[논문 리뷰] Listen, Attend and Spell (LAS) (https://arxiv.org/pdf/1508.01211)
발음 사전 없이 소리를 문자로 번역하는 종단간 음성 인식의 탄생
수천 프레임의 오디오를 피라미드로 압축하고, 어텐션으로 한 글자씩 집중해서 읽어내는
단일 신경망 하나로 전통적 음성 인식 파이프라인 전체를 대체한 혁명적 아키텍처.
ICLR 2016 | William Chan (CMU), Navdeep Jaitly, Quoc V. Le, Oriol Vinyals (Google Brain)
목차
- 서론
- Background
- Problem Definition
- Proposed Method / Approach
- Experiments & Results
- Discussion
- My Insights
- Summary
1. 서론
이 논문은 음성 인식 시스템이 '생각보다 훨씬 복잡한 사전 준비를 요구해왔다' 는 불편한 진실을 정면으로 파고든 연구입니다.
전통적인 음성 인식 시스템은 음향 모델, 발음 사전, 언어 모델 등 여러 독립된 모듈의 복잡한 결합체입니다. 각 모듈을 독립적으로 설계하고 훈련해야 하므로 고도의 전문 지식이 필요합니다. 새로운 언어나 환경에 적용할 때마다 번거로운 튜닝 과정을 거쳐야 합니다. 이러한 구조는 전체 시스템을 한 번에 최적화하는 데 방해가 됩니다.
이 논문은 이 모든 파이프라인을 Listen, Attend and Spell(LAS) 이라는 단일 딥러닝 아키텍처 하나로 통합합니다. 이 글을 끝까지 읽으시면, 어떻게 신경망 하나가 발음 사전도, HMM도 없이 오디오를 곧바로 문자로 바꿔내는지 그 직관적인 원리를 깨닫게 되실 겁니다.
2. Background
논문의 핵심으로 들어가기 전에, 왜 이런 연구가 필요했는지 배경지식을 가볍게 짚고 넘어가 봅시다.
음성 인식의 기존 흐름
| 세대 | 방식 | 특징 |
|---|---|---|
| GMM-HMM | 통계 기반 음향·언어 모델 결합 | 전문 지식 필수, 먼 문맥 기억 불가 |
| DNN-HMM | 딥러닝을 음향 모델에 적용 | HMM의 한계 그대로 상속, 파편화 훈련 |
| CTC 기반 | 분절 없이 종단간 학습 | 출력 간 조건부 독립 가정이 치명적 약점 |
| LAS (이 논문) | Seq2Seq + 어텐션 기반 종단간 | 조건부 독립 가정 폐기, 완전 통합 |
CTC의 한계와 LAS의 등장
직전 논문인 CTC는 수작업 분절 없이 학습한다는 혁신을 이뤄냈습니다. 하지만 결정적인 약점이 남아 있었습니다.
CTC의 치명적 가정: "이 프레임에서 'a'가 나올 확률은 이전에 'c', 'a', 't'가 나왔는지와 완전히 독립적이다."
이 가정 때문에 CTC는 언어 모델을 스스로 내재화하지 못했습니다. LAS는 이 가정을 완전히 폐기하여 다음 문자 예측이 이전 문자들에 의존하도록 설계했습니다.
또 다른 도전: 오디오의 압도적인 길이
기계 번역에서 성공한 Seq2Seq + 어텐션 구조를 음성에 바로 적용하면 문제가 생깁니다.
오디오 신호는 수백에서 수천 개의 프레임으로 이루어집니다. 디코더가 한 글자를 예측할 때마다 이 수천 개를 전부 훑어야 하므로 모델이 어디를 봐야 할지 길을 잃어 수렴하지 못합니다.
3. Problem Definition
이 논문이 꼬집는 핵심 문제는 "기존 파이프라인은 너무 파편화되어 있고, 통합하려면 새로운 구조적 돌파구가 필요하다" 는 것입니다.
기존 방식의 3가지 한계
| 문제 | 설명 |
|---|---|
| 파이프라인 파편화 | 음향·발음·언어 모델을 각각 별도 목표로 따로 훈련 → 최적화 오류 누적 |
| 조건부 독립의 한계 | CTC는 출력 문자들이 서로 독립적이라 가정 → 언어 문맥 자가 학습 불가 |
| 어텐션 연산 폭발 | 수천 프레임 오디오에 어텐션을 직접 적용하면 디코더가 수렴 실패 |
직관적 비유 🏢
회사 보고 체계로 비유해 봅시다.
- 기존 방식: 음향 분석팀, 발음 사전팀, 언어 교정팀이 따로 존재합니다. 각 팀이 순서대로 보고서를 넘기다 보니 오류가 누적되고 전체 최적화가 불가능합니다.
- LAS: 한 명의 만능 비서(단일 신경망)가 소리를 들으면서 동시에 문법도 챙기고 글자도 적어냅니다. 사장(정답)에게 단 하나의 보고서만 올라갑니다.
이 문제를 해결하면
오직 오디오-텍스트 쌍 데이터만 있으면 발음 사전도, HMM도, 별도 언어 모델도 없이 처음부터 끝까지(End-to-End) 단번에 학습이 가능해집니다.
4. Proposed Method / Approach
LAS는 Listen(듣기) → Attend(집중) → Spell(적기) 세 단계로 작동합니다.
전체 작동 흐름
- Listen — 피라미드형 양방향 LSTM(pBLSTM)이 긴 오디오를 압축된 고차원 벡터 시퀀스 로 변환합니다.
- Attend — 디코더(스펠러)가 현재 상태와 를 비교해 어느 시간대에 집중할지 가중치를 계산합니다.
- Spell — 집중 가중치로 만든 컨텍스트 벡터를 바탕으로 다음 문자의 확률 분포를 출력합니다.
Listen: 피라미드형 압축
기본 BLSTM vs pBLSTM
핵심 차이는 괄호 안입니다. 아랫층의 인접한 두 타임스텝을 하나로 합쳐 윗층에 넘깁니다. 층을 올라갈 때마다 길이가 절반씩 줄어듭니다.
| 층 | 프레임 수 |
|---|---|
| 입력 | 1,000개 |
| pBLSTM 1층 | 500개 |
| pBLSTM 2층 | 250개 |
| pBLSTM 3층 | 125개 (8배 압축) |
비유: 회사 보고 압축
평사원 8명의 보고서 → 대리 4명이 2장씩 묶어 요약 → 과장 2명이 재요약 → 부장 1명이 최종 1장으로 압축해 사장에게 전달. 사장이 검토해야 할 서류가 8배 줄어들었습니다.
논문 실험에서 pBLSTM 없이 일반 BLSTM만 사용하면 한 달을 학습해도 수렴하지 못했습니다. pBLSTM이 없으면 LAS 자체가 작동하지 않는다는 뜻입니다.
Attend & Spell: 집중과 받아쓰기
수식 이해하기
| 기호 | 의미 |
|---|---|
| 현재 디코더(스펠러)의 상태 | |
| 인코더(리스너)가 뽑아낸 번째 오디오 벡터 | |
| 와 사이의 유사도(궁합 점수) | |
| 0~1 사이로 정규화된 집중 가중치 | |
| 가중치에 따라 혼합된 최종 컨텍스트 벡터 | |
| 각각 디코더·인코더 상태를 변환하는 MLP |
비유: 동시통역사의 귀
통역사가 "사과"를 말해야 할 타이밍이 됩니다. 화자가 말한 수백 개의 단어 중 "Apple"이라는 소리 파형에만 귀를 쫑긋 세워 집중( 값이 높아짐)합니다. 나머지 소리는 흐릿하게 처리하고, 그 집중된 정보()를 바탕으로 "사과"를 받아적습니다.
계산 예시:
오디오가 3프레임()으로 압축되었습니다. 현재 상태()와 비교한 에너지가 [1, 5, 0]이라면, softmax를 거치면 대략 [0.01, 0.98, 0.01] 이 됩니다. 즉 2번째 오디오 프레임을 98% 활용해 컨텍스트 벡터를 만들어 다음 글자를 예측합니다.
학습의 핵심: Sampling Trick
학습 중에는 이전 스텝의 정답 문자를 다음 입력으로 씁니다. 하지만 실제 추론 때는 모델이 스스로 예측한 문자를 다음 입력으로 써야 합니다. 이 훈련-추론 간의 괴리가 오류를 증폭시킵니다.
저자들은 이를 해결하기 위해 10% 확률로 이전 정답 대신 모델 예측값을 입력하는 Sampling Trick을 도입했습니다. 이 트릭 하나로 WER이 16.2% → 14.1% 로 떨어졌습니다.
📊 Figure 1 — LAS 전체 아키텍처 다이어그램
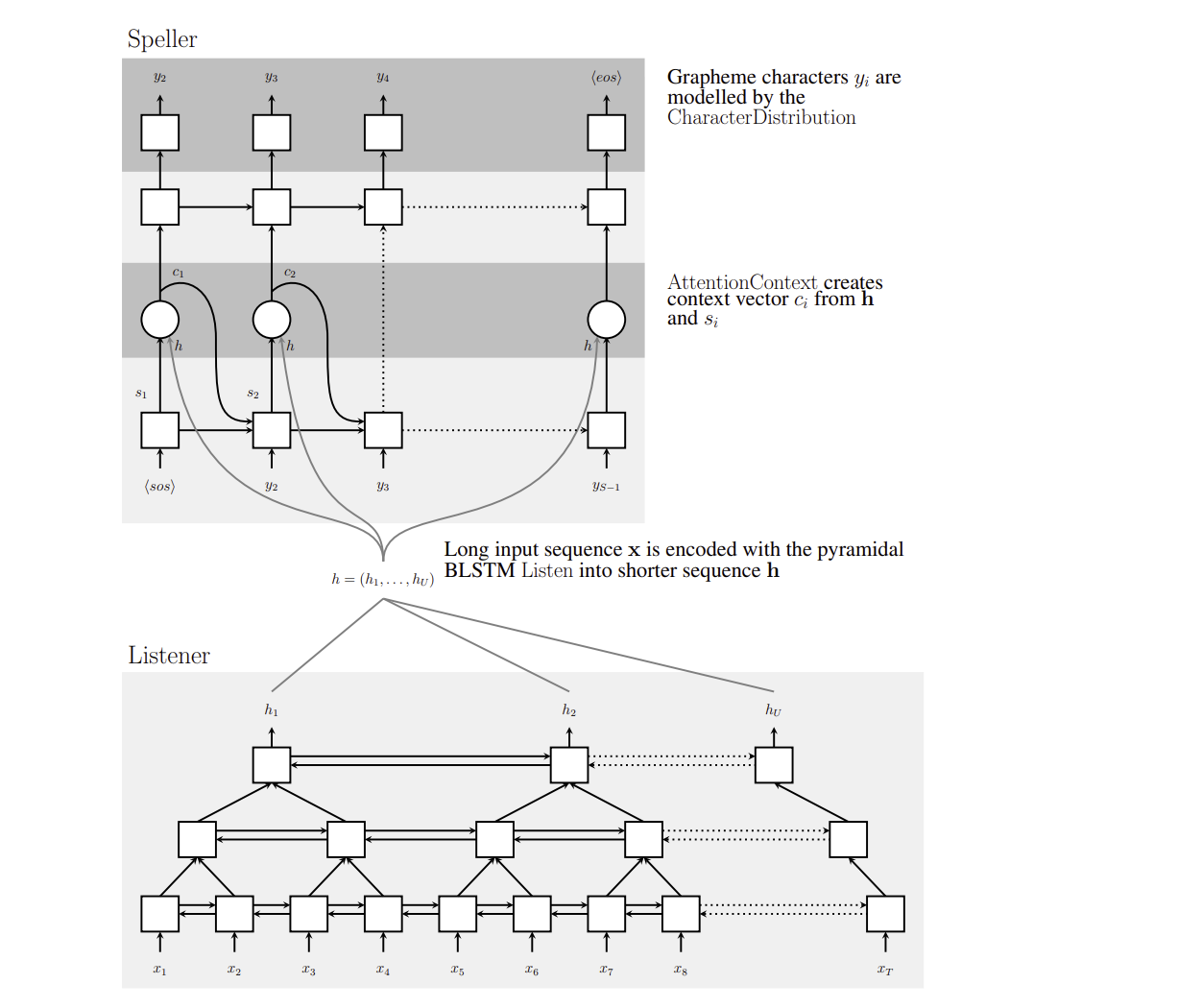
- 이 그림이 보여주는 것: 왼쪽의 리스너(피라미드 BLSTM)가 긴 입력 를 짧은 로 압축하는 과정과, 오른쪽의 스펠러(어텐션 기반 디코더)가 를 참조해 문자 를 하나씩 출력하는 전체 흐름. pBLSTM이 층을 올라갈수록 타임스텝이 줄어드는 피라미드 형태가 시각적으로 표현되어 있습니다.
- 핵심 메시지: 리스너와 스펠러가 완전히 분리된 두 모듈이 아니라, 어텐션 컨텍스트 벡터 를 통해 매 문자 출력 때마다 긴밀하게 연결되어 함께 작동하는 구조입니다.
내가 이해한 포인트
그림을 보면 스펠러가 문자를 하나 출력할 때마다 전체에 어텐션을 다시 계산합니다. 즉 "A"를 쓸 때와 "p"를 쓸 때 집중하는 오디오 구간이 매번 달라집니다. 이것이 CTC와 결정적으로 다른 점이며, 언어 문맥을 스스로 학습하는 원동력입니다.
📊 Figure 2 — 어텐션 정렬 시각화
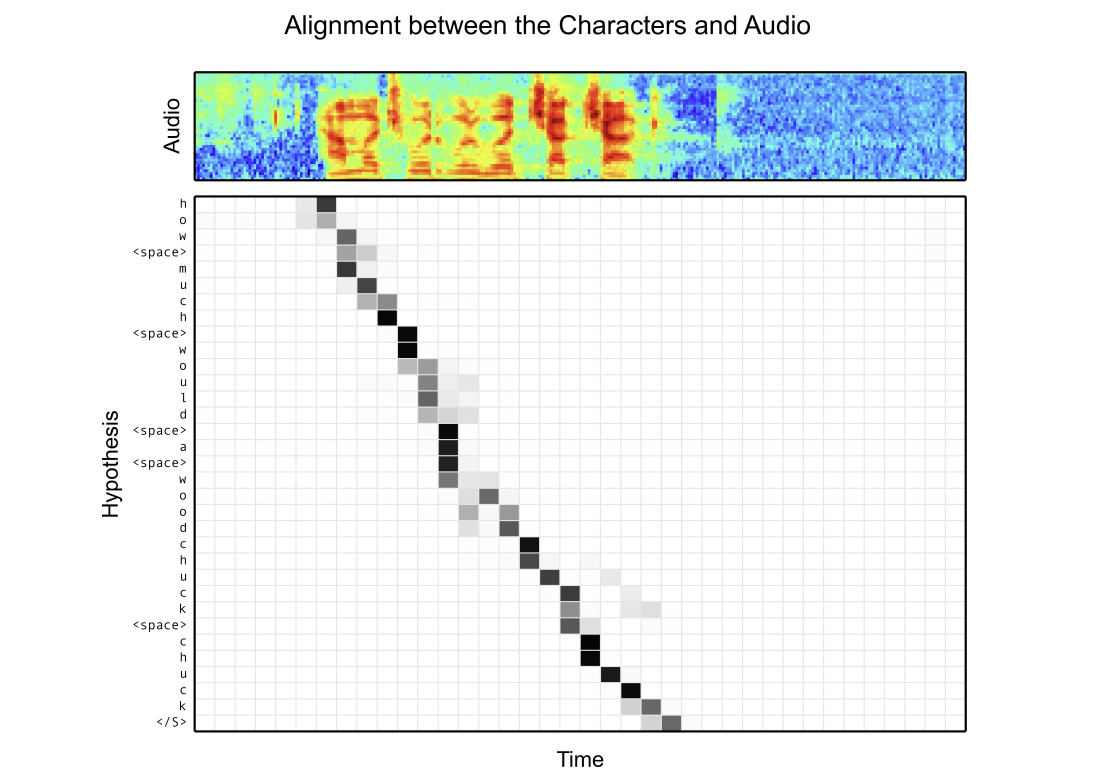
- 이 그림이 보여주는 것: "how much would a woodchuck chuck"라는 발화에 대해, 가로축은 오디오 필터뱅크 타임스텝, 세로축은 출력 문자 순서를 나타내는 히트맵. 밝은 색일수록 해당 오디오 구간에 강하게 집중했다는 뜻입니다.
- 핵심 메시지: 어텐션 정렬이 왼쪽 아래에서 오른쪽 위로 향하는 대각선(단조적) 패턴을 보입니다. 위치 기반 사전 정보(Location Prior) 없이도 모델이 스스로 순서대로 집중하는 법을 학습했습니다.
내가 이해한 포인트
"woodchuck"과 "chuck"는 발음이 유사해서 해당 구간에서 어텐션 분포가 살짝 흐릿해집니다. 논문이 정직하게 이 한계를 시각화로 공개한 점이 인상적입니다. 또한 발화의 시작점과 끝점도 정확히 찾아냈습니다. 위치 정보를 강제로 넣지 않아도 내용 기반 어텐션만으로 정렬이 된다는 사실이 경이롭습니다.
📊 Figure 3 — 빔 너비(Beam Width)에 따른 WER 변화
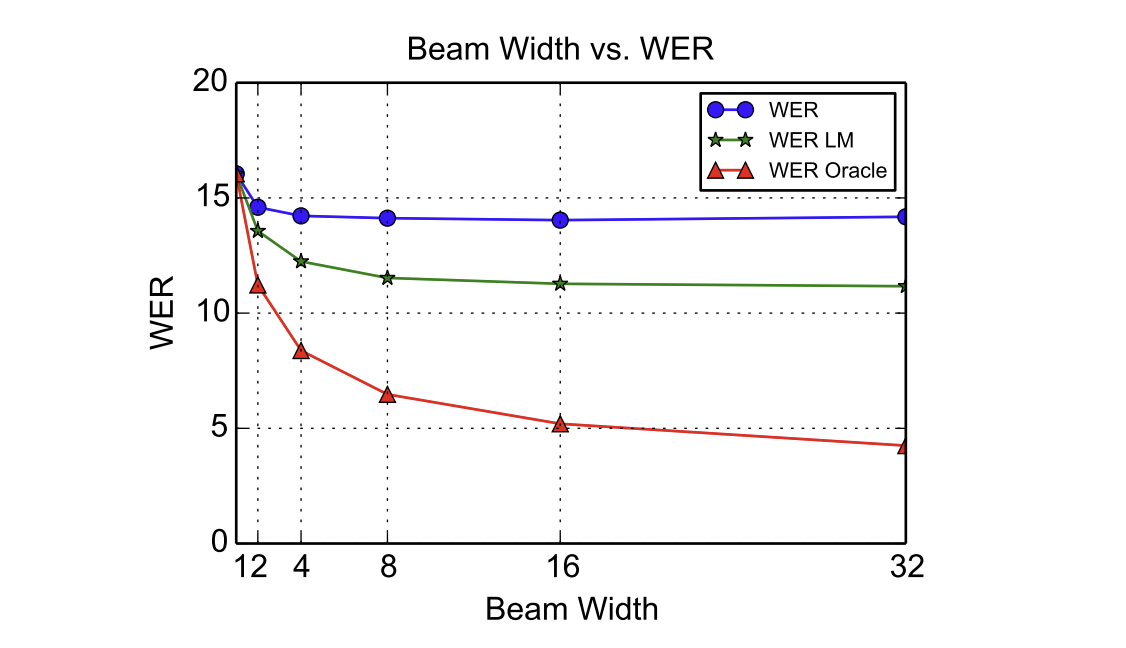
- 이 그림이 보여주는 것: X축은 빔 서치의 너비(), Y축은 WER(단어 오류율). 언어 모델 없는 경우(WER), 언어 모델 재채점 적용 경우(WER LM), 이론적 최상값(WER Oracle) 세 가지 곡선을 비교합니다.
- 핵심 메시지: 빔 너비가 1에서 16으로 커지는 구간에서 WER이 빠르게 개선됩니다. 16 이상에서는 추가 이득이 미미합니다. 빔 너비 32에서 WER 14.1%(LM 없음), 10.3%(LM 적용)를 달성했습니다.
내가 이해한 포인트
Oracle WER이 4.3%라는 것은 "모델이 이미 정답을 32개 후보 안에 담고 있다"는 의미입니다. 즉 모델 자체의 음향 학습 능력은 충분하며, 언어 모델을 더 정교하게 만들면 최종 성능 향상 여지가 크다는 것을 보여줍니다.
📊 Figure 4 — 발화 길이에 따른 오류 유형 분석
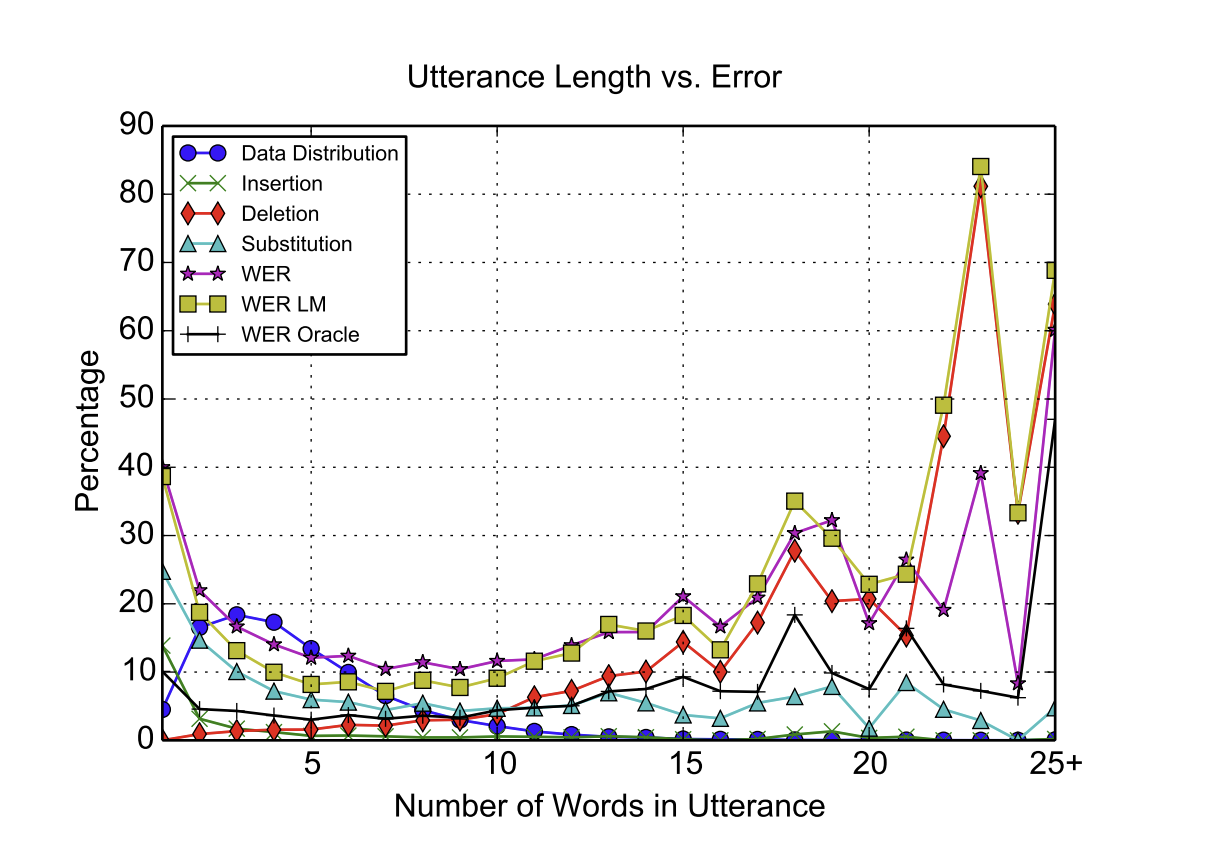
- 이 그림이 보여주는 것: X축은 발화 내 단어 수, Y축은 오류 비율(%). 삽입(Insertion), 삭제(Deletion), 교체(Substitution) 오류 유형을 분리하여 WER, WER LM, Oracle WER과 함께 표시합니다.
- 핵심 메시지: 짧은 발화(2단어 이하)에서는 삽입·교체 오류가 주된 문제이고, 긴 발화(10단어 이상)에서는 삭제 오류가 지배적입니다.
내가 이해한 포인트
짧은 발화에서의 오류는 "단어를 쪼개서 두 개로 인식하는" 문제에서 비롯됩니다. 긴 발화에서의 삭제 오류는 "훈련 데이터에 긴 발화가 적어 어텐션이 길을 잃는" 문제입니다. 이 그림 하나로 LAS가 어디에서 왜 실패하는지 명확하게 이해할 수 있습니다.
5. Experiments & Results
저자들은 LAS가 복잡한 기존 시스템 없이도 충분한 성능을 내는지 검증하기 위해 구글의 대규모 데이터셋으로 실험을 설계했습니다.
| 실험 항목 | 내용 |
|---|---|
| 데이터셋 | 구글 음성 검색 약 300만 발화 (약 2,000시간), 데이터 증강으로 20배 확장 |
| 음향 특징 | 40차원 log-mel 필터뱅크, 10ms 간격 추출 |
| 모델 구조 | 하단 BLSTM + pBLSTM 3층(각 512노드, 256/방향) + 스펠러 2층 LSTM(512노드) |
| 평가 지표 | WER(단어 오류율) — 대체·삽입·삭제 오류 단어 비율 |
| 비교 대상 | 당시 SOTA인 CLDNN-HMM 시스템(WER 8.0%) |
결과 요약 (Table 1 기준)
| 모델 | Clean WER | Noisy WER |
|---|---|---|
| CLDNN-HMM (SOTA) | 8.0% | 8.9% |
| LAS (기본) | 16.2% | 19.0% |
| LAS + LM Rescoring | 12.6% | 14.7% |
| LAS + Sampling | 14.1% | 16.5% |
| LAS + Sampling + LM Rescoring | 10.3% | 12.0% ✅ |
결과 해석
발음 사전도, HMM도, 외부 언어 모델도 없는 순수 LAS가 WER 14.1%를 달성했습니다. 언어 모델 재채점만 추가하면 10.3%로, 당시 SOTA(8.0%)와의 격차가 2.3%p 수준까지 좁혀졌습니다. 모든 복잡성을 제거했음에도 상용화 수준에 근접한 성능을 낸 것입니다.
6. Discussion
✅ 이 방법의 장점
- HMM 파이프라인 완전 제거 — 발음 사전, HMM, 별도 훈련 과정이 모두 사라졌습니다.
- OOV 문제 자동 해결 — 문자 단위로 출력하므로 사전에 없는 단어도 조합해서 표현할 수 있습니다.
- 암묵적 언어 모델 내재화 — 조건부 독립 가정 없이 이전 문자를 참조해 다음 문자를 예측합니다.
- 다양한 철자 표현 가능 — 빔 서치 결과에 "triple a"와 "aaa"가 동시에 생성되는 것처럼, CTC로는 불가능한 다양한 표현을 자연스럽게 만들어냅니다.
❌ 한계점 및 트레이드오프
- 실시간 처리 불가(Offline 모델) — pBLSTM이 양방향 구조이므로 발화가 끝날 때까지 기다려야 합니다. 유튜브 자동 자막처럼 말하는 도중 텍스트가 찍히는 서비스에 바로 쓸 수 없습니다.
- 천문학적 데이터 요구량 — 2,000시간 데이터 + 20배 증강 없이는 모델이 제대로 수렴하지 않습니다. 데이터가 적은 언어나 도메인에서는 적용이 어렵습니다.
- 긴 발화에서 어텐션 실패 — 훈련 데이터 분포보다 긴 발화가 들어오면 삭제 오류가 급증합니다.
- 결국 외부 언어 모델 필요 — "Fully End-to-End"를 강조하지만 최상위 성능(10.3%)은 외부 n-gram 언어 모델 재채점이 더해진 결과입니다.
💡 개선 가능한 방향
저자들이 논문에서 직접 제안하거나 이후 연구로 이어진 3가지 방향입니다.
- 온라인 스트리밍 적용 — pBLSTM을 단방향 구조로 바꾸고 Monotonic Attention을 결합해 실시간 처리를 가능하게 만듭니다. (이후 MoChA, RNN-T 연구로 발전)
- 다국어 범용 모델 — 유니코드 서브워드를 출력으로 확장하고 언어 ID 태그를 붙여 수십 개 언어를 하나의 LAS로 처리합니다.
- 비지도 사전학습 결합 — wav2vec 2.0처럼 정답 없는 오디오만으로 리스너를 먼저 학습시킨 뒤 LAS로 파인튜닝하면, 적은 데이터로도 높은 성능을 낼 수 있습니다.
7. My Insights
새롭게 알게 된 점
"모델에 더 많은 정보(발음 사전, HMM 상태)를 줄수록 더 잘 배울 것이다"라고 생각했습니다.
하지만 LAS는 오히려 정보를 덜 줬더니 더 잘 배웠습니다. 발음 사전을 주입하는 사전학습을 시도했지만 오히려 성능이 올라가지 않았다고 논문이 직접 밝힙니다. 좋은 학습 설계란 '더 많은 규칙을 주입하는 것'이 아니라 '올바른 구조와 자유를 주는 것'임을 배웠습니다.
기존 생각이 바뀐 부분
피라미드 구조(pBLSTM)가 단순히 "연산량 줄이기"로만 보였습니다. 하지만 논문은 이것이 없으면 한 달을 학습해도 수렴하지 않는다는 극단적 사실을 실험으로 증명했습니다. 구조적 설계 하나가 학습 가능성 자체를 결정한다는 점이 강렬하게 남았습니다.
어디에 응용할 수 있을까?
스마트 홈 기기처럼 메모리가 제한된 온디바이스 환경에서 LAS를 경량화하려면 pBLSTM을 단방향 피라미드 LSTM으로 교체하고, 어텐션을 Local Window 방식으로 제한하면 실시간 음성 인식이 가능한 구조가 만들어질 것 같습니다. 2,000시간이 아닌 적은 데이터로도 작동하게 하려면 wav2vec 같은 자기지도 사전학습과 결합하는 방향이 현실적으로 보입니다.
8. Summary
| 항목 | 내용 |
|---|---|
| 핵심 문제 | 전통적 음성 인식은 파이프라인이 파편화되어 전체 최적화가 불가능하고, CTC는 조건부 독립 가정이 치명적 약점 |
| 해결 방법 | pBLSTM으로 오디오를 8배 압축 + 어텐션으로 문자별 집중 구간 학습 = 단일 Seq2Seq 종단간 모델 |
| 핵심 기여 | 발음 사전·HMM 없이 WER 14.1%, LM 재채점 추가 시 10.3% — SOTA(8.0%)와 2.3%p 차이 |
| 가장 인상 깊었던 점 | pBLSTM 없이 한 달 학습해도 수렴하지 못한다는 실험 결과 — 구조적 설계가 학습 가능성 자체를 결정함 |
| 아쉬운 점 | 양방향 pBLSTM으로 인한 실시간 처리 불가, 최상위 성능에는 결국 외부 언어 모델이 필요 |
| 확장 방향 | 단방향 경량화 + Monotonic Attention으로 온디바이스 실시간 처리, wav2vec 결합으로 저자원 언어 대응 |
🧠 이 논문을 한 문장으로 말하면?
LAS는 피라미드형 압축(Listen)과 집중 메커니즘(Attend)으로 수천 프레임의 오디오를 다루는 장벽을 넘어, 발음 사전도 HMM도 없이 오디오를 문자로 직접 받아쓰는 End-to-End 음성 인식 시대를 연 혁명적 아키텍처다.
