LLMs
1.[LLM] A Survey of Large Language Models
Ref: https://velog.io/@gy77/Review-A-Survey-of-Large-Language-Models-Chapter-2일반적으로 Large Language Models(LLMs)는 방대한 텍스트 데이터로 수천억개(또는 그 이상의) 파라미터
2.[LLM] Scaling Lwas for Neural Language Models (2020)
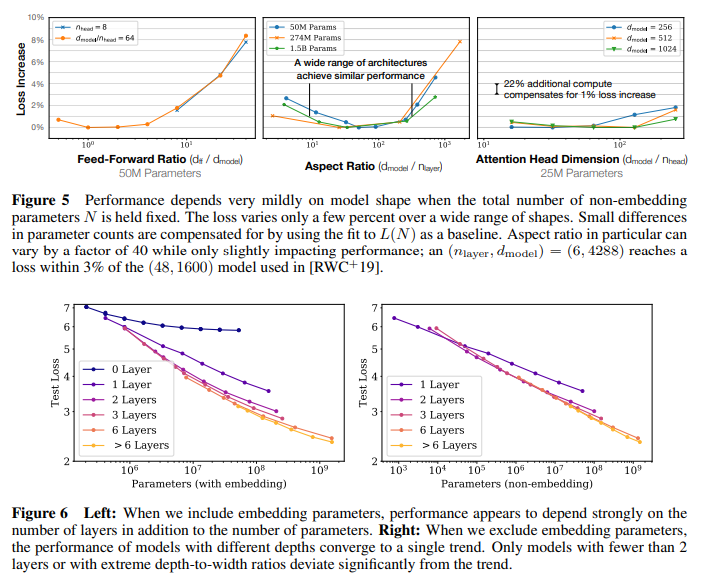
reference : https://velog.io/@zvezda/2024-LLM-%EC%8A%A4%ED%84%B0%EB%94%94-Scaling-Laws-for-Neural-Language-Models-2020본 power-law scaling은 transf
3.[LLM] Mixture-of-Experts
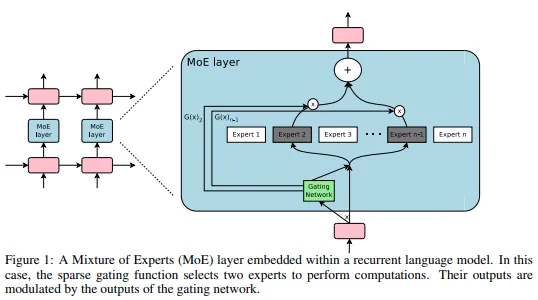
Reference Paper: (구글) https://proceedings.mlr.press/v162/du22c/du22c.pdf https://moon-walker.medium.com/%EB%A6%AC%EB%B7%B0-glam-generalist-language-model-efficient-scaling-of-language-models-with-mixt...
4.[LLM] Prefix Decoder Architecture
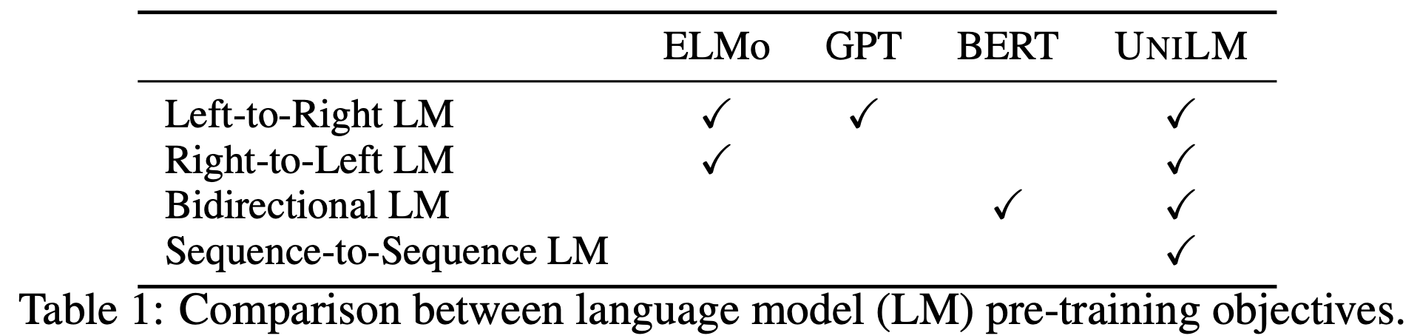
https://obvious-tendency-bc1.notion.site/Unified-Language-Model-Pre-training-for-Natural-Language-Understanding-and-Generation-NeurIPS-2019-a0b7c6e571cc4a1ca0cfd02ce1cdb675 Unified Language Model Pre...
5.[LLM] LIMA: Less Is More for Alignment (NeurIPS, 2023)

paper: Introduction & Summary 연구배경 LLM 발전 동향 (reference) 초기에는 LLM 성능 개선 위해 파라미터 개수 증가에 집중, 최근에는 추론 속도와 제한된 compute 예산을 고려하여 충분한 성능을 제공할 수 있는 작은 모델 선호. LLM의 alignment를 위해 대규모 데이터셋과 컴퓨팅 리소스 줄이려는 노력 ...
6.[LLM] Alignment Tuning
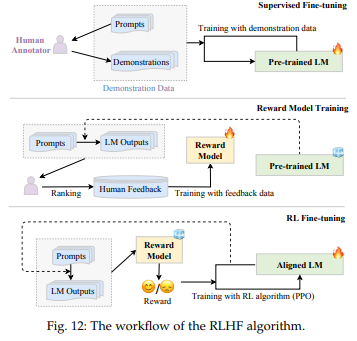
원문 https://velog.io/@zvezda/LLM-study-5.2-Alignment-Tuning Background and Criteria for Alignment Background instruction tuning까지만 진행하면 LLM이 unintended behaviour를 보일 수 있음 (e.g. fabricating false infor...
7.[LLM] SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models (ICML, 2023)

Abstract Quantization할 때 outlier들이 골치임! 이런 애들 더 잘 quantization할 수 있게, 톡 튀어나온 애들 smooth하게, weights들도 비율 맞춰서 조정하는 과정임. Introduction Related Work Large
8.[LLM] Graph of Thoughts: Solving elaborate problems with large language models (AAAI 2024)
Summary [배경] Prompt engineering은 추가 훈련 없이 LLM을 효율적으로 사용할 수 있게 해줌. 하지만 효율적으로 Prompt 디자인하는 것은 challenge함 [기존연구한계] Chain-of-Thoughts: 단 하나의 추론 경로만 가짐.