
들어가기에 앞서
최근에 딥러닝 기반 추천시스템을 공부하면서 밑바닥부터 시작하는 딥러닝을 읽게 되었다. 그 중에서 자연어 처리중에 기본시 되는 word2vec를 이해하는 과정에서 단어의 의미를 파악하는 3가지 방법과 2부에서는 추론 기법인 word2vec, Embedding 과 Negative sampling 을 배워보자
자연어와 단어의 분산 표현
우선 자연어 처리의 본질은 우리의 말을 컴퓨터가 알아듣게 만드는 것이다. 하지만 컴퓨터가 이해할 수 있는 언어는 프로그래밍 언어나 마크업 언어와 같은 것이다. 이 처럼 모든 코드의 의미를 고유하게 해설할 수 있도록 문법이 정의되어 있고 정해진 규칙에 코드를 해석하게 된다. 따라서 컴퓨터가 이해할 수 있도록 단어의 의미를 학습시키는 방법에는 다음과 같은 3가지 방법이 있다.
1. 시소리스를 활용한 키법
2. 통계 기반 기법
3. 추론 기반 기법
시소리스(thesaurus)
시소리스(유의어 사전)은 통계 정보로 부터 단어를 표현하는 통계기반 기법이다. 언어학자들이 유사한 단어뜻을 가진 단어들을 모으거나 아니면 트리형식의 자손형태도 표현하기도 한다.
예를 들어 car, auto , automobile 은 자동차를 의미하는 것과 자동차의 자식으로 SUV,세단,리무진이 있는것 처럼 말이다. 따라서 이런 시소리스의 WordNet 은 단어의 의미를 간접적으로 컴퓨터에 전달할 수 있지만 이처럼 사람이 수작업으로 노동을 해야 한다는 대표적인 단점이 있다. 또 한 시대의 변화에 따라 의미가 변하는 것에 일일이 대응하기가 어렵고 단어의 미묘한 차이를 나타낼 수 없다는 한계점이 들어난다.
통계기반(corpus)
따라서 앞의 시소리스의 한계점을 극복하기 위해서 말뭉치(corpus)를 통해서 통계적으로 단어의 의미를 파악하고자 한다. 앞에서 포스팅한 mecab, nlpk 도구를 통해서 하나의 문장을 여러 개의 corpus를 표현 할 수 있다는 것을 배웠다. 이런 단어를 가지고 단어의 의미를 정확하게 표현 하기 위해 단어의 분산 표현을 하고자 한다.
분포 가설
통계기반으로 단어의 의미를 학습 한느데에는 하나의 가설을 세운다. 그것은 "단어의 의미는 주변 단어에 의해 형성된다" 라는 것이다. 예를 들어 i drink beer , we drink wine, i guzzle beer , we guzzle wine 이라는 문장에서 drink 와 guzzle 의 의미는 주변 단어들을 통해서 의미가 비슷하다는 것을 알 수 있다.
여기서 단어의 의미를 파악하기 위해서 주변 단어를 보는 정도를 window 라고 한다. 해당 단어의 주변 단어 , 즉 맥락에 포함되는 단어의 빈도를 통해서 단어의 의미를 파악해 보자.

위의 사진처럼 "you say goodbye and i hello ." 이라는 문장이 있는 경우 각 단어가 근처에 있는 횟수를 더하는 방식이다. 이 처럼 각 언어의 벡터값을 알 수 있으니 코사인 유사도 를 통해서 각 단어의 유사도를 파악 함에 따라 단어의 의미를 파악 할 수 있게 된다.
통계기반 개선하기
앞 사진을 통해 알 수 있듯이 각 행렬의 값은 해당 단어의 빈도 수를 나타낸다. 하지만 the, a 같은 관사 표현은 특정 문장에서 나오는 것이 아닌 모든 문장에서 나오기 때문에 그 의미를 파악하기가 어렵다. 예를 들어 car 와 drive 가 유사한 것을 나타냈으면 하지만 car 앞에 the , a 가 많이 붙게 되는 경우에는 the 랑 car가 더 유사하다고 나타내기 때문이다.
우리는 점별 상호정보량(PMI)을 통해 이 문제를 개선하고자 한다.
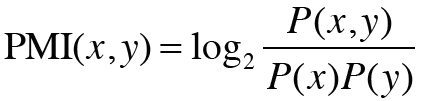
식에서 보면 알 수 있듯이 P(X) 값과 P(Y)의 확률 즉 빈도수로 나누어 주기 때문에 the, a 같은 관사들의 빈도수에 비례하여 값이 크게 나오는 것을 방지한다. PMI 에서 더 나아가 두 단어의 동시발생 횟수가 0이면 log값이 무한대가 되는 것을 방지하는 PPMI 가 있다는 것도 알아두면 좋다.
PMI 개선하기
앞에서 본 PMI로 단어의 의미를 전달 한다고 느낄 수 있다. 하지만 말뭉치의 어휘 수가 증가함에 따라서 단어 백터의 차원수가 증가함에 따라 벡터의 양이 엄청 많아진다는 단점이 있습니다. 또 한 백터 안을 드러다 보면 대부분의 값이 0으로 이루어져 있으며 중요하지 않은 정보라는 것을 알 수 있습니다. 따라서 저희는 차원 축소(dimeansionality redcution) 을 통해서 최대한 중요한 정보를 아끼고 벡터의 크기를 줄이고자 한다.
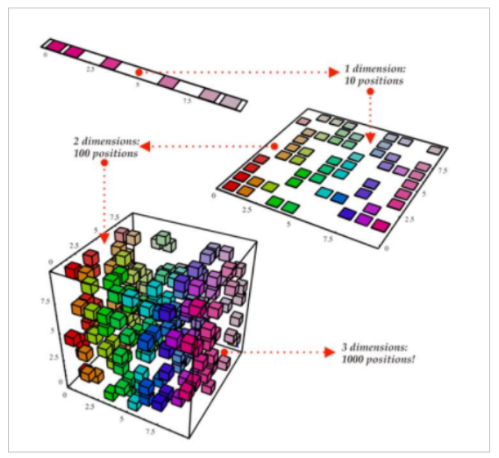
이런 차원 축소 방법에는 linear 한 방식으로 유명 한 것이 PCA(principal Component Analysis) 방식과 non-linear 한 방식인 AE가 있다는 것을 저번 VAE 이해하기 에서 배웠다.
통계 기반 기법을 통해 단어의 분산표현을 하고, 차원 기법을 통해서 차원 축소 하여 축소된 단어의 분산 표현을 나타낸 뒤 의미가 비슷한 단어들이 서로 가까이 붙어 있음을 확인 할 수 있었다. 더 나아가 추론 기법을 알아보자
추론 기법
앞에서 배운 통계 기반 기법에서 corpus 의 양이 많아지면 차원 축소를 통해서 중요한 값을 추출하는 것을 배웠다. 하지만 너무 많은 10만 정도의 corpus라면 차원을 축소해도 중요한 값을 얻어내기가 어렵다.
따라서 추론 기반 기법은 신경망을 사용하여 단어를 처리하는 기법으로 미니배치 학습을 하여 수많은 어휘를 효율적으로 학습한다.
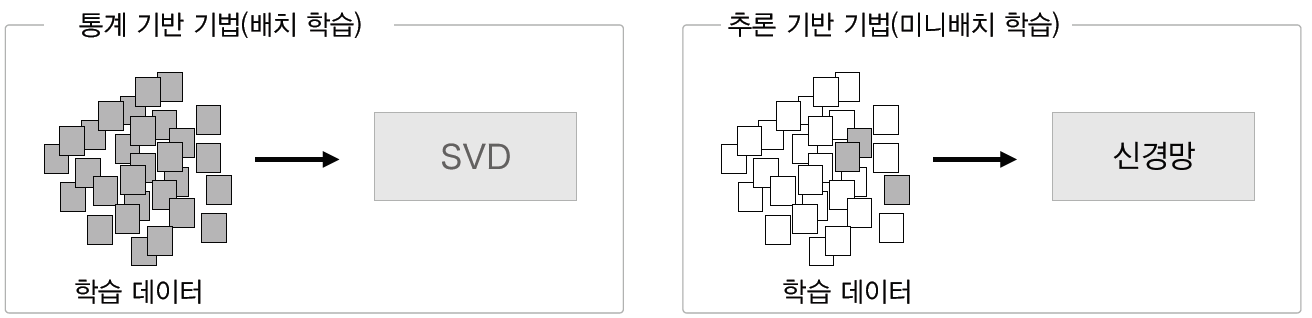
위의 사진처럼 일부 데이터를 나누어서 순차적으로 학습함에 있어서 신경망을 학습할 수 있게 되는 것이다. 더 나아가 추론 기법은 "you say goodbye and i hello ." 라는 문장이 있다면 가운데 구멍을 뚫고 안에 들어갈 높은 단어를 선정하게 된다. 따라서 구멍에 들어갈 말을 맞추기 위해서는 단어들을 신경망의 input 값으로 넣어야 하는데 어떻게 변환할까?
많이들 아는 단어를 on-hot 벡터 로 변환하여 신경망에 넣을 수 있다.
말 그대로 단어의 갯수만큼 리스트를 만들고 해당하는 단어에 대해서만 1로 표기한다.
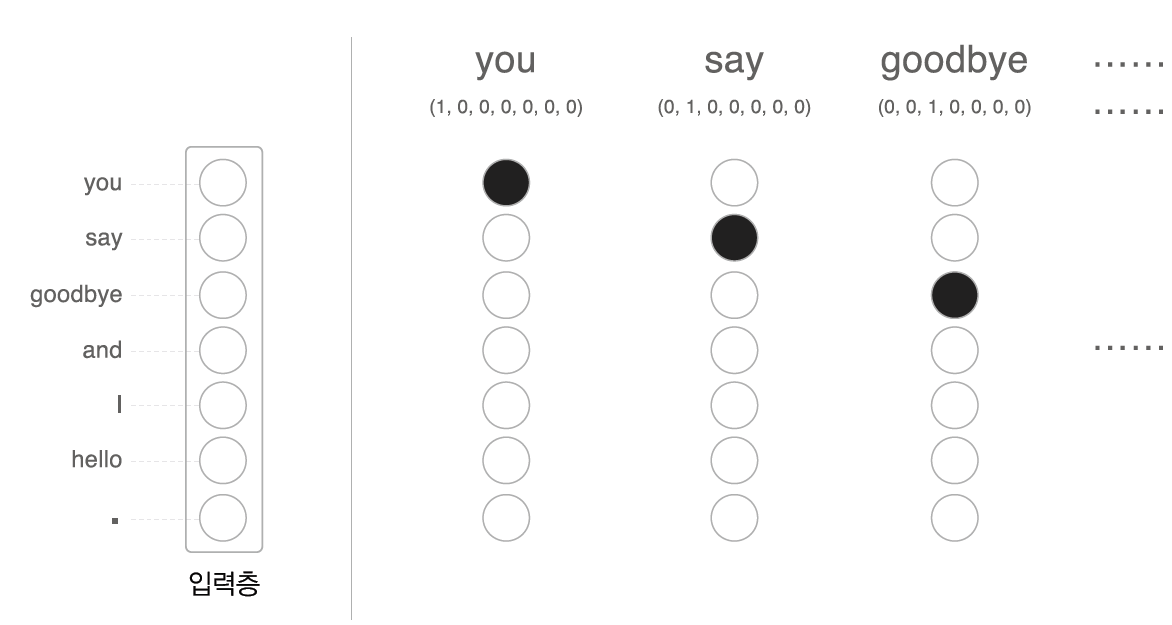
이런 벡터들은 기존에 신경망의 학습 방법과 동일하게 학습을 통해 구멍에 들어갈 단어에 대해 맞출 수 있는 유의미한 가중치를 얻어낼 수 있다.
1부를 마치며
이렇게 추론 기법의 word2vec 를 마치고 2부에서는 word2vec 의 2가지 종류 skip-gram모델 과 CBOW모델을 이해하고 임베딩과 네거티브 샘플링에 대해 알아보자.
