Connectionist Temporal Classification (CTC) (https://www.cs.toronto.edu/~graves/icml_2006.pdf)
정답의 시간표 없이 스스로 학습하는 음성 인식의 혁명
"안녕"을 0.5초에 말하든 2초에 말하든, 사람이 시간 짝을 맞춰주지 않아도 인공지능이 스스로 패턴을 찾아내는 수학적 마법.
ICML 2006 | Alex Graves et al. (IDSIA, Switzerland / TU München)
목차
- 서론
- Background
- Problem Definition
- Proposed Method / Approach
- Experiments & Results
- Discussion
- My Insights
- Summary
1. 서론
이 논문은 음성 인식 AI가 '생각보다 훨씬 많은 사전 준비를 요구해왔다' 는 불편한 진실을 파고든 연구입니다.
기존 인공지능은 순서가 있는 데이터를 다룰 수 있습니다. 하지만 치명적인 단점이 있었습니다. 입력 데이터와 정답의 짝이 시간별로 정확히 맞아야 했습니다. 현실의 음성은 소리의 시작과 끝이 명확히 나뉘지 않습니다. 사람이 일일이 시간 짝을 맞추는 작업은 돈과 시간이 너무 많이 듭니다.
이 논문은 미리 짝을 맞추지 않고도 인공지능이 스스로 정답을 찾아내는 방법인 CTC(Connectionist Temporal Classification) 를 제안합니다. 이 글을 끝까지 읽으시면, 복잡한 수식에 빠지지 않고도 왜 이 논문이 현재 음성 인식 AI의 근본 공식이 되었는지 직관적으로 깨닫게 되실 겁니다.
2. Background
논문의 핵심으로 들어가기 전에, 왜 이런 연구가 필요했는지 배경지식을 가볍게 짚고 넘어가 봅시다.
기존 음성 인식의 지배자: HMM
2006년 이전의 음성 인식은 은닉 마르코프 모델(HMM, Hidden Markov Model) 이 지배했습니다. 하지만 HMM에는 구조적인 한계가 세 가지 있었습니다.
| 한계 | 설명 |
|---|---|
| task-specific 지식 필요 | 상태 모델 설계 등 사람이 직접 설계해야 하는 부분이 많음 |
| 독립성 가정 | 바로 직전 상태만 보고 다음을 예측 — 긴 문맥 기억 불가 |
| 생성 방식 학습 | 분류 문제임에도 불구하고 생성 모델 방식으로 훈련함 |
순환 신경망(RNN)의 가능성과 한계
RNN은 시계열 데이터에 강하고, 사전 지식 없이 훈련이 가능한 이점이 있었습니다. 하지만 한 가지 결정적인 문제가 있었습니다.
기존 RNN은 매 순간마다 독립적인 글자 분류만 할 수 있었습니다. 훈련하려면 소리 데이터의 어느 타이밍에 어느 글자가 나오는지, 사람이 수작업으로 만든 완벽한 시간표(정답 라벨) 가 꼭 필요했습니다.
해결해야 할 근본 문제
사람마다 말하는 속도가 다릅니다. 어떤 사람은 "안녕"을 0.5초에, 다른 사람은 2초에 말합니다. 이 길이를 매번 수작업으로 기록하는 것은 불가능합니다. 이 문제를 풀지 못하면 음성 인식 AI를 실생활에 널리 쓸 수 없습니다.
3. Problem Definition
이 논문이 꼬집는 핵심 문제는 "기존 방법은 너무 많은 사전 작업을 요구하고, 모델의 잠재력을 제대로 쓰지 못한다" 는 것입니다.
기존 방식의 한계
| 방식 | 설명 | 치명적 단점 |
|---|---|---|
| HMM | 통계 기반으로 시퀀스를 모델링 | 먼 과거 문맥을 기억하지 못함 |
| HMM-RNN 하이브리드 | HMM이 분절을 담당, RNN이 분류 | 사람이 만든 시간표 필수, HMM의 단점을 그대로 상속 |
| 프레임 단위 모델 | 소리를 짧은 조각으로 나눠 각각 분류 | 매 조각마다 정답 요구 — 수작업 필수 |
직관적 비유 🏃
음성 인식을 음악 받아쓰기로 비유해 봅시다.
- 기존 방식: 악보에 '2박자 자리에는 반드시 '도'를 쳐야 해!'라고 미리 표시된 악보(시간표)가 있어야만 연습할 수 있습니다.
- CTC가 풀려는 것: 악보 없이 그냥 음악을 들려주고, 인공지능이 스스로 "이 부분이 '도'겠구나"를 터득하게 만드는 것입니다.
이 문제를 해결하면
수작업 시간표(Forced Alignment) 없이 음성-텍스트 쌍 데이터만 있으면 처음부터 끝까지 신경망 하나로(End-to-End) 학습이 가능해집니다.
4. Proposed Method / Approach
CTC는 '빈칸(Blank) 기호 도입'과 '모든 경로 합산' 이라는 두 가지 핵심 아이디어로 이 문제를 해결합니다.
전체 작동 순서
- 빈칸 기호 추가 — 알파벳 외에 '아무 글자도 아님(blank)'을 뜻하는 기호를 새로 만듭니다.
- 매 순간 확률 계산 — 인공지능이 매 타임스텝마다 각 글자(또는 빈칸)가 나올 확률을 계산합니다.
- 중복 합치기 — 연속으로 같은 글자가 나오면 하나로 압축합니다.
- 빈칸 제거 — 남은 빈칸을 모두 지우면 최종 단어가 완성됩니다.
빈칸(Blank) 기호의 역할
빈칸 기호는 단순히 '아무것도 없음'이 아닙니다. 중요한 역할이 있습니다.
예시: 'Hello'의 'l'은 연속으로 두 번 등장합니다. 빈칸 없이 [H, e, l, l, o]가 나오면 인공지능은 중복 압축 규칙에 의해 'Helo'로 오해합니다. 빈칸이 있어야 [H, e, l, blank, l, o] → 'Hello'가 유지됩니다.
직관적 예시 4가지 💡
| 상황 | 인공지능 예측 | 최종 결과 |
|---|---|---|
| "안~~~녕"이라고 길게 말함 | [안, 안, blank, 녕] | 안녕 |
| "Hello"에서 l이 두 번 나옴 | [H, e, l, blank, l, o] | Hello |
| 태블릿에 'a'를 천천히 씀 | [a, a, a, a, a, a, a, a] | a |
| "나...는"이라고 더듬으며 말함 | [나, blank, blank, blank, 는] | 나는 |
수식 이해하기
첫 번째 수식: 하나의 경로(길)를 통과할 확률
비유 먼저:
동전을 3번 던집니다. '앞-뒤-앞'이 나올 확률은 어떻게 구할까요? 각 시도의 확률을 모두 곱하면 됩니다. CTC도 똑같습니다.
| 기호 | 의미 |
|---|---|
| 입력된 소리 데이터 | |
| 특정한 글자의 순서 (예: a-blank-b) | |
| 인공지능이 시간 에 그 글자를 예측할 확률 | |
| 전부 곱하라는 수학 기호 |
이 수식이 없다면? 인공지능이 예측한 수많은 글자 조합 중 어떤 조합이 더 믿을 만한지 점수를 매길 수 없습니다.
두 번째 수식: 모든 가능한 길을 합쳐서 정답에 도달할 확률
비유 먼저:
서울에서 부산까지 가는 길은 여러 개입니다. '부산에 도착할 전체 확률'은 고속도로 확률 + 국도 확률을 모두 더하면 됩니다. 'cat'이라는 정답을 만드는 경로는 수백 개가 넘습니다. 이를 전부 더하면 'cat'이 정답일 최종 확률이 나옵니다.
| 기호 | 의미 |
|---|---|
| 최종 정답 텍스트 (예: cat) | |
| 압축했을 때 'cat'이 될 수 있는 모든 경로들의 모음 | |
| 전부 더하라는 수학 기호 |
이 수식이 없다면? 인공지능은 정답이 되는 '모든 경우의 수'를 고려하지 못해 학습 자체가 불가능해집니다.
📊 Figure 1 — Framewise vs CTC 출력 비교
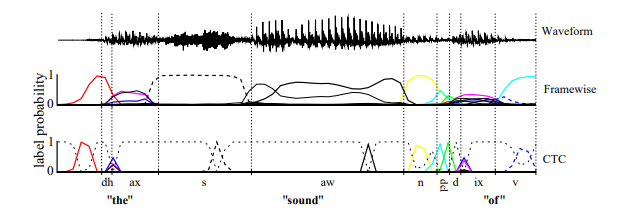
- 이 그림이 보여주는 것: 같은 음성 신호("the sound of")를 Framewise 모델과 CTC 모델이 각각 어떻게 처리하는지 비교한 출력 활성화 그래프. 가로축은 시간, 세로축은 각 음소(phoneme)의 예측 확률입니다.
- 핵심 메시지: Framewise는 사람이 표시한 세로 구분선(수동 분절)에 맞춰 억지로 글자를 출력하려다 경계를 조금만 틀려도 오류가 납니다. 반면 CTC는 확신이 생기는 순간에만 날카로운 스파이크(spike) 를 뱉고, 나머지는 깔끔하게 blank로 채웁니다.
내가 이해한 포인트
CTC 출력 그래프를 보면 'dcl'과 'd'처럼 항상 붙어 다니는 음소들이 이중 스파이크(double spike) 로 묶여서 예측됩니다. AI가 스스로 "얘네는 세트야"라는 언어적 패턴을 수작업 없이 학습했다는 증거입니다. Framewise 결과를 쓰려면 후처리가 필요하지만, CTC 결과는 스파이크만 읽으면 바로 정답이 됩니다.
📊 Figure 2 — Prefix Search Decoding 트리
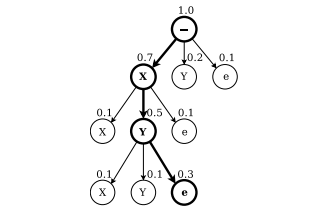
- 이 그림이 보여주는 것: 알파벳 X, Y로 구성된 라벨 공간에서 가장 확률 높은 정답을 찾아가는 트리 탐색 과정. 각 노드 위의 숫자는 해당 접두어(prefix)로 시작하는 모든 정답의 총 확률입니다.
- 핵심 메시지: 가장 확률 높은 prefix를 우선적으로 확장해 나가다가, 단일 정답 'XY'가 나머지 모든 prefix보다 확률이 높아지는 순간 탐색을 멈춥니다.
내가 이해한 포인트
이 방식은 '최선의 경로 하나만 보기(Best Path Decoding)'보다 항상 더 정확한 정답을 찾아냅니다. 단, CTC 출력이 충분히 뾰족하게(peaked) 학습되어야 탐색 시간이 폭발하지 않습니다. 논문에서 blank 확률 99.99% 이상인 지점을 경계로 나눠 각 구간을 독립적으로 탐색하는 휴리스틱을 추가한 이유가 여기 있습니다.
📊 Figure 3 — Forward-Backward 알고리즘: 'CAT' 예시
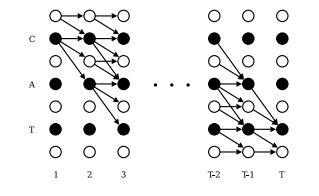
- 이 그림이 보여주는 것: 정답 'CAT'을 학습할 때, 가능한 모든 경로의 확률을 효율적으로 계산하는 동적 프로그래밍 다이어그램. 검은 원은 실제 글자(C, A, T), 흰 원은 blank를 나타냅니다. 화살표는 허용된 전이(transition) 방향을 표시합니다.
- 핵심 메시지: 앞에서 뒤로(Forward) 변수와 뒤에서 앞으로(Backward) 변수를 재귀적으로 계산합니다. 오른쪽 상단의 연결되지 않은 흰 원들은 "남은 시간이 부족해 도달할 수 없는 경로"를 나타냅니다.
내가 이해한 포인트
수백 개가 넘는 경로를 하나씩 다 계산하면 컴퓨터가 죽습니다. Forward-Backward 알고리즘은 이 계산을 HMM에서 쓰던 방식과 유사하게 재귀식으로 분해해서, 결국 선형 시간(Linear Time) 만에 풀어냅니다. 이 알고리즘적 우아함이 CTC를 실용적으로 만든 핵심입니다.
📊 Figure 4 — CTC 오차 신호의 학습 단계별 진화
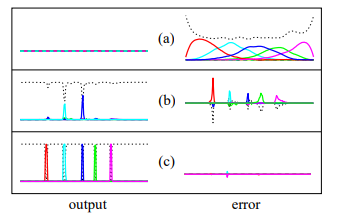
- 이 그림이 보여주는 것: 동일한 음성 시퀀스에 대해 학습 단계별 출력 활성화(왼쪽 열)와 그에 대응하는 오차 신호(오른쪽 열)를 3단계 (a), (b), (c)로 비교한 그래프. 점선은 blank 유닛의 확률을 나타냅니다.
- 핵심 메시지: (a) 초기에는 랜덤 가중치로 오차가 정답 라벨에만 의존합니다. (b) 학습이 진행되면 예측 주변으로 오차가 집중되기 시작합니다. (c) 충분히 학습된 뒤에는 올바른 글자를 강하게 확신하며 오차가 거의 사라집니다.
내가 이해한 포인트
(c) 단계에서 오차 신호가 거의 사라진다는 것은 "모델이 이미 정답을 확신하고 있어서 더 고칠 게 없다"는 뜻입니다. 학습 초반에 헤매다가 패턴을 깨닫는 순간 성적이 수직 상승하는 이유가 이 그림에 고스란히 담겨 있습니다.
5. Experiments & Results
저자들은 새로운 방법(CTC)이 기존 방법보다 성능이 뛰어난지 확인하기 위해 치밀한 실험을 설계했습니다.
| 실험 항목 | 내용 |
|---|---|
| 데이터셋 | TIMIT (영어 음성 코퍼스 — 4,620개 훈련 / 1,680개 테스트 발화) |
| 음소 분류 수 | 61개 음소 + blank 1개 = 총 62개 출력 |
| 신경망 구조 | BLSTM (양방향 Long Short-Term Memory, 파라미터 114,662개) |
| 평가 지표 | LER (Label Error Rate) — 정답과 비교해서 삽입/삭제/교체된 글자 비율 |
결과 요약 (Table 1 기준)
| 시스템 | LER (낮을수록 우수) |
|---|---|
| Context-independent HMM | 38.85% |
| Context-dependent HMM | 35.21% |
| BLSTM/HMM (Hybrid) | 33.84% |
| Weighted error BLSTM/HMM | 31.57% |
| CTC (Best Path) | 31.47% |
| CTC (Prefix Search) | 30.51% ✅ |
결과 해석
CTC(Prefix Search)는 사전 분절 작업이 전혀 없었음에도 불구하고, 가장 복잡한 Hybrid 시스템을 누르고 최저 오답률 30.51% 로 1위를 달성했습니다. 하이브리드 시스템은 가중치 오차 보정(heuristics)을 써야 겨우 비슷해졌지만, CTC는 그런 꼼수 없이 순수하게 이겼습니다.
6. Discussion
✅ 이 방법의 장점
- 노동 해방 — 사람이 직접 데이터를 분절하던 고된 사전 작업을 완전히 없앴습니다.
- End-to-End 학습 — 소리 → 글자 변환 전 과정을 단일 신경망 하나로 처리합니다.
- 새로운 시대 개막 — 소리, 영상, 필기 등 연속 데이터를 다루는 모든 AI 연구의 기본 공식이 되었습니다.
❌ 한계점 및 트레이드오프
- 문법 지식 부족 (독립성 가정) — 매 타임스텝의 출력이 서로 독립적으로 계산됩니다. '가' 다음에 '나'가 올 확률이 높다는 언어적 문맥을 깊게 학습하지 못합니다. 별도의 언어 모델(Language Model)이 꼭 필요합니다.
- 너무 뾰족한 예측 — 글자를 뱉을 때 100% 확신하고 나머지는 모두 blank로 확신하는 극단적 패턴이 생깁니다. 다른 모듈과 조합할 때 조화롭게 어울리기 어렵습니다.
- 실시간 처리의 한계 — 논문의 BLSTM 구조는 미래 문맥까지 보는 양방향(Bidirectional) 구조입니다. 발화가 끝날 때까지 기다려야 해서 유튜브 자동 자막처럼 즉각 반응하는 실시간 서비스에는 당장 적용이 어렵습니다.
💡 개선 가능한 방향
저자들이 논문에서 직접 제안한 3가지 방향입니다.
- Attention 모델과 결합 — 소리 타이밍은 CTC가, 문장의 매끄러움은 Attention이 담당하도록 역할을 나눕니다.
- 단어 단위 학습 — 알파벳 하나씩 예측하지 말고 'Apple', 'Banana' 같은 단어 자체를 예측하게 만들어 오타를 줄입니다.
- 단방향 구조로 개조 — 미래의 소리를 보지 않는 단방향(Unidirectional) 구조로 바꾸면, 정확도를 조금 희생하는 대신 스마트폰 음성 비서처럼 즉시 대답하는 서비스가 가능해집니다.
7. My Insights
새롭게 알게 된 점
AI 연구에서 '빈칸(blank)'이라는 단 하나의 기호를 추가하는 것이 얼마나 혁명적인 변화를 가져오는지 깨달았습니다. 수학적으로 풀리지 않던 길이 불일치(Misalignment) 문제가, 빈칸 기호 하나로 인해 경우의 수를 합산할 수 있는 구조로 바뀌었습니다.
기존 생각이 바뀐 부분
"인공지능에게 더 많은 정보(시간표)를 줄수록 더 잘 배울 것이다"라고 생각했습니다.
하지만 CTC는 오히려 정보를 덜 줬더니(시간표 없이) 더 잘 배웠습니다. 제약을 없애자 모델이 스스로 최적의 패턴을 찾아낸 것입니다. 좋은 학습 설계란 '더 많은 정보를 주는 것'이 아니라 '올바른 자유를 주는 것'임을 배웠습니다.
어디에 응용할 수 있을까?
이 기법은 음성 인식을 넘어 필기 인식, 영상 자막, 단백질 서열 분석처럼 입력과 출력의 길이가 다를 수 있는 모든 분야에 직접 적용 가능합니다. 온디바이스 AI에서 경량 음성 인식 모델을 설계할 때, CTC를 기반으로 단방향 구조와 결합하면 실시간성과 정확도를 동시에 잡는 아키텍처를 설계해볼 수 있겠다고 생각했습니다.
8. Summary
| 항목 | 내용 |
|---|---|
| 핵심 문제 | 기존 RNN은 훈련하려면 사람이 직접 만든 시간별 정답 라벨(Forced Alignment)이 꼭 필요했음 |
| 해결 방법 | blank 기호 도입 + 정답이 되는 모든 경로의 확률을 합산하는 CTC Loss로 사전 분절 없이 학습 |
| 핵심 기여 | TIMIT 데이터셋에서 HMM 및 HMM-RNN 하이브리드를 꺾고 LER 30.51%로 SOTA 달성 |
| 가장 인상 깊었던 점 | 미분 불가능했던 '경로 선택' 문제를 Forward-Backward 동적 프로그래밍으로 우회한 수학적 우아함 |
| 아쉬운 점 | 매 타임스텝 독립 예측 가정으로 인해 언어 문맥 모델링이 약하고, 양방향 구조 탓에 실시간 처리가 어려움 |
| 확장 방향 | Attention 모델과의 결합(CTC+Attention), 단방향 경량화를 통한 온디바이스 실시간 음성 인식 |
🧠 이 논문을 한 문장으로 말하면?
CTC는 'blank'라는 기호 하나와 Forward-Backward 알고리즘으로, 사람이 만든 시간표 없이도 인공지능이 스스로 소리와 글자의 관계를 배울 수 있게 만든 End-to-End 음성 인식의 혁명적 기초다.
