reference : https://velog.io/@zvezda/2024-LLM-%EC%8A%A4%ED%84%B0%EB%94%94-Scaling-Laws-for-Neural-Language-Models-2020
본 power-law scaling은 transformer architecture 하에서 loss, 즉 performance를 dataset size (D), model size (N), compute budget (C)의 함수로 구성할 수 있다는 아이디어임
Abstract
- LM의 scaling laws를 cross entropy loss에서 empirical하게 확인
- loss는 model size, dataset size, amount of compute used에 따라 power-law로 scale함
- network width, depth는 상대적으로 적은 부분을 차지함
- 한정되어 있는 computing budget에서 optimal allocation을 계산할 수 있음
- 큰 모델은 sample efficient하여 compute-efficient training은 상대적으로 modest amount of data에서도 가능함
Background
- 왜 Power Law인가?
y=k×x^α
power law는 다양한 사회현상을 설명하는 데에 사용되고 있고, CS & AI 에서도 도입된 바 있음e.g. dataset size & model size (ACL 2001)
Scaling Laws in short
최적의 학습파라미터 갯수가 있음! 그때 loss는 얼마큼인가? 이런 걸 계산함.
c는 critical, 즉 임계점을 의미함. 임계점 (critical point) 에서의 N, D, C와 지금 손에 갖고 있는 N, D, C가 존재할 때 loss를 계산할 수 있음
Findings
1. Performance & model scale, architecture
-
모델 성능은 scale과 큰 상관관계가 있으며, 모델 구조와는 큰 관계가 없음: scale은 model parameter (embedding 제외) N, dataset size D, 컴퓨팅 파워 C 로 구성됨. 모델의 depth와 width같은 architectural hyperparameter는 굉장히 작은 상관관계를 가짐 (sec 3)
-
Smooth power laws: N,D,C와 성능의 관계는 다른 요소들에서 bottleneck이 있지 않는 한 (loss 기준) 1e-^6차까지 확인됨 (sec 3)
다른 하나를 늘릴 수록 계속 늘어난다.
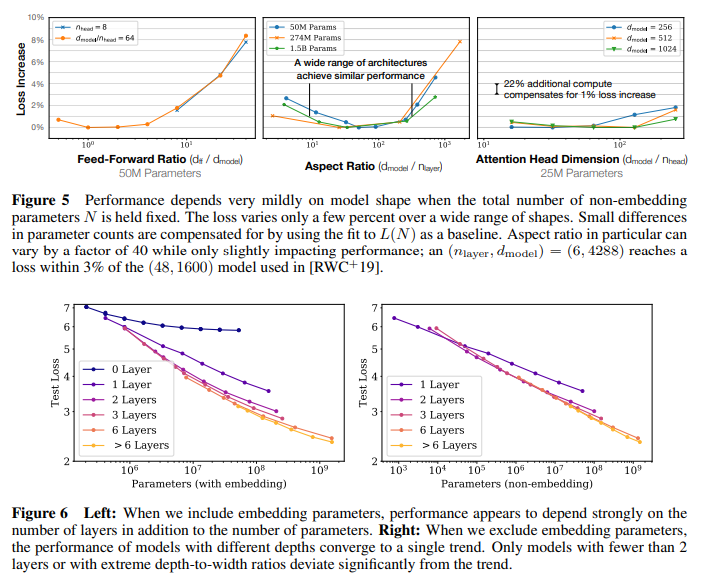
2. Transfer Learning과의 관계
Transfer improves with test performance: training과 다른 distribution을 갖는 dataset에 evaluation 했을 때 (즉, transfer learning을 했을 때), 그 loss 및 penalty는 training set의 결과와 강한 상관관계를 가짐 (sec 3.2.2)
3. 모델 크기와 데이터셋의 적정 비율
Universality of overfitting (모델 크기와 데이터셋의 비율): model parameter N과 dataset size D는 함께 상승시키면 예측가능한 범위 안에서 성능이 상승하지만, 하나를 고정하고 나머지 하나만 증가시키면 일정 지점에서 성능 하락이 발생함 (sec 4)
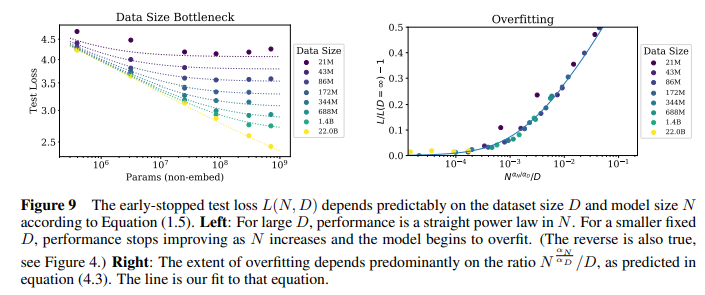
=> 데이터셋 사이즈가 작을 때 모델 크기 커지면 overfitting too much~~~
4. 최적의 배치 사이즈
- Optimal batch size: 모델 학습 시 최적의 배치 크기는 loss의 power law에 따름 (sec 5.1)
- (figure 10) 따라서, loss에 따라서 최적의 batch size를 조절해야 하는데, empirical result에 따르면 loss 13%가 줄어들 때 batch size는 2배로 증가함
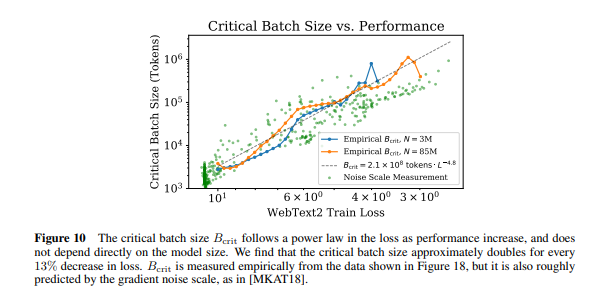
5. 모델 크기와 학습 시간 간 scaling laws
Universality of training: model size와는 별개로 training curve는 power-law를 따르는데, 학습이 더 길어질 때의 loss를 예측할 수 있음 (sec 5)
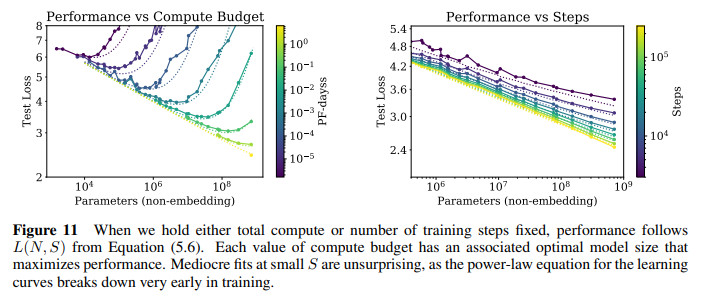
6. Computing Budget의 최적 사용
Convergence is inefficient: computing budget C가 고정되어 있고, model size N과 data size D에 별다른 제한이 없다면, 거대 모델을 사용하여 convergence가 이루어지기 전까지 훈련하는 것이 작은 모델을 사용하여 convergence가 이루어질 때까지 훈련하는 것보다 효과적이며, 데이터 크기 D와 computing budget C의 관계는 D∼C^0.27 과 같음 (computing budget 10배 증가 시 data size는 1.8배만 증가하면 됨) (sec 3 & sec 6) => 모델 파라미터는 5배 증가해야한다?!

=> 큰모델 사용해서 조금만 학습하는게 더 낫다!
7. Sample Efficienty
Sample efficiency: 큰 모델은 작은 모델보다 sample-efficient하며, 이는 optimization step이 적어도 & 적은 data를 사용함으로써 유사한 수준의 성능을 달성할 수 있다는 말임 (fig 2 & fig 4)
Possible Contradictions
Future work
- (figure 15) computing power가 증가할 때 (yellow line), data size를 증가하면서 그려지는 plot(red line)과 만나게 되는데, 이 이후는 연구진의 식과 매치되지 않음
- 해당 point 이후로는 computing budget이 증가할 때, data size가 증가하더라도 성능 향상이 둔화되거나 멈출 수 있음
- 따라서, 새로운 power law를 제시해야 한다고 연구진은 주장
Pros & Cons
- NLP에서 Transformer architecture (decoder-only) 만을 사용했을 때 computing budget (C), model parameter (N), dataset size (D) 와 performance (CEloss로 표현되는) 와의 관계를 empirical하게 처음으로 제시
- 내가 가진 자원 하에서 다른 자원이 얼마나 필요한지, 얼마나 많은 training step이 필요한지 등을 예측할 수 있으므로 공수가 적어짐
- application: overfit 피하기 위해 1B 이하의 모델은 22B 가량의 토큰이 필요하며, 175B 모델 (GPT-3) 을 학습하기 위해 1044B 가량의 토큰이 필요
- 그럼에도, 이 law를 이용해서 실제로 학습한 LLM이 없다는 것은 한계 → Chinchilla's Scaling Law
- 또한, 10B 이상의 LLM에 대한 실험이 없음: open-source로 70B 이상의 LLM이 기 존재한다는 것을 고려할 때, 이는 치명적으로 작동 → Chinchilla's Scaling Law
More on Scaling Laws
패러다임은 얼마나 많은 데이터를 학습시킬 것이냐로 이동
-
Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers (2021)
진짜로 width와 depth는 상관이 없어? 라는 질문에서 시작
OpenAI는 generation에 대한 loss (CEloss) 만을 측정했는데 (사실상 pretraining), 실제로 encoder-only 또는 encoder-decoder 모델에서는 pretrain & finetune pipeline으로 downstream task에 대응하므로, downstream task에 대한 성능 평가가 이루어져야
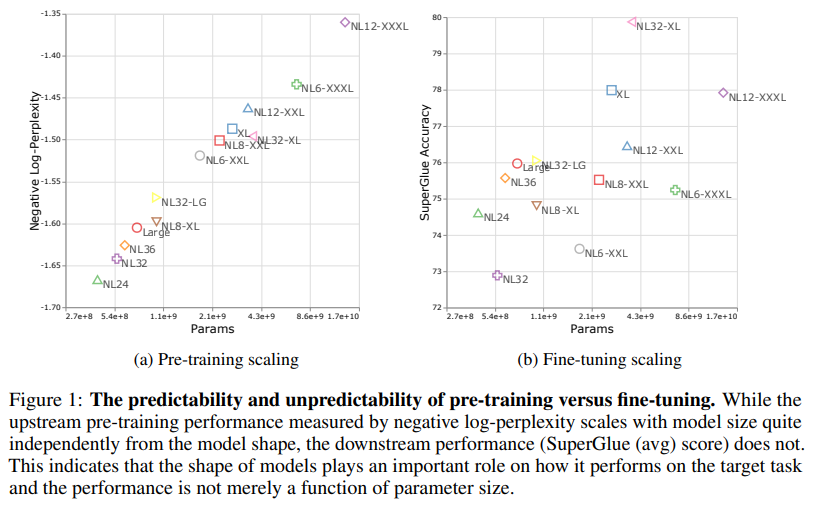
-
Unified Scaling Laws for Routed Language Models (ICML 2022)
Mixture of Experts (MoE) 구조를 사용했을 때, performance와 experts의 수는 power-law를 따름 -
Training Compute-Optimal Large Langauge Models (NeurIPS 2022)
(a.k.a. Chinchilla Scaling Law)- (table 1, table 3) 1B 까지는 OpenAI의 scaling law의 dataset size와 유사하나, 10B 부터는 크게 차이남 (약 3.7배 가량)
- 실제로 70B 규모의 Chinchilla에 1.4tln 규모의 데이터셋을 학습시킨 결과, 4배 규모인 280B Gopher와 유사한 성능을 보임
- 하지만, OpenAI의 scaling law × 3.7이 적절한 dataset size일지?
- LLaMA의 33B 모델은 1.4T token으로 학습했는데, Chinchilla 70B보다 더 좋은 성능을 기록
나의 생각
- 최적의 학습량은 뭘까? 이런건가?!
- 근데 인간의 학습을 생각할 때, 학습량도 중요한데, 그걸 어떻게 linking하냐가 더 중요한 거 같음. => 관련 연구가 있나... black box관련 연구이려나...?
- linking도 cot 로 연결되려나?
- 기존에 있는 데이터를 얼마나 묶음, 그룹화 했냐에 따라서 데이터 효율이 엄청날거같은뎅!!!!!!!!!!!!
(예전에 운전자 집중력 실험할 때 전체를 그림으로 볼 때 효율 엄청나졌던 기억이?)
