
저번 포스트에서는 라벨링, 모델 학습 및 엔드포인트 배포를 했었다.
이번 시간에는 해당 엔드포인트 모델로 예측 및 결과를 보자!
아래 이미지에서 모델 테스트를 해볼 수 있는데!!
모델을 계속 배포 상태로 두면 시간당 과금이 계속 되기에
아래 사진은 배포를 멈춘 화면이다.
(배포 가동 중 일때 예측 및 결과를 전부 만들어 놨으니 걱정 말아라!!
아무튼 배포를 가동 중 이라면 아래에 이미지 예측을 미리 해볼 수 있게
이미지 업로드 버튼이 생길 것이다!
그럼 예측을 하고 싶은 이미지를 업로드를 해보자!
1. 사용된 이미지의 종류
5가지(흰색 랜턴, 펭귄 사각티슈, 론 랜턴, 탐사 물티슈, 텀블러)
2. 각, 이미지별 학습에 사용된 이미지 개수
평균 100개(권장 되는 이미지는 1,000개 이상)
3. 학습 및 배포에 대입한 상황별 이미지 예측 결과
-
[단일 객체 타입]

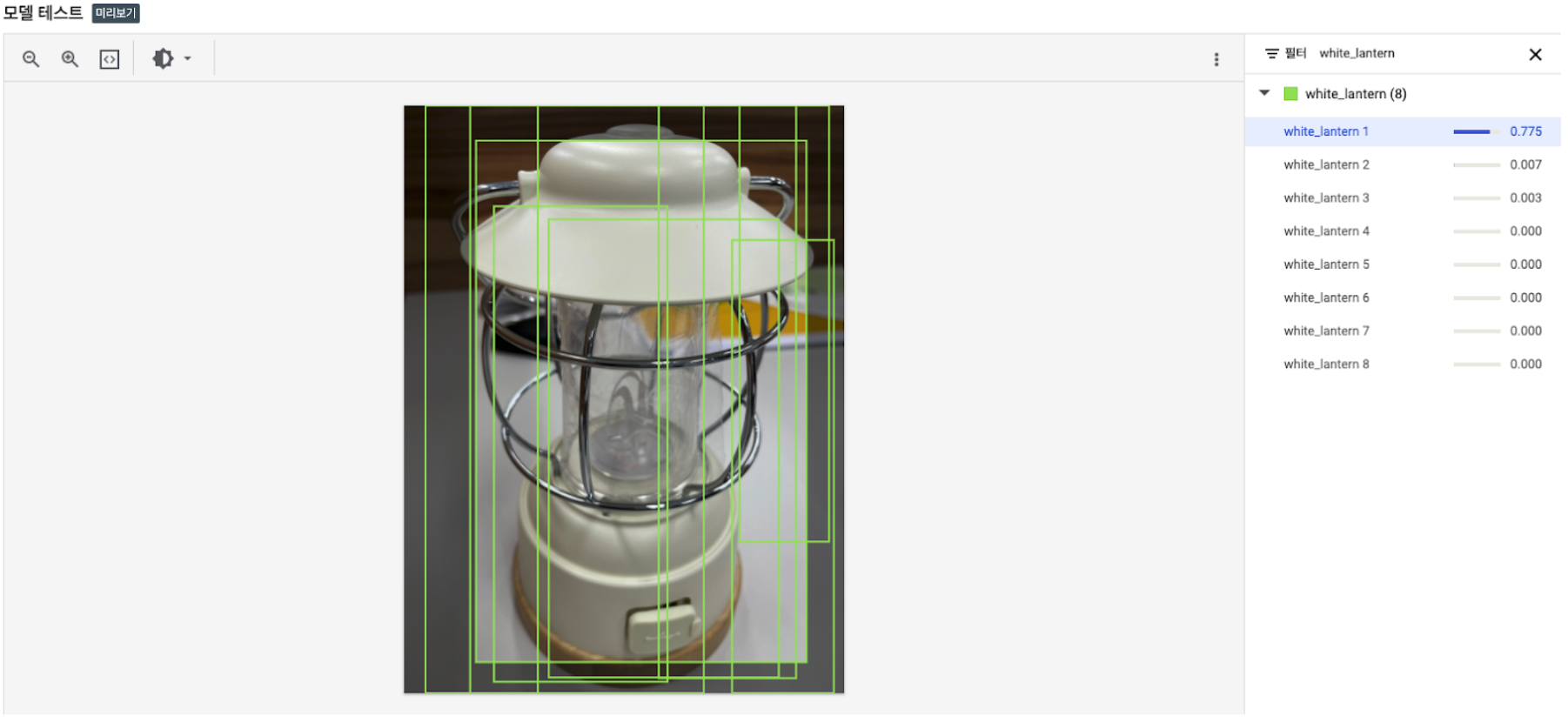
위의 흰색 랜턴 하나만 찍어서 예측 값을 추출 했을 때,
흰색 랜턴(white_lantern)의 값이 0.776으로 가장 높게 나왔음. -
[다중 객체의 경우 - 2개의 다른 형태의 객체 타입]

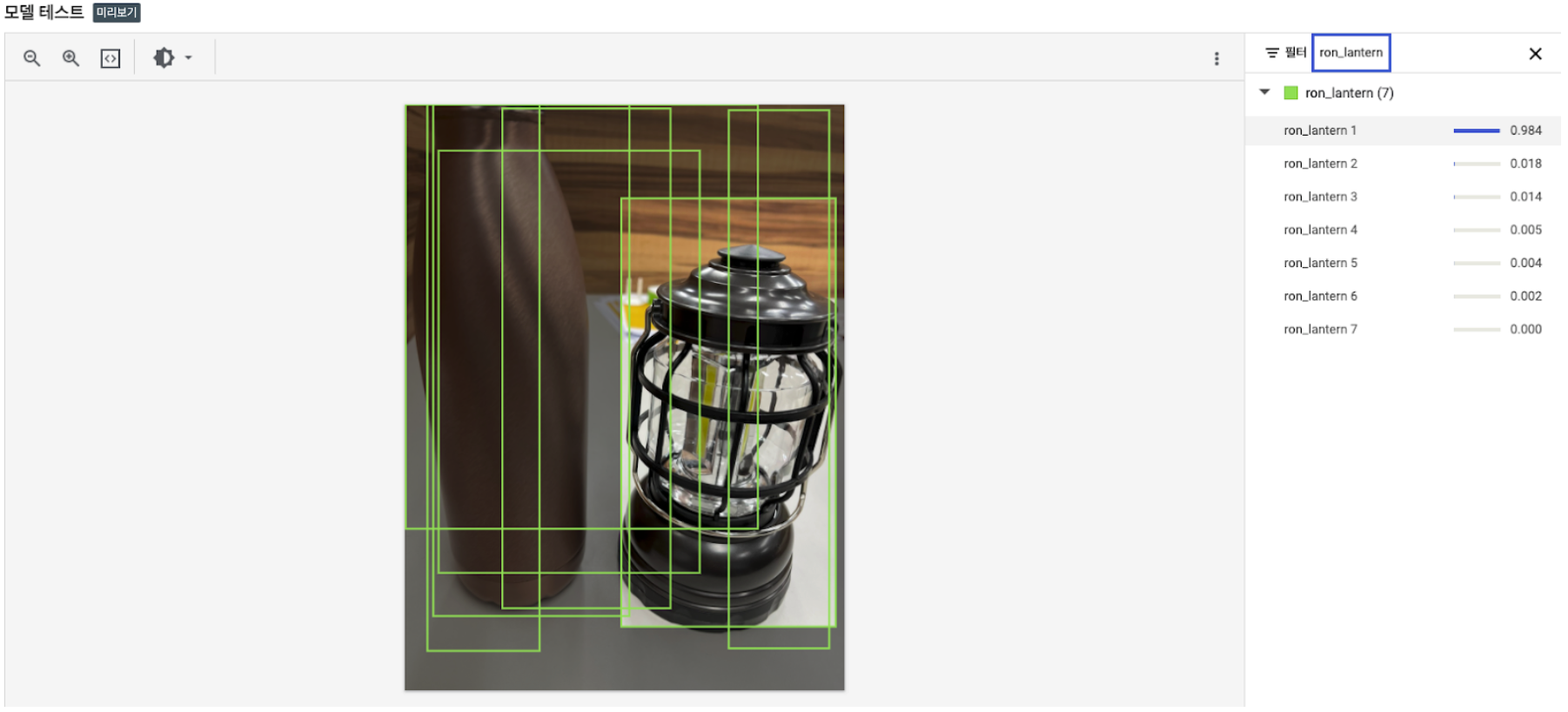
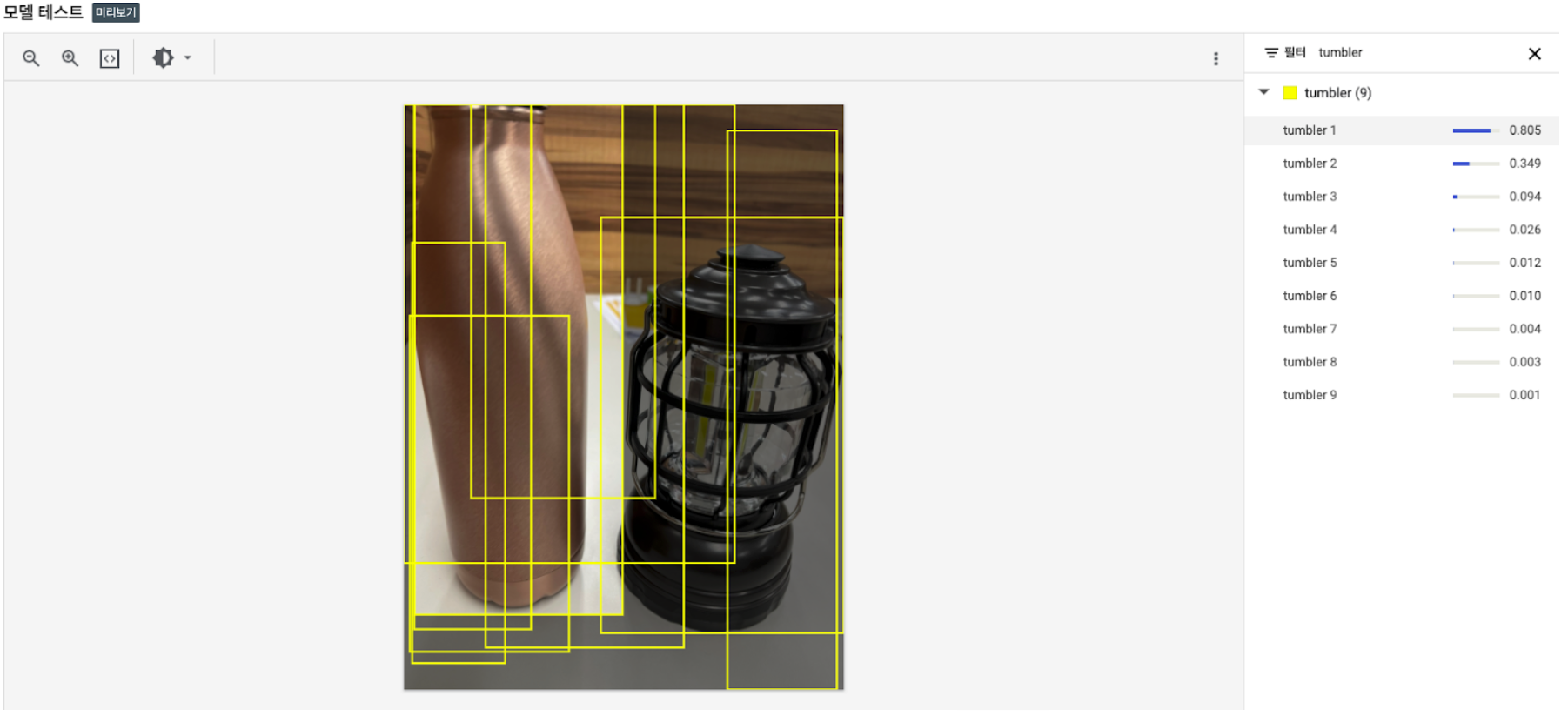
2개의 객체를 담은 사진을 예측 했을 때,
론 랜턴(ron_lantern)의 값은 0.984, 텀블러(tumbler)의 값은 0.805로
결과 값이 잘 분류가 되었음. -
[다중 객체의 경우 - 2개 이상의 비슷한 객체도 포함된 타입]

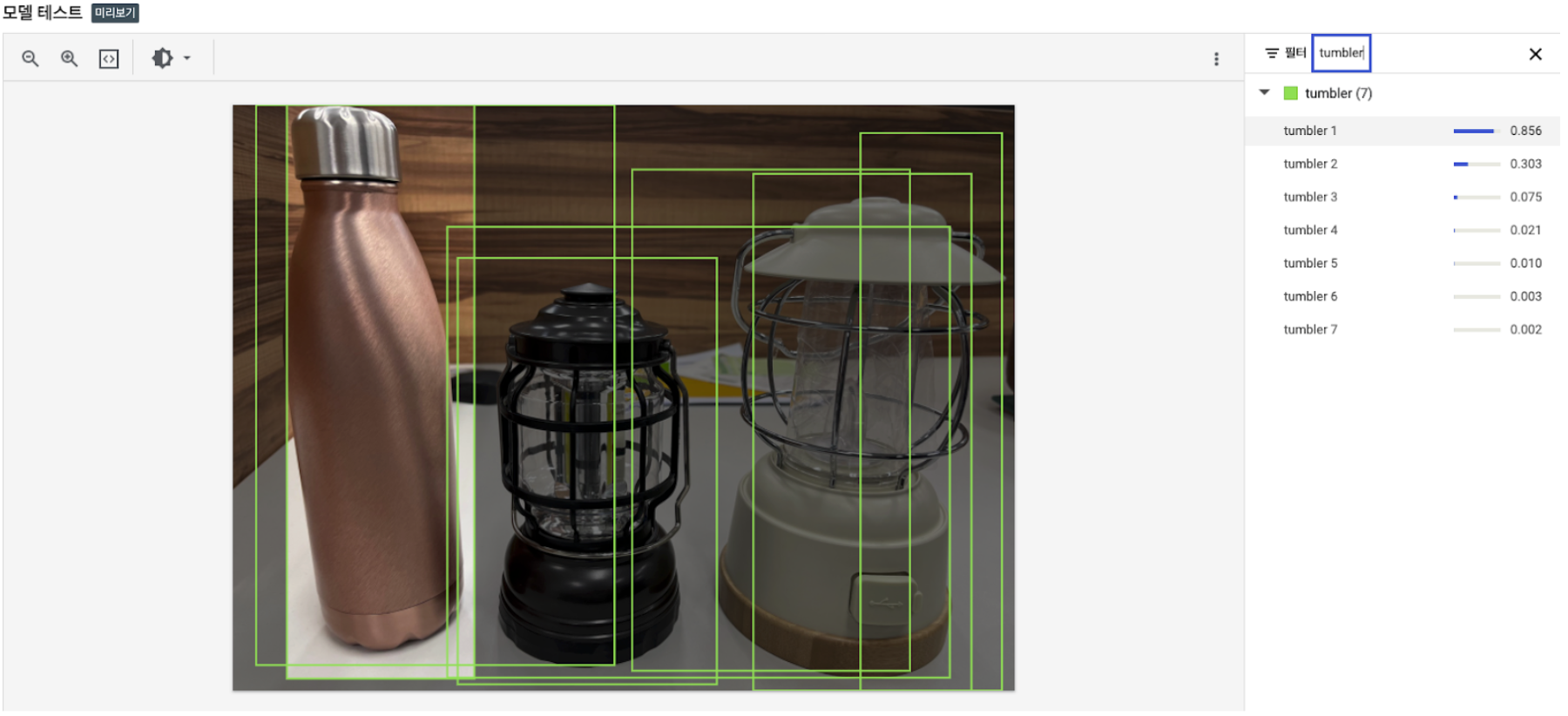


이번 타입의 경우에는 비슷한 형태의 모습을 가진 랜턴이 있는데
텀블러는 인식이 잘 되는 반면에
랜턴 2개의 경우에는 객체 영역에 있어서 혼선이 오고 있는 모습을 볼 수 있다.
이런 부분에서 학습된 이미지의 개수 부족의 영향이 크지 않나 싶음.
4. 최종 결과
최적의 학습은 각종 RGB 색상별, 다각도의 장면, 흐림~선명 까지의 다양한 상황,
권장하는 학습 이미지는 제품 하나당 1,000개 이상으로 권고 하고 있다.현재는 다양한 상황의 연출이 불가하기에 5개 제품을 각, 100개의 단순한 형태로 학습 시킨 상황을
예측한 결과로 봤을 때, 다음과 같은 문제점이 있다.
- 학습에 들어간 객체들 중, 비슷한 형태의 제품이 2개 이상 나오면 객체 선정에 혼란이 옴.
(즉, 론 랜턴과 하얀 랜턴이 있는데 서로의 영역이 겹치는 상황이 발생).- 객체 감지 점수가 다소 낮음.
(학습 이미지가 더 다양해지면 객체 감지 점수도 더 높일 수 있을 것이라 예상).- 캠핑장의 경우, 어둡거나 형태가 온전히 보여지지 않는 경우도 있을텐데 그럴 경우에도
객체 탐지가 불확실 할 것이라 예상.
