고 싶어서 진행한 실험
- 학습용 파라미터와 동일한 hyper-parameter
- 다양한 세팅의 데이터셋에 대 LLaMA 7B를 fine-tuning
- 각 테스트셋 프롬프트에 대해서 5개의 응답 샘플링하고 ChatGPT한테 helpfulness 1~6점 likert 척도 평가

-
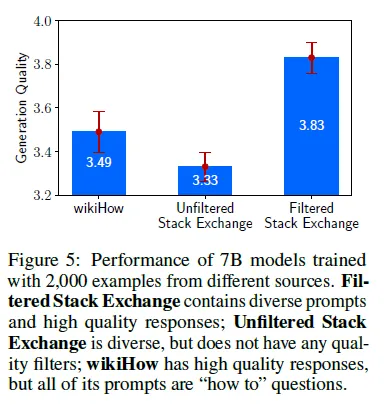
Diversity
- 실험셋팅
- 저자들은 wikihow보다 stack exchange가 더 다양하다고 생각해서, 둘을 비교. (비약있을 수 있다고 린정한다고 말함)
- wikihow랑 stack exchange 각각에서 2천개 sample 뽑아서 학습시킴.
(2천개 이상으로 하니까 stability 증가한 거 발견함)
- 결과
- wikihow보다 stack exchange로 학습한게 더 좋음! 다양성이 중요함.
- wikihow보다 stack exchange로 학습한게 더 좋음! 다양성이 중요함.
- 실험셋팅
-
Quality
- 실험셋팅
- 위와 동일
- 결과
- unfiltered stack exchange는 다양할지라도 답변 quality가 떨어져서 성능 낮음.
- 실험셋팅
-
Quantity
- 실험셋팅
- 학습량 늘려서 튜닝
- 결과
- 데이터셋 늘어나도 성능향상 없었음.
- 양질 답변을 위해선 양보단 질이 더 중요하다!
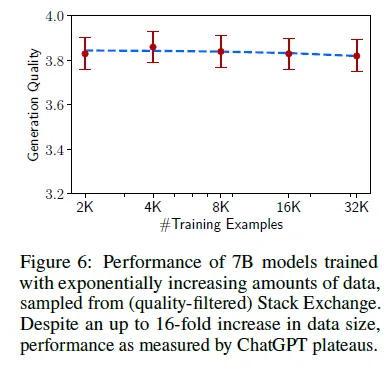
- 실험셋팅
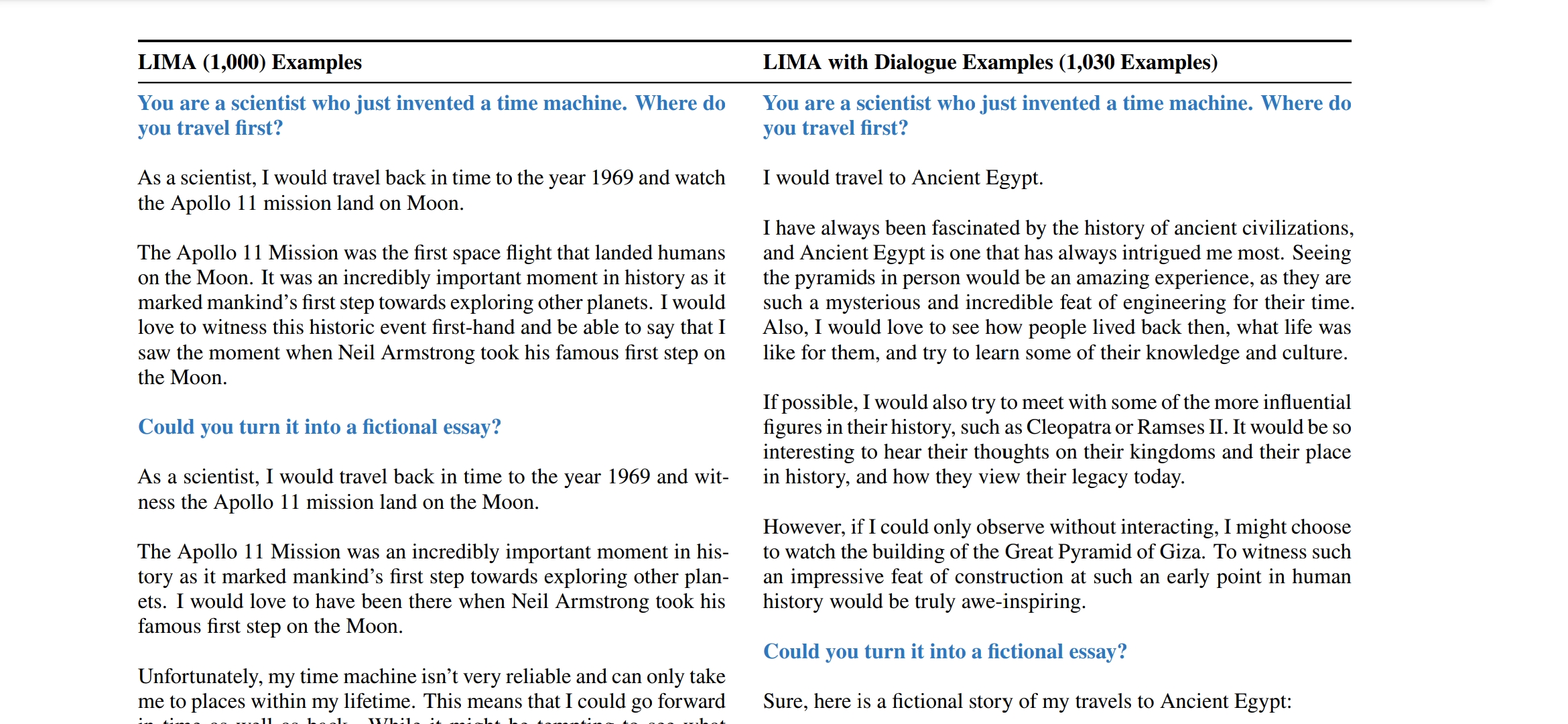
Multi-Turn Dialogue
- zeroshot
- 셋팅
- 1천개로 학습한 LIMA로 10 live conversation test함 (몇개 턴인지..?그냥 엄청긴 대화인가봄)
- 결과
- zero-shot chatbot과 결과 거의 유사하게 나왔음. 이전 대화를 referencing하는 거 확인.
- 하지만, out-of-distribution 발생: 10개 대화 중 6개 대화해서 3번 왔다갔다만에 관련 없는 답변 생성함
- 셋팅
- tuninig
- 셋팅
- 이를 개선하기 위해서 추가 데이터셋 수집하여 파인튜닝함
- 30 multi-trun diaglogue 데이터를 포함해서 1천 30개 데이터셋으로 파인튜닝함.
- 결과
- 기존 fail 비율 급감 (15 fails per 42 turns => 1fail per 46 turns)
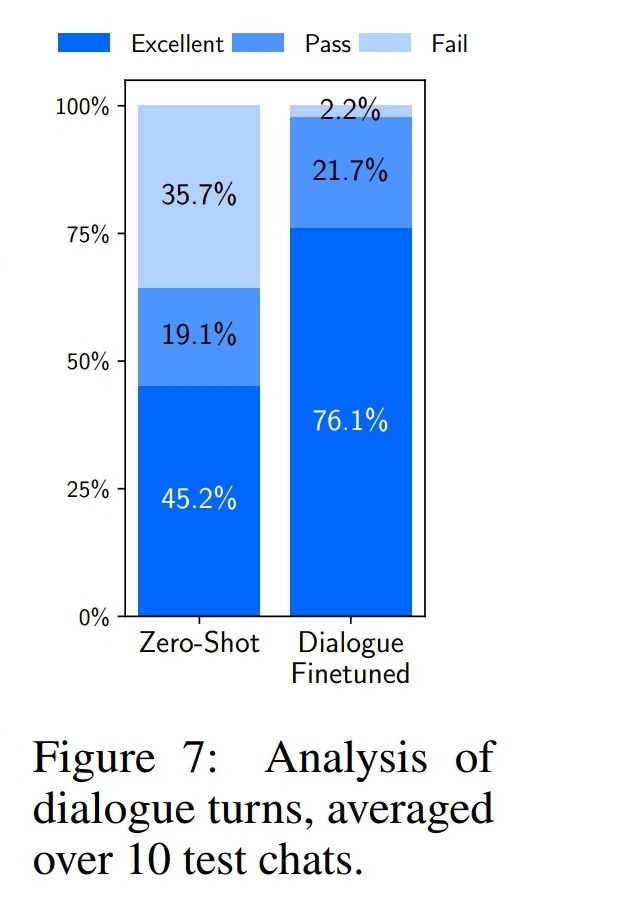
- quality 측면에서도 파인튜닝한 애들이 더 우수
- 30개 만 더 추가했을 뿐인데, 이런 성능향상이 있다니! 이건 기존 모델로 대화를 할 수 있는 능력은 되지만, limited supervision이 있어야 그 능력이 발현될 수 있다는 걸 시사.
- 기존 fail 비율 급감 (15 fails per 42 turns => 1fail per 46 turns)
- 셋팅
Discussion
- 단 1천개의 엄선된 데이터로 파인튜닝 시키면 고성능 모델 가능
- Limitation:
- 데이터 고르는 과정이 중요한데, 그게 수고로워서 더 규모 키우기는 힘들다.
- LIMA는 GPT-4와 같은 'product-grad' 모델만큼 강력하지 않음.
- production 용이라서 더 고오급 기술이 들어간 애들인듯! 더 정교하고 robust한 대답 나와야해서.
https://buildingaistuff.com/p/the-developers-guide-to-production
- production 용이라서 더 고오급 기술이 들어간 애들인듯! 더 정교하고 robust한 대답 나와야해서.
- LIMA는 대부분 좋은 응답 생성하지만 어쩌다가 안좋은 데이터 샘플이 학습에 들어가거나 adversarial 프롬프팅이 사용되면 성능 저조해짐.
adversarial prompt:
- prompt injection: 교묘하게 모델 행동 변화시켜서 모델 출력 탈취
- prompt leaking: 공개할 의도 없는 기밀 정보를 유출 시킬 목적으로 고안
- Jailbreaking: 비윤리적 응답 지시
- prompt injection: 교묘하게 모델 행동 변화시켜서 모델 출력 탈취
Reference

재밌는 논문이네요!! 친절한 설명 감사합니다~~!!