[논문 리뷰] Monotonic Chunkwise Attention (MoChA)
Monotonic Chunkwise Attention (MoChA) (https://arxiv.org/pdf/1712.05382)
실시간으로 달리면서 방금 지나온 길을 되돌아보는 어텐션 메커니즘
미래를 컨닝하지 않고 왼쪽에서 오른쪽으로만 진행하면서,
멈춘 순간 바로 직전 2~8개를 묶어 소프트 어텐션으로 훑어보는 실시간 어텐션의 혁신.
ICLR 2018 | Chung-Cheng Chiu, Colin Raffel (Google Brain)
목차
- 서론
- Background
- Problem Definition
- Proposed Method / Approach
- Experiments & Results
- Discussion
- My Insights
- Summary
1. 서론
이 논문은 어텐션 메커니즘이 가진 오랜 딜레마를 정면으로 파고듭니다.
"정확하려면 전체를 봐야 하고, 실시간이려면 하나만 봐야 한다."
기존의 소프트 어텐션은 입력 전체를 다 읽어야만 결과를 냅니다. 동시통역이나 실시간 자막처럼 즉각 반응해야 하는 서비스에 쓸 수 없습니다. 반면 실시간 처리를 위해 만들어진 단방향 어텐션(Hard Monotonic Attention)은 딱 하나의 프레임만 보기 때문에 앞뒤 문맥을 놓쳐 정확도가 크게 떨어졌습니다.
이 논문은 단방향으로 진행하되, 멈춘 순간 직전 2~8개를 한 묶음으로 묶어 소프트 어텐션을 추가로 수행하는 MoChA(Monotonic Chunkwise Attention)를 제안합니다. 이 글을 끝까지 읽으시면, 왜 '방금 지나온 짧은 구간'을 되돌아보는 것만으로도 전체를 다 읽는 효과를 낼 수 있는지 직관적으로 이해하게 되실 겁니다.
2. Background
논문의 핵심으로 들어가기 전에, 어텐션 메커니즘의 진화 흐름을 먼저 살펴봅니다.
어텐션 메커니즘의 3가지 세대
| 방식 | 설명 | 장점 | 치명적 한계 |
|---|---|---|---|
| 소프트 어텐션 | 매 출력 시각마다 입력 전체를 참조 | 정확도 최고 | 이차 복잡도, 실시간 불가 |
| 하드 단조 어텐션 | 왼→오 스캔, 한 지점에서 멈춰 딱 하나만 참조 | 실시간 + 선형 복잡도 | 단 하나의 프레임만 참조 → 정확도 하락 |
| MoChA (이 논문) | 왼→오 스캔, 멈춘 지점 기준으로 직전 W개를 소프트 어텐션 | 실시간 + 문맥 파악 | 묶음 크기 W가 고정됨 |
소프트 어텐션의 이차 비용 문제
소프트 어텐션의 비용은 입력 길이 와 출력 길이 의 곱인 입니다.
입력 1,000프레임, 출력 100글자인 경우: 10만 번의 계산이 필요합니다. 입력이 2배 길어지면 계산량은 4배가 됩니다. 매우 긴 문서 요약 같은 작업에서는 컴퓨터가 뻗어버릴 수 있습니다.
반면 하드 단조 어텐션은 선형 복잡도로 이 문제를 해결했습니다. 하지만 딱 하나의 프레임만 보는 제약이 정확도를 크게 낮췄습니다. (WSJ 음성 인식 기준 WER 17.4% vs 소프트 어텐션 14.2%)
3. Problem Definition
이 논문이 꼬집는 핵심 문제는 하나입니다.
"하드 단조 어텐션은 실시간성은 얻었지만, 단일 프레임 참조와 엄격한 단조 정렬이라는 두 가지 제약이 소프트 어텐션과의 성능 격차를 만든다."
두 가지 제약의 한계
| 제약 | 문제 | 예시 |
|---|---|---|
| 단일 프레임 참조 | 한 소리 프레임만으로는 발음의 의미를 알 수 없음 | "학"이라는 소리 하나만 듣고 "학교"인지 "학생"인지 맞혀야 함 |
| 엄격한 단조 정렬 | 어순이 뒤바뀌는 번역 등 비단조 태스크에서 성능 폭락 | 문서 요약에서 Hard Monotonic은 ROUGE-1이 8점 가까이 하락 |
직관적 비유 🏀
농구 중계 해설자를 생각해 봅시다.
- 소프트 어텐션: 경기 전체 영상을 다 돌려본 뒤 해설합니다. 정확하지만 실시간이 아닙니다.
- 하드 단조 어텐션: 경기를 보다가 "지금 이 장면!"에서 딱 멈추고 그 순간 사진 한 장만 보고 해설합니다. 빠르지만 맥락이 없습니다.
- MoChA: "지금 이 장면!"에서 멈추되, 방금 전 2~3초의 짧은 리플레이를 같이 보고 해설합니다. 빠르면서도 맥락이 살아 있습니다.
4. Proposed Method / Approach
MoChA는 두 개의 독립적인 어텐션 함수를 결합합니다.
전체 작동 흐름 (테스트 시)
- 탐색 및 정지 — MonotonicEnergy로 왼→오 스캔하다 인 지점 에서 멈춥니다.
- 묶음 경계 설정 — 멈춘 위치 기준으로 직전 개를 하나의 청크로 묶습니다.
- 청크 내 소프트 어텐션 — ChunkEnergy로 청크 내 각 프레임의 중요도를 계산합니다.
- 문맥 벡터 생성 — 중요도 가중 평균으로 컨텍스트 벡터 를 만들어 디코더에 넘깁니다.
두 가지 독립된 에너지 함수
| 함수 | 역할 | 결과 |
|---|---|---|
| MonotonicEnergy | 여기서 멈출지 결정 | : 멈출 확률 (0~1) |
| ChunkEnergy | 청크 안에서 어디가 중요한지 판단 | : 소프트 어텐션 에너지 |
파라미터 증가가 고작 1%!
ChunkEnergy 함수를 추가하는 것이 전체 모델 파라미터를 약 1%만 늘립니다. 아주 작은 비용으로 큰 성능 향상을 얻은 것입니다.
w=1이면 하드 단조 어텐션과 동일
로 설정하면 직전 프레임 하나만 묶어보므로 MoChA가 하드 단조 어텐션으로 환원됩니다. MoChA는 하드 단조 어텐션의 완전한 일반화(Generalization)입니다.
직관적 예시 4가지 💡
| 비유 | 상황 | MoChA의 동작 |
|---|---|---|
| 스마트폰 자동완성 | '안녕ㅎ'까지 쳤을 때 | 멈추는 순간 '안', '녕', 'ㅎ' 3글자를 묶어 "안녕하세요" 추천 |
| 스포츠 비디오 판독 | 반칙 의심 순간에 영상 정지 | 정지 화면 직전 2~3초 리플레이를 묶어서 함께 검토 |
| 회전 초밥집 | 원하는 초밥이 지나갈 때 | 그 접시 하나만 집는 게 아니라 바로 앞 2~3개 접시를 세트로 집음 |
| 손전등 탐독 | 중요한 단어에서 멈춤 | 멈춘 순간 손전등 불빛을 살짝 넓혀 방금 읽은 앞 단어들도 같이 비춤 |
수식 이해하기
핵심 수식: 데이터 의 최종 관심도
직관적 설명 먼저 — 오디션 합격 확률 비유:
오디션 참가자 가 최종 합격할 확률은 두 가지가 동시에 일어나야 합니다. 심사위원이 근처 위치 에서 탐색을 멈춰야 하고(), 그 묶음 안에서 가 다른 참가자보다 눈에 띄어야 합니다(). 이 두 확률을 곱하고, 멈출 수 있는 모든 위치 에 대해 더합니다.
| 기호 | 의미 |
|---|---|
| 데이터 가 받는 최종 관심도 (학습 시 사용) | |
| 한 번에 살펴보는 청크 크기 | |
| 단조 어텐션이 멈춘 위치 | |
| 정확히 에서 멈출 확률 | |
| 청크 안에서 가 차지하는 비중 |
이 수식이 필요한 이유:
테스트 시에는 확률이 0.5 이상인 지점에서 딱 멈추면 됩니다. 하지만 학습 시에는 "멈추는 행동"이 불연속적이라 미분이 불가능합니다. 는 "평균적으로 를 얼마나 보게 되는가"라는 기댓값을 연속 확률로 표현해서 역전파(Backpropagation)가 가능하게 만듭니다.
MovingSum을 활용한 효율적 계산
중첩 합산( 안에 )은 계산 비용이 매우 높습니다. 논문은 이를 이동 합산(MovingSum) 을 이용한 병렬 계산으로 해결합니다.
이는 길이 의 1 시퀀스와의 컨볼루션으로 구현됩니다. 중첩 반복문 없이 GPU에서 병렬로 계산할 수 있습니다.
📊 Figure 1 — 세 가지 어텐션 메커니즘 비교 다이어그램
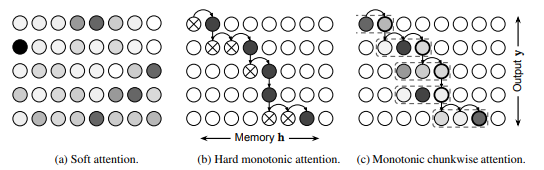
- 이 그림이 보여주는 것: 가로축은 메모리(인코더 은닉 상태), 세로축은 출력 타임스텝. 각 노드가 해당 메모리 위치를 해당 출력 시각에 참조할 가능성을 나타냅니다. (a) 소프트 어텐션 — 모든 노드에 회색 음영으로 확률 할당. (b) 하드 단조 어텐션 — 선택된 노드(검은 점)와 건너뛴 노드(×)로 표시. (c) MoChA — 굵은 테두리의 멈춤 지점과 점선으로 표시된 청크 경계, 청크 내 소프트 어텐션 음영.
- 핵심 메시지: MoChA의 청크 경계(점선)가 멈춤 위치에 따라 유동적으로 이동합니다. 청크 크기 이면 멈춘 위치 기준으로 직전 3개를 묶습니다.
내가 이해한 포인트
세 그림을 나란히 보면 MoChA가 (b)의 확장임이 명확하게 보입니다. (b)에서 검은 점 하나만 참조하던 것을, (c)에서 그 점을 포함한 직전 개 영역으로 넓혔습니다. 구조 변경은 최소인데 정보 활용은 배 늘었습니다.
📊 Figure 2 — 음성 인식 어텐션 정렬 시각화
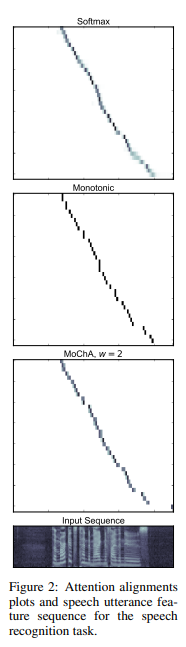
- 이 그림이 보여주는 것: WSJ 데이터셋의 실제 음성 발화에 대해 소프트 어텐션(Softmax), 단조 어텐션(Monotonic), MoChA() 세 가지의 정렬 히트맵. 가로축은 입력 오디오 특징 시퀀스, 세로축은 출력 문자.
- 핵심 메시지: 세 가지 어텐션 모두 왼쪽 아래에서 오른쪽 위로 향하는 대각선(단조적) 패턴이 유사하게 나타납니다. MoChA()도 소프트 어텐션과 거의 동일한 정렬을 학습했습니다.
내가 이해한 포인트
라는 아주 작은 청크 크기만으로도 소프트 어텐션과 시각적으로 거의 동일한 정렬이 만들어진다는 점이 놀랍습니다. 정렬 품질을 유지하는 데 긴 문맥이 반드시 필요한 게 아니라, 직전 2개의 추가 정보만으로 충분하다는 것을 시각적으로 증명합니다.
5. Experiments & Results
저자들은 두 가지 매우 다른 태스크에서 MoChA를 검증했습니다. 하나는 단조 정렬이 자연스러운 음성 인식, 다른 하나는 비단조 정렬이 필요한 문서 요약입니다.
실험 설계
| 항목 | 음성 인식 | 문서 요약 |
|---|---|---|
| 데이터셋 | Wall Street Journal (WSJ) | CNN/Daily Mail |
| 평가 지표 | WER (낮을수록 우수) | ROUGE F-score (높을수록 우수) |
| 청크 크기 | 2, 3, 4, 6, 8 모두 유사 → 선택 | 이 최적 |
| 비교 기준 | 같은 하이퍼파라미터, 어텐션만 교체 | 같은 하이퍼파라미터, 어텐션만 교체 |
음성 인식 결과 (Table 1: WSJ 테스트셋 WER)
| 모델 | Best WER | Average WER |
|---|---|---|
| CTC 기반 [Raffel et al.] | 33.4% | — |
| 강화학습 [Luo et al.] | 27.0% | — |
| CTC [Wang et al.] | 22.7% | — |
| 하드 단조 어텐션 | 17.4% | — |
| Soft Attention (오프라인) | 14.2% | 14.6 ± 0.3% |
| MoChA, | 13.9% ✅ | 15.0 ± 0.6% |
문서 요약 결과 (Table 2: CNN/Daily Mail ROUGE F-score)
| 모델 | ROUGE-1 | ROUGE-2 |
|---|---|---|
| 소프트 어텐션 (오프라인) | 39.11 | 15.76 |
| MoChA, | 35.46 | 13.55 |
| 하드 단조 어텐션 | 31.14 | 11.16 |
결과 해석
음성 인식에서 MoChA()는 온라인 모델로는 최초로 오프라인 소프트 어텐션과 동등한 성능을 달성했습니다. SOTA 대비 20% 상대적 WER 개선입니다. 문서 요약에서는 단조 정렬이 없는 태스크임에도 하드 단조 어텐션과 소프트 어텐션 사이의 격차를 절반 이상 메웠습니다(ROUGE-1 기준 4.32점 회복).
6. Discussion
✅ 이 방법의 장점
- 정확도 격차 해소 — 온라인 모델 최초로 오프라인 소프트 어텐션과 동등한 성능을 증명했습니다.
- 미래 차단 — 왼→오 단방향 스캔을 유지하므로 미래 정보를 절대 참조하지 않습니다. 완벽한 실시간 서비스가 가능합니다.
- 최소한의 비용 — 파라미터 1% 증가, 런타임 복잡도는 상수 인자 만큼만 늘어납니다.
- 수학적 우아함 — 불연속 멈춤 결정을 라는 기댓값 공식으로 변환해 표준 역전파 학습이 가능합니다.
- 비단조 태스크에도 유효 — 문서 요약처럼 정렬이 뒤바뀌는 태스크에서도 하드 단조 어텐션 대비 큰 개선을 보였습니다.
❌ 한계점 및 트레이드오프
- 고정된 청크 크기 — 말의 속도나 언어 특성에 맞춰 를 유동적으로 바꾸지 못합니다. 논문 저자 스스로 "향후 를 적응적으로 변화시키는 연구가 필요하다"고 언급했습니다.
- 학습 시 비선형 비용 — 테스트 시에는 빠르지만, 학습 시 계산에 MovingSum 연산이 추가되어 메모리와 연산량이 더 필요합니다.
- 미래 정보 완전 포기 — 개의 과거 프레임만 보기 때문에, 아주 조금의 Look-ahead(미래 엿보기)가 허용되는 환경에서는 성능을 더 끌어올릴 여지가 있습니다.
- 분산이 약간 높음 — 8회 반복 실험에서 MoChA의 평균 WER(15.0 ± 0.6%)이 소프트 어텐션(14.6 ± 0.3%)보다 분산이 컸습니다. 재현성이 약간 불안정합니다.
💡 개선 가능한 방향
- Dynamic MoChA — 상황에 따라 컴퓨터가 청크 크기를 스스로 조절하게 만듭니다. 말이 빠를 때는 작게, 느릴 때는 크게 유동적으로 변합니다.
- Look-ahead MoChA — 0.1초처럼 사용자가 불편하지 않을 아주 짧은 지연만 허용하고 미래 프레임 몇 개를 힌트로 씁니다. 정확도가 더 올라갑니다.
- Multi-Head MoChA — 짧은 청크()와 긴 청크()를 동시에 여러 헤드에 적용합니다. 짧은 음향 패턴과 긴 언어 문맥을 동시에 잡아냅니다.
7. My Insights
새롭게 알게 된 점
모델이 똑똑해지려면 더 넓은 시야가 필요하다고 생각했습니다. 하지만 MoChA는 직전 2개 프레임만 추가로 보는 것으로 오프라인 소프트 어텐션과 동등한 성능을 달성했습니다. 정보의 양보다 어떤 정보를 언제 참조하느냐가 더 중요하다는 것을 배웠습니다.
기존 생각이 바뀐 부분
불연속적인 결정(멈추거나/멈추지 않거나)은 미분이 불가능하니 학습 자체가 안 된다고 생각했습니다.
하지만 라는 기댓값 공식이 이 문제를 우회했습니다. "어디서 멈출지"라는 이진 결정을 "평균적으로 어디를 얼마나 볼 것인가"라는 연속 확률로 바꾸니 역전파가 가능해졌습니다. 불연속 문제를 기댓값으로 우회하는 수학적 트릭이 인상 깊었습니다.
어디에 응용할 수 있을까?
온디바이스 실시간 회의록 자동 생성 시나리오에서 MoChA가 실용적인 선택지가 될 것 같습니다. 특히 라는 작은 청크 크기가 소프트 어텐션과 동등한 성능을 낸다는 점은, 제한된 메모리의 스마트폰에서도 충분히 돌릴 수 있는 경량 설계의 가능성을 시사합니다. Dynamic MoChA를 결합해 말이 끊기는 구간에서는 를 줄여 지연을 최소화하는 방향이 흥미로울 것 같습니다.
8. Summary
| 항목 | 내용 |
|---|---|
| 핵심 문제 | 소프트 어텐션은 실시간 불가(), 하드 단조 어텐션은 단일 프레임 참조로 정확도 하락 |
| 해결 방법 | 단조 스캔으로 멈춤 위치 결정 + 직전 개 청크에 소프트 어텐션 추가 |
| 핵심 기여 | WSJ 음성 인식에서 온라인 모델 최초로 오프라인 소프트 어텐션과 동등한 WER 달성 (13.9% vs 14.2%) |
| 가장 인상 깊었던 점 | 불연속 결정을 기댓값 공식으로 변환해 역전파를 가능하게 만든 수학적 우아함 |
| 아쉬운 점 | 청크 크기 가 고정, MoChA 평균 WER의 분산이 소프트 어텐션보다 약간 높음 |
| 확장 방향 | Dynamic 적응, Look-ahead 허용, Multi-Head MoChA로 다중 해상도 문맥 포착 |
🧠 이 논문을 한 문장으로 말하면?
MoChA는 왼쪽에서 오른쪽으로만 달리면서 멈추는 순간 직전 2~8개를 되돌아보는 단 하나의 아이디어로, 실시간 온라인 모델 최초로 오프라인 소프트 어텐션의 정확도를 따라잡은 어텐션 메커니즘의 우아한 타협점이다.
