[논문 리뷰] Monotonic Finite Look-ahead Attention (MFLA)
Monotonic Finite Look-ahead Attention (MFLA) (https://arxiv.org/pdf/2506.03722)
Whisper를 실시간으로 — 과거는 무한히, 미래는 딱 k개만 엿보는 스트리밍 음성 인식
훈련과 실전의 괴리를 CIF + MFLA + Wait-k 세 가지 조합으로 해결하여,
Whisper를 그대로 파인튜닝해 실시간 스트리밍 음성 인식 시스템으로 변환한 prefix-to-prefix 프레임워크.
arXiv 2025 | Yinfeng Xia, Huiyan Li et al. (Honor Device Co., Ltd. / Shanghai Jiao Tong University)
목차
- 서론
- Background
- Problem Definition
- Proposed Method / Approach
- Experiments & Results
- Discussion
- My Insights
- Summary
1. 서론
이 논문은 아주 실용적인 질문에서 출발합니다.
"Whisper는 이미 뛰어난 음성 인식 모델인데, 왜 실시간 자막에 바로 쓸 수 없을까?"
Whisper는 대규모 약지도(Weakly Supervised) 사전학습으로 다국어 음성 인식에서 강력한 성능을 보여주는 모델입니다. 하지만 구조 자체가 발화가 끝날 때까지 기다려야 하는 오프라인 Seq2Seq 모델입니다. 실시간 자막이나 동시통역처럼 즉각적인 응답이 필요한 서비스에는 쓸 수 없습니다.
이 논문은 Whisper를 처음부터 다시 학습시키지 않고 LoRA 파인튜닝만으로 실시간 스트리밍 모델로 변환하는 방법을 제안합니다. 핵심은 세 가지 모듈의 조합입니다. CIF(연속 누적 발화 타이밍 감지), MFLA(무한 왼쪽 문맥 + 유한 오른쪽 문맥 어텐션), Wait-k 디코딩이 함께 작동하면서 실시간성과 정확도를 동시에 달성합니다.
2. Background
논문의 핵심으로 들어가기 전에, 왜 이런 연구가 필요한지 배경을 살펴봅니다.
Whisper의 강점과 치명적 한계
| 항목 | 내용 |
|---|---|
| 강점 | 68만 시간 약지도 학습, 다국어 지원, 높은 정확도 |
| 한계 | 발화 전체가 입력돼야 처리 시작 — 본질적으로 오프라인 모델 |
| 기존 시도 | Knowledge Distillation, Speculative Decoding → 속도 개선이지만 오프라인 구조 유지 |
스트리밍 음성 인식의 기존 접근법과 한계
| 방법 | 아이디어 | 한계 |
|---|---|---|
| 개선된 Wait-k 정책 | k개 청크가 들어올 때까지 기다린 후 고정 속도로 출력 | 말하기 속도 변화에 취약, 묵음 구간 처리 불안정 |
| Local Agreement | 연속된 두 청크의 최장 공통 접두사만 출력 | 높은 고정 지연 시간 |
| Simul-Whisper | 디코딩을 적절한 시점에 멈추고 불안정 구간 버림 | 복잡한 온라인 디코딩 파이프라인 |
공통 문제: 기존 방법들은 단편적(One-dimensional)입니다. 지연 시간과 품질 사이의 균형을 유연하게 조절하지 못합니다.
이 논문이 달라지는 지점
기존 Seq2Seq 패러다임(전체 입력 → 전체 출력)을 prefix-to-prefix 패러다임으로 바꿉니다.
prefix-to-prefix: 입력 접두사가 들어오면 그에 대응하는 출력 접두사를 즉시 냅니다. 훈련과 추론 조건이 일치하므로 성능 저하가 없습니다.
3. Problem Definition
이 논문이 꼬집는 핵심 문제는 "훈련과 실전의 불일치(Asynchronous Processing Problem)" 입니다.
훈련-추론 불일치
| 단계 | 조건 | 결과 |
|---|---|---|
| 훈련 시 | 전체 발화 소스를 다 보고 학습 | 완벽한 문맥 파악 |
| 실전 추론 시 | 현재까지 들어온 부분 소스만 사용 | 문맥 부족 → 성능 하락 |
이 불일치는 단순히 모델을 빠르게 만드는 것으로 해결되지 않습니다. 훈련 방식 자체를 실전처럼 바꿔야 합니다.
경계 불안정성 문제
고정 길이 청크로 오디오를 자르면 단어 경계가 청크 끝에 걸릴 수 있습니다. 예를 들어 "school"의 절반만 들어온 상태에서 글자를 출력해야 한다면 신뢰할 수 없는 결과가 나옵니다.
직관적 비유 🧩
퍼즐 조각이 1초에 하나씩 배달된다고 상상해 봅시다.
- 기존 방식: 모든 조각이 다 도착할 때까지 기다렸다가 퍼즐을 완성하고 "코끼리!"라고 외칩니다.
- MFLA 방식: 코끼리 코 모양이 얼추 완성됐을 때 멈추되, 방금 막 배달된 다음 조각 k개만 살짝 훔쳐보고 바로 "코끼리!"라고 외칩니다.
4. Proposed Method / Approach
Streaming-Whisper는 인코더(MoChA) + 예측기(CIF) + 디코더(MFLA) 세 모듈이 유기적으로 작동합니다.
전체 구조 개요
모듈 1: 인코더 — MoChA로 청크 단위 처리
Whisper 인코더의 기존 합성곱 레이어를 인과 합성곱(Causal Convolution) 으로 교체합니다. 미래 청크를 볼 수 없게 막습니다. 인코더 어텐션에는 MoChA를 적용해 현재 청크와 이전 청크들만 참조하도록 제한합니다.
| 설정 | 내용 |
|---|---|
| 청크 크기 | 훈련 시 균등 분포 에서 샘플링 |
| 오프라인(전체 어텐션)과 동일 — 오프라인을 온라인의 특수 케이스로 통일 |
모듈 2: 예측기(Predictor) — CIF로 토큰 경계 감지
CIF(Continuous Integrate-and-Fire)는 음성 프레임의 누적 가중치가 1을 넘는 순간 토큰 하나를 발화하는 메커니즘입니다.
직관: 물통 채우기 비유
빗방울(음성 프레임)이 조금씩 물통에 떨어집니다. 물통이 가득 차서 1리터 눈금을 넘는 순간 밸브가 열리며 물 한 컵(토큰 하나)이 출력됩니다.
| 기호 | 의미 |
|---|---|
| 프레임 의 토큰 가중치 (예측기 출력) | |
| 토큰 하나가 완성됐다는 신호 |
CIF는 세 가지 역할을 동시에 수행합니다. 훈련 시 MFLA의 오른쪽 문맥 윈도우를 가이드합니다. 추론 시 디코딩을 멈춰야 할 시점을 추적합니다. 반복 출력(Repetition) 문제를 방지합니다.
모듈 3: 디코더 — MFLA로 무한 왼쪽 + 유한 오른쪽
MFLA의 핵심 아이디어는 단순합니다.
왼쪽(과거): 제한 없이 전부 참조합니다.
오른쪽(미래): 딱 개 프레임까지만 참조합니다.
| 기호 | 의미 |
|---|---|
| 현재 시각 의 쿼리 | |
| 과거 전체 + 미래 개까지의 키 | |
| 과거 전체 + 미래 개까지의 값 |
직관: 밤길 헤드라이트 비유
백미러(과거)는 지나온 길 전체를 볼 수 있습니다. 하지만 앞길(미래)은 헤드라이트가 비추는 딱 미터 앞까지만 보입니다. 헤드라이트의 가시거리 를 조절해 안전(정확도)과 속도(지연) 사이의 균형을 맞춥니다.
| 값 | 지연 시간 | 정확도 |
|---|---|---|
| 매우 짧음 | 다소 낮음 | |
| 중간 | 높음 | |
| 오프라인 | 최고 (오프라인과 동일) |
Wait-k 디코딩 전략
훈련 시 MFLA로 개 미래 프레임을 보도록 학습했으므로, 추론 시에도 CIF 누적값이 를 초과할 때마다 토큰을 하나씩 출력하면 훈련-추론 조건이 일치합니다.
누적 가중치 α에 현재 프레임 가중치를 더함
α가 k를 초과하는 동안:
토큰 하나 출력
α에서 1 차감
다음 프레임으로 이동2단계 파인튜닝 전략
MFLA 생성이 예측기(CIF)에 의존하므로, 순서대로 학습시켜야 합니다.
| 단계 | 방식 | 목적 |
|---|---|---|
| 1단계 | 디코더에 Full Attention으로만 훈련 | 기본 언어 모델링 능력 확보 |
| 2단계 | Full Attention + Monotonic Attention 혼합 | 실시간 조건 적응 |
📊 Figure 1 — Streaming-Whisper 전체 구조
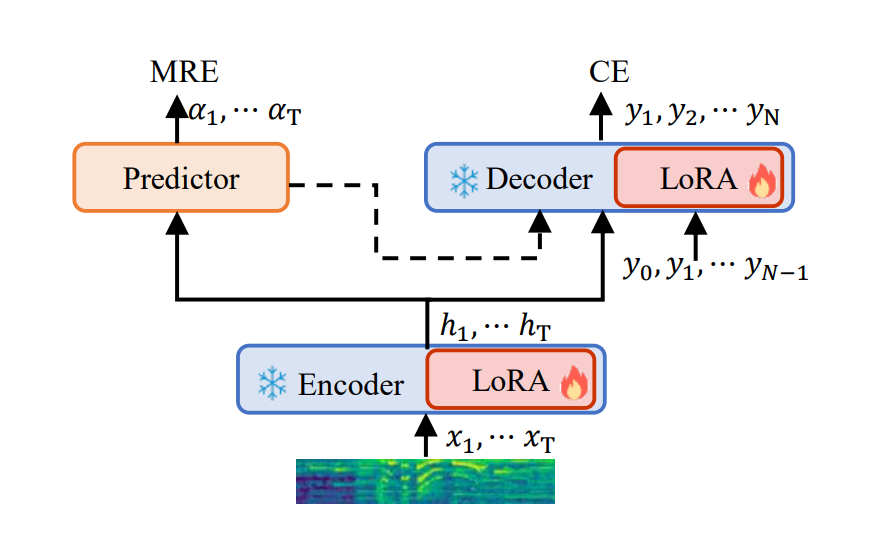
- 이 그림이 보여주는 것: 입력 음성 가 인코더(Encoder + LoRA)를 거쳐 은닉 상태 가 되고, 예측기(Predictor)가 토큰 가중치 를 출력합니다. 디코더(Decoder + LoRA)는 에 가이드된 MFLA로 출력 토큰 을 생성합니다. 손실 함수는 예측기의 MRE Loss와 디코더의 CE Loss 두 가지를 동시에 최적화합니다.
- 핵심 메시지: Whisper 원래 구조에 예측기 하나만 추가하고, 나머지는 LoRA로 파인튜닝합니다. 구조 변경을 최소화하면서 스트리밍을 가능하게 만든 효율적인 설계입니다.
내가 이해한 포인트
LoRA로 인코더와 디코더 파라미터를 동결하고 소수의 저랭크 행렬만 학습하므로, Whisper가 사전학습으로 쌓은 음성 지식을 그대로 보존하면서 스트리밍 능력만 추가로 주입합니다. 처음부터 학습하는 것과 달리 훈련 비용이 극적으로 줄어듭니다.
📊 Figure 2 — MoChA(인코더)와 MFLA(디코더) 어텐션 패턴 비교
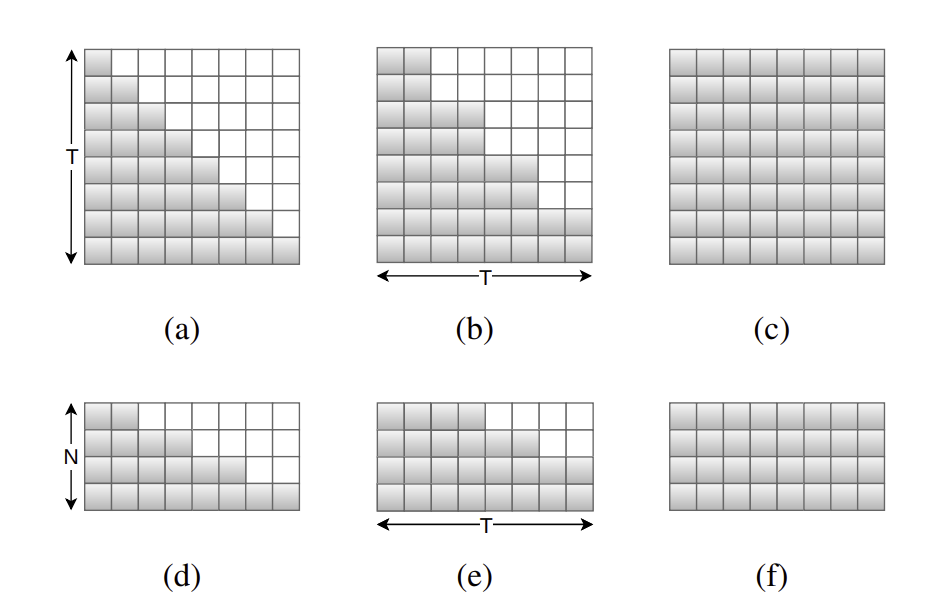
- 이 그림이 보여주는 것: (a)(b)는 인코더의 MoChA — 청크 크기 1과 2의 어텐션 마스크 패턴. (c)는 청크 크기 ∞인 오프라인 풀 어텐션. (d)(e)는 디코더의 MFLA — Look-ahead span 1과 2의 패턴. (f)는 Look-ahead ∞인 오프라인과 동일한 패턴.
- 핵심 메시지: 청크 크기/와 Look-ahead span/ 모두 로 설정하면 오프라인 풀 어텐션과 완전히 동일합니다. 즉 오프라인이 온라인의 특수 케이스로 통일됩니다. 하나의 모델로 오프라인과 온라인 디코딩을 모두 지원합니다.
내가 이해한 포인트
인코더(MoChA)와 디코더(MFLA)가 서로 다른 방향의 어텐션 제약을 담당합니다. 인코더는 청크 단위로 왼→오를 제한하고, 디코더는 무한 왼쪽 + 유한 오른쪽 개를 허용합니다. 두 모듈이 역할 분담해 전체 시스템의 인과성을 보장합니다.
5. Experiments & Results
저자들은 4가지 모델 크기 × 4개 언어 × 다수 데이터셋에서 체계적으로 검증했습니다.
실험 설정
| 항목 | 내용 |
|---|---|
| 데이터셋 | WenetSpeech4TTS(중국어), LibriSpeech(영어), MLS(독·스페인어), VoxPopuli(독·스페인·영어) |
| 모델 아키텍처 | Whisper Small / Medium / Large-V3 / Large-V3-Turbo |
| 지연 지표 | DAL (Differentiable Average Lagging) — 이상적 스트리밍 대비 평균 지연 |
| 비교 기준 | Local Agreement 정책 (Baseline) |
| 청크 길이 | 온라인 디코딩 시 1초 |
아키텍처별 오프라인/온라인 WER (Table 1 요약)
| 모델 | 오프라인 평균 WER | 온라인 평균 WER | 성능 저하 |
|---|---|---|---|
| Small | 7.66% | 9.38% | +1.72%p |
| Medium | 6.06% | 7.62% | +1.56%p |
| Large-V3 | 5.53% | 6.71% | +1.18%p |
| Large-V3-Turbo | 5.63% | 7.17% | +1.54%p |
모델이 클수록 오프라인-온라인 성능 격차가 작아집니다. Large-V3가 1.18%p로 가장 적은 저하를 보였습니다.
핵심 절제 실험 (Table 2: Large-V3-Turbo 기준)
| 방법 | WER (↓) | DAL (↓) | FLOPs (↓) |
|---|---|---|---|
| Local Agreement (Baseline) | 7.06% | 1.65s | 37.56G |
| Wait-1 | 7.59% | 0.93s | 34.35G |
| Wait-2 | 7.25% | 1.17s | 33.48G |
| Wait-3 | 7.17% | 1.41s | 32.63G |
| Wait-3† (버퍼 상태 재사용) | 7.31% | 1.41s | 12.77G ✅ |
| Wait-5 | 7.10% | 1.87s | 31.06G |
| Wait-∞ (오프라인) | 6.81% | 6.71s | 12.85G |
결과 해석
Wait-3은 Local Agreement 대비 WER이 0.11%p만 나빠지면서 지연 시간을 14.54% 단축합니다. Wait-3†(버퍼 상태 재사용)는 WER이 0.14%p 더 낮아지는 대신 디코더 연산량을 60.86% 절감합니다. Wait-k를 쓸수록 Local Agreement 대비 WER은 근소하게 낮아지지만 지연은 훨씬 짧습니다.
SpeechLLM 확장 (Table 3)
Whisper-Large-V3 + Qwen2.5-3B-Instruct를 결합한 SpeechLLM에도 MFLA를 적용했습니다. 오프라인 평균 WER 3.14%, 온라인 4.12%로, Whisper 단독보다 전 항목에서 우수한 성능을 보였습니다.
6. Discussion
✅ 이 방법의 장점
- Whisper 재활용 — 처음부터 학습하지 않고 LoRA 파인튜닝만으로 스트리밍 변환. 훈련 비용이 극적으로 낮습니다.
- 훈련-추론 일치 — prefix-to-prefix 패러다임이 훈련-추론 불일치를 근본적으로 해결합니다.
- 하나로 지연-품질 트레이드오프 제어 — Wait-k의 값을 바꾸는 것만으로 지연과 정확도를 유연하게 조절합니다.
- 오프라인-온라인 통일 — 로 설정하면 오프라인과 동일. 하나의 모델로 두 가지 운영 모드를 지원합니다.
- SpeechLLM 확장 가능 — LLM과 결합해도 동일한 프레임워크가 작동함을 실험으로 입증했습니다.
❌ 한계점 및 트레이드오프
- 예측기 구조 단순 — 예측기가 두 개의 선형 레이어와 ReLU로만 구성되어 프레임 수준 토큰 가중치 추정에 편향이 발생합니다. 저자가 직접 인정한 한계입니다.
- LoRA의 인코더 개선 효과 제한 — Wait-∞(오프라인 한계)와 오프라인 디코딩의 1.18%p 격차는 LoRA 파인튜닝이 스트리밍 음성 처리를 위한 인코더 개선에 충분하지 않음을 보여줍니다.
- 고정된 청크 길이 — 온라인 디코딩은 1초 고정 청크를 씁니다. 말하기 속도 변화에 유연하게 대응하지 못합니다.
- 영어/유럽어 외 검증 부족 — 중국어는 포함되었지만 그 외 아시아 언어에서의 성능은 검증되지 않았습니다.
💡 개선 가능한 방향
- 동적 조절 (Dynamic MFLA) — 쉬운 단어는 짧은 로 빠르게, 발음이 애매한 전문 용어는 더 긴 로 신중하게 처리합니다.
- 예측기 고도화 — 단순 선형 레이어 대신 트랜스포머 기반 예측기를 써서 프레임-토큰 경계 추정 정확도를 높입니다.
- 풀 파인튜닝 구간 추가 — 인코더 일부 레이어는 LoRA 외에 풀 파인튜닝을 허용해 스트리밍 음성에 대한 인코더 적응력을 높입니다.
7. My Insights
새롭게 알게 된 점
"실시간 모델을 만들려면 처음부터 실시간용으로 설계해야 한다"고 생각했습니다. 하지만 MFLA는 기존의 강력한 오프라인 모델(Whisper)에 제약을 추가하는 방식으로 실시간화를 달성했습니다. 새로운 모델을 만드는 것보다 기존 모델의 시야를 줄이는 것이 더 효율적인 전략이 될 수 있다는 것을 배웠습니다.
기존 생각이 바뀐 부분
미래 정보를 전혀 보지 않아야만 "진짜 실시간"이라고 생각했습니다.
하지만 MFLA는 딱 개만큼의 미래를 허용하는 것이 핵심입니다. Wait-3(약 3토큰 지연)만으로 오프라인과 1.18%p 차이까지 따라잡았습니다. "미래를 얼마나 볼 것인가"가 이진 선택이 아닌 연속적 설계 파라미터라는 관점이 실용적으로 중요하다는 것을 깨달았습니다.
어디에 응용할 수 있을까?
온디바이스 실시간 회의록 생성 시나리오에서 MFLA가 실용적인 선택지가 될 것 같습니다. 특히 Wait-3†(버퍼 상태 재사용)가 동일 지연에서 FLOPs를 60.86% 줄인다는 결과는, 배터리와 메모리가 제한된 스마트폰 환경에서도 충분히 작동할 가능성을 시사합니다. LLM과의 결합 가능성도 확인됐으므로, 온디바이스 SpeechLLM 형태로 발전시켜보는 방향이 흥미로울 것 같습니다.
8. Summary
| 항목 | 내용 |
|---|---|
| 핵심 문제 | Whisper는 성능이 뛰어나지만 오프라인 구조 — 훈련-추론 불일치로 실시간 적용 불가 |
| 해결 방법 | CIF(토큰 경계 감지) + MFLA(무한 왼쪽 + 유한 오른쪽 ) + Wait-k 디코딩 = prefix-to-prefix 파인튜닝 |
| 핵심 기여 | Wait-3 기준 Local Agreement 대비 WER +0.11%p에 지연 14.54% 단축, Wait-3†로 FLOPs 60.86% 절감 |
| 가장 인상 깊었던 점 | 로 설정하면 오프라인과 완전히 동일 — 오프라인을 온라인의 특수 케이스로 통일하는 우아한 설계 |
| 아쉬운 점 | 예측기 구조 단순, LoRA의 인코더 개선 한계, 오프라인-온라인 간 여전히 1.18%p 이상의 격차 |
| 확장 방향 | Dynamic 적응, 예측기 트랜스포머화, 온디바이스 SpeechLLM과의 결합 |
🧠 이 논문을 한 문장으로 말하면?
MFLA는 Whisper를 처음부터 다시 만들지 않고, CIF로 토큰 경계를 감지하고 무한 왼쪽 + 유한 오른쪽 개만 보는 어텐션으로 훈련-추론 불일치를 해결해, 단 하나의 파인튜닝으로 강력한 오프라인 모델을 실시간 스트리밍 시스템으로 변환한 실용적 프레임워크다.
