Unified Language Model Pre-training for Natural Language Understanding and Generation (NeurIPS 2019)
본 논문의 핵심 포인트는 무엇인가?
- UniLM → NLU(Natural Language Model)과 NLG(- Generation) 모두 fine tuning이 가능
- 3가지 Pre-training 진행: Unidirectional LM, Bidirectional LM, Seq to Seq LM
- 1개의 Transformer로 학습
이 연구의 목표:
- 좀 더 general한 NLP task 만들자!
- LLM도 그런 목적이니까, 그 목적 이루기 전 초입 단계 논문인 느낌인가봄!
Introduction
- 배경
-
NLP task의 발전을 이끈 Model Pre-training! (with language modeling)
-
한계점
-
encoder단, decoder단으로 각각 만들어서 잘하는 task가 달랐음.
-
목표
- NLU, NLG 둘다 잘하는 모델 만들자!
- NLU, NLG 둘다 잘하는 모델 만들자!
-
Approach
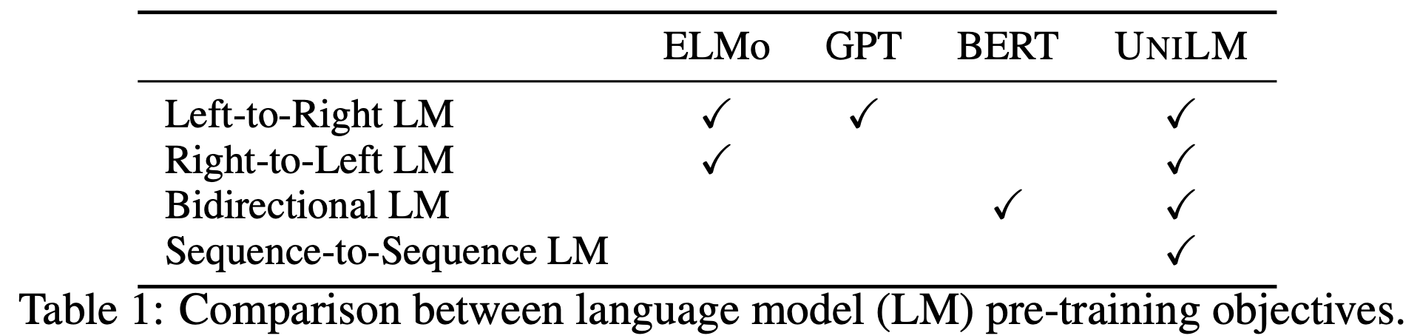
- Unidirectional LM
- 왼쪽에서 오른쪽(LTR) 또는 오른쪽에서 왼쪽(RTL)으로 단어를 순차적으로 예측함
- NLG 작업에서 중요한 역할을 함 (텍스트를 자연스럽게 생성하는 데 유리)
- Bidirectional LM
- 문장의 양쪽 문맥을 동시에 사용하여 단어를 예측함
- 문맥 이해력 강화 → NLU 작업에 유리
- Sequence to Sequence (Seq2Seq) LM
- 입력 시퀀스를 바탕으로 출력 시퀀스를 예측함
- 복잡한 NLG 작업에서 유리함 (예: 번역, 요약 등)
- Unidirectional LM
-
Contribution
- 여러 가지 모델링 기법을 통합한 pre-training은 cloze task를 통해 objective를 정의함으로써 여러 네트워크를 구현할 필요가 없음
- 다양한 모델링 objective로 학습되기 때문에 좀 더 일반화된 representation을 학습할 수 있음
- Seq-to-seq LM을 학습함으로써 더욱 복잡한 NLG task (abstractive summarization, question generation)에서 좀 더 나은 성능을 보임
Method
matrix를 어떻게 구성하느냐에 따라 objective function이 달라짐
오잉?! 세가지를 다 학습할 수 있다는 게 무슨 소리지? 그냥 모델이 세개인건 아닌가?
input은 똑같은데, object에 따라 정보량 (masking) 되는게 다름.
그럼 최종 loss는 다 합쳐?!?!?
뭘 선택하냐가..? 달라???
multi-task learning 처럼?! loss 다 합친다?
근데 왜 ablation 스터디도 없엉?!

왈왈