[Multimodal #1] ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks (NeurIPS, 2019)
Multimodal
인용이 무려 1927회!ㅇ_ㅇ (23.01.28 기준)
Introduction
Background
-
'Vision-and-Language' Task (
VL taskfor short)
: image나 video를 input으로 받고 text로 output 뽑아서 visual understanding하는 task -
Visual Grounding
'Vision-and-Language' Task를 위해서는 보통 visual grounding (language랑 vision stimuli를 aligning하는 것; 각 object들 matching이 되어야 뭔 말인지 아니까~)을 잘 할 수 있어야함. -
Self-Supervised Learning for Vision-and-Language
- language 쪽이랑은 달리 vision 쪽에서는 self-supervised image representations이 supervised 방식의 image classification tasks보다 한참 뒤떨어진다.
- 그래서 보통은 language랑 vision 따로따로 학습 을 시킨 후에 나중에 multi-modal task할 때만 grounding을 학습하는 형태임.
- 하지만 이 방식은 실제 task에 사용될 visuallinguistic paired 데이터가 한정되어 있거나 biased 되어있는 경우에는 grounding을 잘 학습하지 못한다는 거니까, 결과적으로 poor generalization을 보여줄 수 밖에 없음.
Challenge
VL task를 잘 수행하기 위해서 물론 visual, linguistic 각각에 대해 understanding하는 것도 중요하지만, 두 representation간의 연관성을 파악하지 못한다면 말짱도루묵.

Goal
To pretrin for visual grounding => visual-grounding 잘하는 common model을 만들어보자! 그리고 이 모델로 두 모달간의 관계도 학습해보고, VL task할 때도 잘 써먹어보자~!
Vision & Language BERT (ViLBERT)
-
1) Conceptual Captions dataset 사용해 pretrain
vision-language alignmnet하기 위한 적합한 데이터셋 필요 (기존 self-supervised learning 방식의 연구들에서 영감)download: https://ai.google.com/research/ConceptualCaptions/download
-
2) BERT 구조 확장
vision, language 처리를 각각 개별 stream에서 처리 후 co-attentional transformer layer를 통해서 두 modality간의 communication 제공! -
3) pretrain을 위한 proxy tasks
- predicting the semantics of masked words and image regions given the unmasked inputs
- predicting whether an image and text segment correspond
-
4) transfer learning을 위한 VL downstream task
- Visual Question Answering (VQA)
- Visual Commonsense Reasoning (VCR)
- Grounding Referring Expressions
- Caption-Based Image Retrieval
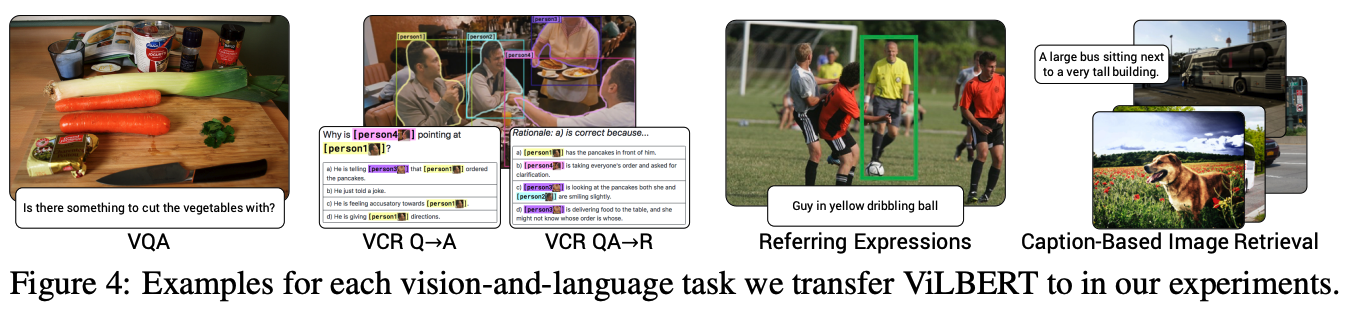
Contribution
- 기존에 vision, language 따로따로 학습한 모델들에 비해 multi-modal downstream task에서 2-10% 성능 향상!
- minor한 구조 변경만으로도 SOTA 달성
- visual grounding (language-vision align하는 거)도 pretrain이 가능하고, transferable 하다는 것을 확인함.
ViLBERT: Extending BERT to Jointly Represent Images and Text
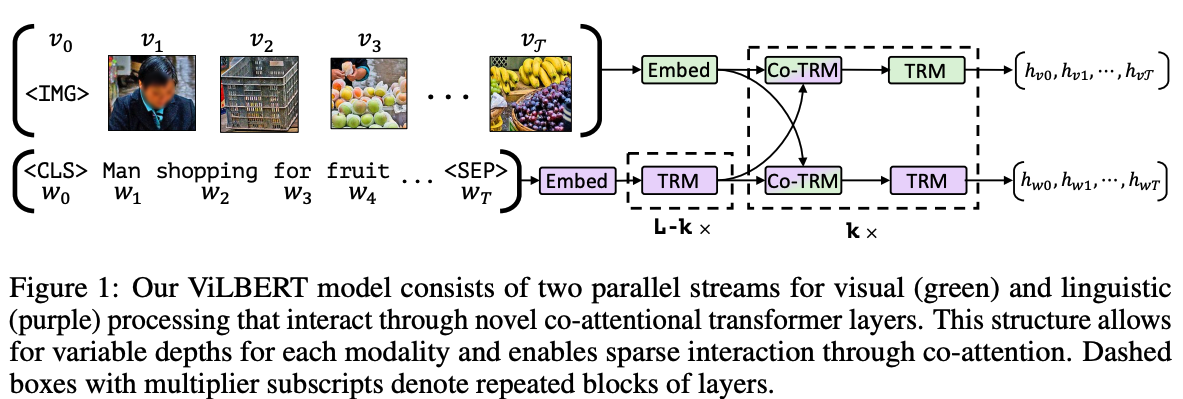
Modality Representation
-
Videobert (2019,ICCV)와 달리 text, vision 각각 다른 stream 구성한 이유
- 1) visual 디테일 정보를 잃을 수 있다.
- 2) 두 modalities의 processing 방식이 다를 수도 있는데, 모델은 두 modal을 동일하게 취급해버림
- 3) 기존에 학습된 pretrained languge BERT에 억지로 visual feature에 대한 weight를 학습하게 시켜버리면 원래 BERT의 정보마저 손상시킬 수 있다.
Ref: Videobert (2019, ICCV)
visual token을 text token처럼 취급하면서 단순히 clustering만 해서 각각의 space를 분리하려고 시도
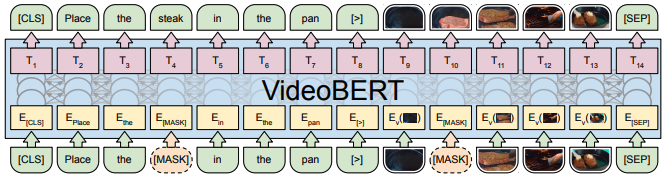
-
Text Representation
- tokenizing: 기존의 BERT 방식 그대로~ (e.g. [CLS], w1, w2, [SEP], ,,,)
- representation: a sum of a token-specific learned embedding and encodings for position
-
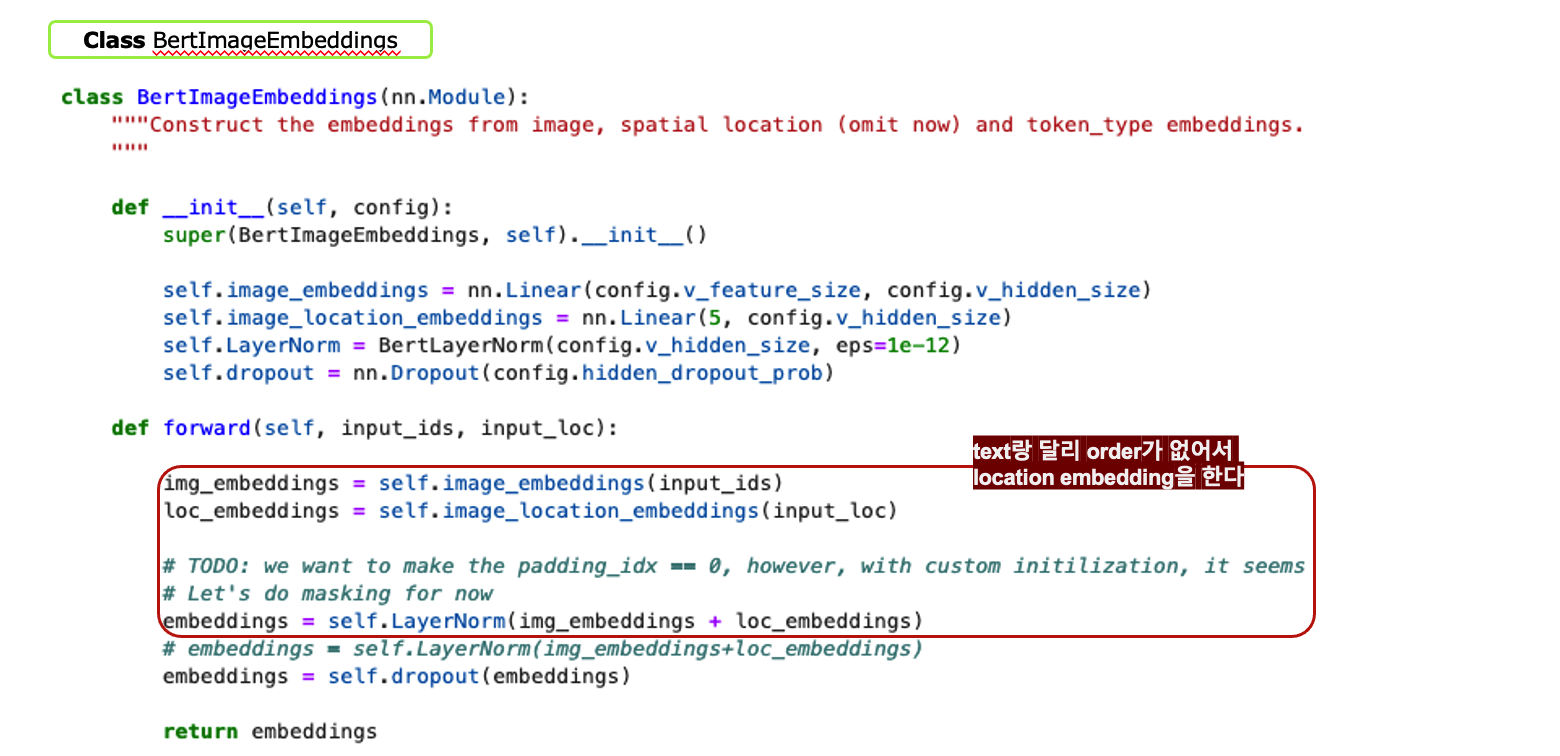
Image Representations
- generate image region features
- pre-trained object detection network bounding box 추출하고 visual feature 뽑음
- spatial location encoding
- text에서는 positional encoding을 하는데 image region은 순서라는게 없음. 그래서 spatial location을 encoding한다.
- 좌표 그려서 region position이랑 image 조각낸 거 정보 가져와서 5-d vector 만듦
- 그래서 visual feature랑 최종적으로 sum을 한다.
- [IMG] token: imgage region sequence 앞에 [IMG] 토큰 붙여서 text의 [CLS]토큰처럼 전체 이미지를 대표하는 토큰으로 만들었음. (i.e. mean-pooled visual features with a spatial encoding)
- generate image region features
Co-Attentional Transformer Layers (Co-TRM)
- 기존과 달라진 점!
- 기존 transformer에서는 self-attention을 해서 query, key, value가 모두 자기 자신
- Co-TRM에서는 query는 target modality의 representation이고, key,value는 source modality의 representation이 된다.
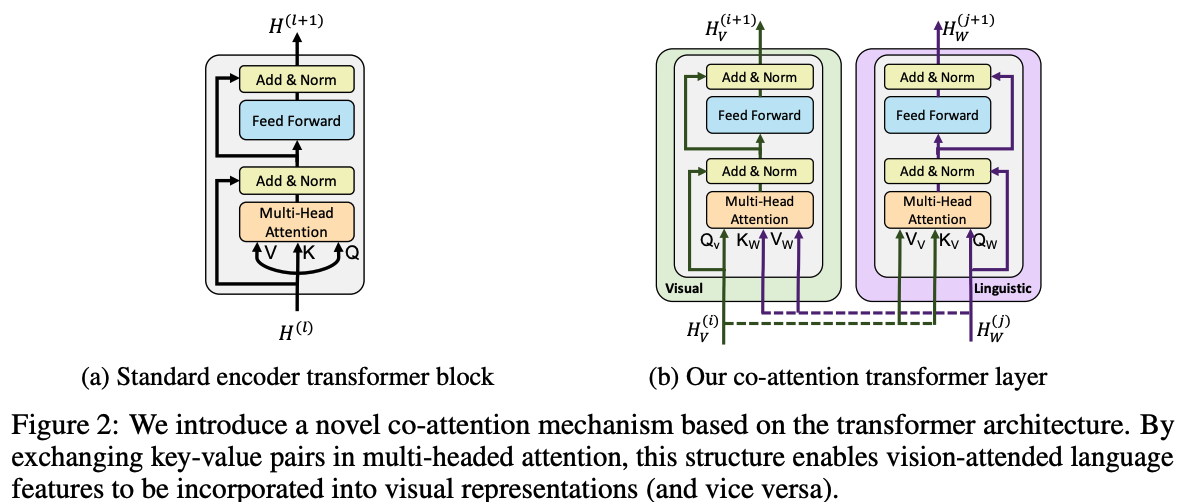
그.런.데! co-attention의 최초는 따로 있다??
Faster R-CNN (2015, NeurIPS), Referitgame (2014, EMNLP) 에서 이미 co-attentional transformer와 비슷한 구조로 실험한 적이 있음! 아예 똑같단 건 아니고...! 그래서 이 논문은transformer구조를 썼다는 점이 차별점인가봄.
Training Tasks and Objectives
-
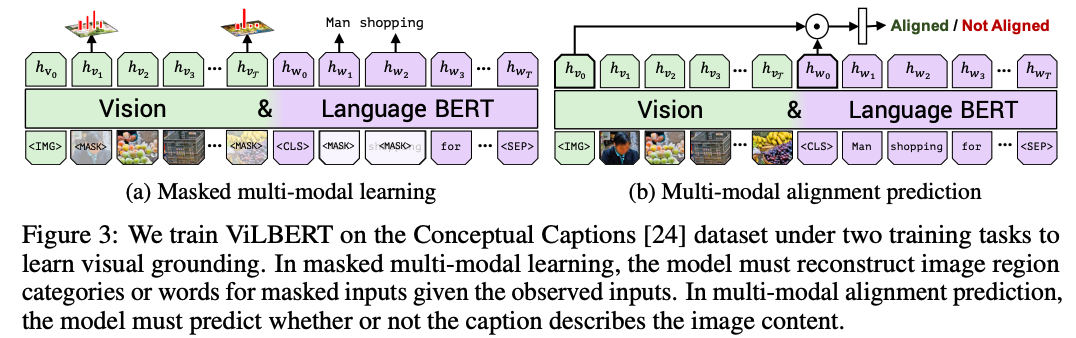
Masked multi-modal modelling
- input: BERT 훈련할 때 사용했던 masking 방법이랑 완전 똑같음! image, text 둘다 대략 15% 정도 masking
- output: 나머지 input 정보들로 masking된거 맞추기
- 단, 이미지는 image region 자체를 복원하는 게 아니라 sementic 카테고리 맞추기로!
-
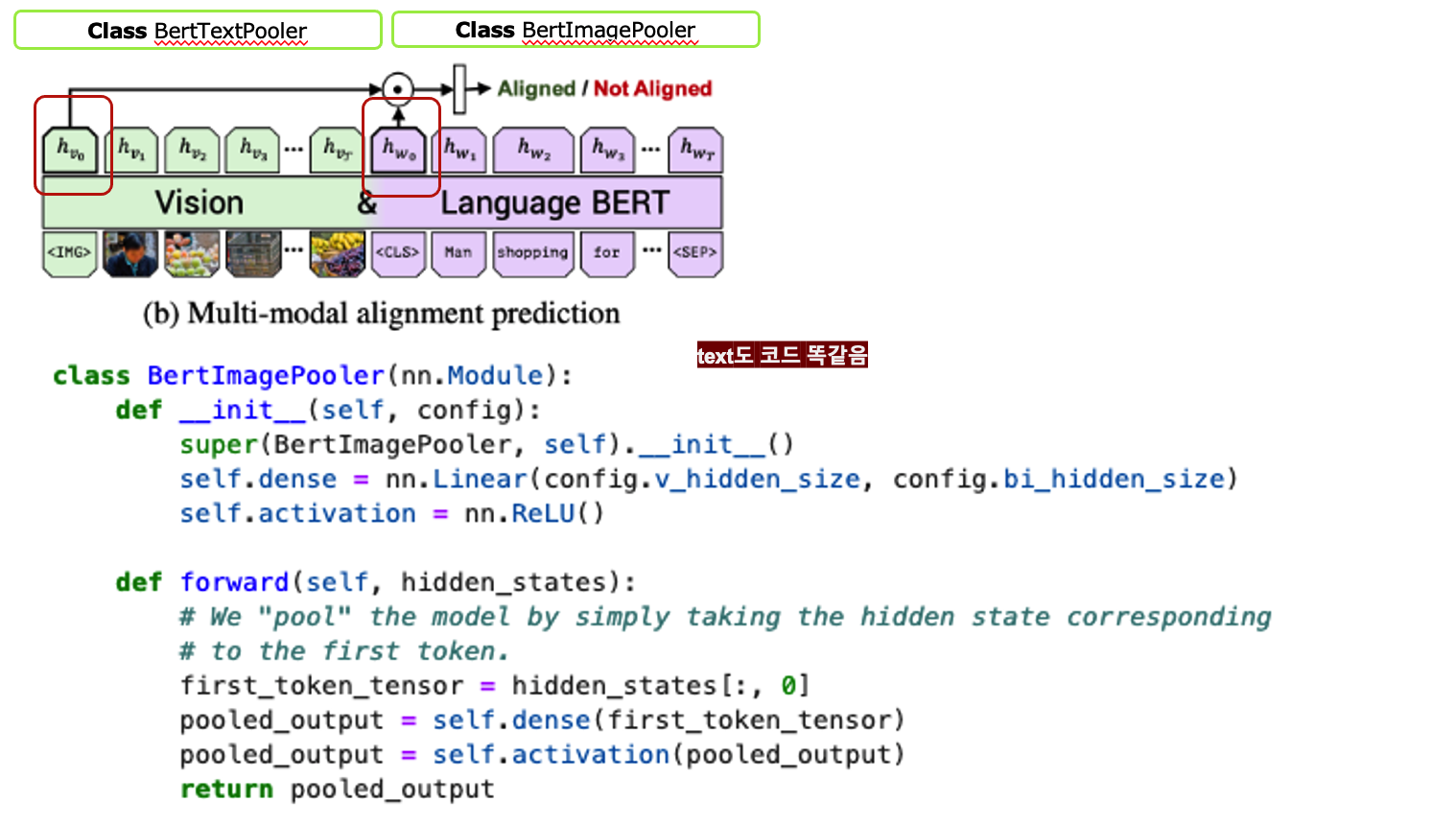
Multi-modal alignment prediction
- input: image-text sequence pair
- output: image-text aligned or not (text가 이미지를 잘 설명하냐?)
- [img]토큰, [cls]토큰 representation을 element-wise product하고, linear layer 통과시켜서 binary prediction 진행
- Conceptual Captions dataset에서 random하게 image, caption 골라서 negative 셋 만들었음.
Experimental Settings
Training ViLBERT
- linguistic stream 초기화 : BERT base
- vision stream 초기화 : Faster R-CNN to extract region features
Vision-and-Language Transfer Tasks
- Visual Question Answering (VQA)
- Visual Commonsense Reasoning (VCR): 정답의 근거까지
- Grounding Referring Expressions: 글만 보고 그림에서 어디에 해당하는지 bounding box맞추기
- Caption-Based Image Retrieval: caption보고 어떤 이미지를 설명하는지 맞추기
- 'Zero-shot' Caption-Based Image Retrieval: fine-tuning 없이 caption보고 어떤 이미지를 설명하는지 맞추기
Results and Analysis
Baselines
- Ablative baselines: two-stream으로 안하고 하나의 BERT 모델에 vision, language 모두 때려 밖아! (single-stream)
- Task-Specific Baselines: 각 Task별로 Sota 모델들
Results
- 1) two-stream > single-stream: (table1 하단 single vs vilbert)
- 2) Our pretraining tasks good: (table1 하단 십자가 vs non 십자가)
- 3) Finetuning from ViLBERT good : (table 1 상단 vs 하단)
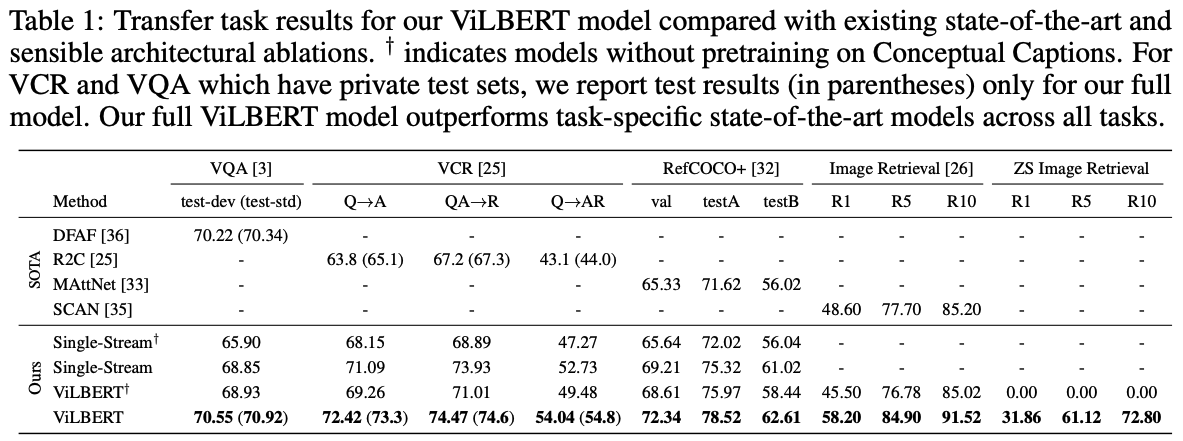
Analysis
- Effect of Visual Stream Depth
- task 별로 효과적인 layer 수가 각기 달랐다. (오호 이건 참 신기하네!)
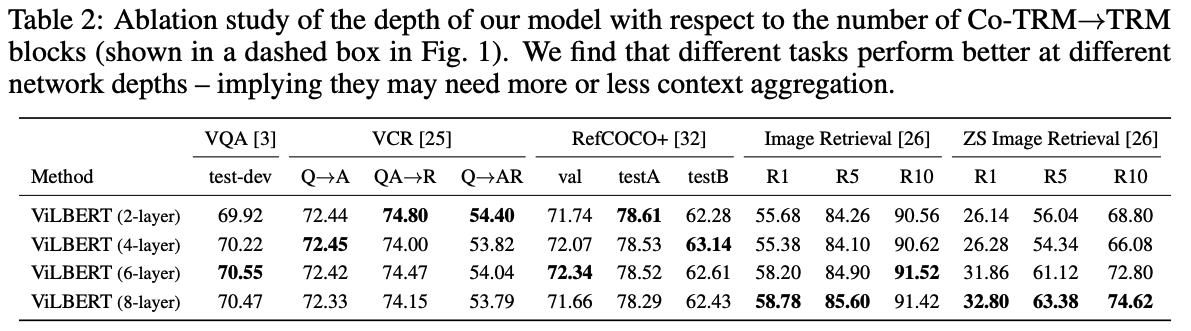
- task 별로 효과적인 layer 수가 각기 달랐다. (오호 이건 참 신기하네!)
- Benefits of Large Training Sets
- 모든 Task가 트레이닝 수가 클수록 성능이 좋았다.
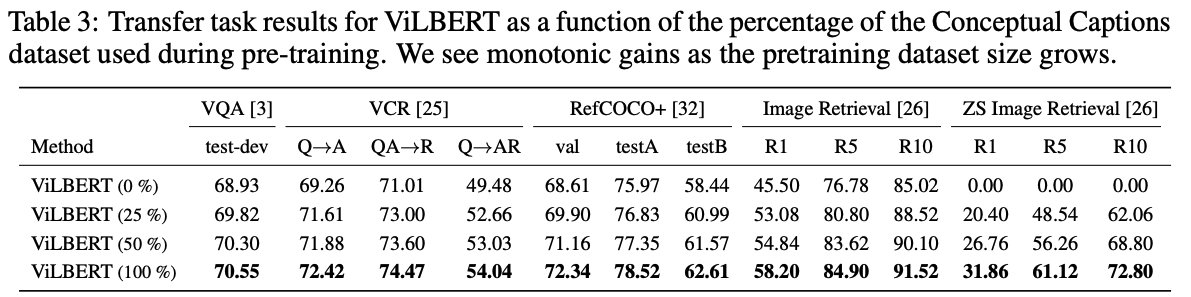
- 모든 Task가 트레이닝 수가 클수록 성능이 좋았다.
- What does ViLBERT learn during pretraining?
- zero-shot setting에서 ViLBERT가 어떻게 돌아가는지 qualitative하게 살펴봄 (table 1 맨 오른쪽 아래)

- zero-shot setting에서 ViLBERT가 어떻게 돌아가는지 qualitative하게 살펴봄 (table 1 맨 오른쪽 아래)
Related Work
- Recent works on Vision-And-Language pre-training
- 이 논문이 arxiv에 먼저 나와서 비슷한 시기에 비슷한 연구들이 좀 있음.
=> 각각 어떤 논문인가 대충보려고 했는데 코드 리뷰하다가 지쳐서 포기함ㅎㅎ
- LXMERT: in-domain dataset (i.e. COCO, Visual Genome)을 사용해 pre-training함
- VisualBERT: BERT 그대로 extend한 구조 사용, out-of-domain, in-domain 데이터셋 모두 사용, language만 MLM pre-traing
- Unicoder: image caption retrieval task에 초점.
- VLBERT
- Unified VLP
- UNITER
- 이 논문이 arxiv에 먼저 나와서 비슷한 시기에 비슷한 연구들이 좀 있음.
Conclusion
- novel two-stream architecture with co-TRM 소개
- 두 가지 pre-training 방식 사용
- SOTA 달성
Code Review
혹시나 github의 코드로 공부 하려는 사람들을 위해서 구조 파악할 수 있게 큰 거에서 작은 거로 & 파일, 클래스 명 등을 기준으로 설명해보겠음..! 코드 개 많고, 쓸떼없이 class 너무 많고!! 짜증남..!!!!
https://github.com/facebookresearch/vilbert-multi-task
def main()
pretrain, finetuning을 어떻게 하나 봅시다!
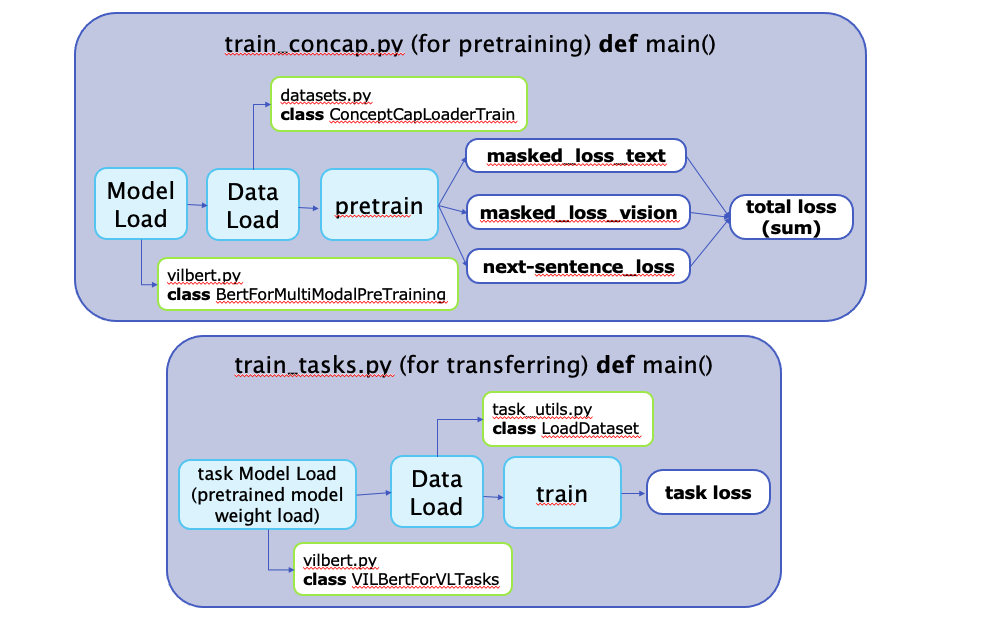
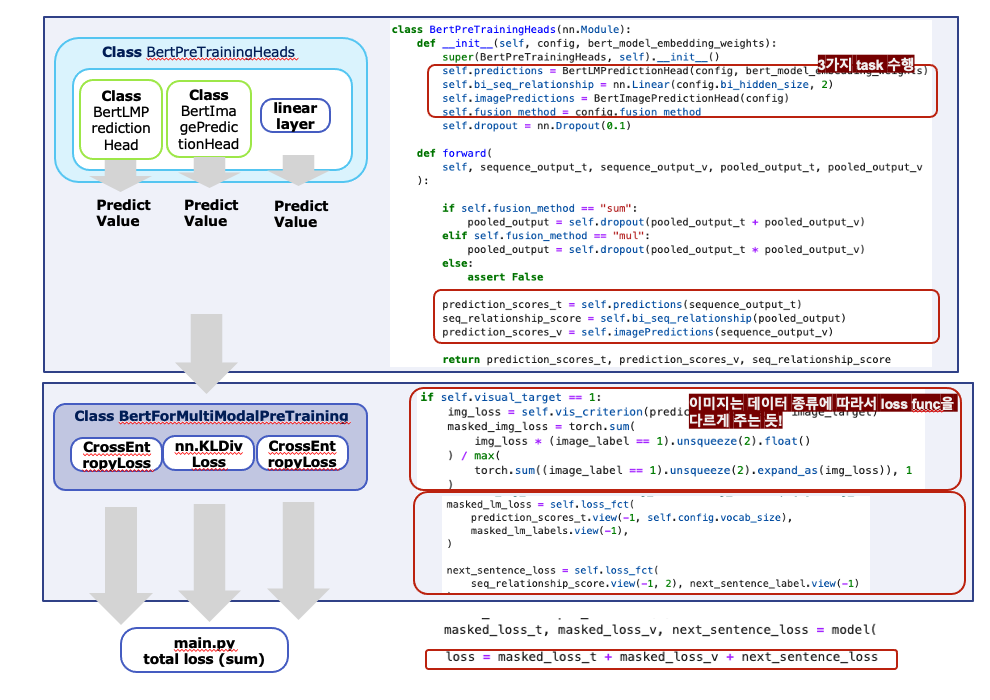
pretraining
위 그림에서 3개 loss가 나오는 과정!
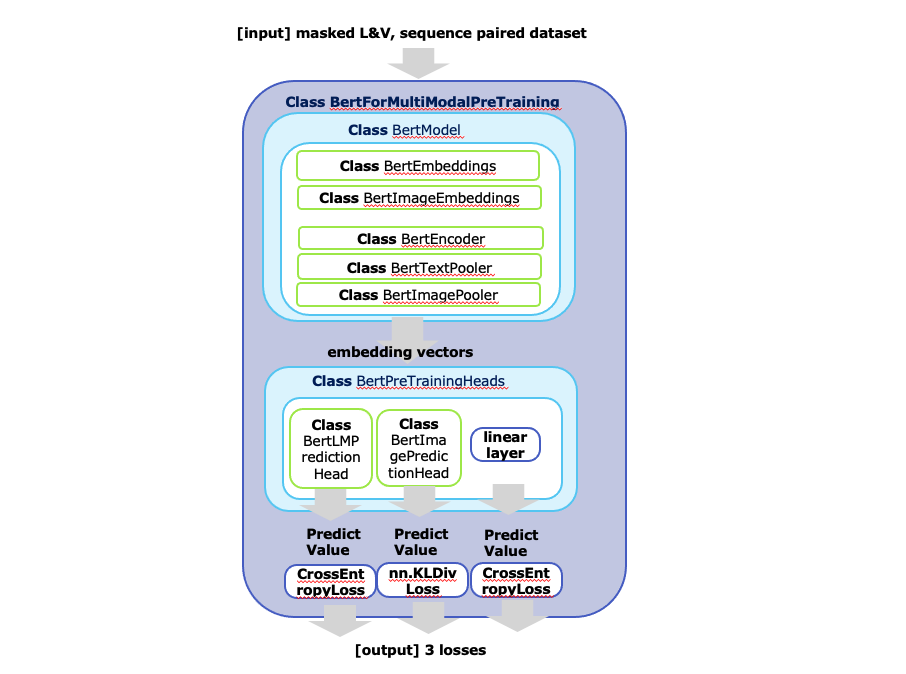
[detail] Class BertModel
-
이미지와 텍스트에서 임베딩을 뽑습니다
-
Class BertEncoder에서는 co-TRM을 수행합니다
-
임베딩 나온걸 task에 사용하도록 pooling해줍니다. (이 과정에서 나온 feature는 alignment에서만 씀)
-
최종 로스 구하기
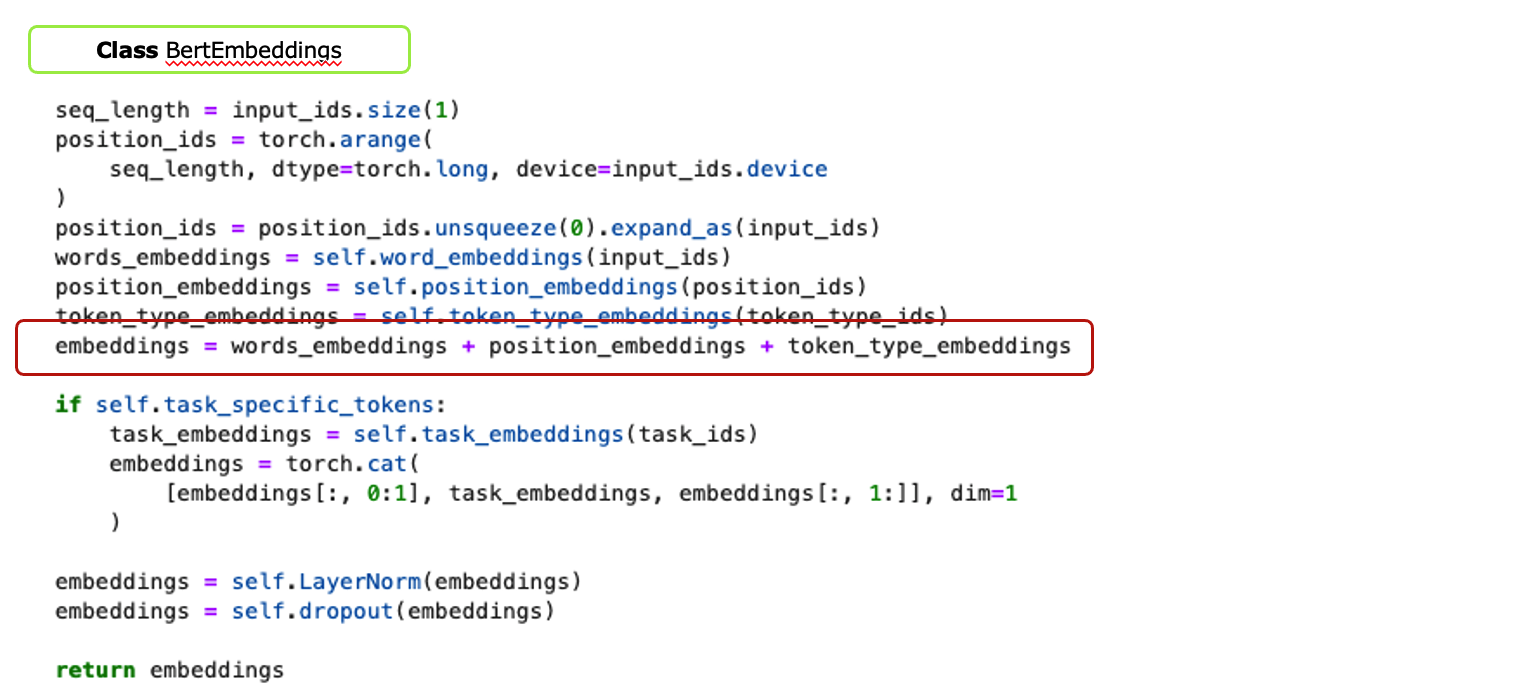


downstream task 수행

What if I'm a reviewer of this paper?
-
strength
- 최초의 모델이라는 것이 중허겠지?! 아주 간단한 방식만으로 최고의 효율을 냈다! 너무 멋지다! 나도 이런거 개발해보고 싶다 ㅠ_ㅠ
- visiolinguistic 에서도 pretrained이 가능하다는 것을 확인했다.
=> 이 부분에서 많은 후속연구를 해볼 수 있을 것 같다. - task 별로 효과적인 구조가 다르다는 게 인상적이다.
- 코드 겁나 정성스럽게 만들어놨네 ^*^
-
weakness
- Table notation이 제대로 안되어 있음
- co-TRM을 제안했으면 이것에 대한 ablation도 있어야하는 거 아닌가??

3개의 댓글

코드 부분을 어떻게 보고 이해하면 좋을지 알려주신 점이 너무 좋았습니다.
다은님처럼 객체들을 직접 시각화해서 구조를 파악해서 이해한 적이 없었는데 정말 좋은 방법인 것 같습니다!! 짱!!
그리고 저도 본문에 나와 있는 부분들을 모두 꼼꼼하게 다 읽고 확인하는 습관을 들이도록 하겠습니다~!

흔히 pretraining + fine-tuning 기법은 NLP의 전유물이라고 생각할 수 있는데,
이런 vision-language pretrained model들이 2019년부터 많이 연구되었네요 !
관련된 다른 모델들 (VisualBERT, LXMERT, Unicoder-VL, ...)과는 어떤 차이가 있는지 궁금해졌어요 ~
잘 읽었습니다!