[Multimodal #2] Found in Translation: Learning Robust Joint Representations by Cyclic Translations between Modalities (AAAI, 19)
Multimodal
한줄 요약: sentiment analysis를 할 건데, 하나의 모달만을 가지고도 여러개의 모달 정보를 담은 것 만큼의 효과를 내보자!! 그럼 test할 때 모달 하나만 있어도 된다!!
# Seq2seq # Cyclic translation loss
Paper: https://ojs.aaai.org/index.php/AAAI/article/view/4666 (main)
Paper supplementary 있는 곳: https://arxiv.org/pdf/1812.07809.pdf
Github: https://github.com/hainow/MCTN
# Introduction
[Backgound]
-
Multimodal Sentiment Analysis
- 기존에는 주로 text만을 사용해서 sentiment analysis가 이루어져 왔음.
- 하지만! nonverbal (비언어적) 신호 역시 매우 중요한 법인데, text만을 사용하면 spoken opinion에서 정보를 충분히 뽑아내는 게 한계가 있음.
- 그래서 visual이나 acoustic 같은 모달을 사용해서 부가적인 정보를 얻으려는 시도들이 생겨났음! 그것인 바로 multimodal sentiment analysis!
- Sentiment Analysis : Identifying a speaker's opinion
 https://intellectdata.com/sentiment-analysis-flip-the-customer-negatives-to-positives/
https://intellectdata.com/sentiment-analysis-flip-the-customer-negatives-to-positives/
- Sentiment Analysis : Identifying a speaker's opinion
-
Learning Joint Representation of multiple modalities
- Challenge: Learning discriminative joint multimodal representations using multiple modalities as input.
- 다양한 multimodal benchmark dataset: CMU-MOSI, ICT-MMMO
CMU MultiComp Lab실에서 나온 데이터들이구먼? (Multimodal + Healthcare 연구 多)

[Limitation of Previous works]
- Test time에서 모든 modal을 요구한다!
=> 보통 우리가 train할 때 두 가지 모달 데이터를 사용해서 학습시켰다면, 당연히 test할 때도 그 형태를 갖춘 데이터를 요구하기 마련인데!! 여기서는 이를 한계점으로 지적함 ㅇ_ㅇ 꺄울!!! 신.기.해!!
[New Approach]
- 1) 모달리티 간에 translation을 적용해보는 거야! 그럼 한 개의 Source 모달 S만 있으면 Target 모달 T를 만들 수 있지 않을까? ( => Seq2seq)
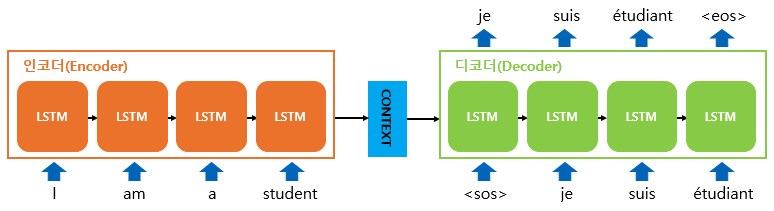
- 2) Translation 모델을 잘 학습시켜놓으면 나중에 source modal 정보만 넣어도 encoder가 뽑아낸 정보 자체가 joint information을 뽑는 거라고 할 수 있으니까 걔를 사용하면 되지 않을까???? (=> Cyclic translation loss)
[Method]
-
Multomodal Cyclic Translation Network Model (MCTN)
-
Goal: Source modal만을 가지고 maximal information을 담고있는 joint representation을 만들어서 test를 할 수 있도록 해보자!
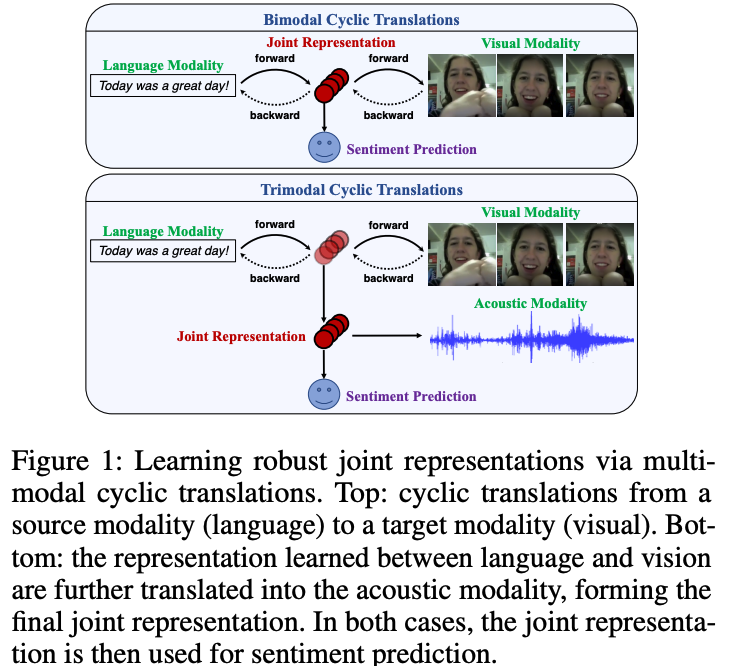
-
point 1: Seq2seq 사용해서 source 모달만 사용 가능할 수 있도록!
- forward translations from S to T (multiple target modalities도 가능!)
- backward translations from T to S
-
point 2: A cyclic translation loss 사용해서 두 모달간의 tranlation을 완벽하게 해보자!! - 총 두개의 loss 사용 (뒤에서 자세히 다시 설명하겠음!)
- (1) A cyclic translation loss
- (2) A prediction loss for task-specific
-
[Results]
- MCTN achieves new SOTA on multimodal sentiment analysis using the CMU-MOSI, ICT-MMMO.
- MCTN learns increasingly discriminative joint representations with more input modalities during training.
[Contribution]
- MCTN is robust to test time perturbations (=test 시 생긴 작은 변화) or missing information on other modalities.
- MCTN is requred only data from the source modality at tst time to infer the joint representation and label.
# Related Work
기존 연구에서 비슷한 연구가 있었던 건 아니라서 한계점을 극복한 건 아니고, 찐 새로운 방식을 제안한 듯!!
그래서 밑에 내용은 어디서 idea를 얻었는지로 생각하면 될 듯!
[Multimodal Sentiment Analysis]
: 하고자 하는 task
- 이러한 연구들이 있었다.
- (Kaushik et al, 2013)
- (Wollmer et al, 2013)
- (Kaushik et al, 2013)
- 저자들의 사전 수행 연구
각 모달에서 나온걸 seq2seq 모델들에 계속 넣어서 예측했네
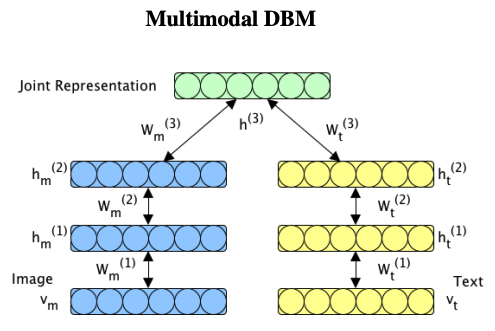
[Learning Joint Representation of multiple modalities]
: 영감을 받은 연구들! 특히 3)4)번
; multimodal sentiment analysis의 main challenge는 아무래도 joint representation learning이겠쥬?
-
1) fusion e.g. concatenation
- https://asidefine.tistory.com/203 잘 설명되어 있음!
-
2) Supervised approaches - Neural Network
-
3) Generative approaches
-
4) Translation
다은 의문점
논문 상에는 learn to translate one madality to another 이라는 문장이 있는데, 릴워에 써있는 어떠한 논문을 찾아봐도 translation하는 것 없다! 왤까! 그냥 generate한 걸 가지고 translation했다고 말한 걸까? STT, TTS처럼 transform하는 건 많잖아?! 그럼 그걸 릴워에 썼어야하는 건 아닌가..?!?! => 뒤까지 다 읽어보니 충분히 비슷한 맥락인 듯 하다!- Style Transfer
- TTS
- Or.. Image to Text (eg. image captioning)
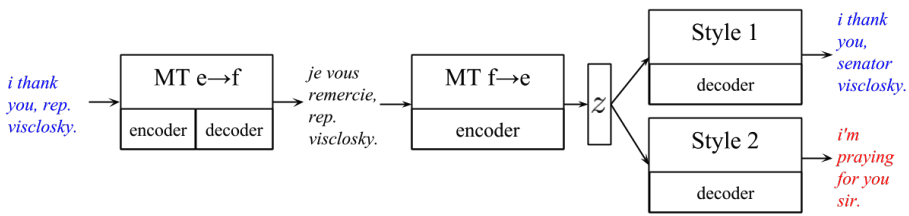
- Style Transfer
[Noisy or missing modalities at test time]
-
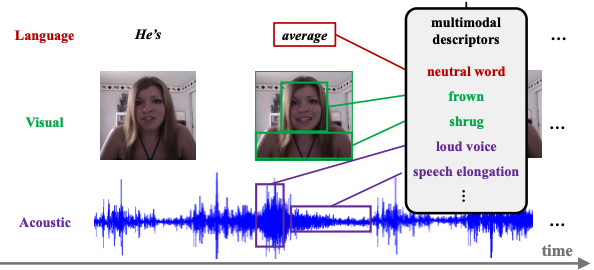
1) to infer the missing modalities by modeling the probabilistic relationships among different modalities
그냥 하나가 부족한 부분이 있으니까, 다른 모달들 정보 잘 활용해서 부족한 부분 메꿔보겠다! 이거구먼?
-
2) Training with modalities dropped at random can imporve the robustness of joint representations
이미지, text 같이 학습한 모델을 가지고 embedding 뽑아서 visual representaion 만든다.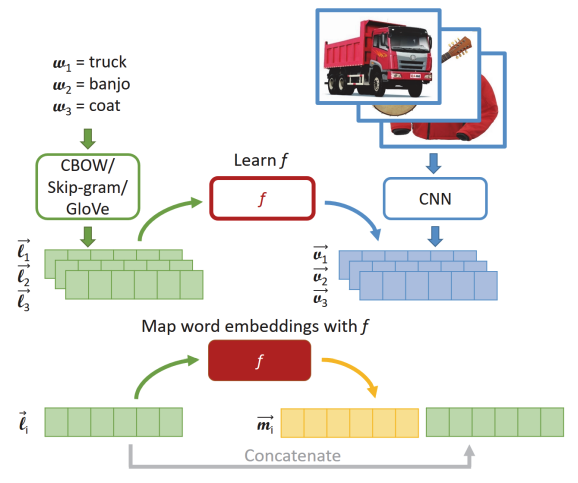
=> 위의 방법들은 prediction 하기 전에 missing된 정보를 infer하겠다는 거고, 본 연구에서는 이미 missing되어있고, perturbed된 모달리티여도 테스트할 때 잘 사용할 수 있다는 걸 보여줌!
# Proposed Approach
[Notation]
- X = (language, visual, acoustic) 수식쓰기 귀찮아서.. 손글씨로..

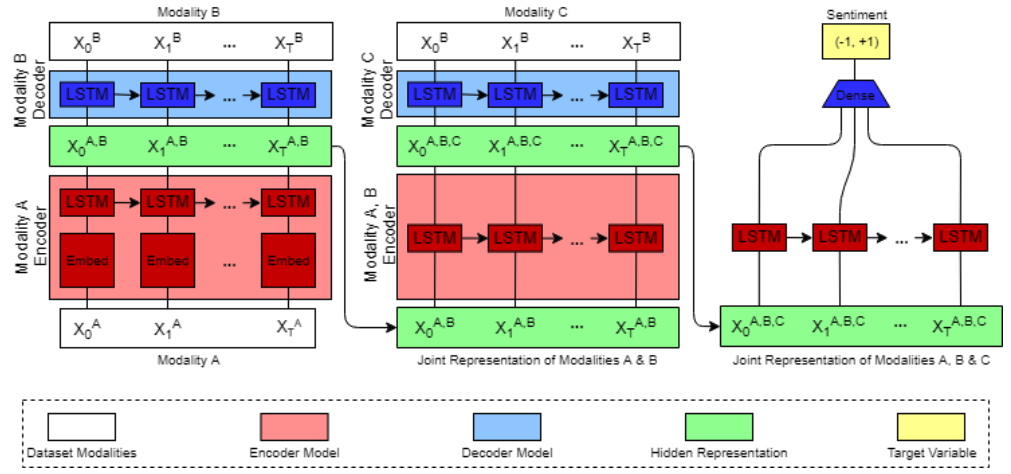
Multimodal Language Analysis with Recurrent Multistage Fusion (EMNLP, 2018)
- 보통은 length (L)로 쓰지 않고 t라고 쓴다고 함. 각 word를 말하는 게 끝나는 시점을 기준으로 chunking을 한다고 함!!
[Problem formulation]
-
Traing (Tr)
- S,T 모달을 f에 넣어서 embedding을 뽑은 후 g에 넣어서 sentiment label을 얻습니다.
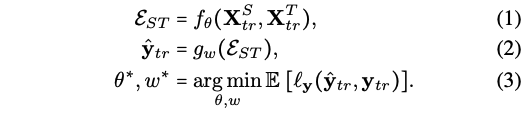
- S,T 모달을 f에 넣어서 embedding을 뽑은 후 g에 넣어서 sentiment label을 얻습니다.
-
Testing (Te)
- test 때는 source 모달을 이용해서 target 모달 만듦!
- 그럼 그 S,T가지고 똑같이 f에 넣어서 임베딩 뽑고, g에 넣어서 label 예측!
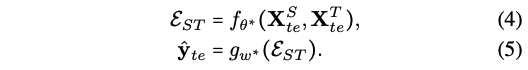
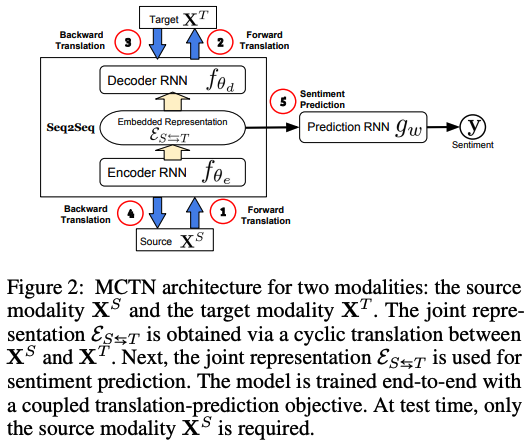
[Multimodal Cyclic Translation Network]
-
Cycle consistency loss
일단 이 모델이 요구하는 input, output들을 알려면 Cycle consistency loss부터 알아야 함!CycleGAN
Cycle-GAN은 pair-image를 사용하지 않고 X 도메인 데이터세트와 Y 도메인 데이터세트만을 이용해 두 도메인 간에 이미지를 변환하는 법을 학습

Cycle consistency loss
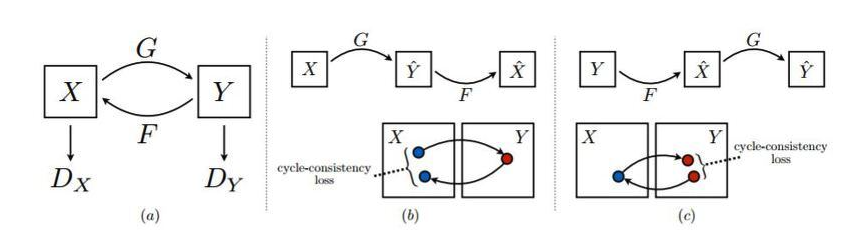
- (a) cycle consistency: Y= G(X), X= F(Y)일 때, X = F(G(X))
- 이게 가능하면 X만 있어도 Y의 정보를 충분히 유추할 수 있음! (우리로 따지면 text만 가지고 audio 정보까지 알아버리는 거임!)
- 하지만 두 함수의 학습 정도가 다를 수 있어서 완전히 똑같은 원형을 생성해내는 것은 어려움 (Mode Collapse)
- (b,c) cycle-consistency loss: 완전히 같은 게 나오지 않고 약간씩 다른 게 나와버리니까 (cyclic translation이라고 하자!), 이때 생성된 것과 원본의 차이를 최소한으로 줄이도록 학습하는 것! 그래서 (a)처럼 A랑 B랑 완벽하게 상호작용할 수 있도록 목표로 하는 것이제.
- (b) = G(X), = F(), (c) = F(Y), = G()
<출처>
(위) https://velog.io/@sjinu/CycleGAN
(아래) https://dogfoottech.tistory.com/177- So, 이 연구에서는 총 3가지 Loss를 요구하며, 각 loss 계산을 위해선 필요한 feature들이 제각각임. 뒤에서는 각 feature들이 어떻게 만들어지는 지 확인할 수 있음!
- 1) Translation loss => 오리지널 T, traslation된 T
- 2) cycle-consistency loss => 오리지널 S, cyclic traslation된 S
- 3) Task loss => ground truth, predicted label
- (a) cycle consistency: Y= G(X), X= F(Y)일 때, X = F(G(X))
-
MCTN: Multimodal Cyclic Translation Network
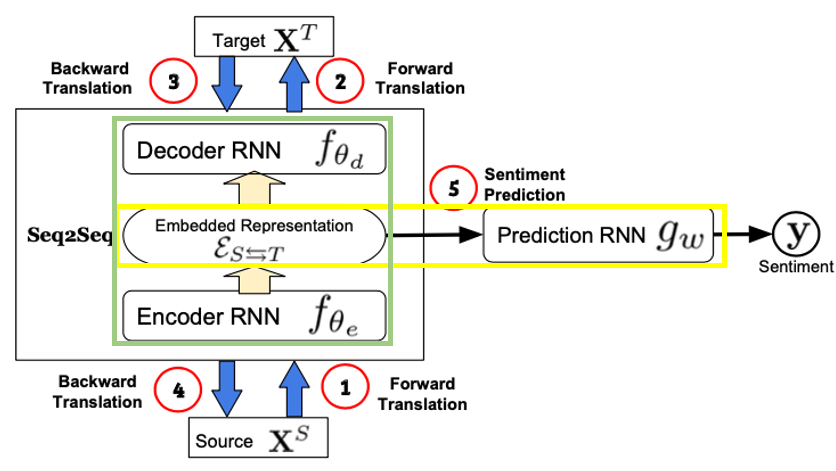
-
Translation - Seq2seq2 (초록색)
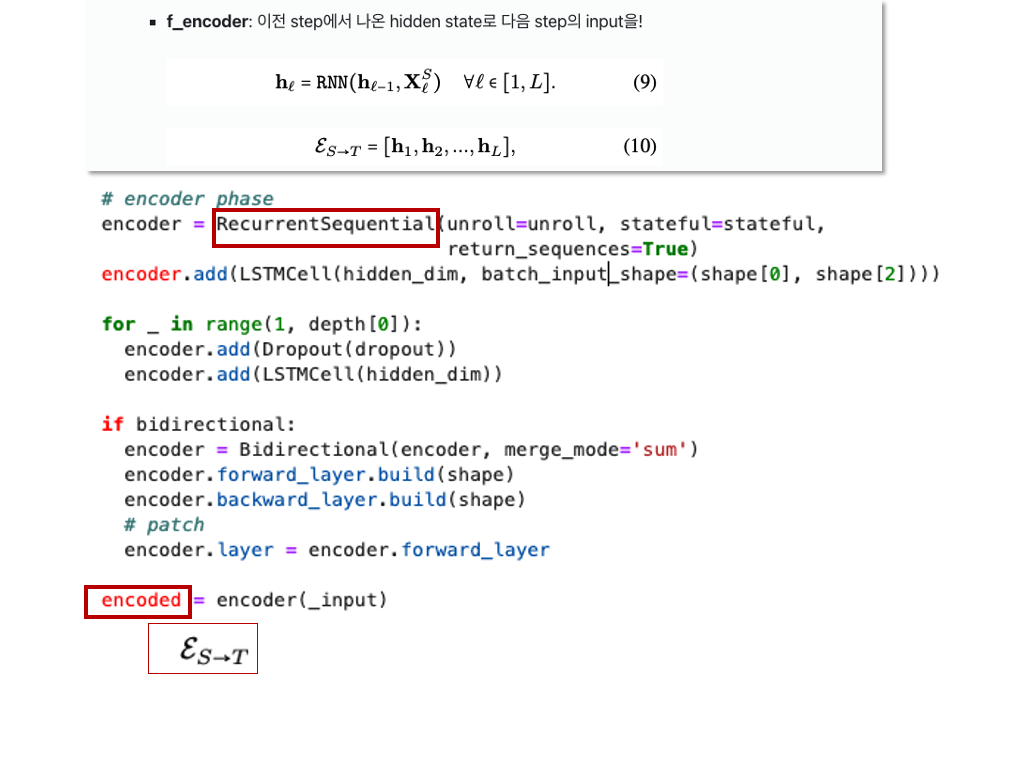
- f_encoder: 이전 step에서 나온 hidden state로 다음 step의 input을!
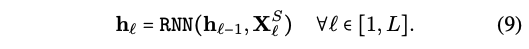
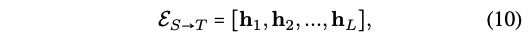
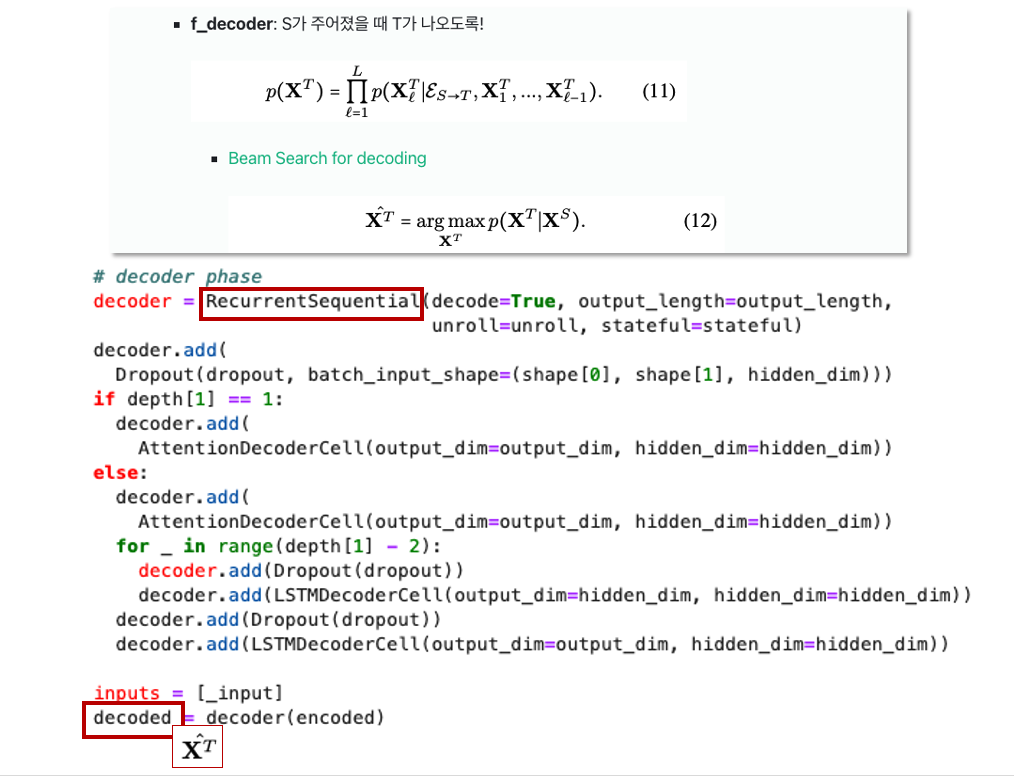
- f_decoder: S가 주어졌을 때 T가 나오도록!
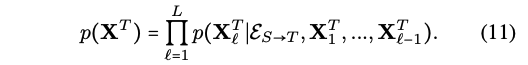
- f_encoder: 이전 step에서 나온 hidden state로 다음 step의 input을!
-
Joint representation (노랑색)
- E_ST: S를 f_encoder에 넣어서 embedding E_st를 뽑은 후, f_decoder에 넣어서 T로 transform함 (== Forward Translation, S->T)
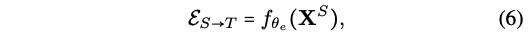
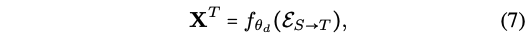
- 다은 의문점
이어야 하지 않았을까....? => 수식이 이해가 안될 땐 코드를 보자!)
- 다은 의문점
- E_TS: forward translation이랑 반대로 T를 f_encoder에 넣어서 embedding E_ts를 뽑은 후, f_decoder에 넣어서 S로 transform함 (==Back Translation,T -> S)
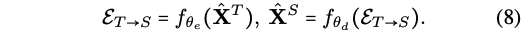
- E_ST: S를 f_encoder에 넣어서 embedding E_st를 뽑은 후, f_decoder에 넣어서 T로 transform함 (== Forward Translation, S->T)
-
Inference
- g: joint representation을 가지고 sentiment analysis 진행!
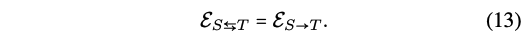
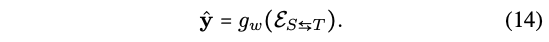
- 다은 의문점
- 논문에서는 translated representation을 쓴다고 해놓고, 수식은 E_ST로 해놓는다..? E_ST는 traslated된게 아닌데...?? 가 아닐까...??? => 코드를 보자!!!
- 아니다! 논문이 맞다! 이제 이해가 된다!
- 여기서 관건은 우리가 source modal만 사용하고서도 target modal의 정보까지 모두 다 잘 담고 있는 표현벡터를 뽑는 것이 핵심인 것이지!!!! 그래서 CycleGAN에서처럼 전혀 다른 category의 데이터를 넣어도 색다른 영역의 이미지를 만들어 내는 것 처럼! translation을 잘 학습을 해놓으면 encoder가 input을 받아서 내놓는 embedding이 결국엔 target이 되는거잖아?? 그래서 그 embedding안에는 source와 target 정보를 모두 잘 반영한 애라고 할 수 있는거지!!!!!!
- 논문에서는 translated representation을 쓴다고 해놓고, 수식은 E_ST로 해놓는다..? E_ST는 traslated된게 아닌데...?? 가 아닐까...??? => 코드를 보자!!!
또다른 의문점: 그럼 그냥 만들어진 그 모달의 정보도 추가로 넣으면 안되는것? 그냥 똑같은 내용 두번 넣는게 되는 것?
- g: joint representation을 가지고 sentiment analysis 진행!
-
-
Coupled Translation-Prediction Objective
총 3개의 loss를 가지고 전체 로스를 구한다!- 1) Translation loss : Mean Sqared Error (MSE)
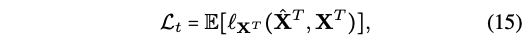
- 2) cycle-consistency loss : Mean Sqared Error (MSE)
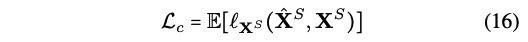
- 3) Task loss :
- Mean Absolute Error (MAE) for CMU-MOSI (sentiment in the range [-3,3])
- Cross Entropy loss for ICT-MMMO, YouTube
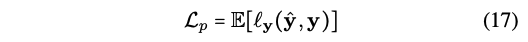
- 4) Coupled Translation-Prediction Objective
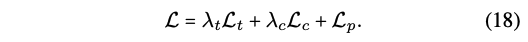
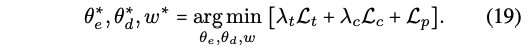
- 1) Translation loss : Mean Sqared Error (MSE)
-
Test Time
- trained된 encoder에 S만 넣으면 된다구요~
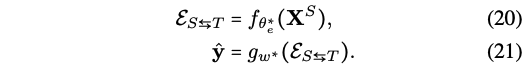
- trained된 encoder에 S만 넣으면 된다구요~
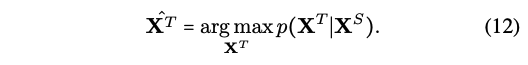
[Hierarchical MCTN for Three Modalities]
모달이 3개일 때도 가능! 모달이 3개 => , ,

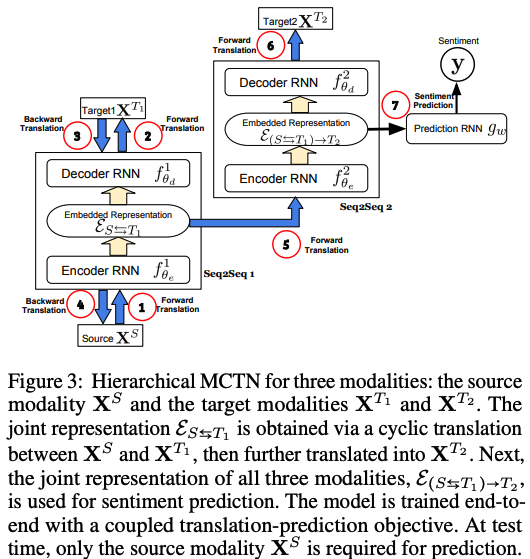
- Two level of modality translations
- 1) E_S_T1
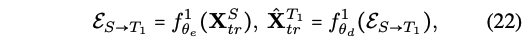
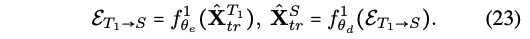
- 2) E_(S,T1)_T2
두번째에서는 cyclic을 안하고 바로 임베딩 사용하는 구먼!
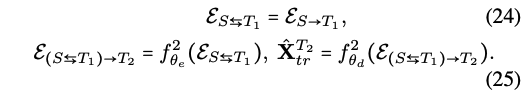
- 1) E_S_T1
- Objective for hierarchical MCTN
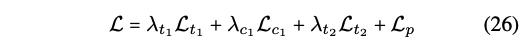
# Experimental Setup
[Dataset and Input Modalities]
- CMU-MOSI: 2199 video segments each with a sentiment label in the range [−3, +3]
- train: 52 segments/ valid: 10 /test: 31 (기존 base연구와 같은 setting)
- ICT-MMMO: online review videos annotated for sentiment
- YouTube: online review videos annotated for sentiment
[Multimodal Features and Alignmnet]
- Features
- Language: GloVe
- Visual: Facet
- Acoustic : COVAREP
- Alignment
- P2FA to obtain spoken word utterance times
- 각 단어의 발화 간격 평균 계산해서 visual이랑 acoustic alignment함 (이건 코드를 더 봐야 알 것 같음.)
[Evaluation Metrics]
- CMU-MOSI
- label이 range로 되어있어서 Mean Absolute Error (MAE) 사용!
- 그런데, sentiment classification을 해서 Acc랑 F1을 report 함
- 다은 의문점
range로 되어있는데, 어떻게 F1을 구한 걸까?? category를 만든건가?
- 다은 의문점
- ICT-MMMO, YouTube
- Categorical Cross-entropy loss
- Acc, F1
[Baseline Models]
- Multimodal models
- RMFN: multistage approach to learn hierarchical representations (CMU-MOSI SOTA 모델)
- LMF
- TFN
- MFN
- EF-LSTM
# Results and Discussion
[Comparison with Existing Work]
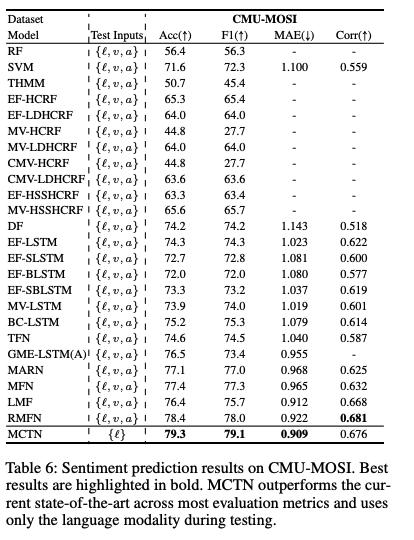
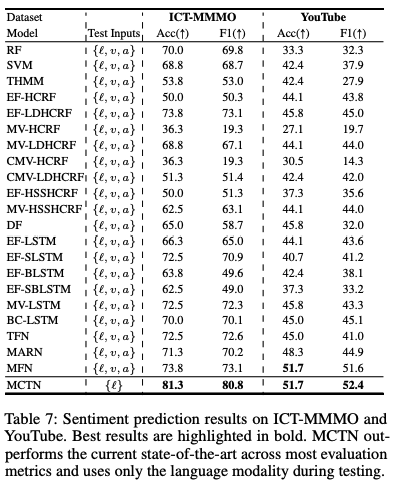
- Q1: How does MCTN compare with existing state-of-the-art approaching for multimodal sentiment analysis?
- MCTN 이 세개의 benchmark에서 SOTA를 달성함!
- 여기서 중요한 것은! MCTN only uses language during testing, while other baselines use all three modalities.
[Adding More Modalities]
- Q2: What is the impact of increasing the number of modalities during training for MCTN with cyclic translations?
- modal 많아질 수록 성능이 좋아진다.
- 이는 모델에서 나온 representation이 진짜로 여러 모달들의 정보를 활용한다는 뜻 아니겠는가??? 진짜로 source만 있어도 joint representation 잘 뽑히고 있다!
- Language가 Source일 때 항상 성능이 제일 좋았다.
- 기존 연구 결과와 일맥상통; language modality contains the most discriminative information for sentiment
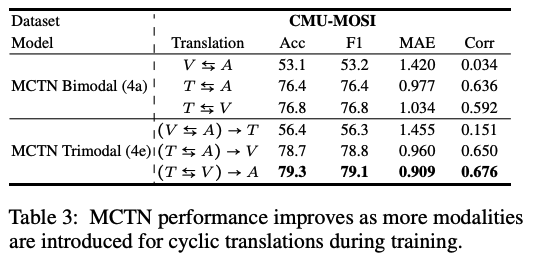
- 기존 연구 결과와 일맥상통; language modality contains the most discriminative information for sentiment
- joint representation 시각화
- 모달 갯수 많아질 수록 joint representations become increasingly separable
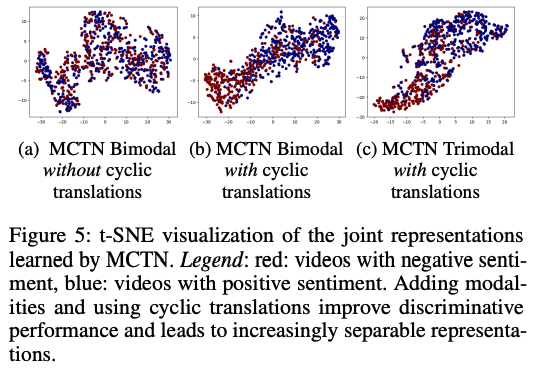
- 모달 갯수 많아질 수록 joint representations become increasingly separable
- modal 많아질 수록 성능이 좋아진다.
- Q5: What is the impact of varying source and target modalities for cyclic translations? (원래 ablation 쪽에 있었는데 여기 있는 게 맞을 것 같아서 옮김)
- Result
- Text best
- (T,V) > (T,A)
- 1차로 V,A 한 후 2차에 L 추가하니까 그렇게 도움되는 거 없었음
- Findings
- language 짱
- Result
- 다은 의문점
- V-A 간의 관계에 대해서 더 자세히 설명을 써줬다면 좋았을 것 같음.
- (b)에서 A->V 실험은 안함. 눈속임?
- a,b,c,d만 봐도 V-A 모델은 논문에서 말하고자 하는 바와 전혀 다르게 성능을 뽑아놓고 있는데, 이에 대한 설명은 성능이 떨어지더라~ 뿐임.
- V<->A보다 V->A가 성능이 더 좋다는 건 A가 안좋은 영향을 미친다는 것?
- b-(V->A)와 c-(V->A, A->V)의 성능 결과 숫자가 아예 똑같음. 실수? 혹은 A->V가 아예 영향이 없는 것??? 그래서 실험도 따로 안한 것???
[Ablation Studies]
:구조 별로 얼마나 성능에 좋은 영향을 미칠까?
-
Setting
- 1) cyclic translations, 2) modality ordering, 3) hierarchical structure (논문에는 이렇게 써 있었으나, 2번은 위로 올라가야 할 것 같고 거기에 seq2seq이 추가되면 될 듯!)
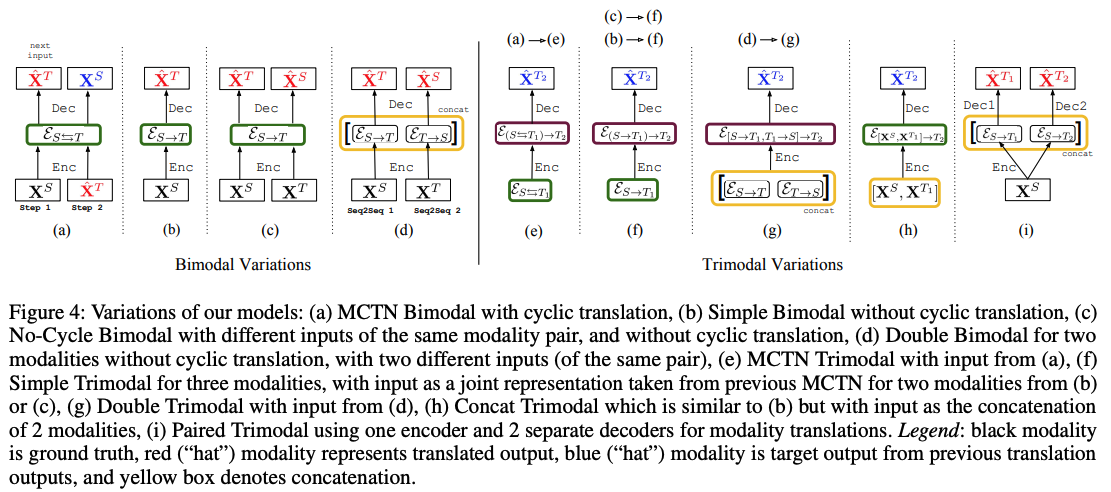
Q3- Cyclic translation Q4 - One Seq2seq Q6 - Hierarchical Bimodal (a) Target / / (b) Control / / (c) Control Target / (d) Control Control / Trimodal (e) Target / Target (f) Control Target / (g) Control Control / (h) Control / Control (i) / / / - Bimodal - (a): 기존 main 구조 - (b): \[cyclic loss X] 그냥 translation만 - (c): \[cyclic loss X] 독립적으로 S,T 둘다 translation - (d): \[cyclic loss X, encoder 2개] (c)랑 방식은 똑같은데 S,T 따로 embedding 뽑아서 concat *(이 방식 써도 test time때는 학습된 encoder만 사용하면 되니까 모달 한개로 하는 거겠지?)* - Trimodal - (e): 기존 main hierarchical 구조 - (f): \[cyclic loss X] (c) 확장 버전 (가운데에 두번 작동하는 부분은 그림 생략된듯!) - (g): \[cyclic loss X, 1차_encoder 2개] (d) 확장버전, S <-> T1 embedding 뽑아서 concat한 걸 가지고 T2 생성 - (h): \[cyclic loss X] 원래 (e)버전에서는 S <-> T1 translation 임베딩 가지고 T2를 만들지 않았음? 그런데 1차 아예 빼버리고 S,T1 raw를 바로 사용해서 T2 생성 - (i): \[cyclic loss X, decoder 2개] 원래는 S,T1 사용해서 T2를 만들었는데, 여기선 S를 가지고 T1,T2각각 만들어버림. decoder가 두개!
- 1) cyclic translations, 2) modality ordering, 3) hierarchical structure (논문에는 이렇게 써 있었으나, 2번은 위로 올라가야 할 것 같고 거기에 seq2seq이 추가되면 될 듯!)
-
Result Tables
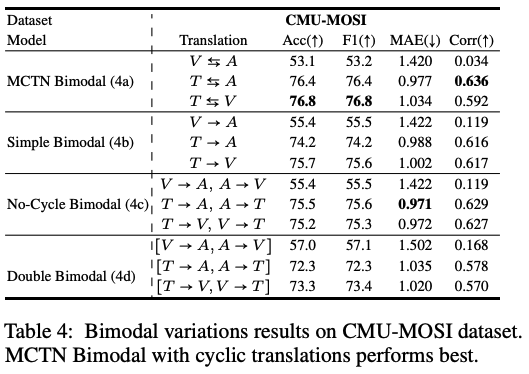
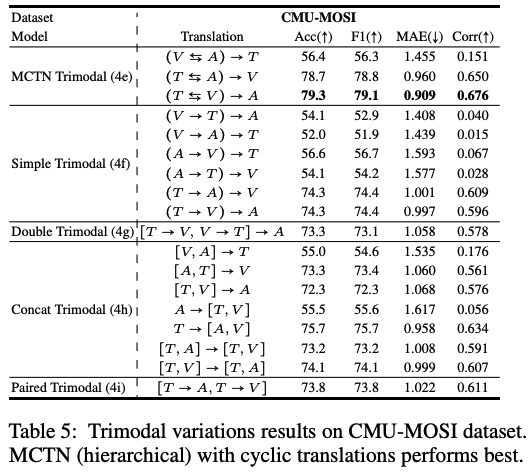
-
Q3: What is the impact of cyclic translations in MCTN?
- Result
- (a) > (b,c,d)
- (e) > (f,g,h)
- Findings
- cyclic translations는 joint representation 만들 때 중요!
=> 모델이 S와 T를 대칭 (symmetry)을 이룰 수 있도록 해줌
=> 모든 모달들의 정보를 최대한 포함할 수 있도록 해줌- 다은 의문점
모든 부분에서 최고점을 낸 것은 아닌데..? 왜 그냥 없는 애들 취급하는 거야... ㅋㅋ
- 다은 의문점
- cyclic translations는 joint representation 만들 때 중요!
- Result
-
Q4: What is the effect of using two Seq2Seq models instead of one shared Seq2Seq model for cyclic translations?
- Result
- (c) > (d)
- (f) > (g)
- Findings
- 두 개의 모델을 학습시키려면 많은 데이터를 필요로하고, overfitting되기 쉬웠던 거 아닐까 추측
- joint된 표현 배워야하는 데 각각 해버리니까 제대로 학습을 못했을 거야.
- 다은 의문점
- (b)모델과의 해석도 있으면 좋지 않았을까. 이상적인 결과는 c>d>b임. 하지만 결과를 보면 c>b>d임. 여기서 주장하는 것은 따로 훈련해서 제대로 학습을 못했다는 것인데, 그래도 아예 학습 안한 b보다는 d가 더 좋았어야 하는 것 아닐까? 아님 아예 방해가 된다는 걸까?? 무조건 모든 정보 합치는 게 좋은 건 아니란 연구들도 있는데 그거 인용해서 요런 한마디라도 덧붙였으면 더 좋지 않았을까?
- 다은 의문점
- Result
-
Q6: What is the impact of using two levels of translations instead of one level when learning from three modalities?
- Result
- (e) > (h)
- Findings
- representation learning is easier when the task is broken down recursively
- 다은 의문점
- (e)랑 (h)가 정말 좋은 비교일까? 투 레벨이 좋다고 하면 다른 건 다 동일해야하는데, (e)의 첫번 째 레벨에는 cyclic translation이 들어가 있어서 비교가 안될 것 같은 걸? 차라리...? 2번째 단계를 빼고, 첫번째 단계 translation만 하는 게 더 낫지 않았을까??
- 다은 의문점
- representation learning is easier when the task is broken down recursively
- Result
# Conclusion
- Goal: Source modal만을 가지고 maximal information을 담고있는 joint representation을 만들어서 test를 할 수 있도록 해보자!
- Method: Multomodal Cyclic Translation Network Model (MCTN)
- seq2seq으로 단일 모달만으로 상대 모달 표현 가능하도록!
- clyclic translation loss로 모달간 interaction 극대화
- Result:
- CMU-MOSI SoTa
- 모달 많을 수록 성능 up
# Code
so sad... keras로 되어있넹..... but I can do it!
-
main.py
-
핵심 모델의 전체적인 흐름을 파악해보자!
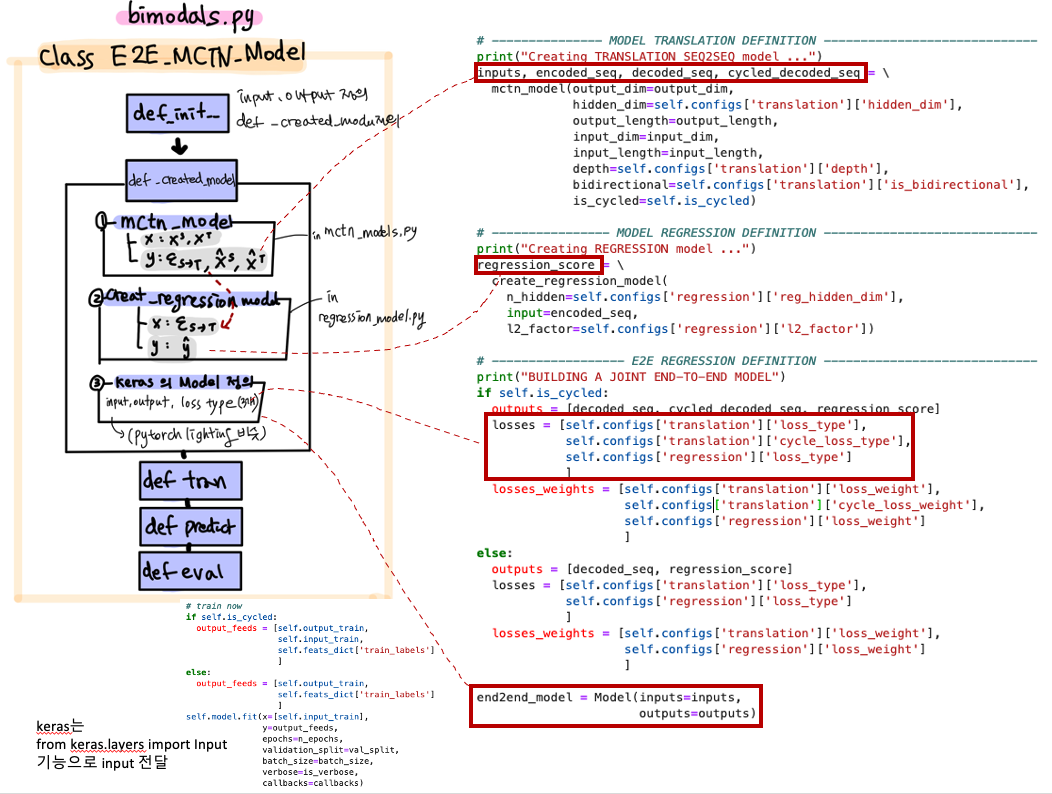
-
seq2seq 부분 (mctn_model)
-
sentiment analysis 부분 (regression_models)
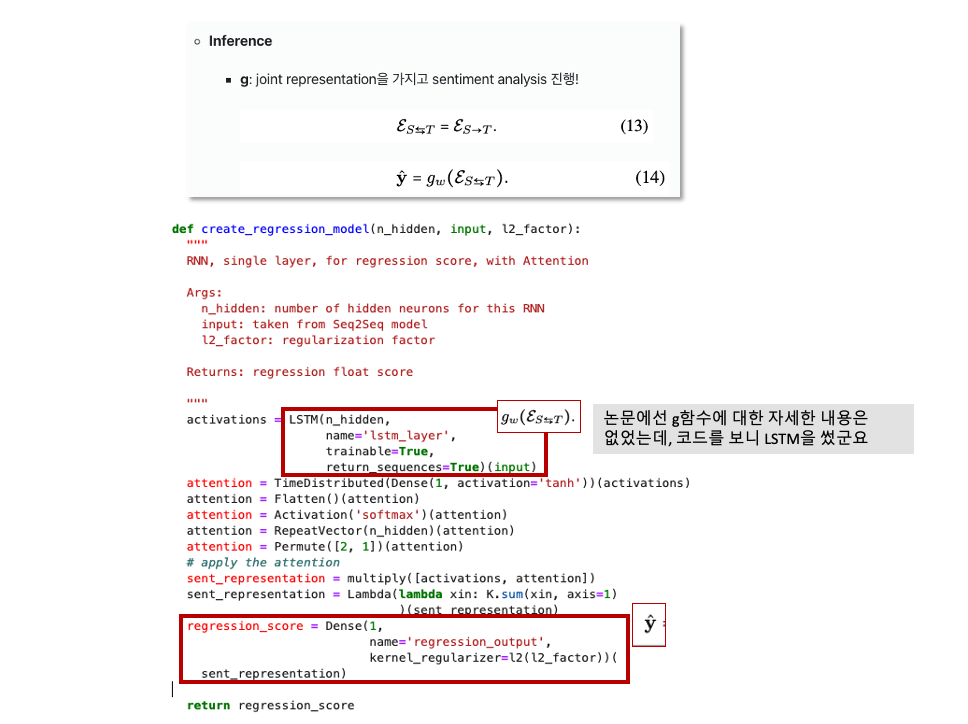
-
3개 모달일 땐?

-
loss & Test time


# What if I'm a reviewer of this paper?
- Weakness
- 글 잘못 쓴게 많다
- figure, table 번호랑 수식 잘못 씀.
- AAAI에는 suplementary도 같이 포함 안되어 있음
- ablation study에서 (i) 모델에 대한 설명은 없음. modality ordering 부분은 반복 됌
- 실험 셋팅
- ablation study 등 result에서 하고자 하는 말이 뭔지는 알 것 같은데, setting이 좀 잘못되지 않았나 싶다!
- 글 잘못 쓴게 많다
- Strength
- 부족한 부분에도 불구하고 아이디어. 린정 킹정. 아무리 논문을 잘써도 아이디어가 좋아야하는 거구나 깨달았다.
- 기존의 한계점에 대해 challenge한 것이 아니라, 새로운 한계점을 제시하였고 이를 해결하고자 한 거라고 생각한다. 사람들에게 너~ 사실~ 이거 불편했을 걸? 이렇게 하면 더 편할 걸? 하고 새로운 task를 제시했달까! good!
- 나도 논문 많이 읽고 실험 해보면서 불편한 점들을 더 찾아내야겠다.
- 코드와 수식이 일치하다.



케라스로 되어있는 코드까지 분석한 알차디 알찬 발표 감사합니다 : -) What if I'm a reviewer of this parper와 중간중간 있는 논문에 대한 해석들이 논문에 대한 이해를 더 쉽게 하는데 큰 도움이 된 것 같습니다 !!!