앞선 글에서 LLM이 등장하기 전 AI시장에 대해 알아보았다면 이제는 LLM의 등장에 대해서만 알아보려고 한다.

LLM의 구조 이해하기
초기 NLP 모델
1. RNN(Recurrent Neural Networks)
순환 신경망으로 시퀀스 데이터를 처리하기 위해 고안된 신경망 구조이다. 이전의 정보를 기억하고(이전의 문장, 단어) 현재의 결과를 결정하는데 사용하게된다.
예를 들어, (나는 커피를 __) 일때,
이전의 커피를 기준으로 다음의 단어인 '마신다'를 유추할 수 있다는 것이다.따라서 입력 데이터가 시간순서를 가지게 될 경우 유용했고, 연속된 데이터를 처리하는데 적합했지만,
‘장기 의존성 문제’가 존재하게 된다.이는 과거의 정보를 기억하기 어려워지는 문제로 알고있으면 된다.
2. LSTM(Long Short-Term Memory)
RNN의 장기 의존성 문제를 해결하기 위한 장,단기 메모리 네트워크이다.
셀 상태를 도입하여 중요한 정보를 오랫동안 저장하였고 게이트 메커니즘을 사용해 장기 패턴을 더 잘 기억할 수 있었다.
하지만 연산량이 많아 학습 속도가 느리고, RNN과 마찬가지로 순차적으로 데이터를 처리해야 하므로 병렬 연산이 어려워 고성능을 발휘할 수 없다.
이는 Transformer가 등장하는 계기가 되게 했다.
3. Word2Vec(트랜스포머 이전의 자연어 처리)
단어를 벡터로 변환하는 방법을 제시한 논문으로 의미적으로 비슷한 단어들이 가까운 벡터 공간에 위치하도록 설계하는 것이다.
즉, 왕 - 남자 + 여자 -> 여왕 와 같은 의미적 연산을 가능케 했다.하지만 단어 간 유사도를 학습할 수는 있지만, 문장이나 문맥(context)을 반영하기는 어려웠다.
I go to skool을 자연스럽게 우리는 school의 오타임을 알수있지만 컴퓨터는 이를 해결해내지 못했다는 의미이다.
또한 동일한 단어라도 다른 의미를 가질수 있는데 이를 구별해내지 못했다.
Transformer의 등장
"Attention is All You Need"논문에서 기존의 RNN과 LSTM은 장기 의존성 문제와 속도의 문제를 해결할 Transfomer 모델을 발표하였다.
self-Attention을 통해 순차적으로 학습해야 하는 RNN/LSTM의 문제를 병렬 처리를 통해 문장의 모든 단어를 서로 연결하여 문맥을 효과적으로 반영하였고, 장기 의존성 문제 또한 Self-Attention을 통해 해결하였다.
학습 속도 또한 모든 단어를 병렬적으로 처리하기 때문에 향상시켰고 더욱 효율적인 메모리를 사용할 수 있게 되었다.
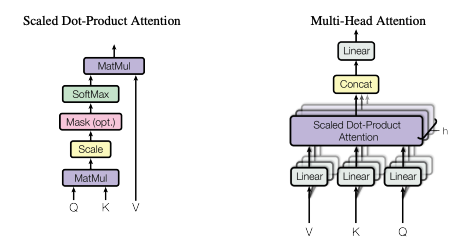
동작 방식
각 단어를 Q(Query), K(Key), V(Value)라는 벡터로 변환한다.
그리고 각각의 단어 하나하나가 문장 내 모든 단어들과의 관계를 분석한다.
그 결과 어떤 단어가 어떤 단어와 얼마나 높고 낮은 유사도를 가지는지 파악한다.
-> 높은 가중치를 부여한다는 의미
그리고 유사도에 따라 단어의 중요도를 조정하여 긴 문장의 관계도를 학습하고 위 과정을 통해 다의어의 문제도 해결하며 더 정교한 NLP 모델을 만들게 된다.
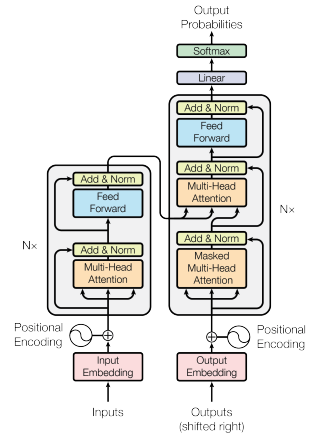
구조
📌 Encoder → 입력 문장을 받아 문맥(Context) 정보를 포함한 벡터로 변환
📌 Decoder → 변환된 벡터를 바탕으로 출력 문장을 생성
1️⃣ 입력 문장 → 임베딩(Embedding)
2️⃣ 위치 정보 추가 → Positional Encoding
3️⃣ Self-Attention 적용 (입력 문장 내 단어 간 관계 학습)
4️⃣ Feed-Forward Network(비선형 변환수행) → 추가 학습
5️⃣ 출력 문장 생성 (Decoder에서 Self-Attention 및 Masked Attention 사용)
Self-Attention
가장 중요한 기술이다.
입력 문장의 모든 단어를 동시에 처리하면서, 각 단어가 다른 ‘모든’ 단어들과 얼마나 관련이 있는지 계산
RNN, LSTM이 순차적으로 데이터를 처리하지만, Self-Attention은 문장 내의 모든 단어를 동시에 보고 처리(병렬)
Multi-Head Atention(다중 헤드 어텐션)
여러 개의 어텐션을 동시에 수행하여, 다양한 문맥 정보를 반영할 수 있도록 한다
쉽게 생각하면 하나의 attention-head는 동사의 시제를 학습하면서 다른 attention-head는 단어 간 의미 관계에 대해 학습한다는 것이다.
Encoder의 발전 -> BERT
한줄로 설명하자면 Transfomer 인코더 구조를 사용하여 문장의 앞뒤 정보(양방향 문맥)를 모두 학습하는 양방향 모델이라고 할 수 있따.
MLM(마스킹 단어 모델)기법으로 더 풍부한 문맥 이해가 가능하도록 학습하게 한다.
입력 : I love [Mask] music
예측 : I love classic music예측이 가능하게해야하므로 미래를 볼 수 없기 해줘야한다.
또한 NSP(Next Sentence Prediction)을 통해 두 문장이 연속된 문장인지 예측하게 한다
문장 1 : I went to the store
문장 2 : I bought some apples -> 정답
문장 3 : The sun is shining -> 오답하지만 BERT는 문장을 잘 이해할뿐 직접 문장을 생성하지는 못한다.
Decoder의 발전 -> GPT
이 또한 한문장으로 설명하자면 문장을 왼쪽에서 오른쪽으로 예측하는 생성형 모델로 말 그대로 다음 단어를 예측하며 문장을 생성하는데 초점을 둔 모델이다.
입력 : I love classical
출력 : music이렇게 예측하여 만들어주는게 GPT라고 이해하면 편하다.
자연스러운 텍스트를 생성해주지만, 문장 간의 논리적 일관성을 완벽하게 유지하지 못할 수 있다는 단점이 있다.
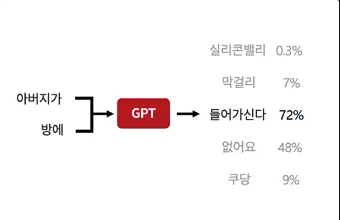
이렇게 GPT는 G(예측)PT이다. 따라서 항상 일관되게 들어가신다를 고를 확률이 100프로가 아니라는 뜻이고, 👿거짓말을 내뱉을 수도 있다👿
GPT입장에서는 나름 예측해서 대답한 것이지만 정답은 아닐수도 있기 때문이다
이를 우리는 Hallucination(환각)이라고 한다.
말만 거창하지 그냥 헛것을 보고 말한다고 봐도 무방하다.
LLM
드디어 LLM에 대해 설명하는 부분이다.
하지만 우리는 이미 무엇이 발전되어야했고 어떤 기술이 더 필요한지 앞서서 다뤄왔다. 그저 더 많은 매개변수와 학습 데이터를 통해 성능을 개선해오고, 사용자와의 대화에서 AI가 맥락(context)를 잘 이해하고 적절한 방응을 제시할 수 있으며, 답변할 수 있는 영역을 광범위화 하자 인것이다.
그렇게 발전한 결과, 지금까지의 정형데이터인 텍스트를 넘어 이미지와 오디오, 비디오 등 비정형데이터까지 다루며 인식하고 이해하는 시대에 도달하게 되었다.
AI는 더 이상 단순한 도구가 아닌, 창작과 사고의 영역까지 확장되는 강력한 파트너가 되고 있다. 일자리를 위협하는 존재가 아닌 나의 전문성을 두곽시키고 기량을 확장시킬 도우미정도로 이해하고 사용하여 생산성을 높이고 창의적인 혁신을 만들어 내는것이 중요한 개념이라고 생각한다.
[출처] "Attention Is All You Need"(https://arxiv.org/pdf/1706.03762)
