cf) 완벽하게 리서치와 정리를 한 후에 포스팅 하는게 아니라 작성하면서 정리해나가는 것이므로 추후에 지속적인 업데이트 예정
SQL문 작성요령
문법 작성 순서
① SELECT 컬럼명
② FROM 테이블명
③ WHERE 조건식
④ GROUP BY 컬럼명
⑤ HAVING 조건식
⑥ ORDER BY 칼럼명
실행 작동 순서
① FROM
② ON
③ JOIN
④ WHERE
⑤ GROUP BY
⑥ CUBE | ROLLUP
⑦ HAVING
⑧ SELECT
⑨ DISTINCT
⑩ ORDER BY
⑪ TOP
주로 자주 사용되는 쿼리문의 순서는
- 조회 테이블 확인(FROM)
- 데이터 추출 조건 확인(WHERE)
- 컬럼 그룹화(GROUP BY)
- 그룹화 조건(HAVING)
- 데이터 추출(SELECT)
- 데이터 순서 정렬(ORDER BY)
순으로 이루어진다.
1. JOIN
2. GROUP BY
2-1. GROUP BY 란?
GROUP BY는 여러 row 를 하나로 묶을 때 사용한다.
SELECT
products.id, products.title, products.description, products.price,
product_images.url,
charges.name, charges.price
FROM products
LEFT JOIN product_images ON products.id = product_images.product_id
LEFT JOIN product_charges ON products.id = product_charges.product_id
LEFT JOIN charges ON product_charges.charge_id = charges.id
GROUP BY products.id;해당 sql 문은 아래처럼 여러 행을 묶기 위한 준비하고 있는 상태라고 보면 된다.
아래에 products.id 가 같은 row는 같은 색으로 색칠 되어 있는데, 위 쿼리문을 실행하면 에러가 발생한다. 이유는 색칠된 것처럼 준비까지만 하고 실제 묶는 행위는 하지 않았기 때문이다.
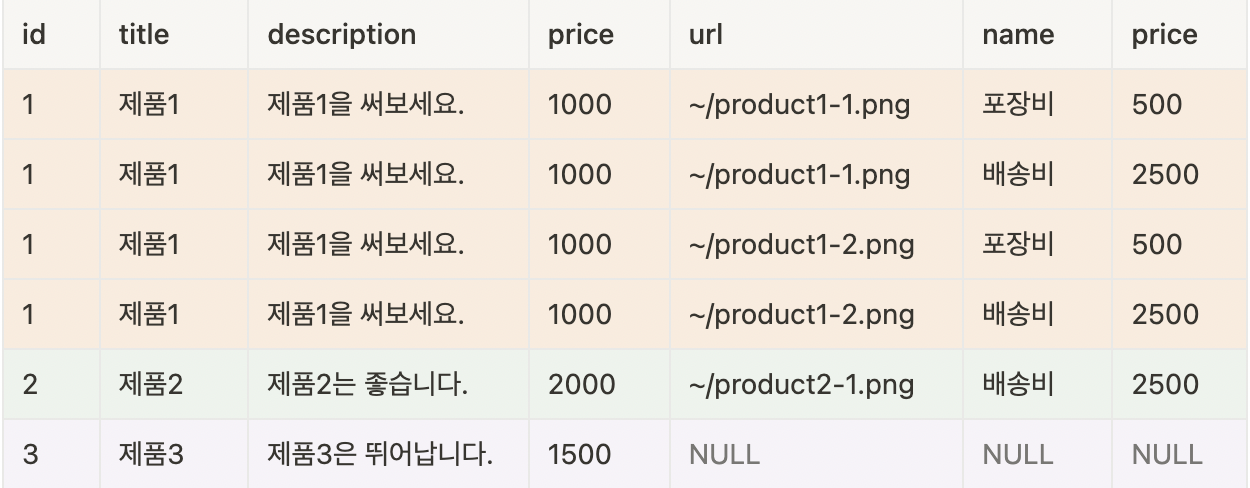
// 에러 발생!
Error Code: 1055. Expression #5 of SELECT list is not in GROUP BY clause and contains **nonaggregated column** 'advanced_sql.product_images.url' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_bymysql 에서는 aggregate 를 하지 않아서 생긴 오류라고 알려주고 있다. 이는 묶는 준비까지는 했는데 어떻게 묶어야할지 모르겠다라고 mysql 이 알려주는 것이라고 보면 된다.
2-2. 집계 함수(aggregate function)란?
집계 함수는 GROUP BY 로 묶인 행들을 어떻게 하나의 행으로 보여줄지에 대해 처리하는 함수를 의미한다. 종류로는 평균, 최대, 최소 등이 집계함수가 될 수 있다.
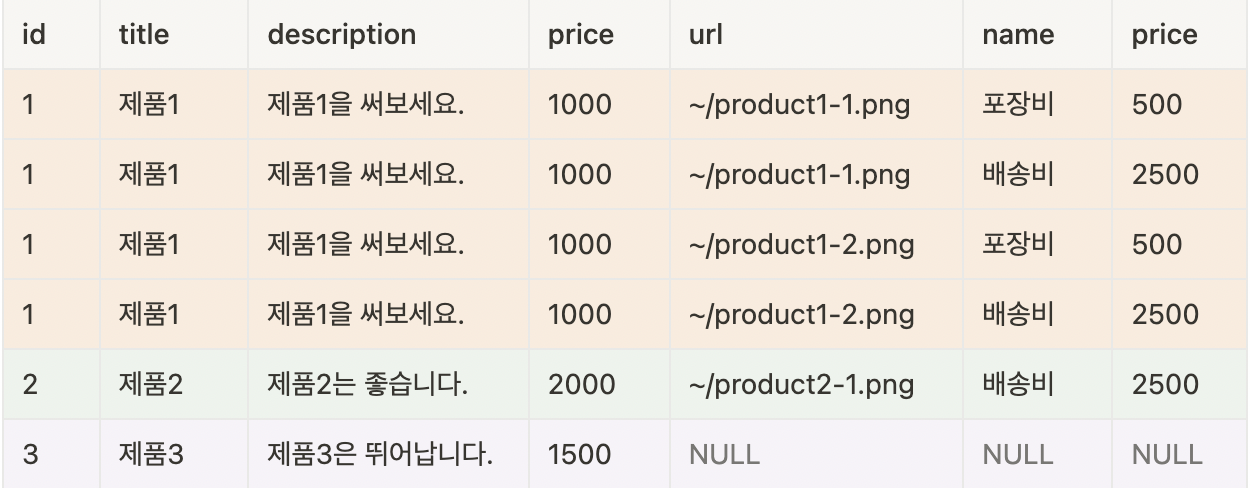
예제로 string 을 묶어주는 GROUP_CONCAT 함수와 JSON 형태로 보이게 하는 JSON_ARRAYAGG 함수를 사용하면 다음과 같다.
-- GROUP_CONCAT 을 사용하였을 때
SELECT
products.id, products.title, products.description, products.price,
GROUP_CONCAT(product_images.url),
GROUP_CONCAT(charges.name), GROUP_CONCAT(charges.price)
FROM products
LEFT JOIN product_images ON products.id = product_images.product_id
LEFT JOIN product_charges ON products.id = product_charges.product_id
LEFT JOIN charges ON product_charges.charge_id = charges.id
GROUP BY products.id;
-- JSON_ARRAYAGG 을 사용하였을 때
SELECT
products.id, products.title, products.description, products.price,
JSON_ARRAYAGG(product_images.url),
JSON_ARRAYAGG(charges.name), JSON_ARRAYAGG(charges.price)
FROM products
LEFT JOIN product_images ON products.id = product_images.product_id
LEFT JOIN product_charges ON products.id = product_charges.product_id
LEFT JOIN charges ON product_charges.charge_id = charges.id
GROUP BY products.id;3. sub-query
3-1. sub-query 란?
서브쿼리는 쿼리 내에서 일부분의 데이터를 가져올 때 사용할 수 있다.
이는 전체적인 데이터를 들고 오는 방식이 아닌 원하는 데이터들만 조회해서 들고오기 때문에 더 정확한 JOIN 연산을 진행할 수 있다.
다음과 같이 sub query 와 GROUP BY 를 합쳐서 데이터를 가져올 수 있다.
SELECT
products.id, products.title, products.description, products.price,
pi.images,
pc.charges
FROM products
LEFT JOIN (
SELECT
product_id,
JSON_ARRAYAGG(
JSON_OBJECT(
"id", id,
"url", url
)
) as images
FROM
product_images
GROUP BY product_id
) pi ON products.id = pi.product_id
LEFT JOIN (
SELECT
product_id,
JSON_ARRAYAGG(
JSON_OBJECT(
"id", product_charges.id,
"name", charges.name,
"price", charges.price
)
) as charges
FROM
product_charges
JOIN
charges ON product_charges.charge_id = charges.id
GROUP BY product_id
) pc ON products.id = pc.product_id
GROUP BY products.id;변경된 부분은 SELECT 요소와 LEFT JOIN 다음 부분이다.
이전 쿼리에서는 LEFT JOIN 다음 부분이 테이블 이름이었지만, 현재 쿼리의 경우에는 LEFT JOIN 다음 부분이 서브 쿼리가 들어가 있다.
| id | title | description | price | images | charges |
|---|---|---|---|---|---|
| 1 | 제품1 | 제품1을 써보세요 | 1000 | [{"id": 1, "url": "~/product1-1.png"}, {"id": 2, "url": "~/product1-2.png"}] | [{"id": 1, "name": "배송비", "price": 2500}, {"id": 2, "name": "포장비", "price": 500}] |
| 2 | 제품2 | 제품2는 좋습니다. | 2000 | [{"id": 3, "url": "~/product2-1.png"}] | [{"id": 3, "name": "배송비", "price": 2500}] |
| 3 | 제품3 | 제품3은 뛰어납니다. | 1500 | NULL | NULL |
결과를 통해 서브 쿼리가 먼저 실행되고, 그 결과를 다시 하나의 테이블처럼 가정하여 JOIN을 한 연산이 나타났다는 것을 알 수 있다.
이처럼 서브쿼리와 GROUP BY 를 결합하면 여러 테이블에 대한 JOIN을 내가 들고 오고 싶은 데이터에 대해서만 가져올 수 있게 된다.
cf) 서브쿼리 작성시, 한번에 모든 쿼리를 작성하시는 것보다 먼저, 서브 쿼리들이 실행되는지 확인하면서 쿼리를 작성하는 것이 좋다
3-2. sub-query 작성법&문법
- 비교연산자의 오른쪽에 기술해야 하고 반드시 괄호 안에 넣어야 한다.
- 메인 쿼리가 실행되기 이전에 한 번만 실행된다.
SQL의 기본 문법이자 가장 자주쓰이는 SELECT, WHERE, FROM 서브쿼리를 각각의 어느 위치에서 사용하냐에 따라 나누어진다.
-
SELECT 절 서브쿼리 (scalar sub-query)
- SELECT 절 안에 서브쿼리가 들어있다.
이 때, 서브쿼리의 결과는 반드시 단일 행이나 SUM, COUNT 등의 집계 함수를 거친 단일 값으로 리턴되어야 한다. 이유는 서브쿼리를 끝마친 값하나를 메인쿼리에서 SELECT 하기 때문이다.
예시
SELECT 학생이름, ( SELECT 학과.학과이름 FROM 학과 WHERE 학과.학과ID = 학생.학생ID ) AS 학과이름 FROM 학생 WHERE 학생이름 = '홍길동' ; - SELECT 절 안에 서브쿼리가 들어있다.
-
FROM 절 서브쿼리 (Inline Views sub-query)
- FROM 절 안에 서브쿼리가 들어있다. 이 때, 서브쿼리의 결과는 반드시 하나의 테이블로 리턴되어야 한다. 이유는 서브쿼리를 끝마친 테이블 하나를 메인쿼리의 FROM 에서 테이블로 잡기 때문이다.
예시
SELECT 학생이름, 수학점수
FROM ( SELECT 학생.학생이름 AS 학생이름,
과목.과목점수 AS 수학점수
FROM 학생, 과목
WHERE 학생.학생이름 = 과목.학생이름
AND 과목.과목이름 = '수학' ) ;-
WHERE 절 서브쿼리 ( 중첩 서브쿼리 )
- WHERE 절 안에 서브쿼리가 들어있다.
- 가장 자주 쓰이는 대중적인 서브쿼리이며 단일행과 복수행 둘 다 리턴이 가능하다. 이유는 서브쿼리를 끝마친 값들을 메인쿼리의 조건절을 통해 비교하기 때문이다.
SELECT *
FROM 학생
WHERE 학생.학생이름 IN ( SELECT 과목.학생이름 FROM 과목 WHERE 과목.과목이름 = '수학' ) ;-
단일행 서브쿼리
- 서브쿼리의 수행결과가 오직 하나의 ROW(행)만을 반환한다. 이 하나의 결과로 메인쿼리는 비교연산자를 통해 쿼리를 수행한다.
- 비교연산자는 단일행 비교연산자를 사용 ( >, >=, <, <=, =, ... )
// ex ) 사원들의 평균 급여보다 더 많은 급여를 받는 사원을 검색 SELECT ENAME, SAL FROM EMP WHERE SAL > ( SELECT AVG(SAL) FROM EMP); ```
-
다중행 서브쿼리
-
서브쿼리의 수행결과가 두 건 이상의 데이터를 반환한다.
-
비교연산자는 다중행 비교연산자를 사용 (IN, ANY, SOME, ALL, EXISTS).
-
※ 다중행 연산자
IN
메인쿼리의 비교조건이 서브쿼리의 결과중에서 하나라도 일치하면 참.
ALL
메인쿼리의 비교조건이 서브쿼리의 검색결과와 모든 값이 일치하면 참.
- 메인쿼리 < ALL ( 서브쿼리 ) : 서브쿼리의 결과와 비교하여 최소값 반환.
- 메인쿼리 > ALL ( 서브쿼리 ) : 서브쿼리의 결과와 비교하여 최대값 반환.
// ex ) 30번 소속 사원들 중 급여를 가장 많이 받는 사원보다 더 많은 급여를 받는 사람의 이름과 급여를 출력
SELECT ENAME, SAL
FROM EMP
WHERE SAL > ALL ( SELECT SAL
FROM EMP
WHERE DEPTNO = 30 );ANY
메인쿼리의 비교조건이 서브쿼리의 검색결과와 하나 이상이 일치하면 참.
-
메인쿼리 < ANY ( 서브쿼리 ) : 서브쿼리의 결과와 비교해 메인쿼리의 데이터중 한개라도 서브쿼리 결과보다 작다면 최소값 반환.
-
메인쿼리 > ANY ( 서브쿼리 ) : 서브쿼리의 결과와 비교해 메인쿼리의 데이터중 한개라도 서브쿼리 결과보다 크다면 최대값 반환.
EXISTS
메인쿼리의 비교조건이 서브쿼리의 검색결과중에 하나라도 만족하는 값이 존재하면 참.
IN은 실제 존재하는 데이터들의 모든 값까지 확인하지만, EXISTS 는 해당 로우가 존재하는지의 여부만 확인한다.
NOT EXISTS는 메인쿼리의 컬럼명과 서브쿼리의 컬럼명을 비교하여 일치하지 않으면 메인쿼리 테이블의 모든 ROW(행)을 반환한다.
4. Application JOIN
