DeepLearning
1.TFIDF와 코사인 유사도를 통한 문서 추천하기

현재 가지고 있는 일기 데이터를 통해서 자신이 작성한 일기와 유사한 일기를 추천하는 시스템을 만들고자 하였습니다. TFIDF로 유사도를 측정하면서 문제점은 또 어떠한 것이 있는지 알아보겠습니다.먼저 프로젝트에 사용하는 모듈을 불러오기 위해서 가상환경을 설정해 줍니다.현
2021년 8월 8일
2.VAE 추천 시스템 구현하기
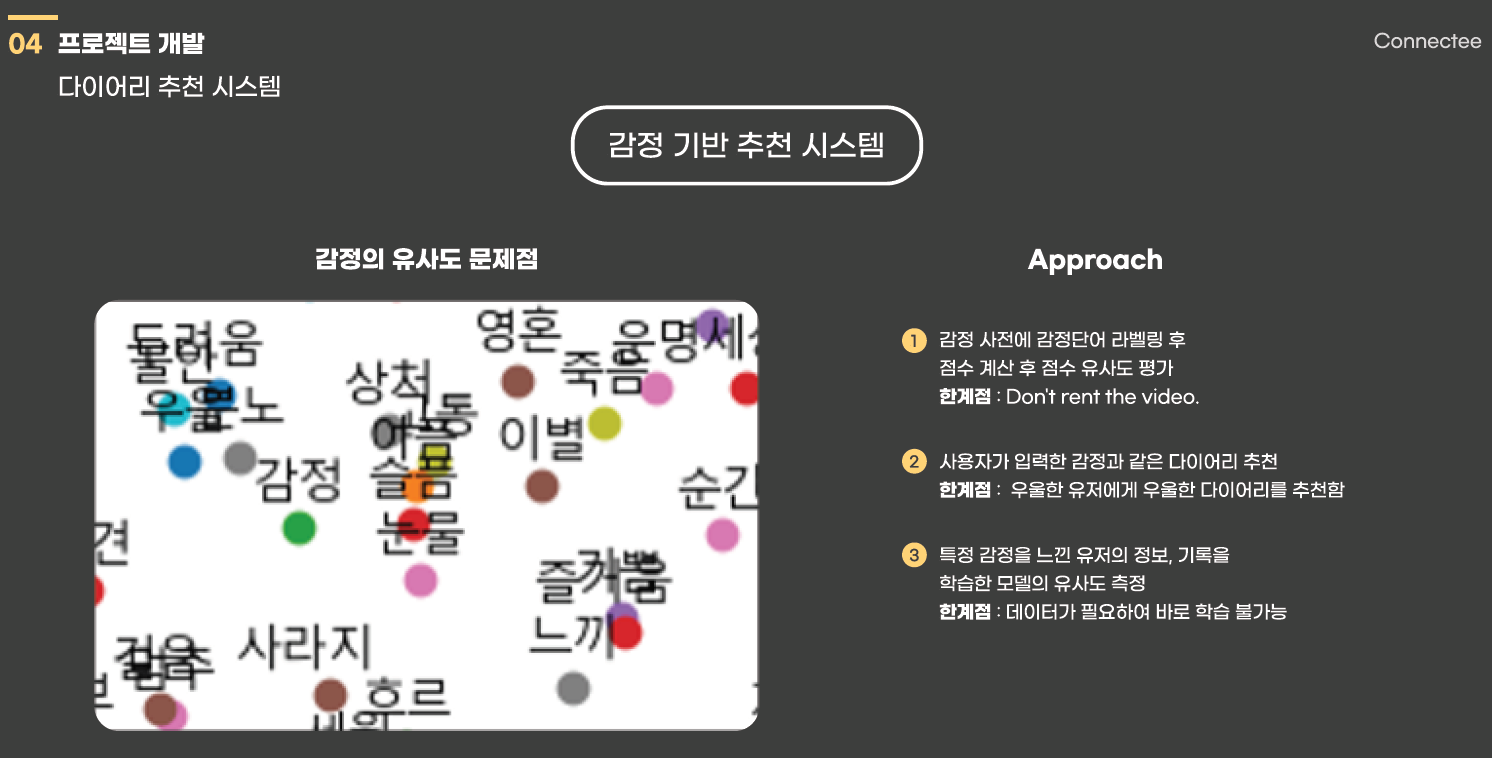
최근에 소마에서 추천 시스템을 공부하면서 감정 기반 추천 시스템을 준비 할 일이 있었다. 하지만 감정 단어들은 word2vec 방식을 사용하였을 때 유사한 벡터값을 가진 것을 알 수 있다. 따라서 다른 감정 기반 추천 방식을 생각해 보았고,
2021년 9월 8일
3.word2vec 이해하기 1부

들어가기에 앞서 최근에 딥러닝 기반 추천시스템을 공부하면서 밑바닥부터 시작하는 딥러닝을 읽게 되었다. 그 중에서 자연어 처리중에 기본시 되는 word2vec를 이해하는 과정에서 Embedding 과 negative sampling 에 대해 알아보자. 자연어와 단어
2021년 9월 26일
4.word2vec 이해하기 2부

앞에서 word2vec 의 대표 모델로 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법인 CBOW와 중간에 있는 단어로 주변 단어들을 예측하는 방법인 Skip-Gram 가 있다. 둘의 매커니즘은 유사하며 먼저 CBOW에 대해서 알아보자 CBOW CB
2021년 9월 30일
5.FastText 와 LDA 이해하기
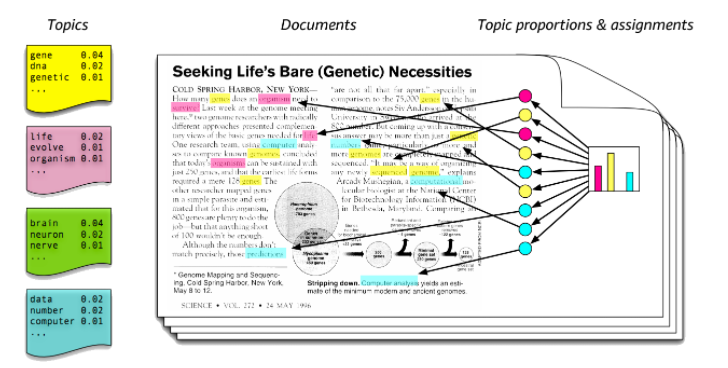
이번에 프로젝트를 마무리 함에 있어서 FastText 와 LDA에 대해 다시 한 번 정리하는 시간을 가져보고자 한다. LDA에 관하여 우선 LDA 즉 잠재 디리클레 할당에 대해서 이해 하기 위해서 토픽 모델링과 기존에 작성하였던 TF-IDF로 추천 시스템 구현하기
2021년 10월 11일