앞에서 word2vec 의 대표 모델로 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법인 CBOW와 중간에 있는 단어로 주변 단어들을 예측하는 방법인 Skip-Gram 가 있다. 둘의 매커니즘은 유사하며 먼저 CBOW에 대해서 알아보자
CBOW
CBOW 모델은 앞에서 언급한 window 크기 만큼 주변 단어를 체크 하면 된다.
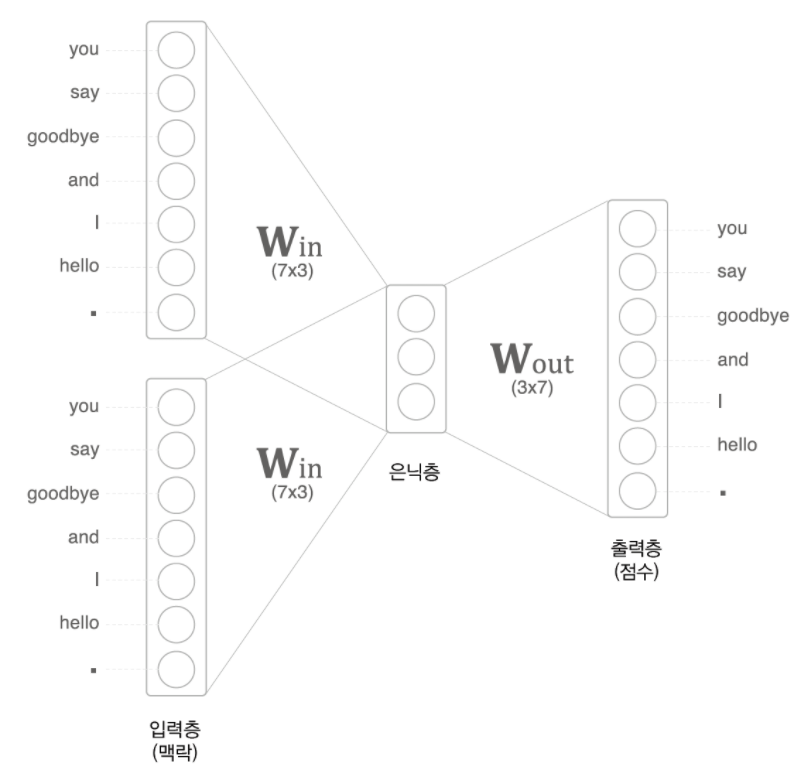
위의 예시처럼 문장이 "you say goodbye and i hello . "라고 가정해보자 현재 위의 사진은 you 가 중심문장이고 윈도우가 2인 경우에는 input 값이 say와 goodbye 2개의 벡터값이 들어가게 된다. 만약 윈도우의 크기가 2이이고 중심문장이 goodbye 이면 양쪽 좌우 2개씩 하여 input 값이 4개가 들어가게 된다.
그리고 위의 사진을 보게 되면 우리가 일상 아는 딥러닝은 은닉층에 여러개의 layer로 구성되어 있고 마지막에 비선형 함수를 넣어 학습을 하는 것으로 알고 있지만 이에 반해 word2vec는 이런 비선형 함수도 없이 벡터 계산만 하는 것을 알 수 있다. 이 처럼 word2vec에서는 일반적인 벡터 연산만 하는 은닉층을 룩업 테이블 혹은 투사층으로 부른다.
CBOW 가중치
1. 가중치의 의미
먼저 위의 그림을 보면 알 수 있듯이 7개의 단어로 입력이 들어오고 룩업 테이블에서 3개의 값으로 이루어진 것을 보아 Win의 가중치는 73 이며 단어의 분산표현이다. 반대로 나가는 가중치 Wount은 37로 이루어져 있으며 추후 softmax를 지나게 되면 출현 확률로 나오게 된다. 단순히 벡터의 크기로 보면 전치행렬 로 보일 수 있지만 이는 서로 의미하는 값이 다르 다는 것을 알 수 있다. 이 후 손실 함수는 softmax와 잘 어울리는 CEE 함수를 사용하여 학습을 진행한다.
2. 룩업 테이블의 크기
앞의 그림을 보면 알 수 있듯이 입력 층의 크기 보다 룩업테이블의 크기가 작은 것을 알 수 있다. 이 처럼 입력층의 크기보다 작아야 하는데 예측에 필요한 정보를 간결하게 담을 밀집 벡터를 얻기 위함이다.
SKip-gram
skip-gram은 중심 단어에서 주변 단어를 예측하는 방법이다.
"The fat cat sat on the mat" 라는 문장과 윈도우의 크기가 2이 이면 아래와 같이 나타 낼 수 있다.
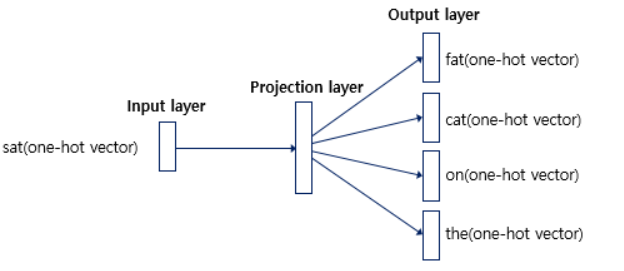
위의 사진처럼 인풋 값이 여러개인 CBOW와 달리 출력층에 윈도우 수만큼 있는 것을 확인 할 수 있다. 앞에서 CBOW는 입력층에서 평균을 구하고 결과값을 softmax와 손실함수를 통해 학습을 해나간다면 Skip-gram 은 윈도우 크기 *2 만큼 개별적으로 손실을 구하고 이 개별 손실을 모두 더한 값으로 최종 손실을 구한다.
skip-gram 과 CBOW
위의 2가지 모델을 공부하면서 각자 느끼는 바가 있을 것이다. 하나의 손실을 구하는 것이냐 혹은 여러개의 손실을 합쳐서 평균을 내는 것에서 어느 것이 더 성능이 좋을지 말이다. 단순히 생각해 보면 하나의 단어를 맞추는 것과 하나의 단어 주변 단어를 맞추는 과정에서 계산량은 후자가 더 많다는 알 것이다. 이 처럼 skip-gram 은 CBOW에 비해 더 어려운 문제에 도전하는 것을 알 수 있으며 이는 단어의 분산 표현이 더 높게 나온 다는 것을 알 수 있다.
Enbedding 과 Negative sampling
앞에 CBOW 모델에서 보면 알 수 있듯이 on-hot 벡터값들이 여러개가 들어 올수록 연산량이 많아진다는 것을 알 수 있다. 이처럼 대부분이 0이고 하나의 값만 가진 벡터의 연산을 어떻게 하면 줄일 수 있을까?
Embedding
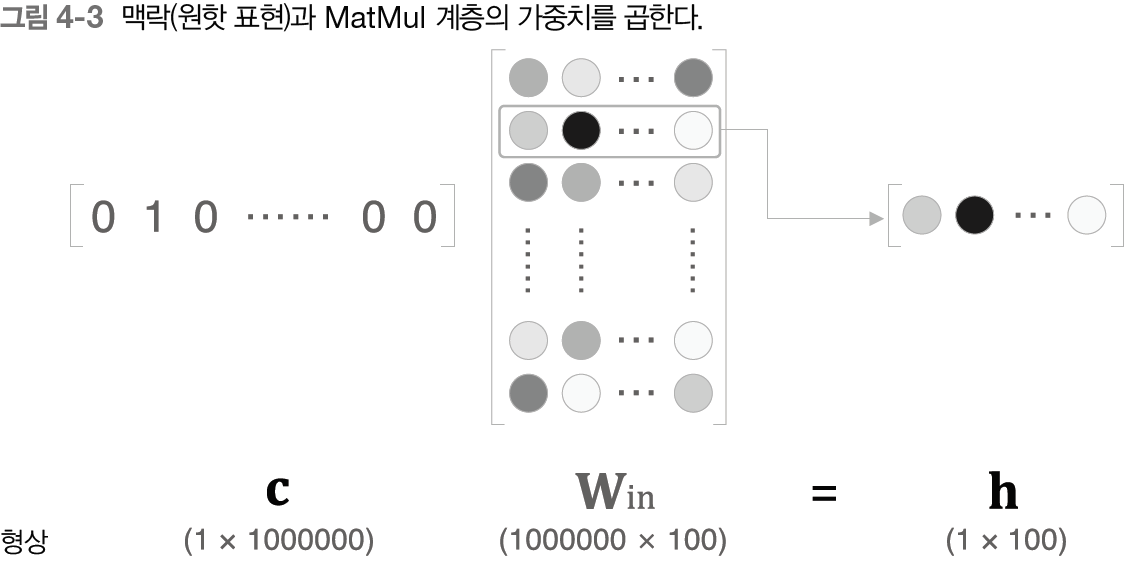
답은 단순 할 수 있다. 대부분이 0인 벡터를 연산한느 것이 아닌 Win 으로 부터 단어 index에 해당하는 부분만 추출하면 되는 것이다. 결과적으로 Embedding은 단어의 분산표현을 저장하는 즉 Win 가중치를 저장하고 원하는 index값만 보내주는 역할이라고 생각하면 편하다.
negative Sampling
Word2Vec은 역전파 과정에서 모든 단어의 임베딩 벡터값의 업데이트를 수행하지만, 만약 현재 집중하고 있는 중심 단어와 주변 단어가 '컴퓨터'와 'CPU', 'memory'과 같은 단어라면, 사실 이 단어들과 별 연관 관계가 없는 '강아지'나 '고양이'와 같은 수많은 단어의 임베딩 벡터값까지 업데이트하는 것은 연산으로 봤을 때 비효율적이다.
이처럼 네거티브 샘플링은 Word2Vec이 학습 과정에서 전체 단어 집합이 아니라 일부 단어 집합에만 집중할 수 있도록 하는 방법이다.
네거티브 샘플링은 무작위로 선택된 주변 단어가 아닌 단어들을 일부 가져온다. 이렇게 하나의 중심 단어에 대해서 전체 단어 집합보다 훨씬 작은 단어 집합을 만들어놓고 마지막 단계를 이진 분류 문제로 변환한다.
주변 단어들을 긍정, 랜덤으로 샘플링 된 단어들을 부정으로 레이블링한다면 이진 분류 문제를 위한 데이터셋이 되고 긍정 과 부정인 예에 대해 손실을 구하고 각각의 손실의 평균을 구하는 방법이다.
이는 기존의 단어 집합의 크기만큼의 선택지를 두고 다중 클래스 분류 문제를 풀던 Word2Vec보다 훨씬 연산량에서 효율적으로 결과값을 뽑아내게 될 수 있다.
그러면 어떤 단어들이 부정적인 예로 샘플링이 되는 것일까? 단순히 무작위로 가져오는 것도 좋지만 자주 등장하는 단어를 많이 뽑고 드물게 등장하는 단어에 대해 적게 추출하여 빈도수로 부터 오는 단어의 의미를 파악 할 수 있게 되는 것이다.
