보다 쉽게 생각하자면 두개의 것이 합쳐져서 하나가 되는 것을 말하고, 작은 필터가 이미지가 이미지의 한 부분과 뒤섞이며 새로운 특징(이미지)를 만들어낸다.
이를 통해 이미지와 같은 2D 데이터에서 특징을 자동으로 추출하여 학습하는 딥러닝 모델이라는 것을 우리는 알 수 있다.
물론 특징을 잘 뽑아주는 장점을 가지고 있어 이미지 뿐만 아니라 텍스트와 같은 형태에서도 유용하게 쓸 수 있다.
단적인 예시를 위해 2D 이미지 데이터를 입력으로 받는다고 생각해보자
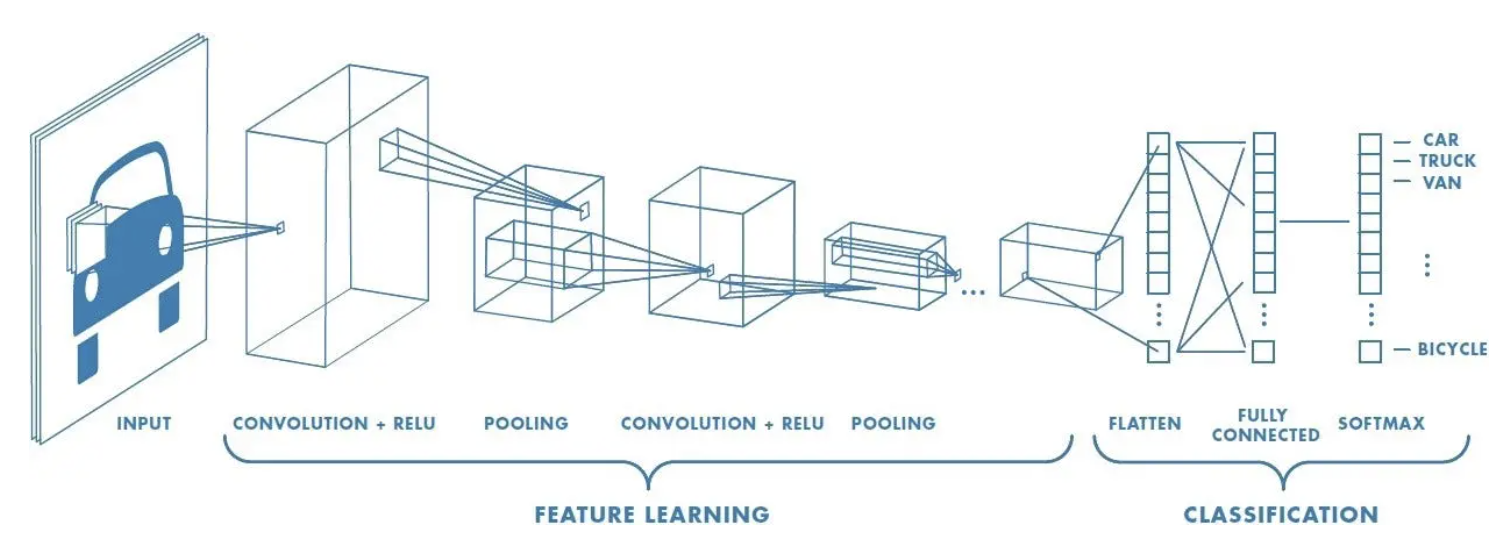
1. 데이터 입력 (Input Layer)
입력받은 이미지는 단순한 숫자 배열이 아니라 픽셀 값이 3D 형태로 표현되는 3차원 텐서 데이터이다
(가로크기, 세로크기, 채널수)를 통해 각 차원이 얼마나 많은 요소를 포함하고 있는지 정보를 얻을 수 있다.
2. 합성곱 연산 (Convolution Layer)
ConV로 줄여서 작성하기도 하는 해당 계층에서 3차원 이미지 정보에서 이미지 특징(Feature)를 뽑아낸다.
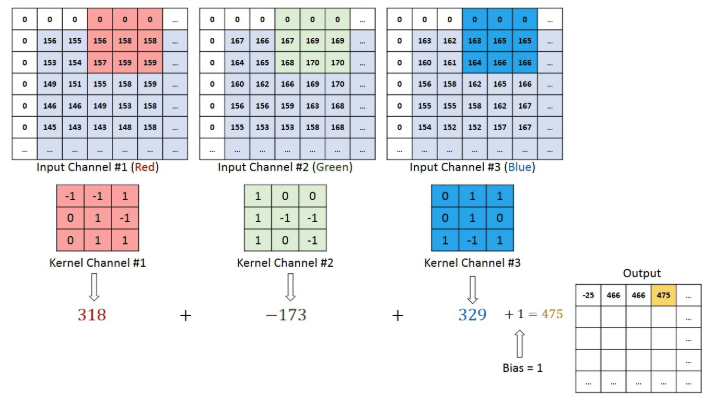
해당 과정을 통해 원본 데이터에서 feature를 뽑아낼 수 있고
feature map의 사이즈가 줄게 된다
보통 특징을 잘 뽑아내기 위해 작은 사이즈로 돌리고 (3,3)
stride(보폭)을 정할 수도 있지만 보통 한칸으로 진행한다.
2-1. Padding
합성곱 연산을 수행할 때, 입력 이미지의 크기를 유지하거나 특정 패턴을 보존하기 위해 가장자리(padding)에 0(혹은 1)을 추가하는 기법이다.
만약 배경에 아무것도 없는 경우 안써도 무방하지만 화면에 빽빽하게 정보들이 저장되어 있고, 해당 그림들을 특정하고 싶다면 padding을 진행 후 conv를 또 다시 진행하게 된다.
2-2 ReLU (Rectified Linear Unit)
합성곱 연산 후 비선형성을 추가하기 위해 ReLU 활성화 함수를 사용한다.
음수값이 0으로 변환되고 비선형성을 추가하여 CNN이 더 복잡한 패턴을 학습 가능하고 속도가 증가하게 해주는데, 값이 맞으면 곧이곧대로 값을 보내주고, 틀린값이 온다면 0으로 처리한다고 이해하면 쉽다.
3. 풀링 (Pooling Layer)
특징 맵의 크기를 줄여 계산량을 줄이고 중요한 특징망 추출해서 작은 이미지로 남겨두는 것이다 (애매한 값은 버린다)
이를 통해 사진이 축소되는 느낌을 받게되며, 대표적으로 Max Pooling을 사용한다.
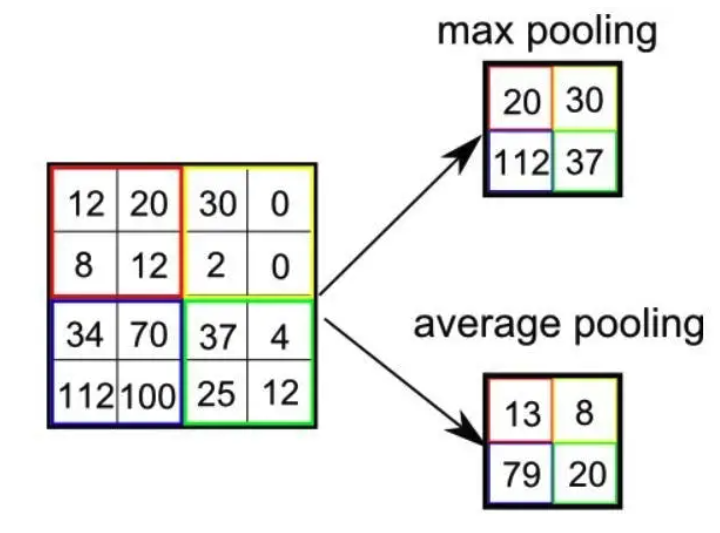
(2,2)로 pooling하겠다고 설정 후 각 칸에서 가장 큰값이나 평균값등을 뽑아 이미지를 생성한다.
4. 분류(Classification)
CNN이 특징을 추출한 후, 최종적으로 FC를 사용하여 분류를 수행하게 된다.
4-1. Faltten Layer
분석한 이미지 데이터를 라벨 분류하기 위해 1D 벡터로 변환해주는 역할을 수행한다.
변환된 데이터를 Dense Layer에서 활용할 수 있게끔 펼치는 과정이다.
4-2. Dense(밀집) Layer
Flatten(평탄화)된 벡터를 받아 분류를 수행하는 층이다.
CNN이 추출한 특징을 바탕으로 최종적으로 예측을 수행하는 층으로 생각하면 된다.
해당 층에서 FC 데이터를 받아 softmax Function을 통해
출력을 확률(0~1)로 변환하여 분류를 수행한다.
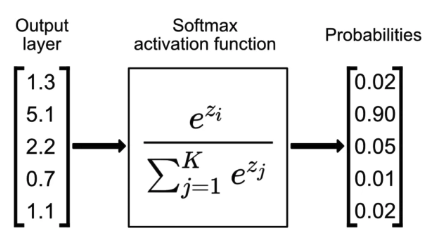
해당 이미지에서 볼 수 있듯이 2번째 라벨로 예측될 확률이 90%라는 의미이다.
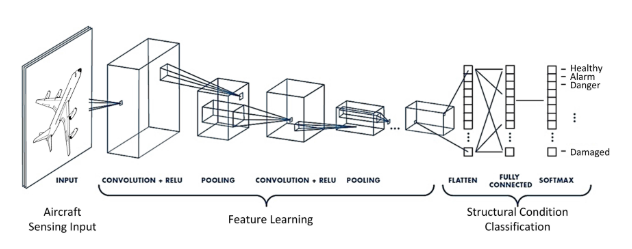
이제 다시 해당 이미지를 통해 흐름에 대해 이해할 수 있을 것이다.
< 🏞️ 이미지 출처 >
