데이터셋 만들기
데이터셋을 만들기 위해서는 데이터를 수집하고 레이블링할 필요가 있음
머신 러닝
데이터가 적을때도 성능이 나온다
딥러닝
데이터가 많을때(수십, 수백억개) 성능이 잘 나옴
데이터 수집
데이터를 수집할 때는 데이터가 편향되지 않도록 주의
데이터 레이블링
-
데이터 레이블링은 주관적인 판단이 필요하기 때문에, 다양한 이슈가 발생할 수 있음(주관성, 비용)
-
레이블링하기 복잡하거나 어려운 데이터면 비용은 더 커짐
(의료나 법률, 과학기술 등 복잡한 배경지식이 있어야 레이블링 할 수 있는 데이터)
자동화된 레이블링
- 레이블링의 여러 문제를 완화하기 위해서 머신러닝을 이용하여 데이터 레이블링을 자동화할 수도 있음
- 준지도 학습(Semi-supervised Learning) : 레이블링되지 않은 데이터와 레이블링 된 데이터를 함께 사용하여 모델을 학습시키는 방법
새로 출시된 생성형 AI
https://www.bing.com/create
셀레늄
- 웹 브라우저 자동 제어를 위한 소프트웨어
- 웹 브라우저가 JavaScript 실행, 서버와 통신 등을 처리
- 직접 스크랩 할 경우 HTML만 전송하지만 웹 브라우저는 문서 내 모든 요소(이미지, 광고 등)를 다운로드 하므로 속도가 느릴 수 있음
라이브러리 설치
Colab에서는 크롬창이 안보이기 때문에 Jupyter Notebook을 사용하였다
웹 드라이버 설치(윈도, 맥)
- 크롬버전 확인: chrome://version
우상단 ... -> 도움말 -> Chrome 정보
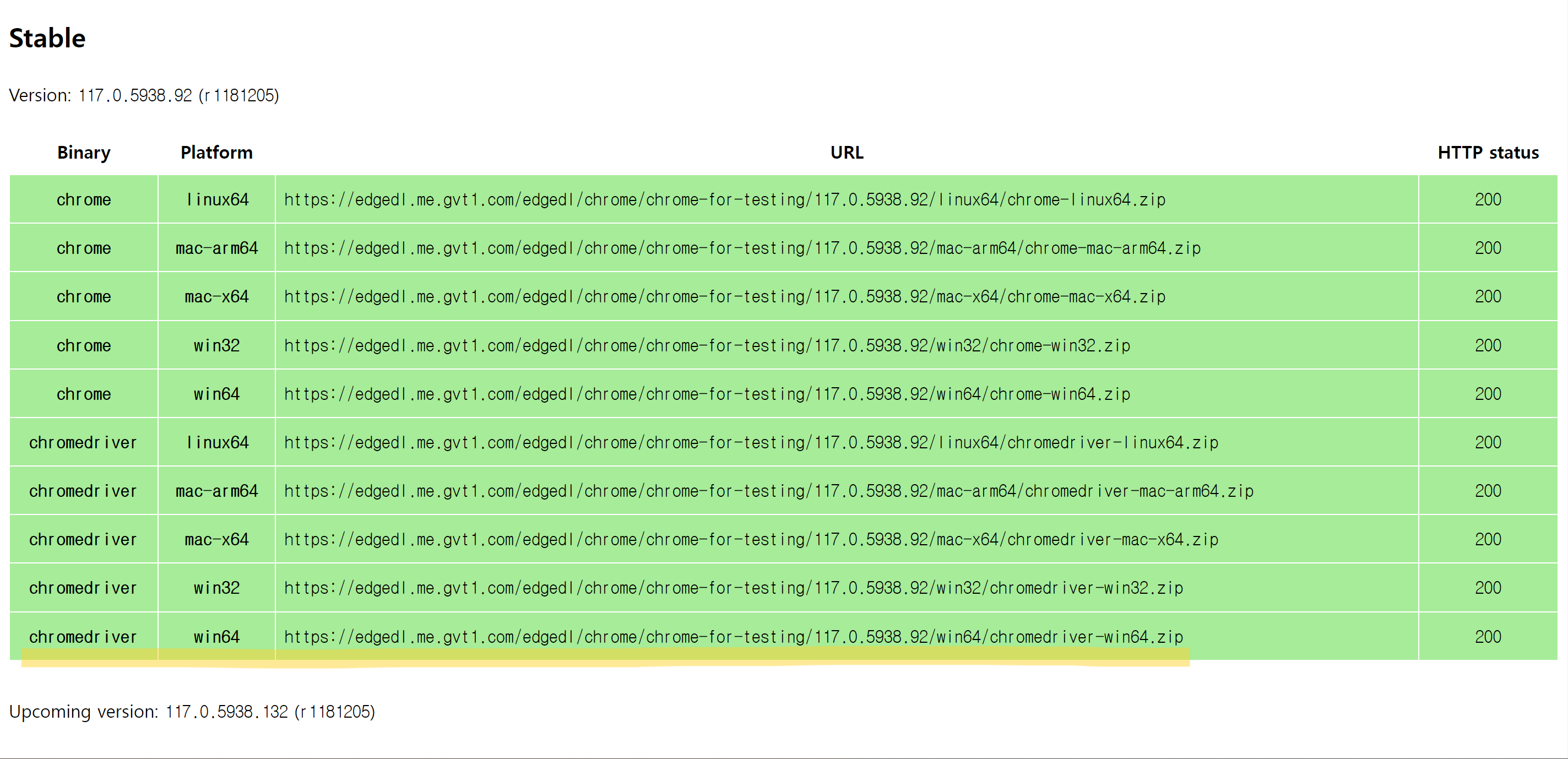
2.https://googlechromelabs.github.io/chrome-for-testing/
방문
- 자기 운영체제에 맞는 압축 파일 주소를 주소창에 붙여넣기
Jupyter Lab 사용
설치
!pip install selenium이 경로에 아까 다운받은 chromdriover.exe 폴더를 이동
import os
print(os.getcwd())C:\Users\AprilChoi
import
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.service import Service
service = Service(executable_path='chromedriver.exe')
browser = Chrome(service=service)데이터 수집
browser.get('https://blog.naver.com') # 네이버 블로그로 이동해라
browser.current_url # 현재 실제 주소가 어떻게 되냐
from selenium.webdriver.common.by import By
elems = browser.find_elements(By.CSS_SELECTOR, 'a.link_naver')
elems
elem = elems[0]
elem.text
elem.get_attribute('href') # 네이버로고를 코드로 클릭할 수 있다
# 본인이 원하는 키워드 넣기
url = 'https://section.blog.naver.com/Search/Post.naver?pageNo={}&keyword={}'
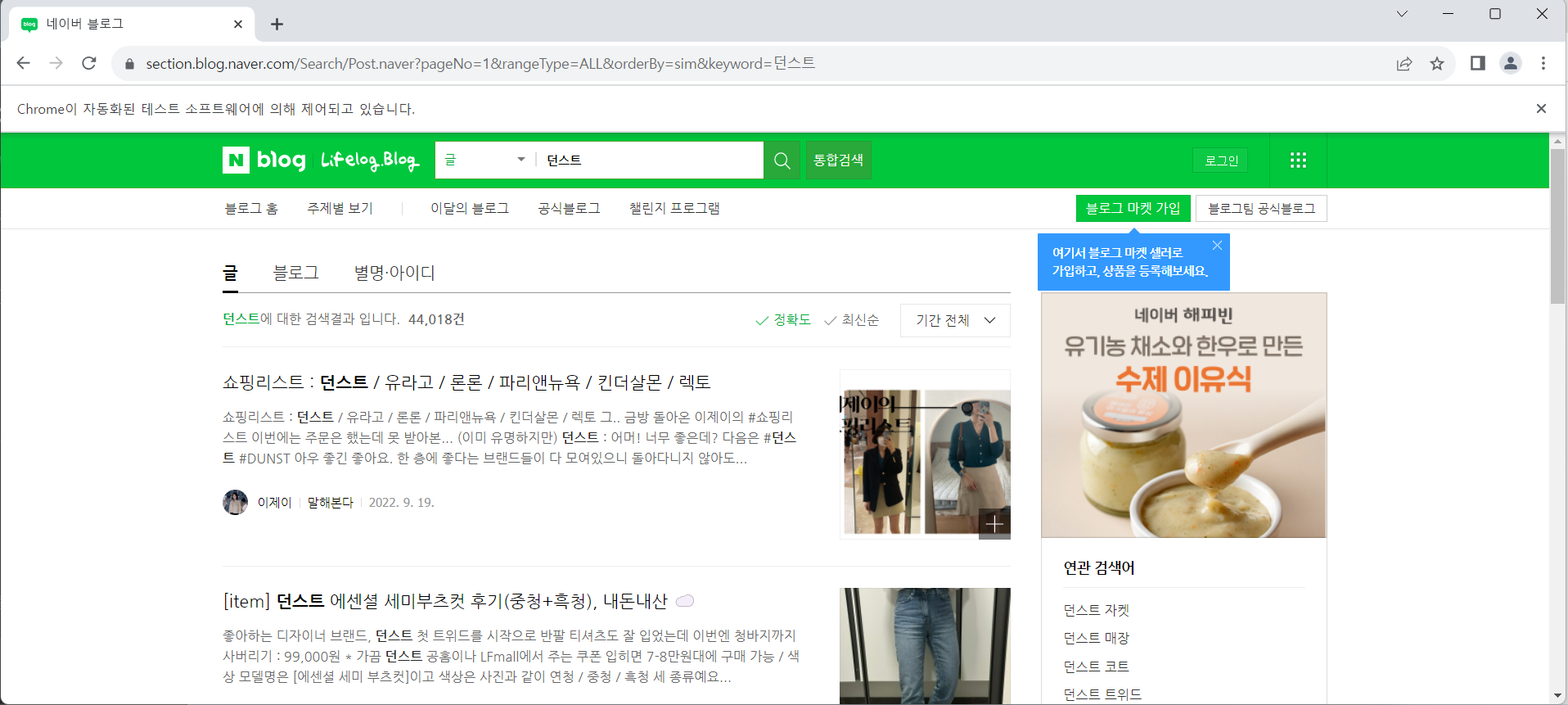
browser.get(url.format(1, '던스트'))
# 제목 링크 찾기
elems = browser.find_elements(By.CSS_SELECTOR, 'a.desc_inner')
post_urls = []
for elem in elems:
post_urls.append(elem.get_attribute('href'))
post_urlsiframe
한 페이지의 일부에 다른 웹페이지를 보여줌
우클릭 허용 확장프로그램 설치후 사용
블로그 내용 긁어오기
# id와 내용 뽑기
import re
post_url = post_urls[0]
m = re.match(r'https://blog.naver.com/(\w+)/(\d+)', post_url) # 정규표현식 이용해서 뽑아내기
blog_id, log_no = m.groups()
frame_url = f'https://blog.naver.com/PostView.naver?blogId={blog_id}&logNo={log_no}'
browser.get(frame_url)
browser.find_element(By.CSS_SELECTOR, 'div.se-main-container').text
# 주소 수집하기
import time
url = 'https://section.blog.naver.com/Search/Post.naver?pageNo={}&keyword={}'
post_urls = []
for page in range(1, 3): # 1~2페이지(3페이지 포함X)
browser.get(url.format(page, '던스트'))
time.sleep(3) # 3초간 대기
elems = browser.find_elements(By.CSS_SELECTOR, 'a.desc_inner')
for elem in elems:
post_urls.append(elem.get_attribute('href'))
post_urls
# 본문 수집하기
import re
import tqdm.auto as tqdm
texts = []
for post_url in tqdm.tqdm(post_urls):
m = re.match(r'https://blog.naver.com/(\w+)/(\d+)', post_url)
blog_id, log_no = m.groups()
frame_url = f'https://blog.naver.com/PostView.naver?blogId={blog_id}&logNo={log_no}'
browser.get(frame_url)
time.sleep(3)
texts.append(browser.find_element(By.CSS_SELECTOR, 'div.se-main-container').text)
# 엑셀파일로 저장하기
import pandas as pd
df = pd.DataFrame({'url': post_urls, 'text': texts})
df.to_excel('blog.xlsx')
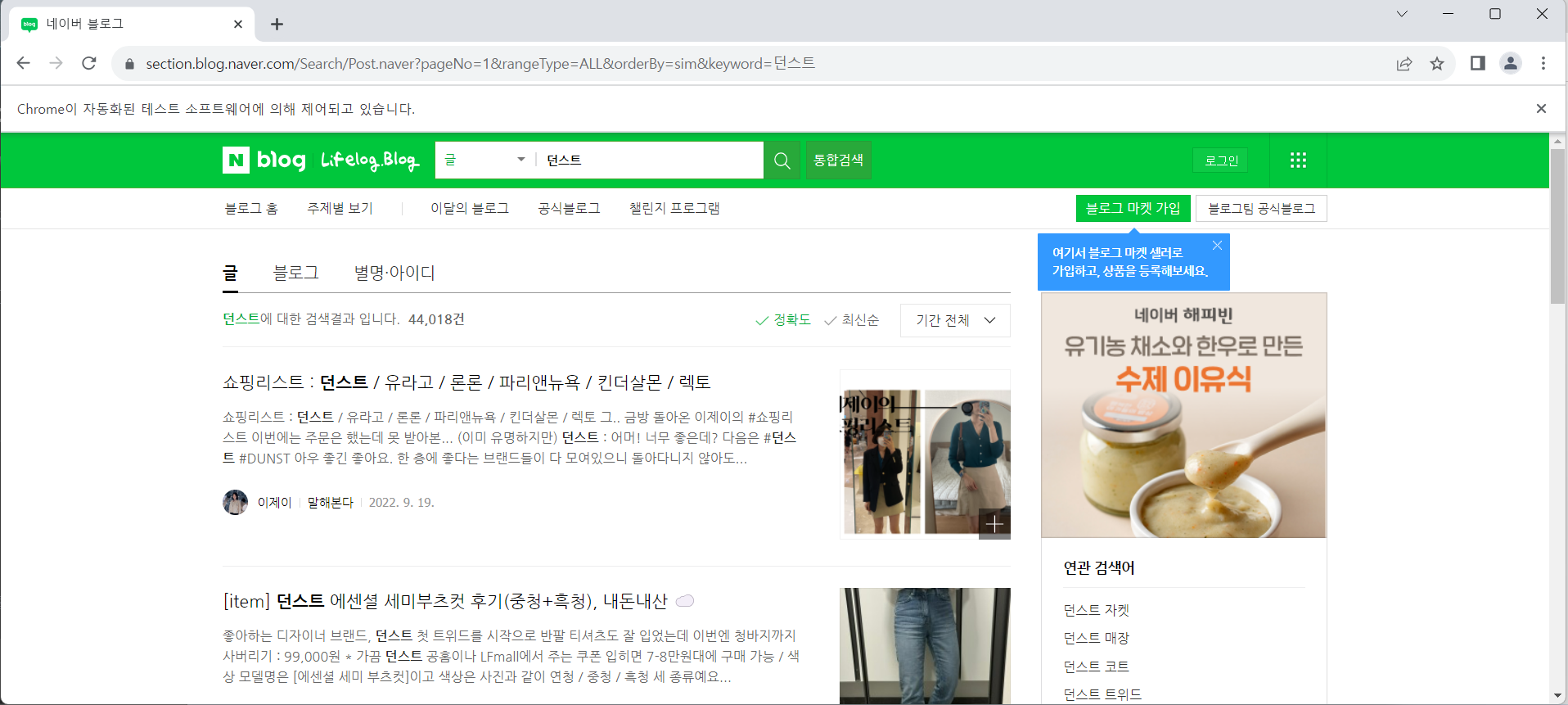
코드로 '던스트' 검색
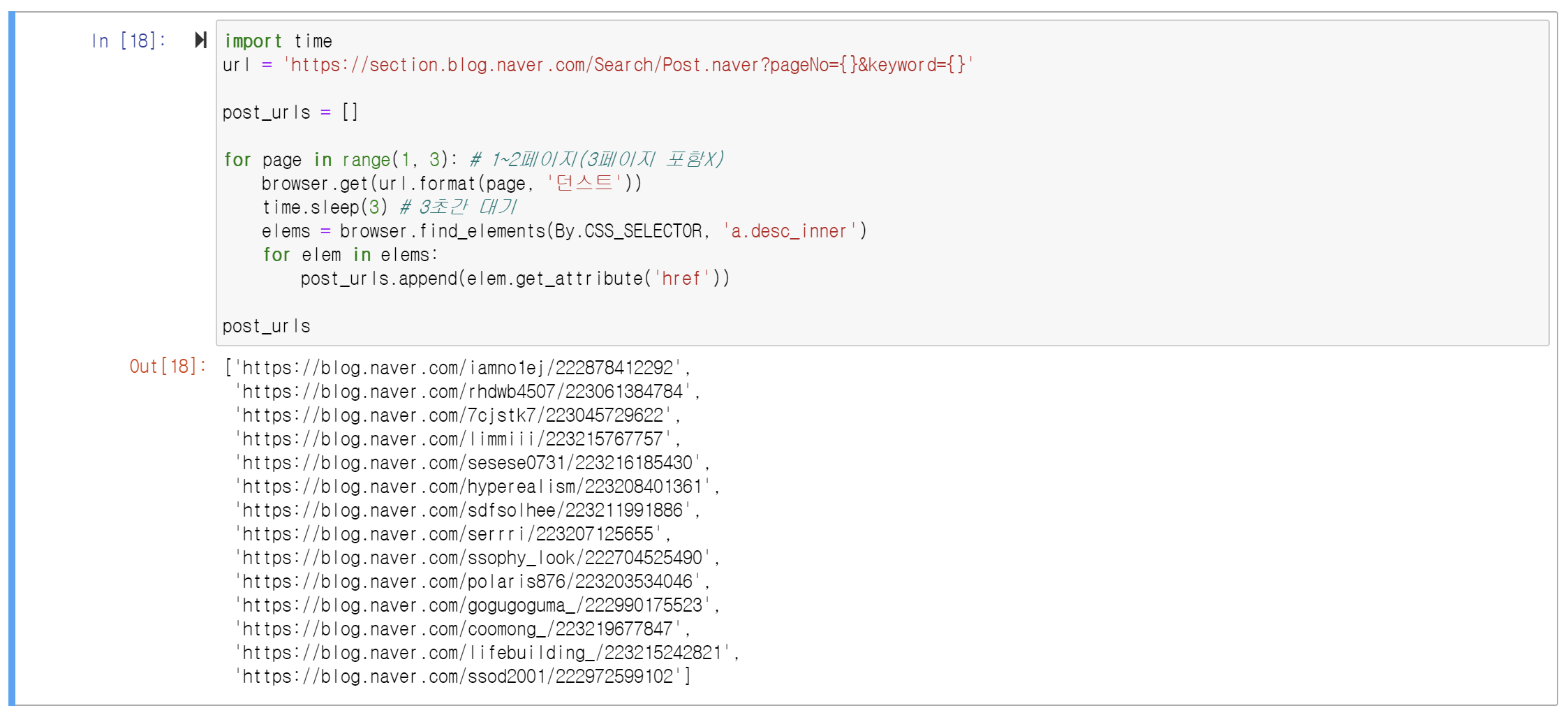
수집된 주소들

엑셀 파일로 저장된 주소와 본문
Q. url = 'https://section.blog.naver.com/Search/Post.naver?pageNo={}&keyword={}'
이 주소는 어떻게 가져오신 건가요?
(1) 검색을 한다
그냥 네이버 블로그 홈에서 검색을 하면 아래와 같은 주소로 이동
https://section.blog.naver.com/Search/Post.naver?pageNo=1&rangeType=ALL&orderBy=sim&keyword=%EB%8D%98%EC%8A%A4%ED%8A%B8
(2) 포스트에 들어가서 본문을 가져온다
검색을 한 주소로 들어가면 그 블로그가 프레임으로 되어 있다
프레임 보기
