최근 다양한 AI 제품들이 단순한 응답 생성에서 나아가 외부 도구를 직접 호출하고, 판단하고, 행동하는 구조로 진화하고 있습니다.
이런 구조를 코드로 실현하기 위해서는 GPT와 도구 사이의 흐름을 정교하게 제어할 수 있는 프레임워크가 필요합니다.

그래서 이번 글에서는 LangGraph를 활용해 GPT가 웹 검색 도구를 직접 요청하고, 결과를 바탕으로 다시 사고하고 응답하는 일련의 흐름을 구현했습니다.
이 과정을 통해 단순한 챗봇을 넘어서, 도구 기반 Agent 구조를 설계하고,
LLM의 사고와 행동을 그래프 기반으로 제어하는 실전 워크플로우를 학습할 수 있습니다.
LangGraph란?
LangGraph는 LangChain 위에서 동작하는 상태 기반 워크플로우 프레임워크입니다.
즉, 에이전트의 상태와 흐름을 노드 그래프 형태로 시각적으로 설계하고 실행할 수 있게 해주는 프레임워크라고 할 수 있습니다.
기존의 LangChain으로 체인, 에이전트를 구성하였고,
동작시켰지만 다음과 같은 문제가 발생합니다. 그리고 해당 문제들을 LangGraph로 해결합니다.
흐름 제어가 어렵다 -> 명시적 상태 기반 전이로 해결
에이전트 간 협업이 불투명 -> 각 노드를 정의하고 연결함으로써 해결
복잡한 워크플로우의 디버깅 -> 시각적 흐름으로 디버깅 가능
사전 개념
코드 리뷰를 진행하기 전에 알아야할 기본 개념들입니다.
-
LangChain
: LLM을 위한 체인/에이전트 구성 프레임워크 -
State
: 현재 에이전트나 워크플로우가 어떤 정보를 갖고 있는지 나타내는 상태값 -
Node
: 그래프에서 하나의 처리 단계를 의미(LLM 호출, 도구 실행) -
Edge
: 상태 간의 전이(어떤 조건이 만족되었을 때 어디로 이동하는가?) -
memory
: 노드간 상태(state)를 공유하고 업데이트하는 역할 -
Thread id
: 각 그래프 실행 인스턴스를 고유하게 식별하는 ID
: 같은 그래프라도 서로 다른 유저가 동시에 실행할 수 있다
: 따라서 어떤 사용자의 흐름인지 식별해야 한다 -
checkpointer
: LangGraph의 실행 흐름 중간 상태를 디스크나 데이터베이스 등에 저장하는 기능이다.
: 중간에 끊겨도 상태를 저장해두었다가 이어서 실행이 가능하다
: 복잡한 워크플로우에서 각 단계별 상태 스냅샷의 보관이 가능하다. -
graph_builder
: LangGraph 워크플로우를 정의할 때 사용되는 빌더 객체
코드 설명
LangGraph - Basic
Dict : 일반적인 key-value 딕셔너리이며 모든 값이 str,int 등 값임을 지정합니다.
TypeDict : Python 3.8에서 등장한 구조로, 딕셔너리를 클래스처럼 정의할 수 있게 해줍니다.
# TypedDict
class Person(TypedDict):
name: str
age: int
job: str
typed_dict: Person = {
"name": "김영희",
"age": 25,
"job": "ai engineer",
}typedDict는 LangGraph의 상태정의(State)를 표현할 때 자주 사용됩나다.
그래프의 상태가 어떤 필드를 갖고, 어떤 타입인지 명시해줘야 그래프 흐름이 더 명확해지기 때문
뿐만 아니라 dict는 아무키나 추가가 가능하지만 typeddict는 사전에 정의된 키만 허용합니다
그래프 상태를 구조화하고, 예상치 못한 값이 흘러가지 않게 하기 위해서입니다.
from typing import Annotated, List
from pydantic import Field, BaseModel, ValidationErrorLangGraph의 상태를 정의할 떄 고급 타입과 검증을 지원하기 위해 추가 모듈을 가져옵니다.
Annotated : 타입에 추가 메타데이터를 부여한다. 필드에 설명이나 제약조건을 추가
List : 리스트 타입 지정. 복수 값 필드 타입화
Field : 필드에 기본값, 검증 조건 설정. Pydantic 모델 필드 설정
BaseModel : Pydantic의 기본 모델로 데이터 검증 및 직렬화에 사용
이에 따라 Pydantic 모델을 활용한 데이터 검증을 본격적으로 진행할 수 있습니다.
class Student(BaseModel):
id: Annotated[str, Field(..., description="학생ID")]
name: Annotated[str, Field(..., min_length=3, max_length=50, description="이름")]
age: Annotated[int, Field(gt=23, lt=31, description="나이(24~30세)")]
skills: Annotated[
List[str], Field(min_items=1, max_items=10, description="보유기술(1~10개)")
]각 필드는 Annotated를 통해 타입과 추가 검증 조건이 설정되어있다.
따라서 모든 조건이 올바르게 만족되어야 에러가 발생하지 않고 인스턴스가 생성될 수 있다.
from langchain_core.messages import AIMessage, HumanMessage
from langgraph.graph import add_messagesLangGraph에서 메시지 관리는 굉장히 중요한데, 특히 대화형 워크플로우를 구축할 때
HumanMessage와 AIMessage를 구분해서 관리합니다.
AIMessage : AI모델의 응답 메시지를 표현 -> 메시지 흐름에서 사용
HumanMessage : 사용자의 입력 메시지를 표현 -> 사용자-에이전트 대화 관리
add_messages : 두 메시지 리스트를 합치는 함수 -> 상태(State) 업데이트 시 사용
message1 = [HumanMessage(content="안녕하세요?", id="ID-001")]
message2 = [AIMessage(content="반갑습니다.", id="ID-002")]
result = add_messages(message1, message2)
print(result)
서로 다른 아이디의 메시지를 합친다면 단순히 두 리스트를 이어 붙이는 역할을 한다.
문제없이 병합된다는 의미입니다.
message1 = [HumanMessage(content="안녕하세요?", id="ID-001")]
message2 = [AIMessage(content="반갑습니다.", id="ID-001")]하지만 같은 ID의 메시지라면 보통은 마지막 메시지가 우선시 됩니다.
정리
TypedDict와 BaseModel을 이용해 상태(State) 구조를 엄격하게 정의한다.
Pydantic을 이용해 입력 데이터의 타입과 조건을 검증할 수 있도록 준비한다.
HumanMessage와 AIMessage를 이용해 대화 메시지를 객체로 관리한다.
add_messages를 사용하여 여러 메시지를 안전하게 합치고, 상태를 갱신한다.
LangGraph - Chatbot
앞으로 진행될 코드리뷰에서 계속해서 이 코드가 반복됩니다.
# API KEY Loading
from dotenv import load_dotenv
load_dotenv()이는 API_KEY나 TAVILY_KEY같은 개인키를 불러오는 역할을 합니다.
또한
from langchain_teddynote import logging
logging.langsmith("CH21-LangGraph")
해당 코드를 통해 CH21-LangGraph라는 이름으로 LangSmith상에서 로그를 남길 수 있습니다.
https://smith.langchain.com 사이트에서 워크플로우 실행을 추적할 수 있습니다.
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messagesStartGraph : LangGraph 그래프 빌더. 워크플로우를 설계할 객체
START,END : 그래프 특수 노드. 그래프의 시작점과 종료점을 지정
State 정의
class State(TypedDict):
messages: Annotated[list, add_messages]State라는 클래스를 정의합니다.
이는 LangGraph 워크 플로우에서 사용할 상태 구조를 정의한것으로
TypeDict를 사용해서 messages라는 키만 가진 딕셔너리 형태로 상태를 정의합니다.
이때 messages는 단순 리스트가 아니라 Annotated를 통해 LangGraph가 상태 업데이트 시
자동으로 add_messages 함수를 적용하도록 설정한 것입니다.
즉, 각각의 노드가 출력한 메시지를 messages 필드에 계속 누적하면서 대화 흐름을 관리할 수 있게 되는 구조입니다.
Node 정의
# 챗봇 함수 정의
def chatbot(state: State):
return {
"messages": [llm.invoke(state['messages'])]
}LangGraph 노드에서 사용할 chatbot 동기 호출 함수입니다
입력받은 state(이전 대화 메시지들)를 기반으로 LLM을 호출하고,
그 결과 메시지를 다시 messages에 추가합니다.
반환값은 [] 딕셔너리로 되어있고, messages 키에 AI 응답 메시지가 리스트로 포함됩니다.
이 값은 State의 messages에 자동으로 add_messages를 통해 누적됩니다.
Graph 정의
# 그래프 정의
graph_builder = StateGraph(State)
# 노드 추가
graph_builder.add_node("chatbot", chatbot)StateGraph(State)를 사용해 워크플로우에서 사용할 상태 타입을 설정하고, chatbot이라는 이름의 노드를 정의합니다.
"chatbot"이라는 노드는 위에서 정의한 def chatbot 함수를 수행합니다.
Edge 추가
# 시작점 정의
graph_builder.add_edge(START, "chatbot")
## 종료지점 정의
graph_builder.add_edge("chatbot", END)START -> "chatbot"노드로 흐름을 연결
즉, 그래프 실행이 시작되면 가장 먼저 "chatbot"노드를 실행하게 됩니다.
"chatbot" -> END 지점으로 흐름을 이어줌
즉, 이 그래프는 "START" → "chatbot" → "END" 순서로 한 번만 실행되고 종료됩니다.
graph = graph_builder.compile()위에서 설계한 graph_builder의 상태와 노드들을 실행가능한 그래프 객체로 컴파일 합니다.
이후 이 graph 객체를 사용하여 .invoke()등으로 실행이 가능합니다.
from langchain_teddynote.graphs import visualize_graphLangChain과 LangGraph 흐름을 시각화 할 수 있는 도구입니다.
question = "서울 맛집 TOP 10 알려주세요"
for event in graph.stream({"messages": [("user", question)]}):
for value in event.values():
print("Assistant: ", value["messages"][-1].content)graph.stream()은 LangGraph 그래프를 단계별로 실행하며 이벤트를 스트리밍으로 전달합니다.
입력으로 {"messages": [("user", question)]} 구조의 상태(state)를 넘깁니다.
각 단계에서 반환된 메시지중 마지막[-1] 메시지를 꺼내어 출력합니다.
GPT 기반 챗봇을 LangGraph 워크플로우로 구성하는 예제
한 번의 질문에 GPT가 응답하고 종료하는 단일 턴 챗봇 구조
LangGraph-Agent
from langchain_teddynote.tools.tavily import TavilySearchTavilySearch는 웹 검색을 수행하는 LangChain Tool입니다.
에이전트가 외부 정보를 실시간으로 가져오기 위해 사용합니다.
이번 코드는 이 TavilySearch 도구를 에이전트에 연결하여
LangGraph 내에서 Tool 기반 행동을 수행하는 에이전트를 구성하려는 흐름으로 진행됩니다.
# 도구 정의
tool = TavilySearch(max_results=5)
# 도구 목록 반영
tools = [tool]TavilySearch의 검색결과를 최대 5개를 가져와 도구로 정의합니다.
이 도구를 tools 리스트에 담아 나중에 에이전트나 LangGraph 그래프에 연결할 수 있게 준비합니.
# 도구 실행
print(tool.invoke("LangGraph Tutorial"))TavilySearch 도구에 LangGraph Tutorial이라는 쿼리를 전달하여 웹 검색을 수행합니다.
결과물 출력

from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI위에서 정의한대로 상태정의와 메시지 병합 그리고 LLM 준비를 위한 import 구성입니다.
상태를 TypeDict로 정의하고 GPT기반 응답 시스템을 ChatOpenAI로 만들게됩니다.
# State 정의
class State(TypedDict):
messages: Annotated[list, add_messages]LangGraph에서 사용할 상태 클래스를 TypeDict로 정의합니다.
사용자와 AI가 주고받은 메시지를 messages에 저장하고,
단순히 리스트가 아니라 새로운 메시지가 추가될때마다 병합됩니다.
# LLM 정의
llm = ChatOpenAI(model = 'gpt-4o-mini', temperature=0)
# LLM + Tools
llm_with_tools = llm.bind_tools(tools)앞서 정의한 tools목록을 GPT의 도구로 연결(bind)합니다.
이를 통해 LLM은 일반 텍스트 응답 뿐만 아니라 필요한 경우 TavilySearch 도구를 직접 호출합니다.
def chatbot(state: State):
answer = llm_with_tools.invoke(state["messages"])
return {"messages": [answer]}에이전트 노드 함수를 정의합니다.
from langgraph.graph import StateGraph
# 그래프 초기화
graph_builder = StateGraph(State)
# 노드 연결
graph_builder.add_node("chatbot", chatbot)앞서 정의한 State클래스를 기반으로 LangGraph그래프를 초기화합니다.
이 객체에 노드추가, 시작/종료 연결등을 합니다.
def __init__(self, tools: list) -> None:
# 도구 리스트
# 주어진 도구 리스트를 이름(name)을 기준으로 딕셔너리 형태로 변환
self.tools_list = {tool.name: tool for tool in tools}
def __call__(self, inputs: dict):
# 메시지가 존재할 경우 가장 최근 메시지 1개 추출
# inputs 딕셔너리에서 "messages" 키의 값을 가져옴 (없으면 빈 리스트 반환)
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
# 도구 실행 결과를 저장할 리스트
outputs = []
# message 객체 안의 tool_calls 속성에는 LLM이 호출 요청한 도구 정보가 리스트로 저장되어 있음
for tool_call in message.tool_calls:
# 도구 이름으로 실제 도구 인스턴스를 가져와서, 전달된 인자(args)를 사용해 실행
tool_result = self.tools_list[tool_call["name"]].invoke(tool_call["args"])
# 도구 호출 후 결과 저장
# 도구 실행 결과를 문자열(JSON 형식)로 변환하여 ToolMessage 객체로 저장
outputs.append(
# 도구 호출 결과를 메시지로 저장
ToolMessage(
content=json.dumps(
tool_result, ensure_ascii=False
), # 도구 호출 결과를 문자열로 변환
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}GPT가 tool_call을 요청하면 해당 요청을 처리하는 Tool 전용 실행노드입니다.
GPT 응답 안의 .tool_calls 속성을 확인해
tool_result = self.tools_list[].... 문장에서
도구 이름에 해당하는 실제 Tool객체를 찾아 전달된 args를 넘겨 invoke를 실행합니다.
실제 도구를 실행하고 그 결과글을 ToolMessage로 포장해서 반환합니다.
self.tools.list 문장을 통해 GPT가 "name":"TavilySearch"로 요청했을 때,
이름으로 바로 찾아 실행할 수 있습니다.
# 도구 노드 생성
tool_node = BasicToolNode(tools=[tool])
# 그래프에 도구 노드 추가
graph_builder.add_node("tools", tool_node)위에서 정의한 BasicToolNode 인스턴스를 생성하고
tools라는 이름으로 그래프에 연결합니다.
Conditional Edge
조건 분기 노드 연결 이라는 뜻으로 그래프 실행 중 상태(state)의 내용에 따라
다음 노드를 동적으로 결정할 수 있게 해주는 기능입니다.
일반적인 흐름은 다음과 같습니다.
graph_builder.add_edge("nodeA", "nodeB")무조건 nodeA 다음에 nodeB
하지만 조건 분기 흐름을 사용하면 다음과 같습니다.
graph_builder.add_conditional_edges(
source="nodeA",
path=route_function,
path_map={"yes": "nodeB", "no": "nodeC"}
)
nodeA가 끝난 다음, route_function(state)함수의 반환값에 따라
nodeB, nodeC 경로를 지정합니다.
라는 의미입니다.
그리고 조건 분기 함수의 구성은 다음과 같습니다.
def route_function(state):
ai_message = state["messages"][-1] # 가장 최근 메시지
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return END현재 상태(state)안에 들어있는 AIMessage객체를 확인합니다
해당 메시지 안에 tool_calls 속성이 있고, 실제로 호출 요청이 존재하면 tools를 반환하고
그렇지 않으면 END를 반환합니다.
코드의 조건분기 연결설정에서는
graph_builder.add_conditional_edges(
source="chatbot",
path=route_tools,
path_map={
"tools": "tools", # route_tools가 "tools" 반환 시 실행할 노드
END: END, # route_tools가 END 반환 시 종료
}
)이렇게 존재하는데 그렇다면 이는
route_tools가 "tools" 반환 시 tools 노드를 다음 노드로 실행하고
route_tools가 END 반환 시 종료한다는 의미인 것입니다.
graph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("tools", "chatbot")
이제 전체 흐름을 마무리 합니다
LangGraph의 시작점에서 "chatbot"으로 흐름에 진입하고
도구 실행을 완료한 tools노드에서 다시 chatbot으로 되돌아가
도구 결과를 기반으로 후속 응답을 생성합니다.
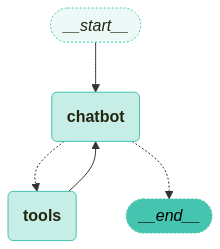
점선은 조건부, 실선은 기본을 의미합니다.
실행
inputs = {"messages": "SKC&C에서 진행하는 SKALA에 대해서 검색해 주세요"}
for event in graph.stream(inputs, stream_mode="values"):
for key, value in event.items():
print(f"\n==============\nSTEP: {key}\n==============\n")
print(value[-1])실제로 실행을 한다면
START -> chatbot 노드
GPT는 사용자의 질문을 입력으로 받고, 아직 정보가 부족하다고 판단하면
도구 호출(tool_call)을 생성합니다.
tool_calls: [{"name": "tavily_web_search", "args": {"query": "SKC&C SKALA"}}]GPT 응답은 비어있지만 tool_calls에 tavily_web_search 검색 명령이 들어가있음을 확인할 수 있습니다.
조건 분기 route_tools
route_tools()가 실행되고, tool_call가 있음을 확인 후 tools가 선택됩니다.
tools 노드 실행
BasicToolNode가 실행되어 실제로 TavilySearch("SKC&C SKALA")를 호출
웹에서 정보를 검색한 결과를 ToolMessage형식으로 LangGraph에 저장합니다.
tools -> chatbot
chatbot노드는 gpt에게 ToolMessage 결과를 넘깁니다.
GPT는 검색 결과를 바탕으로 최종 응답을 생성합니다.
다시 route_tools실행
이번에는 tool_calls가 없습니다.
정리
사용자의 질문에 대해 GPT가 도구를 활용해 직접 정보 검색하고,
검색 결과를 바탕으로 최종 응답을 생성하는 지능형 워크플로우 구현
