Transformer Transducer(https://arxiv.org/pdf/2002.02562)
트랜스포머의 똑똑함 + RNN-T의 실시간성 — 두 마리 토끼를 동시에 잡다
RNN-T의 뼈대는 그대로 유지하면서 내부 엔진을 LSTM에서 Transformer로 교체하고,
어텐션 마스킹으로 시야를 제한해 실시간 스트리밍까지 가능하게 만든 종단간 음성 인식 모델.
ICASSP 2020 | Qian Zhang, Han Lu, Hasim Sak, Anshuman Tripathi, Erik McDermott, Stephen Koo, Shankar Kumar (Google Inc.)
목차
- 서론
- Background
- Problem Definition
- Proposed Method / Approach
- Experiments & Results
- Discussion
- My Insights
- Summary
1. 서론
이 논문은 음성 인식 분야의 오래된 딜레마를 정면으로 파고듭니다.
"모델이 똑똑해질수록 실시간 처리가 불가능해진다."
트랜스포머는 자기 어텐션(Self-Attention) 덕분에 문맥 파악 능력이 매우 뛰어납니다. 하지만 전체 입력을 한꺼번에 봐야 하는 구조라 말이 끝날 때까지 기다려야 합니다. 반면 기존의 실시간 모델(RNN-T)은 속도는 빠르지만 LSTM의 한계로 정확도가 낮습니다.
이 논문은 RNN-T의 프레임 동기식 뼈대를 그대로 살리면서, 내부 LSTM 인코더를 Transformer로 교체하는 방법을 제안합니다. 그리고 어텐션 마스킹으로 시야를 제한해 실시간 처리까지 가능하게 만들었습니다. 이 글을 끝까지 읽으시면, 어떻게 '제한된 시야'가 실시간성과 정확도를 동시에 달성하는 열쇠가 되는지 직관적으로 이해하게 되실 겁니다.
2. Background
논문의 핵심으로 들어가기 전에, 왜 이 연구가 등장했는지 배경을 짚어봅니다.
종단간(End-to-End) 음성 인식의 3가지 흐름
| 모델 | 대표 논문 | 장점 | 치명적 한계 |
|---|---|---|---|
| CTC | Graves et al., 2006 | 빠르고 간단 | 출력 간 조건부 독립, 문맥 파악 불가 |
| LAS (Seq2Seq) | Chan et al., 2015 | 문맥 파악 우수 | 발화 끝까지 기다려야 함 — 실시간 불가 |
| RNN-T | Graves, 2012 | 실시간 + 문맥 고려 | LSTM의 장거리 의존성 한계 |
RNN-T: 실시간의 영웅, 하지만 구형 엔진
RNN-T는 스마트폰 음성 비서처럼 프레임 동기식(Frame-synchronous) 으로 작동합니다. 매 프레임마다 출력을 뱉을 수 있어 지연이 없습니다. 하지만 내부 인코더가 LSTM이라 긴 문맥을 기억하는 데 한계가 있었습니다.
Transformer: 최강의 엔진, 하지만 실시간 불가
Transformer의 Self-Attention은 입력 전체를 한꺼번에 보면서 어디에 집중할지 결정합니다. 이 능력이 탁월한 성능의 비결이지만, 동시에 "미래의 소리를 먼저 알아야 한다" 는 구조적 문제를 만들었습니다.
이 논문이 풀려는 핵심 질문:
Transformer의 자기 어텐션을 실시간 환경에서 작동하게 만들 수 있을까?
그리고 RNN-T의 프레임 동기식 손실 함수와 결합할 수 있을까?
3. Problem Definition
이 논문이 꼬집는 핵심 문제는 두 가지입니다.
| 문제 | 설명 |
|---|---|
| Transformer의 비인과성 | Self-Attention이 미래 프레임까지 참조 → 발화가 끝나야만 처리 가능 |
| Self-Attention의 이차 복잡도 | 입력 길이 에 대해 계산 → 스트리밍 환경에서 프레임당 연산량이 계속 늘어남 |
직관적 비유 🔦
동굴을 탐험한다고 상상해 봅시다.
- 기존 Transformer: 동굴 전체에 조명을 설치한 뒤 전부 살펴보고 길을 정합니다. 정확하지만 조명 설치가 끝날 때까지 기다려야 합니다.
- RNN-T (LSTM): 손전등 하나로 앞만 보며 걷습니다. 빠르지만 멀리 있는 장애물을 미리 파악하지 못합니다.
- Transformer Transducer: 손전등으로 앞 10걸음만 비추며 걷습니다. 속도를 유지하면서도 LSTM보다 훨씬 넓은 문맥을 파악합니다.
핵심 아이디어:
어텐션이 볼 수 있는 범위를 고정 윈도우로 제한(마스킹)하면, 프레임당 연산량이 로 상수화되어 스트리밍이 가능해집니다.
4. Proposed Method / Approach
Transformer Transducer(T-T)는 RNN-T의 뼈대 + Transformer 인코더 + 제한적 어텐션 마스킹 세 요소의 결합으로 작동합니다.
전체 구조: RNN-T 아키텍처에 Transformer를 이식
RNN-T 구조는 오디오 인코더, 라벨 인코더, 조인트 네트워크 세 부분으로 나뉩니다. 기존 RNN-T는 두 인코더 모두 LSTM이었습니다. T-T는 이 두 인코더를 Transformer로 교체합니다.
| 구성 요소 | 기존 RNN-T | Transformer Transducer |
|---|---|---|
| 오디오 인코더 | LSTM | Transformer (18 layers) |
| 라벨 인코더 | LSTM | Transformer (2 layers) |
| 조인트 네트워크 | Feed-Forward | Feed-Forward (동일) |
| 손실 함수 | RNN-T Loss | RNN-T Loss (동일) |
핵심 설계: Transformer 인코더 블록
논문의 Transformer 인코더는 일반적인 Transformer와 미묘하게 다릅니다.
- LayerNorm 먼저 적용 — 입력에 먼저 정규화한 뒤 어텐션 계산 (Pre-Norm 방식)
- 상대적 위치 인코딩(Relative Positional Encoding) — Transformer-XL 방식을 채택해 과거에 계산한 상태를 재사용 가능하게 함. 절대 위치 인코딩을 쓰면 재사용이 불가해 복잡도가 로 폭발
- 라벨 인코더 ↔ 오디오 인코더 간 어텐션 없음 — 두 인코더가 서로를 참조하지 않고 독립적으로 동작 → 스트리밍 가능
왜 라벨 인코더가 오디오 인코더를 보지 않나요?
LAS처럼 디코더가 인코더를 참조하는 구조는 오디오 전체를 알아야만 작동합니다. T-T는 정렬(Alignment)을 RNN-T Loss의 Forward 알고리즘이 처리하므로, 두 인코더가 독립적으로 동작해도 됩니다. 이것이 스트리밍을 가능하게 만드는 구조적 비결입니다.
스트리밍의 열쇠: 어텐션 마스킹
Transformer의 Self-Attention을 실시간 환경에 쓰려면 미래 프레임을 보지 못하게 막아야 합니다.
| 마스킹 방식 | 설명 | 지연 시간 |
|---|---|---|
| Full Attention | 과거·미래 프레임 모두 참조 | 발화 전체 대기 |
| Left-only (left=10) | 과거 10프레임만 참조 | 거의 0 |
| Left + Right Context | 과거 N + 미래 M 프레임 참조 | 레이어 수 × M × 30ms |
Right Context의 트레이드오프:
Figure 3이 이를 잘 보여줍니다. 3개 레이어에서 right=1프레임씩 허용하면, 을 출력하기 위해 실제로는 이 도착할 때까지 기다려야 합니다. 논문에서 right=6프레임/레이어를 허용하면 약 3.2초 지연이 발생하지만 성능이 크게 개선됩니다.
직관적 예시 2가지 💡
| 비유 | 설명 |
|---|---|
| 동시통역사 | 소리 인코더는 귀로 발음만 듣고, 라벨 인코더는 지금까지 적은 자막만 봅니다. 둘의 의견을 조인트 네트워크가 종합해 다음 글자를 결정합니다 |
| 손전등 탐험 | Full Attention = 전체 조명 설치 후 출발. Left=10 마스킹 = 손전등으로 10걸음 앞만 비추며 실시간 전진 |
수식 이해하기
핵심 수식: 모든 정렬 경로의 확률 합산
| 기호 | 의미 |
|---|---|
| 최종 출력 레이블 시퀀스 (예: "hello") | |
| 입력 오디오 프레임 시퀀스 | |
| 레이블과 시간의 정렬 쌍 — blank 포함 가능 | |
| 길이 에서 가 될 수 있는 모든 유효 정렬의 집합 |
이 수식의 핵심:
CTC와 마찬가지로 가능한 모든 경로의 확률을 합산합니다. CTC와의 차이는 각 경로 확률 를 계산할 때 이전 라벨 히스토리를 조건으로 포함한다는 점입니다. 즉, 이전에 무엇을 출력했는지가 현재 출력에 영향을 미칩니다.
Self-Attention 수식
| 기호 | 의미 |
|---|---|
| (Query) | 지금 집중하려는 기준 벡터 |
| (Key) | 비교 대상 벡터들의 태그 |
| (Value) | 실제로 끌어올 정보 |
| 점수 폭주 방지 스케일링 |
스트리밍 모드에서는 계산 시 미래 위치를 로 마스킹해 Softmax 후 가중치가 0이 되도록 만듭니다.
📊 Figure 1 — RNN-T vs Transformer Transducer 아키텍처 비교
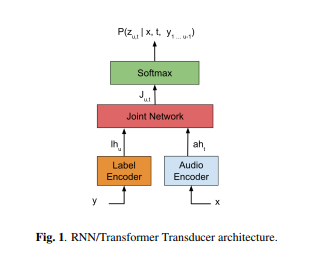
- 이 그림이 보여주는 것: 왼쪽은 LSTM 기반 RNN-T, 오른쪽은 Transformer 인코더로 교체된 T-T의 전체 구조. 오디오 인코더, 라벨 인코더, 조인트 네트워크(Feed-Forward + Softmax) 세 블록 구성이 동일함을 보여줍니다.
- 핵심 메시지: 뼈대(RNN-T 구조)는 완전히 동일하고 내부 인코더 블록만 Transformer로 교체되었습니다. 이 심플한 교체가 논문의 핵심 아이디어입니다.
내가 이해한 포인트
두 인코더(오디오, 라벨)가 서로를 참조하지 않고 독립적으로 작동한다는 점이 LAS와 가장 크게 다릅니다. LAS는 디코더가 인코더 전체를 봐야 하지만, T-T는 정렬을 RNN-T Loss가 담당하므로 두 인코더가 분리되어 스트리밍이 가능해집니다.
📊 Figure 2 — Transformer 인코더 블록 내부 구조
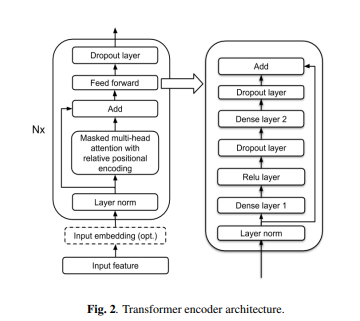
- 이 그림이 보여주는 것: T-T에 쓰인 Transformer 레이어의 세부 구조. 입력 → LayerNorm → Multi-Head Attention → Residual Connection → LayerNorm → Feed-Forward(2048 → 1024) → Residual Connection → 출력. 입력 임베딩 크기 512, 어텐션 헤드 8개, 헤드 차원 64, Dropout 0.1의 파라미터 설정이 Table 1에 명시됩니다.
- 핵심 메시지: Pre-Norm(LayerNorm을 먼저 적용) + Residual Connection 구조로 깊은 레이어에서도 안정적으로 학습됩니다.
내가 이해한 포인트
일반적인 Transformer(Post-Norm)와 달리 LayerNorm을 먼저 적용합니다. 또한 상대적 위치 인코딩(Transformer-XL 방식)을 써서 스트리밍 시 이전에 계산한 상태를 재사용할 수 있습니다. 이 덕분에 복잡도가 에서 로 줄고, 윈도우 마스킹을 더하면 상수 복잡도가 됩니다.
📊 Figure 3 — Right Context 지연 시간 시각화

- 이 그림이 보여주는 것: 3개 레이어 Transformer에서 각 레이어에 right=1프레임 허용 시, 을 출력하려면 실제로 이 도착할 때까지 기다려야 하는 지연 누적 과정을 다이어그램으로 표현합니다.
- 핵심 메시지: 레이어가 많을수록 Right Context의 지연이 누적됩니다. 18개 레이어에서 right=6프레임/레이어 허용 시 약 3.2초 지연(18 × 6 × 30ms ≈ 3.24초)이 발생하지만, WER이 크게 개선됩니다.
내가 이해한 포인트
이 그림 하나로 "Right Context 몇 프레임을 허용할 것인가"가 단순한 하이퍼파라미터 선택이 아니라 실제 사용자 체감 지연 시간과 직결된 설계 결정임을 알 수 있습니다. 논문은 right=2프레임/레이어(약 1초 지연)가 스트리밍 모델 대비 약 30% 성능 개선을 가져온다고 밝혔습니다.
5. Experiments & Results
저자들은 T-T가 정확도와 실시간성을 동시에 달성하는지 체계적으로 검증했습니다.
| 실험 항목 | 내용 |
|---|---|
| 데이터셋 | LibriSpeech (970시간 오디오 + 800M 단어 텍스트 전용 데이터) |
| 음향 특징 | 128채널 log-mel, 32ms 윈도우, 4프레임 스태킹 + 3프레임 서브샘플링 → 512차원, 30ms 스트라이드 |
| 모델 구조 | 오디오 인코더 18레이어 + 라벨 인코더 2레이어, 총 139M 파라미터 |
| 학습 환경 | 8×8 TPU, 배치 2048, 약 1일 학습 (LSTM RNN-T: 3.5일 대비) |
| 평가 지표 | WER(단어 오류율) — test-clean / test-other |
결과 요약 (Table 2 기준)
| 모델 | 파라미터 | Clean WER | Other WER | LM 적용 시 Clean | LM 적용 시 Other |
|---|---|---|---|---|---|
| Hybrid [22] | — | — | — | 2.26% | 4.85% |
| LAS [23] | 361M | 2.8% | 6.8% | 2.5% | 5.8% |
| BiLSTM RNN-T | 130M | 3.2% | 7.8% | — | — |
| FullAttn T-T (Ours) | 139M | 2.4% | 5.6% | 2.0% | 4.6% ✅ |
스트리밍 모드 결과 (Table 3, 4, 6 기준)
| 오디오 Left | Right | 라벨 Left | Clean WER | Other WER |
|---|---|---|---|---|
| 512 (Full) | 512 | 20 | 2.4% | 5.6% |
| 10 | 2 | 2 | 3.6% | 10.0% |
| 10 | 0 | 20 | 4.2% | 11.3% |
| 6 | 0 | 20 | 4.3% | 11.8% |
결과 해석
Full Attention T-T(2.4%)는 LAS(2.8%, 3.6배 큰 모델)와 BiLSTM RNN-T(3.2%)를 모두 이겼습니다. 파라미터 수는 오히려 더 적으면서 SOTA를 달성했습니다. 스트리밍 모드(left=10, right=2, label=2)에서도 3.6%로, 기존 BiLSTM RNN-T 최고 성적(3.2%)에 근접한 수준을 유지했습니다.
6. Discussion
✅ 이 방법의 장점
- 학습 속도 3.5배 향상 — 같은 파라미터 수에서 LSTM RNN-T 대비 1일 vs 3.5일. Self-Attention의 병렬화 덕분입니다.
- 유연한 정확도-지연 트레이드오프 — Left/Right Context 프레임 수와 레이어 수를 조절해 지연 시간과 WER을 자유롭게 균형 잡을 수 있습니다.
- 적은 파라미터로 SOTA — 361M의 LAS보다 2.6배 작은 139M으로 더 낮은 WER 달성.
- 라벨 인코더는 left=3만으로 충분 — Table 5에서 라벨 left를 20→3으로 줄여도 WER 변화가 미미합니다. 라벨 문맥은 오디오보다 훨씬 짧아도 됩니다.
❌ 한계점 및 트레이드오프
- 스트리밍 시 성능 저하 — Full Attention(2.4%) 대비 Left-only 스트리밍(4.2%)은 WER 75% 상승. 아직 격차가 큽니다.
- 조용한 환경 편향 — LibriSpeech는 오디오북 기반의 깨끗한 데이터입니다. 지하철·식당 같은 실제 잡음 환경에서의 검증이 빠져 있습니다.
- 여전히 무거운 모델 — 139M 파라미터는 온디바이스 스마트폰 탑재에는 부담스러운 크기입니다.
- 같은 마스크를 모든 레이어에 적용 — 논문이 직접 "레이어별로 다른 Context를 쓰는 것이 탐구할 가치가 있다"고 언급할 만큼 아직 최적화되지 않은 설계입니다.
💡 개선 가능한 방향
- Conformer와 결합 — Convolution 블록을 추가해 지역적 음향 패턴까지 잡으면 WER이 더 낮아집니다. (실제로 이후 Conformer-T 연구로 발전)
- Dynamic Chunk 크기 — 말이 빠를 때는 넓게, 말이 멈췄을 때는 좁게 청크를 유동적으로 조절하면 지연-정확도 균형이 개선됩니다.
- Knowledge Distillation — Full Attention 모델이 선생님, 스트리밍 모델이 학생이 되어 미래 문맥을 간접적으로 학습하면 격차를 줄일 수 있습니다.
7. My Insights
새롭게 알게 된 점
같은 Transformer라도 어디에 어텐션을 허용하느냐가 모델의 성격을 완전히 바꾼다는 것을 배웠습니다. Full Attention과 Left-only Masking은 수식 구조가 똑같지만, 마스크 하나로 실시간 모델과 비실시간 모델로 갈립니다. 구조보다 어떤 정보에 접근을 허용할 것인가라는 설계 철학이 더 중요하다는 것을 깨달았습니다.
기존 생각이 바뀐 부분
"실시간 모델은 배치 처리 모델보다 항상 성능이 낮을 것이다"라고 생각했습니다.
하지만 T-T의 스트리밍 모드(left=10, right=2)는 WER 3.6%로, Full Attention LAS(2.8%)와 오히려 비슷한 수준입니다. Right Context를 소량 허용하는 것만으로도 Full Attention과의 격차를 상당 부분 메울 수 있다는 사실이 실용적인 설계 지점으로 남았습니다.
어디에 응용할 수 있을까?
온디바이스 실시간 회의록 생성 시나리오를 생각해보면, T-T의 레이어별 Context 마스킹 전략을 응용할 수 있을 것 같습니다. 하위 레이어는 넓은 Right Context로 음향 패턴을 충분히 파악하고, 상위 레이어는 Left-only로 지연을 최소화하는 계층별 차등 마스킹 방식이 흥미로운 구조가 될 것 같습니다.
8. Summary
| 항목 | 내용 |
|---|---|
| 핵심 문제 | Transformer는 성능이 뛰어나지만 전체 입력을 봐야 해서 실시간 처리 불가. LSTM RNN-T는 실시간이지만 정확도 한계 |
| 해결 방법 | RNN-T 뼈대 유지 + LSTM → Transformer 교체 + 어텐션 윈도우 마스킹으로 실시간화 |
| 핵심 기여 | LibriSpeech SOTA 달성(Clean 2.4%, LM 적용 시 2.0%), LSTM RNN-T 대비 학습 속도 3.5배 향상 |
| 가장 인상 깊었던 점 | 라벨 인코더가 오디오 인코더를 참조하지 않는 구조 덕분에 스트리밍이 가능해진다는 설계적 통찰 |
| 아쉬운 점 | 스트리밍 모드의 WER 상승(2.4→4.2%), 잡음 환경 검증 부재, 모든 레이어에 동일 마스크 적용 |
| 확장 방향 | Conformer 블록 결합, Dynamic Chunk 마스킹, Full-Streaming Knowledge Distillation |
🧠 이 논문을 한 문장으로 말하면?
Transformer Transducer는 RNN-T의 프레임 동기식 뼈대에 Transformer 인코더를 이식하고 어텐션 윈도우 마스킹으로 시야를 제한해, 전 세계 표준 벤치마크에서 SOTA를 달성하면서도 실시간 스트리밍까지 가능하게 만든 정확도와 실시간성의 균형점이다.
