
그래서 쿠버네티스가 등장하게 된다.
쿠버네티스
다수의 서버와 다수의 컨테이너를 요청에 따라 적절하게 스케쥴하고 배치하기 위한 Orchestration가 필요했고, 물리적인 서버를 하나의 논리적인 시스템으로 합쳐서 컨테이너가 운영되도록 지원한다.
모든 노드가 하나의 거대한 컴퓨터인 것처럼 수천개의 컴퓨터 노드에서 소프트웨어 애플리케이션을 실행한다고 생각하면 된다.
참고 : Kubernetes 는 10글자이다. 이에 따라 사람들은 앞 뒤 글자만 자르고 k8s라고 잘 부른다.
명령적 방식 → 선언적 방식
쿠버네티스의 가장 큰 특징이라고 한다면 명령적 방식이 아닌 선언적 방식이라고 볼 수 있다.
기존의 명령적 방식은 업무를 지시하고 계속해서 지켜보고 조율하고 해줘야한다. 하지만 선언적 방식은 명세서(목적)만 전달하고 더 이상 신경쓰지 않는다는 점이다.
요청 받은 명세서(업무)는 이제 알아서 무슨일이 있어도 지켜야 하는 명령이 된 것이다.
선언적 구조 동작 방식의 흐름
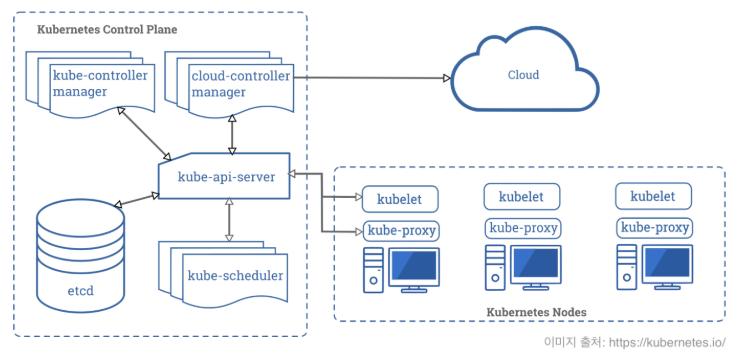
사용자는 yaml,json의 형태의 imagefile 즉 명세서(Manifest)를 작성한다.
그리고 해당 명세서를 kubectl을 통해 kube-API-Server에 파일을 전송한다.
kube-API-Server는 쿠버네티스의 핵심 컴포넌트로, 모든 요청을 처리하는 중앙 API 역할을 수행한다.
이때 전송된 파일이 배포할 Pod, SErvice등 원하는 상태(spec)이 담겨있는 파일인 것이다.
kubectl : 사용자가 쿠버네티스에 명령을 내릴 수 있도록 하는 CLI(Command Line Interface) 도구)2. yaml 저장
kube-API-Server는 전달받은 yaml을 ETCD(쿠버네티스의 Key-Value 저장소)에 저장한다.
ETCD내에 Manifest(yaml)가 저장되면 이것을 기준으로 쿠버네티스는 SPEC을 유지하기 위해 계속해서 알아서 일한다.
3. 배포 Pod 식별 및 배포 요청
kube controller는 현재 클러스터 상태와 원하는 상태(yaml에서 정의한 spec)를 비교한다.
차이가 있을 경우, 새로운 Pod를 생성하도록 요청을 kube-API Server에 보낸다.
4. 스케쥴 여부 확인
클러스터 내의 리소스 사용량을 분석하고, 적절한 Worker Node에 Pod를 배치할지 결정한다.
5. spec에 따라 유지
스케줄된 Node에서는 spec을 유지하기 위해 kubelet이 Pod를 실행하고 유지 관리한다.
kubelet은 API Server와 지속적으로 통신하면서, Pod가 정상적으로 동작하는지 확인한다.
그리고 Pod가 비정상적이면 자동으로 복구하는 역할을 한다.
kubelet은 단순히 관리하는 역할만 한다. 로드밸런싱은 Ingress이렇게 클러스터 전체를 관리하는 노드를 Master Node (Control Plane)이라고 하고,
실제 애플리케이션이 동작하는 노드를 Worker Node라고 한다.
그리고 컨테이너를 관리하는 Node들의 집합을 클러스터라고 한다.
이렇게 동작하는 방식을 보면서 우리는 쿠버네티스 클러스터가 여러개의 물리적/가상 서버를 묶어서, 하나의 거대한 컨테이너 오케스트레이션 시스템처럼 동작시킨다고 흐름을 알 수 있다.
클러스터 >> 노드 >> 파드 >> 컨테이너
클러스터(Cluster) - 가장 큰 개념 (공장 단지)
쿠버네티스 시스템 전체로 여러 개의 노드(Node)로 구성된다
(내부에 Control Plane (Master Node) + 여러 개의 Worker Node )
실제 애플리케이션을 실행하는 환경이라고 할 수 있다.
노드(Node) - 클러스터를 구성하는 개별 서버 (공장)
클러스터를 구성하는 개별 서버 (물리 서버 or 가상 머신)라고 할 수 있다.
Control Plane Node (마스터 노드): 클러스터 관리 담당
Worker Node (작업 노드): 실제로 애플리케이션을 실행하는 역할
Worker Node 내부에는 여러 개의 Pod가 배치된다.
파드(Pod) - 최소 실행 단위 (공장의 작업장)
쿠버네티스에서 애플리케이션이 실행되는 최소 단위
보통 하나의 Pod 안에는 하나의 컨테이너가 들어가지만 여러 개의 컨테이너를 포함할 수도 있다.
같은 Pod 안에 있는 컨테이너들은 같은 네트워크 환경(가상 IP)을 공유한다.
컨테이너(Container) - 실제 애플리케이션 실행(작업장 안의 기계)
실제 애플리케이션이 실행되는 환경이다.
Docker 같은 컨테이너 기술을 사용하여 실행되고,
같은 Pod 안의 컨테이너들은 같은 저장 공간(Volume)과 네트워크를 공유한다.
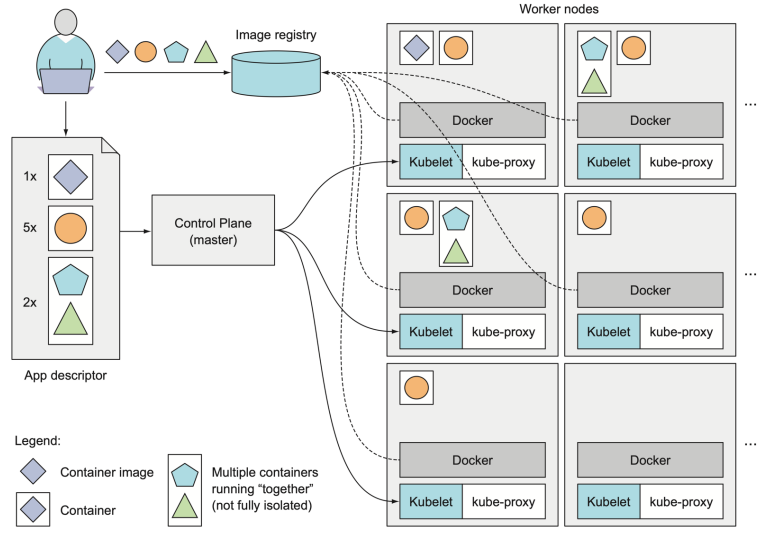
해당 그림을 보면서 좀 더 쉽게 용어들을 이해할 수 있다.
사용자는 마름모 컨테이너 이미지, 동그라미 컨테이너 이미지등을 작성하여 manifest를 만든다.
그리고 해당 spec을 유지하기 위해 master node는 woker node와 소통하면서 pod들을 할당한다. 그리고 각자의 pod들은 본인의 container들을 가져다가 실행한다. 여기서 pod안에는 하나의 container가 있을수도 있지만 multi-container가 있을수도 있다.
Service
Pod는 휘발성이므로, Pod가 종료되거나 재시작될 때 IP가 바뀌는 문제가 발생한다. 이에 따라 Pod의 IP 고정,지정해주는것이다.
라벨 셀렉터를 사용해 라벨에 해당하는 Pod들을 서비스에 매칭시키는데, 만약 새로 추가된 Pod가 해당하는 라벨을 달고있다면 Service는 해당 Pod로 트래픽을 보내는 방법을 알게된다는 것이다.
이게 가능한 이유는 Endpoints라는 오브젝트에 해당 하는 Pod들을 매핑 시키는데, 이 Endpoints에 매핑된 Pod들의 IP정보를 가지고 Pod에게 트래픽을 전달하는 것이다.
트래픽을 전달 하는 것이지 로드 밸런싱 해주는것은 아니다.
Ingress
클러스터 외부에서 내부 서비스로 HTTP 및 HTTPS 트래픽을 라우팅하는 리소스이다.
외부에서 클러스터로 들어오는 요청(트래픽)을 여러 Service로 라우팅(분배)한다.
즉, ingress로 위부 트래픽이 들어오는것을 내부의 여러 service로 로드밸런싱한다는 의미이다.
ConfigMap
환경 변수 주입
키, 밸류로 이루어져있따
config를 매핑시켜준다 → 비밀번호 키, 밸류 이런것을 등록한 뒤 배포
Secret
configMap이랑 동이랑 기능을 수행하는데
난수화를 통해 보안설정(밖에서 보지 못하게)
Namespace
쿠버네티스에 자신의 애플리케이션을 배포했을 때 사용되는 리소스
컨테이너의 네임스페이스와는 다른것이다
실제 스페이스가 실행되기 위한 다양한 환경들을 격리 시켰다고 보면 된다
Horizontal Pod AutoScaler
파드의 개수를 늘리는것
Vertical Pod AutoScaler
파드가 처리할 수 있는 개수를 늘리는 것
