Reference
Abstract
Research Background
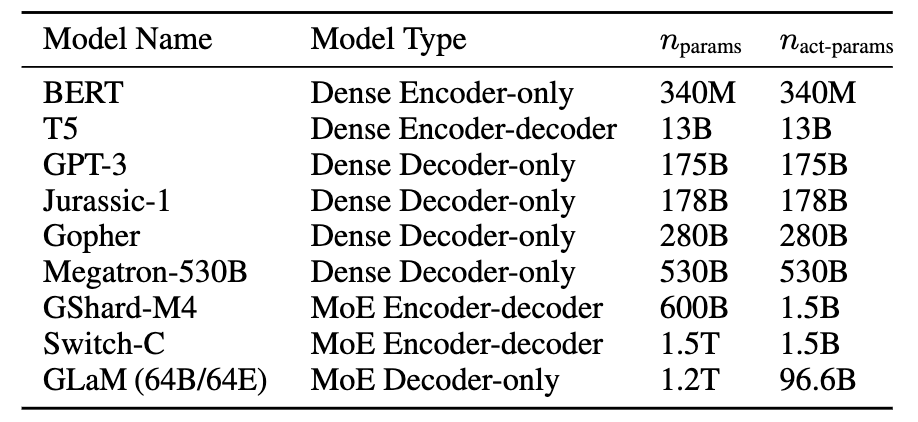
- dataset size (D), model size (N), compute budget (C)를 이용한 Saling language model들 엄청난 성능 보이고 있음.
- 예) GPT3
Challenge
- 거대 언어모델 훈련시키려면 엄청난 양의 computing resources 필요함
Approach
- Mixture-of-experts architecture 사용
Challenge
-
장점:
- 기존 dense model에 비해 일부 파라미터만 사용하기 때문에 빠른 추론
- 전체 모델의 크기를 크게 하지 않고도 성능 향상 가능!
- 분산 컴퓨팅에 good
-
단점:
- 복잡성: 전문가가 여럿이기 때문에 구조가 복잡함. overfitting되기 쉽고, fine-tuning할 때 일반화 어려움. 효율적인 운영 필요함.
- 훈련 어려움: 어떤 expert에게 routing 해야하는 가?! 잘못된 전문가 선택 시 성능 하락 우려
- 추론 속도는 빠르지만, 모든 파라미터들이 RAM에 적재되어 있어야 해서 고용량 RAM 필요
Method
-
Sparse-gate MoE
-
MoE Transformer
-
Switch Transformer
-
GLaM (Generalist Language Model)
-
Mixtral
Mixture-of-Experts (MoE)란?
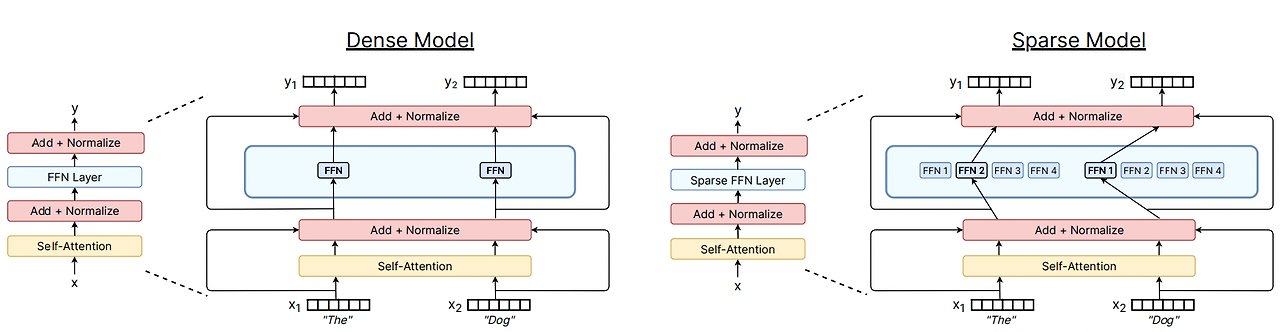
- 딥러닝에서 모델은 일반적으로 모든 입력에 대해 동일한 파라미터를 재사용함.
- But, 전문가 혼합(MoE) 모델은 이를 무시하고, 들어오는 예제마다 다른 매개변수를 선택 (so, MoE를 Routing Network라고도 함)
- 예) 문제 해결할 때 모든 전문가가 나서지 말고, 수학은 수학 전문가가, 과학은 과학 전문가가 해결하자!
MoE 작동원리
-
Sparse MoE layers (Experts)
- 여러 개의 작은 모델들 (신경망 모델)이 각각 다른 일을 잘하는 전문가들처럼 행동.
- 예) Switch Transformer: Transformer 구조에서 MoE는 FFN를 MoE layer로 대체
- 여러 개의 작은 모델들 (신경망 모델)이 각각 다른 일을 잘하는 전문가들처럼 행동.
-
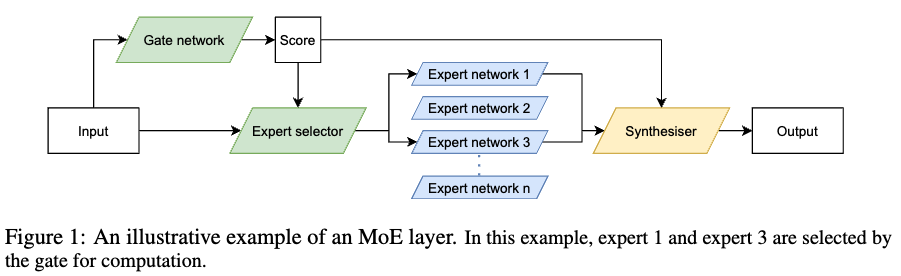
Gate Network or Route
- 입력 (e.g. token)을 받으면, 어떤 Expert를 배정해줄 지 결정해주는 Network
- 각 입력 or 각 token 당 하나 이상의 expert가 배정됨
- 배정된 expert들이 수행한 연산 결과를 모아 최종 결과 계산
MoE Challenge
-
장점:
- 기존 dense model에 비해 일부 파라미터만 사용하기 때문에 빠른 추론
- 전체 모델의 크기를 크게 하지 않고도 성능 향상 가능!
-
단점:
- 복잡성: 전문가가 여럿이기 때문에 구조가 복잡함. overfitting되기 쉽고, fine-tuning할 때 일반화 어려움. 효율적인 운영 필요함.
- 훈련 어려움: 어떤 expert에게 routing 해야하는 가?! 잘못된 전문가 선택 시 성능 하락 우려
- 추론 속도는 빠르지만, 모든 파라미터들이 RAM에 적재되어 있어야 해서 고용량 RAM 필요
MoE의 역사
- Adaptive Mixture of Local Experts (1991)
- Learning Factored Representations in a Deep Mixture of Experts (2013)
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (2017)
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (Jun 2020)
- GLaM: Efficient Scaling of Language Models with Mixture-of-Experts (2021)
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (2021)
- ST-MoE: Designing Stable and Transferable Sparse Expert Models (Feb 2022)
- FasterMoE: modeling and optimizing training of large-scale dynamic pre-trained models(April 2022)
- MegaBlocks: Efficient Sparse Training with Mixture-of-Experts (Nov 2022)
- Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models (May 2023)
- Mixtral-8x7B-v0.1, Mixtral-8x7B-Instruct-v0.1.
🍎 초창기
👉Adaptive Mixtures of Local Experts (1991년)
- 최초 제안
- 초기 MoE는 ensemble 방법과 유사.
- 여러 network로 구성된 시스템에서 각각이 다양한 하위집합들 관리함.
👉Experts as Components (2014년)
- 배경: MoE가 하나의 시스템이 아닌, Multilayer network의 일부로 포함되기 시작
- 이로 인해 모델이 더 커지고 효율적일 수 있게 되었음
- Learning Factored Representations in a Deep Mixture of Experts
👉Conditional Computation 조건부 계산 (2014년)
- 배경: 기존 MoE는 모든 input은 모든 layer 통과해야했음.
- 입력에 따라 동적으로 layer 활성화 시키는 방법 조건부 계산 idea 활용 (요슈아 벤지오)
=> 이 개념이Sparsity - Conditional computation in neural networks for faster models
🍎 본격 MoE in NLP
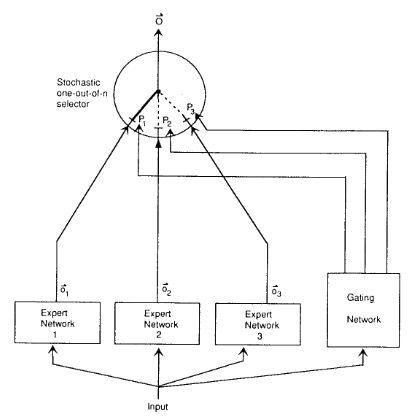
👉Outrageously Large Neural Networks: The Sparsely-gated Mixture-of-Experts Layer (ICLR,2017)
- 배경
- LSTM 사이에 MoE 내장해서 scale up한 언어모델 (Transfomer 2저자)
- LSTM 사이에 MoE 내장해서 scale up한 언어모델 (Transfomer 2저자)
- 작동 방식
-
전통 MoE gating 함수 G, Experts E
- 이게 모든 MoE 쓰는 애들이 사용하는 기본 수식
- softmax에서 나온 결과값 G는 i번째 expert가 할당될 확률
- E는 input x가 i번째 expert nextwork 통과해서 나온 값
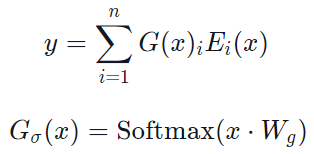
-
Noisy Top-K Gating
- 조정가능한 노이즈 도입한 후에, softmax에 의해 top-k experts 선택!
- 각 expert들이 도출한 결과값 weighted sum해서 다음 layer로 보냄.
- 이때 라우팅하는 G가 0인 경우에는 계산 필요없으니까 연산 절약 가능!

✅ Load balancing issue!
- 이때, noise를 포함하는 건 load balancing issue 완화 때문임.
- 입력들이 소수의 experts에만 쏠리면 학습이 비효율적임.
- 이를 완화하기 위해서 모든 expert들이 균형있게 선택되도록 부가적인 loss (auxiliary loss) 추가함. (tunable noise)
- 그래서 선택과정을 더 확률적으로 만들어서 탐색하게 함
-
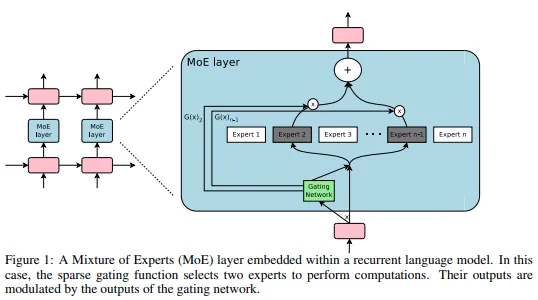
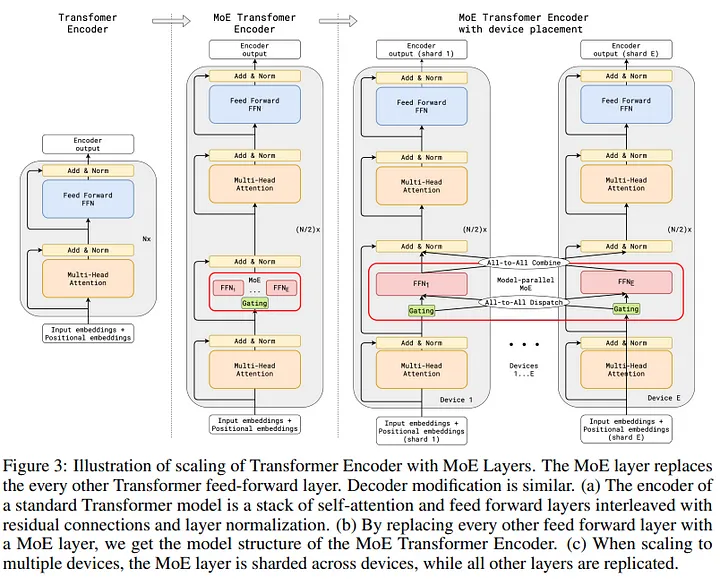
🍎 MoE & Transformer
👉 GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (arxiv, 2020, ICLR,2021)
-
배경
MoE 활용해서 Transformer를 600B까지 scale up한 모델 (MoE transformer라고 부름) -
모델
-
(1) Transformer Encoder의 FFN 레이어를 MoE로 대체 (2번째 그림)
-
(2) 한 token 2개의 experts 작동 (top-2)
-
(3) experts 디바이스에 분산 => 각 디바이스 expert에 입력 보내기 => 해당 expert의 연산 결과 다시 가져오기 (3번째 그림)
✅ 효율적인 분산 컴퓨팅
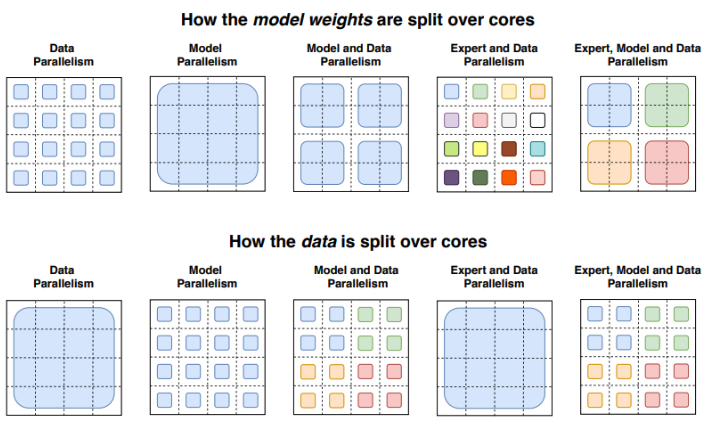
- 대규모 모델 훈련할 때 분산 컴퓨팅 사용하는 게 일반적임. 시간+자원 줄이기 위해서 여러 컴퓨팅 장치에 작업 분배해서 동시에 처리
- 예 1. Data paralleism: 모델을 여러 곳에 복제해서, 데이터셋을 나눠서 훈련
- 예 2. Model Parallelism: 모델 자체를 여러부분으로 나눠서 다른 장치에서 훈련. 이때 필요한 경우 서로 통신하여 중간 결과 교환.
- 예 3. MoE: 다른 레이어는 다 복제하고, MoE 레이어는 디바이스끼리 공유(분산)! 전문가들이 여러 장치에 걸쳐 분산되는 거니까, 많은 전문가들이 동시에 활성화되어 계산 수행 가능! 전문가가 다른 쪽에 있으면 거기로 input보내서 결과 가져오기.
- 대규모 모델 훈련할 때 분산 컴퓨팅 사용하는 게 일반적임. 시간+자원 줄이기 위해서 여러 컴퓨팅 장치에 작업 분배해서 동시에 처리
-
-
Load balancing issue 해결 방법
-
auxilary loss
-
Randon routing:
-
top-2 expert: 이때 점수 가장 높은 expert 첫번째로 선택하고, 두 번째 expert는 각 점수(weights)에 비례하는 확률로 추출
-
top1은 무조건 softmax에서 나온 값 중에서 제일 높은 애로 정하는데, 두 번째 놈은 random으로 설정함. 그런데 그 random으로 뽑을 때 각각의 expert 뽑힐 확률은 weights에 비례하게 계산
import numpy as np # 4명 전문가들의 게이트 확률 gate_outputs = np.array([0.6, 0.2, 0.15, 0.05]) # Top-1 전문가 선택 top1_index = np.argmax(gate_outputs) top1_expert = gate_outputs[top1_index] # 나머지 전문가들 중 두 번째 전문가 확률적으로 선택 remaining_indices = np.delete(np.arange(len(gate_outputs)), top1_index) remaining_gates = gate_outputs[remaining_indices] # 확률 분포를 계산 total_remaining_gates = np.sum(remaining_gates) probabilities = remaining_gates / total_remaining_gates # 두 번째 전문가 확률적으로 선택 second_expert_index = np.random.choice(remaining_indices, p=probabilities) # 결과 출력 print(f"Top-1 Expert Index: {top1_index}, Gate Output: {top1_expert}") print(f"Second Expert Index: {second_expert_index}, Gate Output: {gate_outputs[second_expert_index]}")
-
-
Expert capacity (전문가 역량): 각 expert 마다 몇 개의 token까지 수용 가능한지 설정
- 각 전문가에게 얼마나 많은 토큰 전달될지 미리 고정해놔야 함.
- 전문가들이 다 임계값 넘어버리면 overflow되어 버려서, 남은 token들은 residual connections로 다음 layer로 가버리거나 삭제되어버림!
-
-
저자가 밝힌 한계점
- Top-K 고르는데 load balancing 문제 여전~
- experts들이 디바이스들마다 분산되어 있어서, 디바이스간 통신 비용이 매우 크다고함.
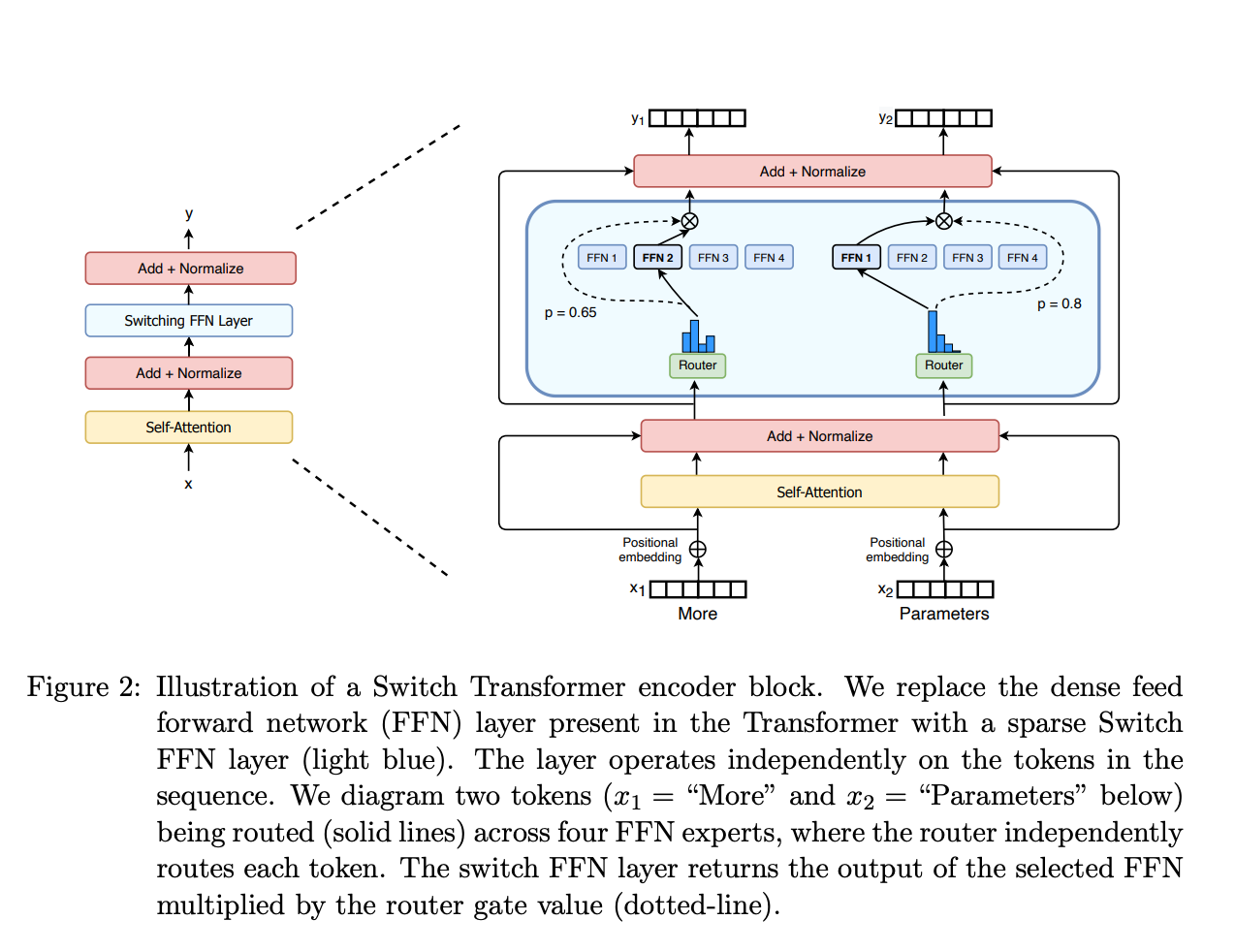
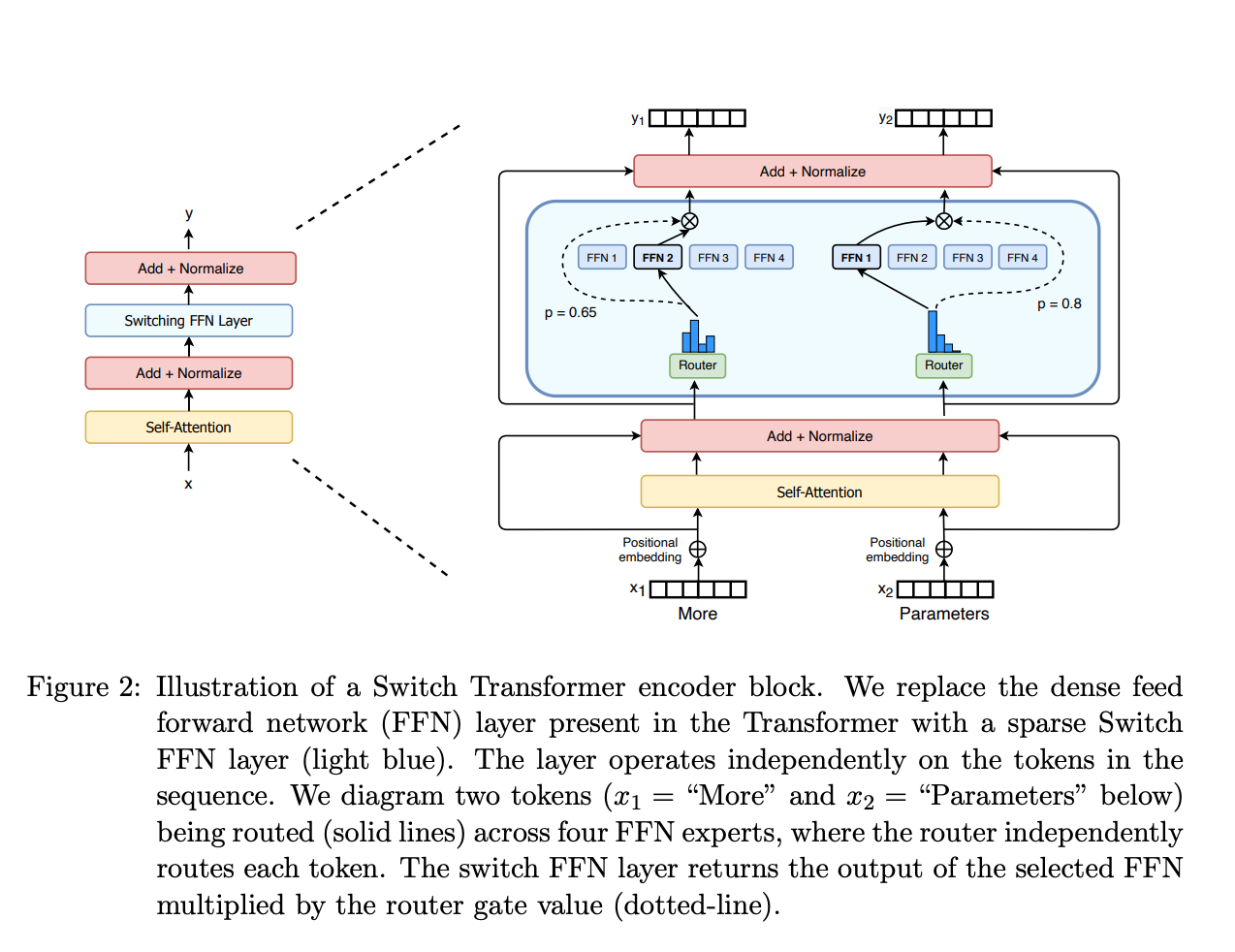
👉 Switch Transformer (arxiv 2021, JMLR 2022)
-
배경:
MoE 사용할 때 발생하는 다음 3가지 줄이기 위한 연구- ①complexity
- ②communication costs
- ③training instability
-
모델
-
(1) Simplifying Sparse Routing
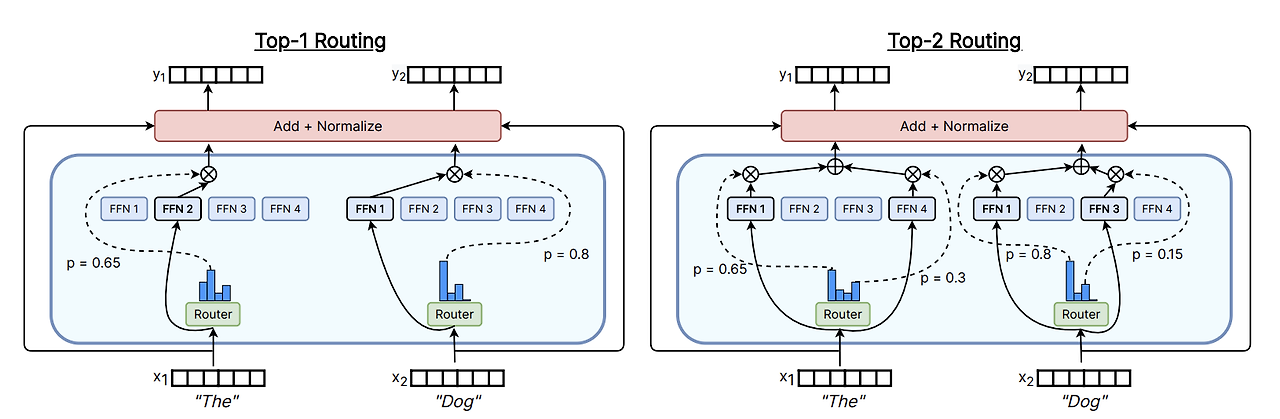
- Switch Routing (Top-1): 기존에는 sequence 당 전문가 2명, 여기서는 token마다 expert 1개로 설정
- 장점1) 라우팅 위한 연산 감소, expert들끼리 비교 안해도 됌
- 장점2) token당 하나 expert 배치하니까, expert capacity 최소 절반 이상 감소
- 장점3) 라우팅 구현 simple, 비용 감소
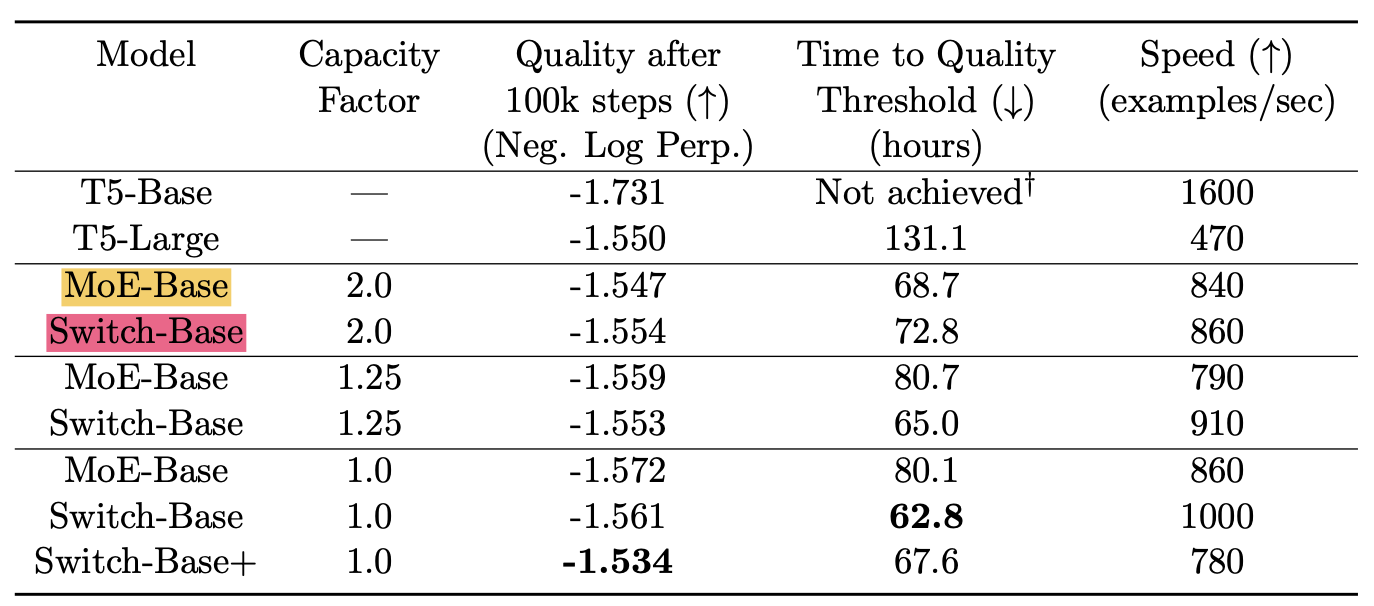
- 관련 실험결과:
T5랑 MoE transformer 비해 speed랑, quality 좋음
- Switch Routing (Top-1): 기존에는 sequence 당 전문가 2명, 여기서는 token마다 expert 1개로 설정
-
(2) Efficient Sparse Routing
-
(a) Distributed Switch Implementation: Expert Capacity 설정 강화!
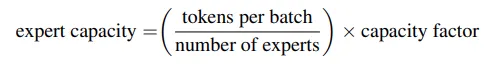
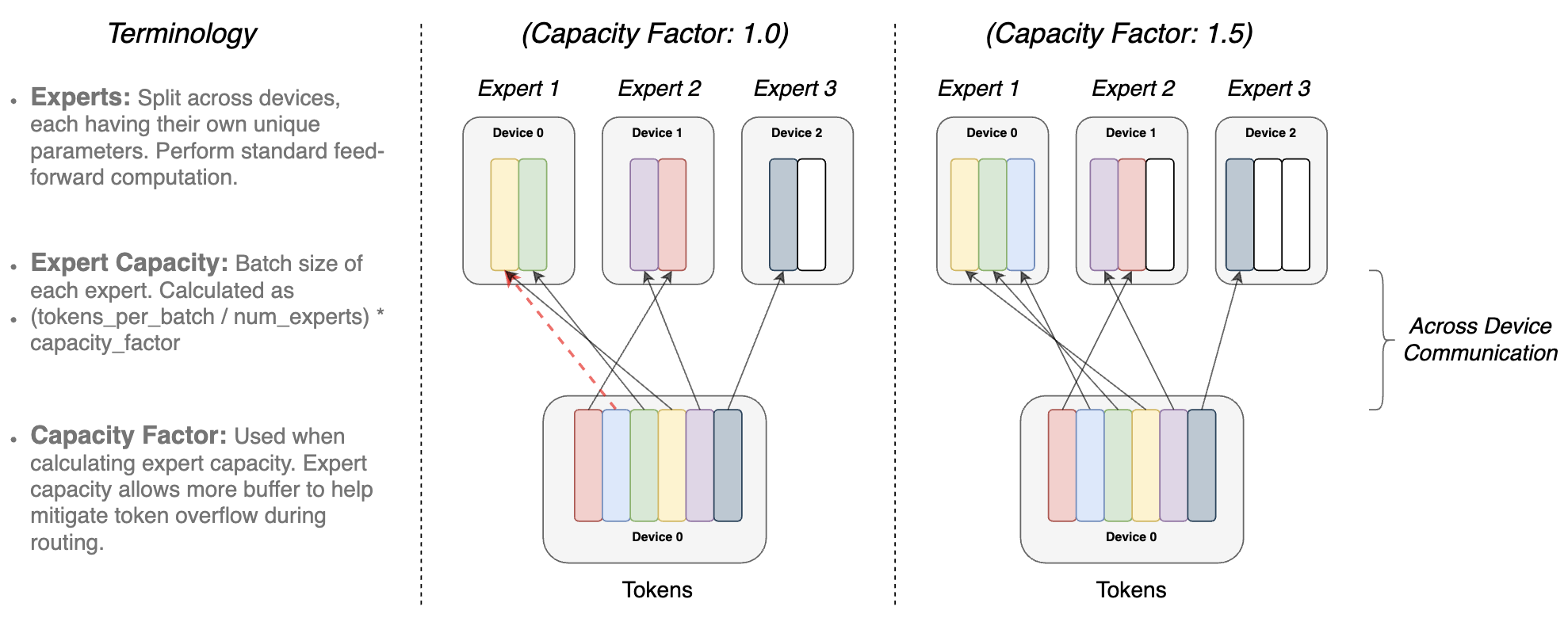
- capacity factor는 input이 uneven하게 distributed될 때 완충제 역할 하기 위해 존재하는 파라미터!
- 한 expert에 여러개 몰릴 수 있으니까, capacity factor로 조절해가지고 overflow 방지 (capacity 작으면, input skip해버림)
- switch transformer에서는 낮은 capa factor (1~1.25)가 good
-
(b) A Differentiable Load Balancing Loss: Auxiliary loss
- 각 switch layer에 aux loss 추가해서 최종 loss랑 합쳐짐
-
-
-
훈련 방식의 효율 높이기
- (a) selective precision training
- 자료형에 따른 연산속도가 엄청나게 차이가 있더라
- communication 할 땐 가벼운 bfloat16 / router 계산할 때는 stability 높일 수 있는 float32

- 속도 빠르고! 성능은 굿!

- (b) Smaller parameter 초기화: 기존 초기화값보다 더 작게 초기화
- (c) regularization
expert랑 non-expert 각각 dropout 해줬더니 성능 올라가더라
- (a) selective precision training
-
실험 결과:
- 2048개 experts, 1.6trillion parameters MoE
- huggingface에 공개해놓음! transformer로 돌릴 수 있음.
- Downstream task
- T5가 백본인데, T5 보다fine-tuned tasks 잘함
- same FLOPS per token, but 7x+ 스피드업
- 파라미터를 비교하는게 의미가 없다. 파라미터 수는 엄청나게 많지만, 연산 되는 비용이 적음. 그니까 FLOPS를 동일하게 비교하자!

- Distillation
- sparse pre-trained & fine-tuned model을 작은 dense model로 distillation 성공. 모델 사이즈는 99%줄이고, teacher의 성능 30%는 보존
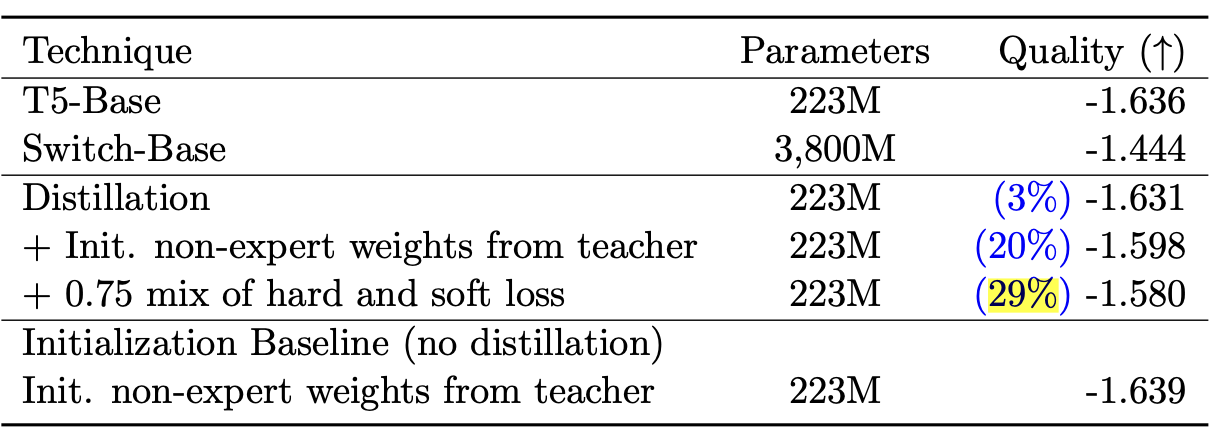
- sparse pre-trained & fine-tuned model을 작은 dense model로 distillation 성공. 모델 사이즈는 99%줄이고, teacher의 성능 30%는 보존
- Multilingual 에서도 좋은 성능!
-
Discussion (자문자답)

👉 (2021년) GLaM:: Efficient Scaling of Language Models with Mixture-of-Experts
https://research.google/blog/more-efficient-in-context-learning-with-glam/
-
배경
- GPT3를 백본으로 decoder only 방식 (Switch-T는 encoder-decoder) 사용해서 더 효과적인 in-context-learning 하자!
- decoder-only models
- fine-tuning보단 few-shot, one-shot evaluation 초점
- GPT3를 백본으로 decoder only 방식 (Switch-T는 encoder-decoder) 사용해서 더 효과적인 in-context-learning 하자!
-
Dataset
- 1.6 trillion token dataset (1조 6천억개) 구축.
- Wikipedia and books
-
모델
- 1.2T 파라미터, but inference에서는 전체 파라미터의 8% 97B만 활성화
- 총 32개 MoE layer, MoE layer 당 64개 expert
- Top-2 routing (Expert 2개만 활성화)
- 기존 Transformer에서 수정된 사항 (변경 이유나 실험은 나와 있지 않음)
- positional embedding => per-layer relative positional bias
- by original연구: 절대위치 아니고, 상대 위치가 temporal confusion 더 최소화 한다
- Non-MoE Transformer Feed-Forward sub-layer에서 첫번째 linear projection & activation 함수를 ReLU => Gated Linear Unit로 교체
- by original연구: component-wise product of two linear projection. 실험결과 ReLU, GELU 보다 품질 개선
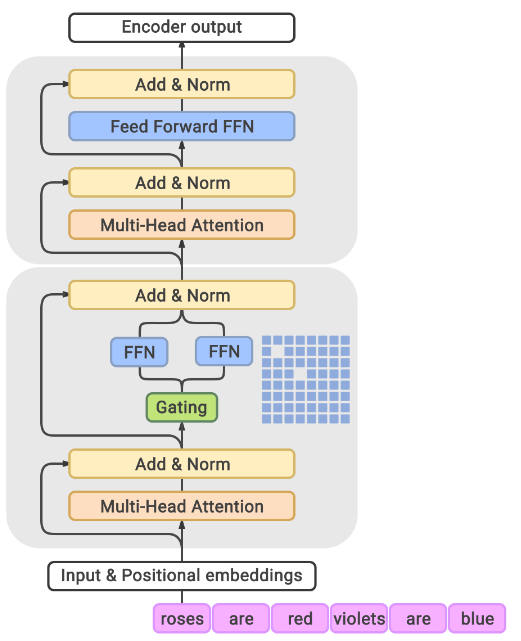
- by original연구: component-wise product of two linear projection. 실험결과 ReLU, GELU 보다 품질 개선
- positional embedding => per-layer relative positional bias
-
Model Partitioning (for scaling & training cost)
-
각 expert들은 여러 디바이스로 놔눠져 있음
-
이때, GSPMD 컴파일러 백앤드 사용하여 전문가 scaling할 때 생기는 문제 해결
- 2D topology 활용하는, 2D sharding 알고리즘 적용해서 GLaM모델의 weights와 computation 분할해서 동시 작업가능 하게!
- 서로 다른 층의 MoE layer에서 동일한 계산 그래프(계산 수행 과정)가 나올 수 있게, 같은 장치 내 서로 다른 MoE layer에 동일 index 가진 expert 배치
- 그럼 반복적인 모듈을 while_loop control flow문 쓰면 되니까 컴파일 시간 단축 가능
GSPMD (General and Scalable Parallelization for Neural Networks)
- 2D topology: 컴퓨터 네트워크에서 장치들이 2차원 형태로 연결. (여러 대 컴퓨터가 행과 열로 배열)
- 2D sharding: 큰 데이터를 2차원 형태로 나눔 (큰 직사각형 종이를 작은 정사각형 조각들로)
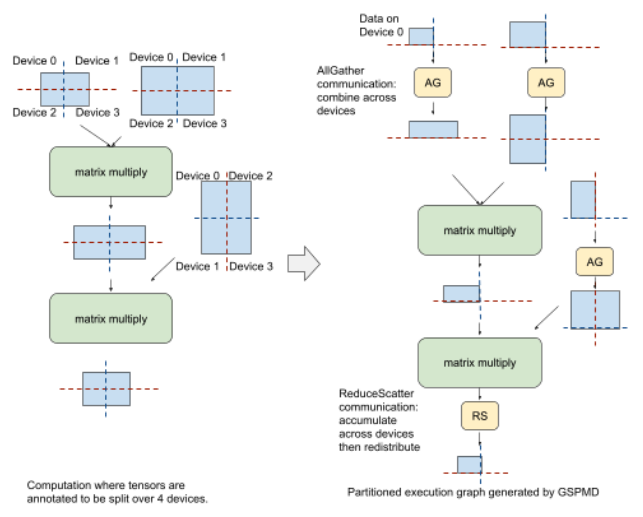
-
-
실험 결과
-
거대 파라미터 대비 적은 에너지 소모
- GPT-3의 7배 파라미터 (1.2 trilion parameter)
- GPT3의 1/3 에너지 사용
- GPT3의 절반의 computation flops for inference

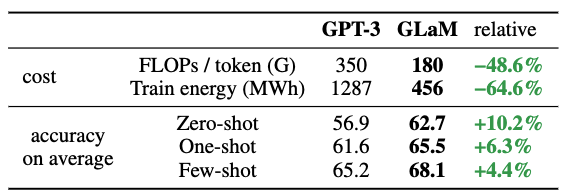
-
GPT3보다 zero, one, few-shot에서 29개 NLP task에서 더 좋은 성능

-
capacity factor 훈련 중에 컴퓨팅리소스에 따라 변경 가능
-
- GLaM(8B/64E): Transformer 레이어-8B parameter dense 모델/ Non-transformer 레이어- 64 expert MoE 레이어
- GLaM(137B): 같은 데이터셋으로 학습된 dense 137B 파라미터 모델
👉 Mixtral 8X7B (arxiv, 2024)

-
배경:
LLama2 백본으로 하는 mistral에 MoE 결합한 Sparse Mixture of Experts (SMoE) language model. -
차별점:
-
Mistral7B랑 동일 아키텍처, but 각 레이어가 8개의 Experts로 구성
-
2개 expert (top-2 routing)
-
결과
- 47B개 파라미터, inference 시에는 13B만 활성화
- 32k 토큰 컨텍스트로 trainig
- Llama 2 70B 및 GPT-3.5보다 성능 뛰어나거나 비슷
- 특히 수학, 코드 생성, 다국어 벤치마크에서 Llama 2 70B 크게 앞지름
- Mixtral 8x7B - Instruct는 휴먼 벤치마크에서 GPT-3.5 Turbo, Claude-2.1, Gemini Pro 및 Llama 2 70B 능가
What does an expert learn?
-
Mixtral 8X7B

- 각각의 expert들이 선택되는 기준이 도메인 보다는 문서에서 각 토큰이 가지는 구문적 성질에 더 좌우받는다는 것 확인
- 입력과 출력과 큰 연관있는 첫 번째 & 마지막 레이어에서 더욱 두드러지게 나타남
-
ST-MoE
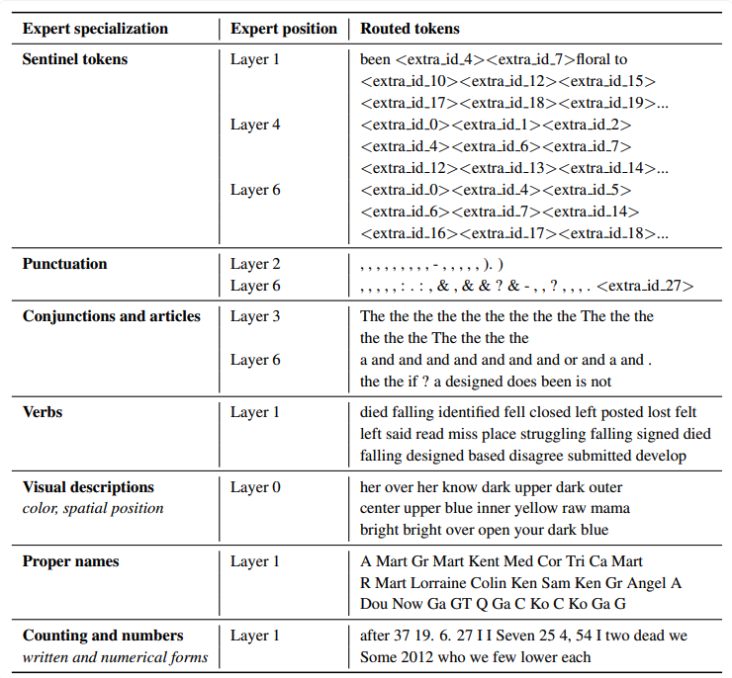
🐶 Multimodal 연구자를 위하여
-
Scaling Vision with Sparse Mixture of Experts (NeurIPS, 2021)
: MoE를 ViT에 적용하여 절반의 계산 비용으로 동일한 성능을 내는 V-MoE 제안https://arxiv.org/abs/2106.05974
https://ostin.tistory.com/346 -
AdaMV-MoE: Adaptive Multi-Task Vision Mixture-of-Experts (ICCV, 2023)
:a fixed network capacity는 overfitting 문제 있을 수 있음
 => 패치별로 활성화된 Experts들
=> 패치별로 활성화된 Experts들
=> 오쫌 Vision GNN 느낌나는 결과인걸~?
Take-home-message & Discussion
-
-
기존 모델들에 MoE 결합하는 걸로 새로운 연구 제시하는 것들이 많군

MoE에 대해서 몰랐는데 꼼꼼히 알려주셔서 좋았습니다
!!