~ 2023 / 11 / 12
실수의 연산시 주의할 점
부동소수점변환에 대하여 탐구하였습니다
c++ 코드를 작성하여 예를 들어보겠습니다
#include <iostream>
using namespace std;
int main() {
int a, b;
a = 10;
b = 15;
cout << a + b << endl;
return 0;
}변수 a 와 b를 선언하였습니다
이 때 a와 b의 자료형은 int (정수) 입니다
a와 b 각각 10과 15를 저장하였습니다
그 다음으로 a+b를 출력하도록 하였습니다
이 때 출력 결과는 25로 정상적인 값이 나왔습니다
하지만 자료형을 float (실수) 로 바꿔주게 된다면 무슨일이 발생할까요?
#include <iostream>
using namespace std;
int main() {
float a, b;
a = 10;
b = 15;
cout << a + b << endl;
return 0;
}이 때의 출력결과도 당연히 25가 나왔습니다
10과 15가 아닌, 0.1과 0.11같은 소수와 소수의 연산에서도 정상적으로 작동하는지 확인해보겠습니다
#include <iostream>
using namespace std;
int main() {
float a,b;
a = 0.1;
b = 1.1;
cout.precision(22);
cout << fixed;
cout << a + b << endl;
return 0;
}코드를 약간 수정해주었습니다.
cout.precision(22);
cout << fixed;이 코드는 소수점 아래 22번째 자리까지 표현한다는 코드입니다
이 때의 실행 결과로는 1.2000000476837158203125 로 비정상적인 값이 출력되었습니다
왜 이런 일이 일어나는지 알아보겠습니다
일단 컴퓨터가 숫자를 저장하는 방법을 먼저 알아야합니다
예를들어 숫자 5를 저장하는 방법에 대하여 설명해보겠습니다
컴퓨터의 램 이라는 부품에 숫자를 포함한 데이터들을 잠시 저장합니다
cpu는 데이터를 저장하지 못하기 때문에 하드디스크나 ssd같은 저장장치에서 필요한 데이터들을 빠르게 연산하기 위해 램에 저장합니다
왜냐하면 hdd나 ssd에서 바로 cpu로 연산할 데이터들을 옮기는건 비효율적이고 속도가 느립니다
한 마디로 램은 cpu를 위한 작업공간 이라고 생각하면 편합니다
그리고 이 램을 확대시켜보면 0과 1을 저장 할 수 있는 칸들이 매우 많이 있습니다 흔히
메모리라고 불립니다

저는 숫자 5를 저장하기 위해 메모리에 8칸 정도를 마련해봤습니다
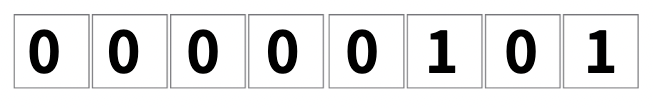
컴퓨터는 2진법을 사용하기 때문에 숫자 5를 2진수로 변환하여 저장하였습니다
물론 숫자 5 말고 더 큰 숫자를 저장하려면 방금 보셨던 칸을 늘리면 됩니다
하지만 5.125 같은 소수는 어떻게 저장할까요?
소수 저장하는 법
5.125를 2진수로 변환한다면 101.001 로 표현할 수 있습니다

이렇게 컴퓨터 메모리에 저장하려면 정수와 소수부분 따로따로 저장 할 수 있습니다
하지만 속도와 효율이 중요하니, 이 방법은 사용하지 않습니다

맨 첫번째 칸은 숫자의 부호를 결정합니다
5.125는 양수이기 때문에 0을 넣어주었습니다
그 다음으로 5.125를 2진수로 바꾸어줍니다
5.125 ---> 101.001
그리고 소수점을 옮겨줍니다
101.001 ---> 1.01001
그 후 2의 제곱을 곱해줍니다
1.01001 x 2^2
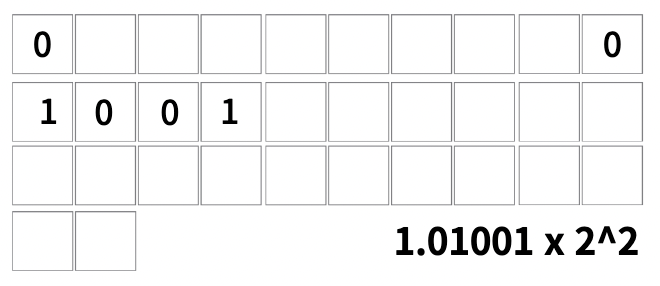
소수점 기준으로 우측에 있는 수를 mantissa 라고 합니다
이 mantissa를 맨 뒤에서부터 23칸에 차례대로 넣어줍니다
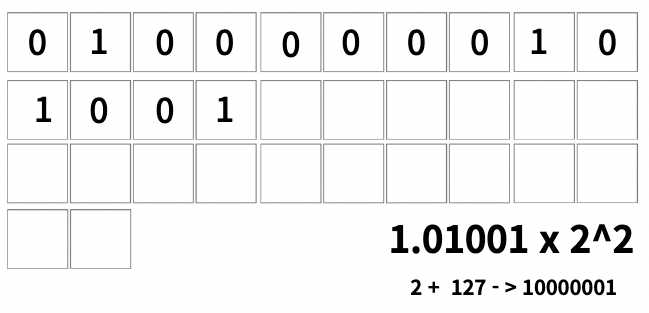
다음으로 지수에 127을 더한 후 2진법으로 변환 후 앞 자리에다 넣어줍니다
이게 컴퓨터가 소수를 저장하는 방법입니다
순환소수 (무한소수) 문제
0.125 같은 소수들은 0.001로 깔끔하게 떨어집니다
하지만 0.1같은 수들은 2진수로 변환하였을 때 0.00011001100110011001100.....
이렇게 순환하는 무한소수가 발생하게 됩니다

그래서 아까 방식과 같이 메모리에 저장한다면 이렇게 칸을 넘어가게 됩니다
메모리를 더 사용하면 된다고 생각할 수 있겠지만,
이 32칸은 float자료형의 메모리 크기라고 할 수 있고 32바이트입니다
더 크게는 double의 64바이트입니다
하지만 저희는 단지 0.1이라는 소수만 저장할 것이기 때문에 더 많은 칸을 차지하는 것은 낭비입니다
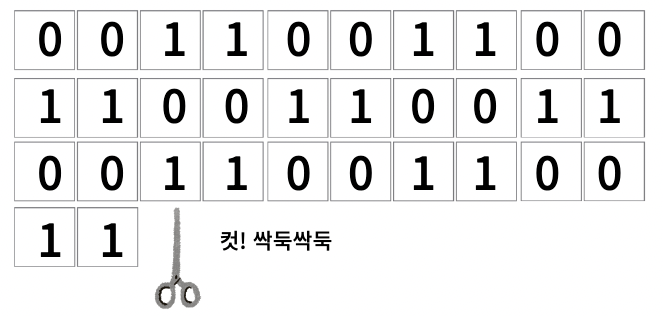
그렇기 때문에 칸을 넘어가는 부분을 모두 잘라주었습니다

넘어가는 부분들을 모두 다 잘라버리게 된다면 잘린 부분만큼 오차가 발생합니다
그래서 0.1을 메모리에 저장한다면 0.1이 정확이 저장되지 않고 근삿값이 저장됩니다
문제 해결 방법
실제 중요한 프로그램을 작성할 때 이만큼의 오차도 일어나서는 안됩니다
아주 작은 수 이지만, 여러면 더해지거나 오차가 증가하면 치명적입니다
또한 비교연산자를 사용하였을때 결과가 달라집니다
그렇기 때문에 실수를 표현 할 때 반올림을 해버리거나 단위를 바꿔줄 수 있습니다
단위를 바꾼다는 말은 예를들어 1.1km 대신 1100m로 표현 할 수 있습니다
참고 영상 / 글
유튜브 코딩애플 - https://youtu.be/-GsrYvZoAdA
MISRA-C 요약 글 - https://grapevine9700.tistory.com/45
포인터 / 메모리 구조
언어의 특성과 c언어 포인터에 관련한 내용입니다
프로그래밍 언어를 배우다보면 포인터라는 단어가 처음 들어보는 단어는 아닐겁니다
그만큼 어렵고 복잡하고 헷갈리는 내용으로 유명합니다
그래서 c언어를 사용하지 않으면 포인터를 안배워도 상관 없다고 착각을 합니다
하지만 요리사가 요리만 잘 하는게 아닌 재료와 도구 관리도 중요시 하는 것 처럼
포인터 또한 중요합니다
저수준 언어의 개념과 지식 없이도 웹 서비스나 앱을 만들 수 있겠지만,
아무래도 경력이 쌓이고 중요한 시스템을 구현 할 때 컴퓨터가 어느방식으로 굴러가는지 아는 것은 중요합니다
메모리의 구조에는 4가지 영역이 있습니다
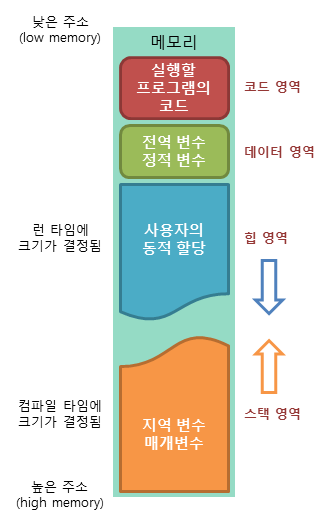
code 영역
실행할 프로그램의 코드가 저장되는 영역
프로그램이 시작하고 끝날 때 까지 메모리에 계속 남아있습니다
컴파일된 기계어가 들어갑니다
cpu는 이 영역에 있는 기계어를 하나씩 가져다 연산합니다
data 영역
프로그램의 global 변수와 static 변수, 문자열, 상수가 저장되는 영역
프로그램의 시작과 동시에 할당되고, 종료시 데이터는 소멸합니다
stack 영역
프로그램이 자동으로 사용하는 임시 메모리 영역
함수의 호출시 필요한 지역변수와 매개변수가 저장됩니다
선입선출의 방식으로 가장 나중에 들어온 데이터가
이곳에 저장되는 함수의 정보를 스택 프레임이라고 합니다
스택 영역은 메모리의 높은 주소에서 낮은 주소의 방향으로 할당되기 때문에
LIFO 형식이고, 후입선출의 방식입니다
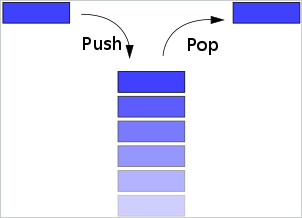
스택 영역에서 푸시로 데이터를 저장하고 팝으로 데이터를 내보냅니다
heap 영역
프로그래머가 직접 관리해야하는 영역
힙 영역은 프로그래머가 메모리 공간이 동적으로 할당되고 해제됩니다
힙 영역은 메모리의 낮은 주소에서 높은주소의 방향으로 할당되기 때문에 FIFO 방식이고, 선입선출입니다
unmanaged 언어와 managed 언어의 차이점
unmanaged 언어는 대표적으로 c와 c++ 있습니다
특징은 개발자가 메모리 관리를 조금 더 직접적으로 할 수 있습니다
메모리의 할당과 해제 작업을 통해 메모리 누수 현상이 없도록 관리해준다면
managed 언어에 비해서 속도가 빠릅니다
대표적으로 managed 언어에는 java와 c#이 있습니다
managed 언어는 가비지컬랙터를 통해 메모리의 할당과 해제를 언어 자체적으로 관리합니다
메모리의 직접적인 할당과 해제를 하지 못하기 때문에 프로그래밍의 자유도가 상대적으로 낮으며 비정기적으로 메모리의 정리가 이루어집니다
포인터는 무엇일까요
메모리관리에 사용되는 수단 중 하나입니다
포인터는 가비지컬랙터를 사용하지 않고 보다 직접적으로 컴퓨터를 제어할 수 있게 해줍니다
예시로 c언어 코드를 사용하겠습니다
#include <iostream>
using namespace std;
int main(int argc, const char* argv[]) {
char lang = 'c' ;
int any_num = 123 ;
double pi = 3.141592 ;
return 0;
}문자변수 lang, 정수변수 any_num, 그리고 double 변수 pi를 저장했습니다
이 값들은 메모리 어딘가에 저장됩니다
한정된 메모리 안에서 변수나 함수 같은 값들이 할당과 해제를 통해 관리됩니다
프로그램을 만들다 보면 변수에 있는 값을 다른 여러 곳에서 써야 할 경우가 있습니다
예를들어 생명과학 수행평가를 준비한다고 하면
내용을 알려주기위해 노트에 다 적고 보여주는 것 보다
생명과학의 책 페이지 수만 알려주면 됩니다
void function_1(int _arg) {
//작업 수행
}
int argument = 10;
function_1(argument)c언어에서 어느 함수에 변수가 인자로 주어질 때는 그 값이 복사되어서 넘어갑니다
복사된다는 것은 중복된 크기만큼 메모리의 공간을 차지한다는 말입니다
즉 수행평가 내용을 알려주기 위해 종이에 내용을 다 쓰지 않고 페이지 수만 알려주는 것과 같이
메모리를 낭비하지 않고 페이지 번호만 적어 보여줄 수 있도록 하는것이 포인터입니다
메모리는 각각 주소를 가지고있습니다
#include <iostream>
using namespace std;
int main(int argc, const char* argv[]) {
char lang = 'c' ;
int any_num = 123 ;
double pi = 3.141592653 ;
char* p0 = ⟨
return 0;
}p0이란 포인터 변수로 해서 lang의 위치를 가리키는 코드입니다
#include <iostream>
using namespace std;
int main(int argc, const char* argv[]) {
char lang = 'c' ;
int any_num = 123 ;
double pi = 3.141592653 ;
char* p0 = ⟨
cout << *p0 << endl;
return 0;
}
p0를 출력해보면 lang 변수에 저장된 값이 출력됩니다
수행평가 범위는 시작하는 페이지와 끝나는 페이지로 구성되어있습니다
마찬가지로 포인터도 끝나는 부분도 필요합니다
int (정수)는 1이 들어오든, 1273891이 들어오든 4바이트를 차지합니다
반면 double 자료형은 0.1이라는 값에도 8바이트를 차지합니다
다른 자료형들도 정해진 바이트들이 있습니다
포인터를 지정할 때 자료형도 같이 표시하는 이유입니다
#include <iostream>
using namespace std;
int main(int argc, const char* argv[]) {
char lang = 'c' ;
int any_num = 123 ;
double pi = 3.1415926535897 ;
char* p0 = ⟨
cout << *p0 << endl;
int x = 1;
int y = 200;
int z = 7894123;
int* p1 = &x;
cout << *p1 << endl;
//1 출력
x++;
cout << *p1 << endl;
//2 출력
return 0;
}
x의 값을 1증가시키면 2가 당연히 출력됩니다
#include <iostream>
using namespace std;
int main(int argc, const char* argv[]) {
char lang = 'c' ;
int any_num = 123 ;
double pi = 3.1415926535897 ;
char* p0 = ⟨
cout << *p0 << endl;
int x = 1;
int y = 200;
int z = 7894123;
int* p1 = &x;
cout << *p1 << endl;
//1 출력
x++;
cout << *p1 << endl;
//2 출력
p1 ++;
cout << *p1 << endl;
//-500688741 출력
return 0;
}
하지만 포인터에 정수값을 더해준다면 자료형의 크기 x 그 값 만큼 메모리 구역이 오른쪽으로 이동합니다
변수들은 프로그래머가 지정하는대로 예측가능한 곳에 배열되지 않습니다
이렇게 포인터를 제대로 알고 사용하지 않으면 이런 오류가 날 수 있습니다
배열 자료형을 사용하면 값들이 메모리에 나란하게 배열됩니다
#include <iostream>
using namespace std;
int main(int argc, const char* argv[]) {
char lang = 'c' ;
int any_num = 123 ;
double pi = 3.1415926535897 ;
char* p0 = ⟨
cout << *p0 << endl;
int x = 1;
int y = 200;
int z = 7894123;
int* p1 = &x;
cout << *p1 << endl;
//1 출력
x++;
cout << *p1 << endl;
//2 출력
p1 ++;
cout << *p1 << endl;
//-500688741 출력
int numbers[] = {1,2,3,4,5,6,7}
int* p2 = &numbers[0]
cout << *p2 << endl;
//1 출력
p2++;
cout << *p2 << endl;
//2 출력
return 0;
}
포인터는 이렇게 배열과 연계되어 사용될 수 있습니다
void _Performance_ssessment_Jeong_woo_value(int _arg) {
_arg = 24;
}
void _Performance_ssessment_Jeong_woo_pointer(int* _arg) {
*_p++ = 24;
}
int arg = 10;
int *p_arg = &arg;
_Performance_ssessment_Jeong_woo_value(arg);
cout << arg << endl;
//10 출력
_Performance_ssessment_Jeong_woo_pointer(&arg);
cout << &arg << endl;
//24출력
수행평가 내용을 배껴적은 노트를 정우가 받았을 때
포인터 없이 노트에 배껴적어준 내용에다 수정하면 정우만 볼 수 있습니다
이렇게 출력했을 때 정우에게만 인자로 주어진 것만 변하고 원본은 그대로 남습니다
포인터로 주어진 페이지로 원본상의 내용을 찾아서 거기다 수정을 해주어야 정우는 물론이고 재혁이와 학진이까지 볼 수 있습니다
변수가 함수에 의해 값이 변경될 수 있습니다
이처럼 특정 변수나 객체의 값을 그대로 함수에 복사해주는것이 아닌
포인터로 위치만 넘겨주는 것을 참조에 의한 호출 (reference) 라고 합니다
참고영상 글
유튜브 얄팍한 코딩사전 - https://youtu.be/u65F4ECaKaY
메모리엔진 - https://www.site24x7.com/learn/java/heap-and-stack-memory-management.html
스택 내용 - https://gmlwjd9405.github.io/2018/08/03/data-structure-stack.html
힙 내용 - http://www.tcpschool.com/c/c_memory_structure
C 프로그래밍 #1
c언어 시작하기
c언어의 기본 구조
#include <stdio.h>
int main() {
}-
#include <stdio.h>
이 라인은 c언어의 표준 매크로 정의, 상수, 여러 형의 입출력 함수가 포함된 stdio.h라는 헤더 파일을 불러오는 코드입니다
-
int main() {}
이 라인은 main이라는 함수를 정의한다는 코드입니다.
실행될 코드들을 {} 안에 작성하면 됩니다
추후 자세히 다룰 내용입니다
printf() 함수
#include <stdio.h>
int main(){
printf("hello world!");
}
괄호 사이에 출력될 대상을 넣습니다
참고로 문자열을 출력할시 "" 를 사용해야합니다
; 는 세미콜론으로, 컴파일 오류가 나지 않도록 한 줄이 끝나면 붙여야합니다
변수 선언
int main(){
int result;
result = 100;
printf("%d",result);
}-
int result;
result 라는 변수를 선언하는 코드입니다
int 자료형의 변수로, int의 자료형을 가진 데이터만 이 변수에 들어올 수 있습니다
-
result = 100;
선언한 result 변수에 100의 값을 저장하라는 코드입니다
이 때 = 은 같다는 의미가 아닌, 대입연산자입니다
-
printf("%d",result);
"%d" 의 위치에 result 변수의 값을 출력시키는 코드입니다
이 코드를 실행시키면 100이라는 값이 출력됩니다
사용자 입력
변수에 직접 값을 입력 할 수 있습니다
scanf("%d",&a);scanf 함수를 사용하여 변수에 직접 입력값을 넣어줄 수 있습니다
산술연산자
일반 수학에서 사용하는 연산 부호를 사용할 수 있습니다
#include <stdio.h>
int main(){
int a,b,result;
scanf("%d",&a);
scanf("%d",&b);
result = a+b;
printf("%d + %d = %d\n",a,b,result);
result = 0;
result = a-b;
printf("%d - %d = %d\n",a,b,result);
result = 0;
result = a*b;
printf("%d x %d = %d\n",a,b,result);
result = 0;
result = a/b;
printf("%d / %d = %d\n",a,b,result);
result = 0;
}-
int a,b,result;
a, b, result 변수들을 선언해주었습니다
-
scanf("%d",&a);
콘솔창에서 사용자 입력을 받고 변수에 저장합니다
마찬가지로 다음 줄 또한 같습니다
-
+ 연산자
덧셈 연산자입니다
-
- 연산자
뺄셈 연산자입니다
-
* 연산
곱셈 연산자입니다
-
/ 연산
나눗셈 연산자입니다
정수형 변수이기 때문에 몫만 저장됩니다
부동소수점
int a = 123;
float b = 123.45;정수형 변수 a 와 실수형 변수 b를 선언하고 각각 123 과 123.45 값을 저장했습니다
printf("a의 값 =>%d\n",a);
printf("b의 값 =>%.2f\n",b);-
printf("a의 값 =>%d\n",a);
123을 출력합니다
-
printf("b의 값 =>%.2f\n",b);
123.45의 소수점 둘째자리까지 출력합니다
float 와 double 자료형
float c = 0.2345678912345678912345;
double d = 0.2345678912345678912345;
printf("%.25f\n",c);
printf("%.25f\n",d); double 자료형은 float 자료형보다 데이터를 담을 수 있는 공간이 더 많습니다
그렇기 때문에 저 코드를 실행하면 값이 각각 다르게 출력되며,
double 자료형인 d의 변수값만 제대로 출력됩니다
문자 자료형
char e, f, g;char 로 선언합니다
문자열과 달리 ' ' 안에 들어갑니다
문자를 아스키코드표에 따라 10진수 숫자로 저장합니다
그렇기때문에
e = 'E';
printf("%c\n", e);
printf("%d\n", e);정수와 문자 모두 출력이 가능합니다
C 프로그래밍 #2
문자열
#include <string.h>문자열 관련 함수를 사용하기 위해서 string.h 파일을 불러옵니다
char str1[10];
char str2[10];
char str3[10] = "CookBook";char str[문자열 배열] 로 문자열을 선언할 수 있습니다
- char str1[10]; 으로 길이가 10인 문자열 변수를 선언 할 수 있습니다
문자열 관련 함수
string.h 파일 안에는 문자열에 사용할 수 있는 함수들이 있습니다
strcpy(str1, "Basic-C"); strcpy(복사한 문자를 저장할 변수, 복사할 문자열) 로 사용할 수 있습니다
위 코드는 Basic-C 라는 문자열을 str1문자열에다 복사합니다
연산자
산술연산자
일반 산술식에서 사용하는 연산자를 그대로 사용할 수 있습니다
a = b + c; // 덧셈
printf("더하기 %d + %d = %d\n", b,c,a);
a = b - c; // 뺄셈
printf("빼기 %d - %d = %d\n", b,c,a);
a = b % c; // 나머지
printf("나머지 %d %% %d = %d\n", b,c,a); // %%에서 앞의 %는 탈출문자
a = b / c; // 나눗셈
printf("나누기 %d / %d = %d\n", b,c,a); // int끼리의 연산은 몫만 출력위와같은 연산자들이 있습니다
참고로 나눗셈 연산자를 사용할 때 나누는 수가 float 자료형이여야만 소수점까지 연산됩니다
증감연산자
변수의 값을 증가시키거나 감소시킬 수 있습니다
a++; // 1 증가
printf("a++ >> %d\n",a);
a = 10;
a--; // 1 감소
printf("a-- >> %d\n",a);
a = 10;
a+=5; // 5 증가
printf("a+=5 >> %d\n",a);
a = 10;
a*=5; // a = a*5;
printf("a*=5 >> %d\n",a);
a = 10;
a/=5; // a = a/5;
printf("a/=5 >> %d\n",a);
a = 10;
a%=5; // a = a%5;
printf("a/=5 >> %d\n",a);
a = 10;
a = 10; // b = a 를 수행시킨 후 a를 1 증가시킨다
b = a++;
printf("%d\n",b);
b = ++a; // a를 1 증가시킨 후 b = a를 수행함
printf("%d\n",b);= 앞에 연산자를 붙여 변수의 값을 증감시킬 수 있습니다
논리연산자
AND 연산
둘 다 참이여야 AND 연산의 결과가 참입니다
연산자는 &&을 사용합니다
OR 연산
둘 중 하나만 참이여야 OR 연산의 결과가 참입니다
연산자는 ||을 사용합니다
NOT 연산
반대의 결과로 바꿉니다
연산자는 !을 사용합니다
참이면 거짓, 거짓이면 참으로 바꿉니다
//논리연산자
a = 90;
printf("AND연산 : %d\n",(a>=100)&&(a<=200));
printf("OR연산 : %d\n",(a>=100)||(a<=200));
printf("NOT연산 : %d\n",!(a==100));
a = 100;
b = 200;
printf("상수의 AND연산 : %d\n",a&&b);
printf("상수의 OR연산 : %d\n",a||b);
printf("상수의 NOT연산 : %d\n",!a);
//0빼고 다 1임
출력결과 위와 같습니다
비트연산자
비트 논리곱
각 자리의 비트끼리 AND 연산을 합니다
각 자리의 값이 두 수 모두 1이여만 결과도 1입니다
printf("10 & 7 = %d\n",10 & 7); // 10과 7의 비트 논리곱(AND)을 수행
printf("123 & 456 = %d\n",123 & 456); // 123과 456의 비트 논리곱을 수행
연산자는 &를 사용합니다
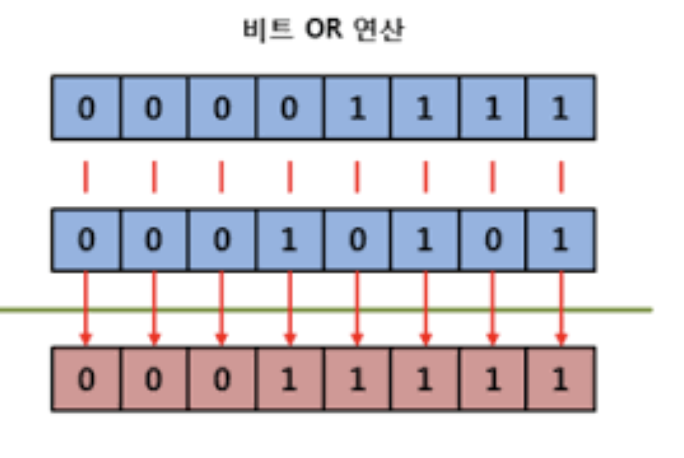
비트 논리합
각 자리의 비트끼리 OR 연산을 합니다
각 자리의 값 중 하나만 1이면 결과또한 1입니다
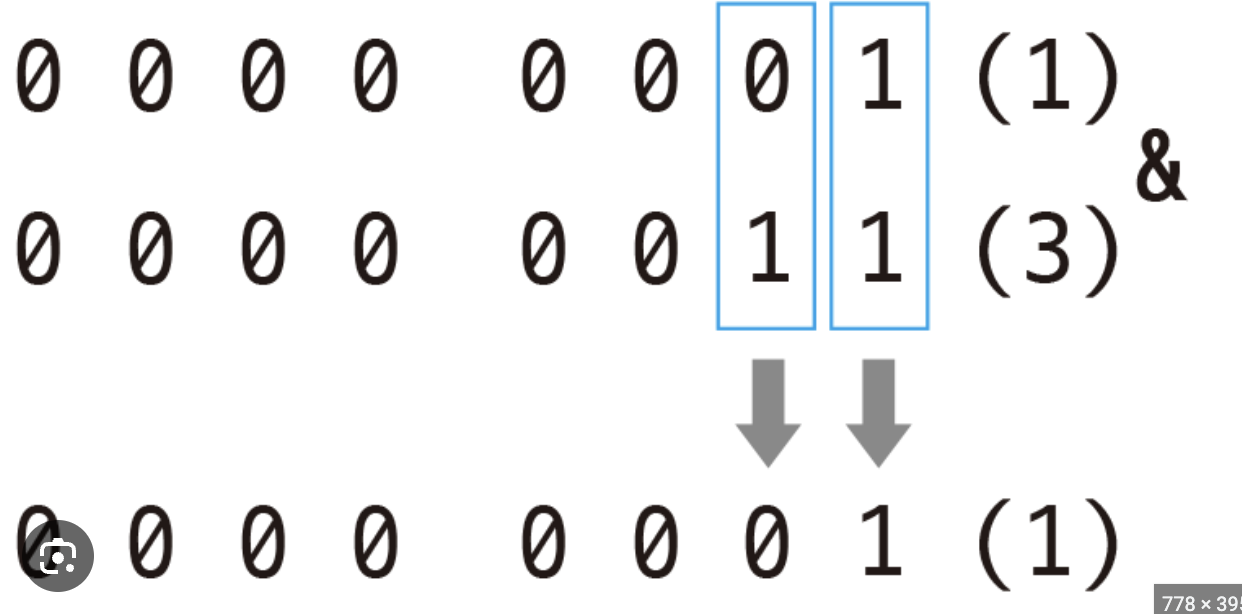
printf("10 | 7 = %d\n",10 | 7); // 10과 7의 비트 논리합(OR)을 수행
printf("123 | 456 = %d\n",123 | 456); // 123과 456의 비트 논리합을 수행연산자는 |를 사용합니다
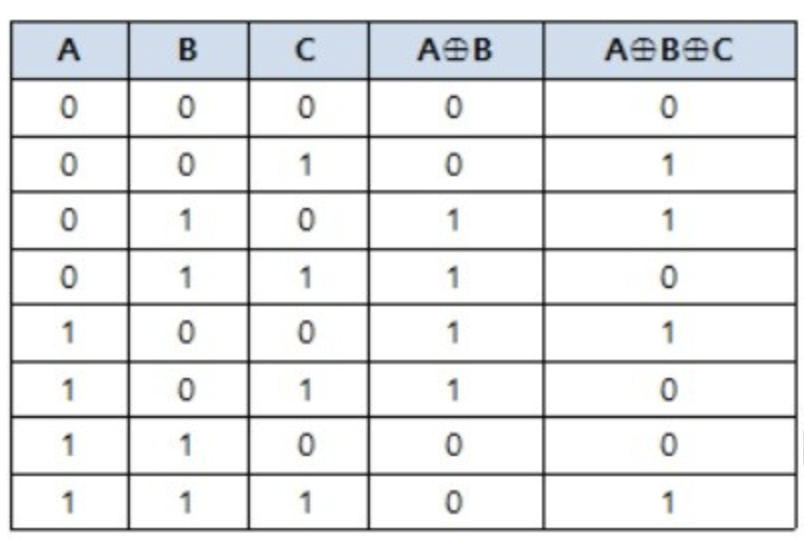
비트 배타적 논리합
각 비트끼리의 XOR 연산을 합니다
XOR 연산은 두 값 중 하나만 1일때 0을 출력합니다
왼쪽 비트 시프트 연산자
나열된 비트의 자리값을 왼쪽으로 이동시키는 연산자입니다
왼쪽으로 시프트를 할 때마다 2의 n승을 곱한 효과입니다
a = 10;
printf("%d를 왼쪽으로 1회 시프트하면 %d 이다\n",a,a << 1);
printf("%d를 왼쪽으로 2회 시프트하면 %d 이다\n",a,a << 2);
printf("%d를 왼쪽으로 3회 시프트하면 %d 이다\n",a,a << 3);오른쪽 비트 시프트 연산자
나열된 비트의 자리값을 오른쪽으로 이동시키는 연산자입니다
오른쪽으로 시프트를 할 때마다 2의 n승을 나눈 효과입니다
a = 10;
printf("%d를 오른쪽으로 1회 시프트하면 %d 이다\n",a,a >> 1);
printf("%d를 오른쪽으로 2회 시프트하면 %d 이다\n",a,a >> 2);
printf("%d를 오른쪽으로 3회 시프트하면 %d 이다\n",a,a >> 3);제어문
조건문
다음 코드의 실행 여부를 판단하는 문법입니다
if문
코드에 조건을 걸어 다음 코드가 실행될지 판단하는 문법입니다
a = 1;
if(a == 1){ //참
printf("%d",a)
}
() 안의 조건이 참이라면, 코드블럭 안에있는 값을 실행합니다
조건이 거짓이라면 코드를 실행하지 않고, 건너뜁니다
else if문
else if 를 사용하여 조건을 추가할 수 있습니다
a = 1;
if(a == 2 ){ //거짓
printf("%d",a)
}
else if (a == 1){ //참
printf("hello");
}마지막에 else를 사용하여 위의 조건들이 모두 참이 아닐경우 다음 코드 블럭을 실행시킵니다
a = 1;
if(a == 2 ){ //거짓
printf("%d",a)
}
else if (a == 7){ //거짓
printf("hello");
}
else{
printf("good");
}switch case 문
if문과 비슷한 역할을 하지만, 변수의 값에 따라 코드를 실행합니다
switch (변수)
{
case 변수의 값1:
실행시킬 코드
break;
case 변수의 값2:
실행시킬 코드
break;
default:
break;
}변수의 값이 무엇이 들어오는지에 따라 실행시키는 코드들이 달라집니다
break로 해당 switch 문을 탈출할 수 있습니다
default로 case에 해당하지 않는 값이 들어왔을때 처리할 수 있습니다
else와 비슷한 코드입니다
예시로 계산기 코드를 들어보겠습니다
#include <stdio.h>
int main() {
int a,b;
char ch;
while (1)
{
printf("계산할 두 수 입력 (멈추려면 컨트롤 c): ");
scanf("%d %d",&a,&b);
printf("계산할 연산자 입력 (멈추려면 컨트롤 c): ");
scanf(" %c",&ch,1);
switch (ch)
{
case '+':
printf("%d + %d = %d\n",a,b,a+b);
break;
case '-':
printf("%d - %d = %d\n",a,b,a-b);
break;
case '/':
printf("%d / %d = %.2f\n",a,b, a/(float)b);
break;
case '%':
printf("%d %% %d = %d\n",a,b,a%b);
break;
default:
printf("연산자 잘못 입력했음\n");
}
}
}연산자를 입력받아 연산을 진행하는 코드입니다
두 수를 입력받고 연산자를 입력받습니다
입력받은 연산자는 swich문에서 각 일치하는 케이스의 코드를 실행시킵니다
반복문
일정 코드를 반복수행하게 하는 문법입니다
for 반복문
반복해야하는 횟수가 정해져있을 때 주로 사용합니다
for(변수; 반복 조건; 변수값 변화량){
반복할 코드
}
for(int i = 0; i < 5;i++;){
printf("%d",i)
}for 반복문이 한번 반복 할 때 마다 i의 값이 1씩 증가하는 코드입니다
반복 조건이 i가 5보다 작다면 반복하기 때문에 i가 5이상이라면 반복을 멈춥니다
위 코드는 i의 값이 1씩 증가되며 반복되어 출력되기때문에 출력값은
0 1 2 3 4 가 될 것입니다
while 반복문
주로 조건에 따라 반복을 해야하는 상황에서 쓰이는 반복문 입니다
while(조건식){
반복할 코드;
}
이런 형식으로 작성됩니다
int flag = 1;
int a = 0;
while(flag == 1){
a ++;
if(a > 5){
flag = 0;
}
}초기 flag 값은 while문이 반복되면서 a의 값은 1씩 증가합니다
a의 값이 6이 되었을 때 조건문에 의하여 flag 값은 1에서 0으로 바뀝니다
while의 조건인 flag == 1 이 거짓이 되었기 때문에 반복을 종료합니다
-
참고로 c++의 헤더파일인 iostream이 아닌, stdio.h로 진행한다면
bool 자료형은 사용할 수 없습니다그렇기 때문에 0과 1로 참 거짓을 나타낼 수 있습니다
Do-while문
시작과 끝을 모를때 사용합니다
#include <stdio.h>
int main(){
int menu;
do {
printf("\n손님 주문하시겠습니까?");
printf("<1> 카페라떼 <2> 카푸치노 <3> 아메리카노 <4>그만 주문==>");
scanf("%d",&menu);
switch (menu)
{
case 1:
printf("카페라떼 주문하셨습니다");
break;
case 2:
printf("카푸치노 주문하셨습니다");
break;
case 3:
printf("아메리카노 주문하셨습니다");
break;
case 4:
printf("주문하신 커피 준비하겠습니다");
break;
default:
printf("잘못 주문하셨습니다");
break;
}
}
while (menu != 4); //입력값이 4면 종료
}예시로 카페 메뉴를 주문하는 코드를 들겠습니다
반복해서 입력을 받습니다
만약 입력값이 4이면 do while 문을 종료합니다
분기문
프로그램의 진행 여부를 결정해주는 코드입니다
break
반복을 멈추고 반복문을 탈출합니다
int sum = 0;
int num;
for( num =1; num++) {
sum += num;
if(sum >= 100) {
break;
}
}다음 for문은 종료조건 없이 무한반복하는 반복문입니다
하지만 sum의 값이 if문의 조건을 만족시켰을 때
break문을 만나 반복을 종료합니다
continue
break와 반대로 코드를 계속 진행시킵니다
return
프로그램이나 함수를 종료하거나 값을 반환하는 return이 있습니다
함수 단원에서 자세히 다룰 예정입니다
배열
배열은 여러 데이터를 연속적으로 저장할 수 있는 자료 구조입니다
배열의 선언
배열에 들어올 데이터의 자료형 배열 이름[배열의 크기];
int a[100];C 프로그래밍 #3
함수
함수는 특정한 역할을 하는 코드들을 독립적으로 모아둔 집합체입니다
함수를 사용했을 시 유지보수가 간편해지며 코드의 가독성이 좋아집니다
함수는
반환형 함수이름(매개변수){
실행할 코드
return 반환값; (반환값이 없으면 없어도 됨)
}
이런 형태로 생겼습니다
int Add(int n1, int n2){
return n1 + n2;
}정수를 반환하는 함수입니다
n1과 n2 자리에 값들을 전달받아 n1과 n2를 더한 값을 반환합니다
void Add2(int n1, int n2){
printf("연산 결과 : %d\n",n1+n2);
}void를 사용하여 반환값이 없는 함수를 선언할 수 있습니다
함수의 범위
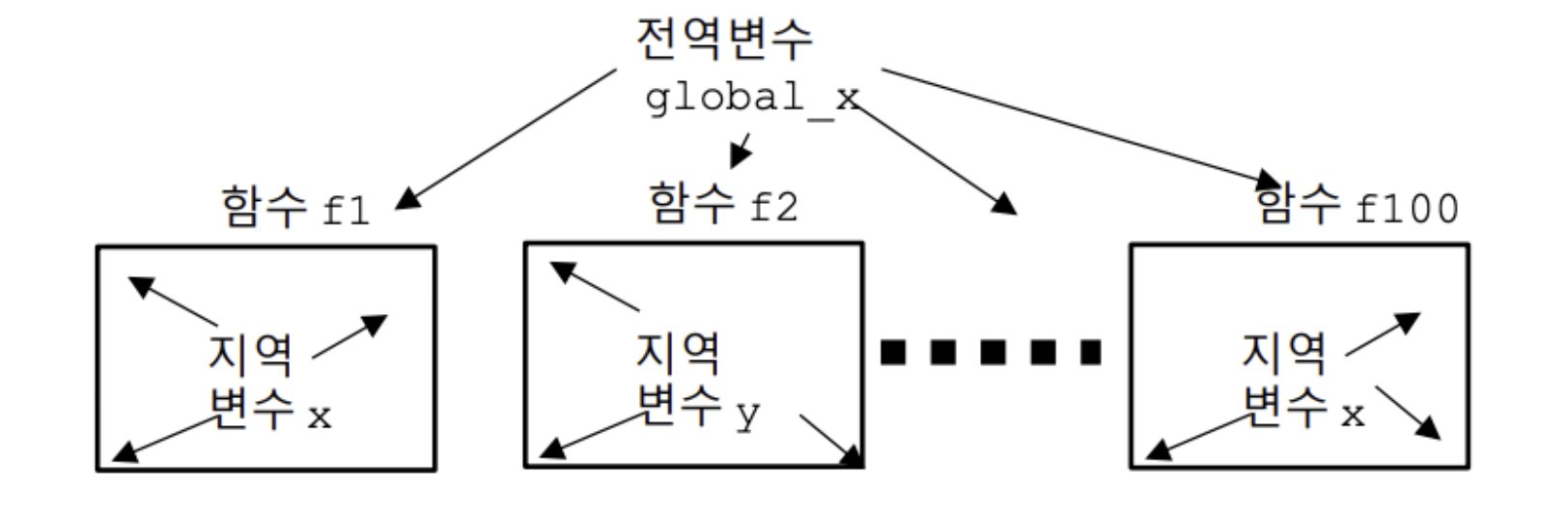
지역 변수
블록 내부에서 선언된 변수로 블록 내부에서만 유효하고 블록이 끝나면 해제됩니다
지역 내부에 새로운 지역에서 같은 이름의 변수가 선언되면
외부에 있는 변수보다 내부에 있는 변수가 더 높은 우선순의를 가지게 됩니다
전역 변수
함수 외부에서 선언된 변수로 프로그램이 종료될 때 해제됩니다
전역변수는 별도의 초기화를 진행하지 않으면 0으로 초기화 됩니다
전역변수와 지역변수의 이름이 같다면 해당 지역에 선언된 지역변수가 더 높은 우선순의를 가집니다
정적 변수
전역 변수와 지역변수의 특성을 둘 다 가지고 있습니다
전역변수의 특성인 프로그램이 종료될 때 메모리의 공간이 해제된다는 특성을 가지고 있습니다
지역변수의 특성인 블록 내부에서만 유효하다는 특성을 갖고있습니다
(정적변수 선언 원형 : static 자료형 변수명;)
포인터
C언어의 꽃이자 가장 중요한 내용입니다
변수는 선언될 때 메모리에 저장되는 위치값을 가집니다
그 때 위치값을 주소 라고 부릅니다
포인터는 변수의 주소를 저장하는 변수입니다
포인터변수는 다음과 같은 형식으로 선언할 수 있습니다
저장한 공간의 자료형* 변수명
int num = 5;
int* ptr; // int* - int 자료형을 가진 공간의 주소정수형 변수 num을 선언하고 5로 초기화 해주었습니다
그리고 ptr 이라는 포인터 변수를 선언해주었습니다
(* : 애스털리스크라고 읽으며, 주소에 해당하는 변수의 값을 참조하는 역할을 합니다)
ptr = #그 후 ptr에 num의 주소값을 저장해주었습니다
(& : 앰퍼센드라고 읽으며, 메모리에서의 주소를 나타냅니다)
printf("(&num의 값 출력)num의 주소 : %p\n",&num);
&num을 출력해본다면

5가 아닌 num의 메모리 주소가 출력됩니다
printf("num의 주소 : %p\n",ptr);ptr변수에 저장된 값 또한 출력했을시 동일하게 주소값이 출력됩니다
#include <stdio.h>
int main(){
int a = 0;
int* ptr;
ptr = &a;
printf("입력 : ");
scanf("%d",ptr);
printf("출력 : %d", a);
return 0;
}이렇게 scanf에서 포인터 변수로 사용할 수 있습니다
포인터 변수는 다양하게 사용합니다
메모리 동적 할당
메모리를 사용하는 부분만 빌려와 사용한 후, 다시 반납하는 방법입니다
메모리를 효율적으로 관리할 수 있습니다
*메모리 사용이 끝난다면 꼭 해제를 해주어야 합니다
#include <stdlib.h>
#include <malloc>둘 중 하나를 사용하여 메모리를 동적으로 할당할 수 있게 해주는 함수들을 불러옵니다
int* p;
p = (int*)malloc(sizeof(int));
*p = 100
printf("%d",*p);
free(p);
포인터 변수 p를 선언하고, int자료형 (4바이트) 만큼 할당하라는 코드입니다
free() 함수로 할당된 메모리를 운영체제에 반납해주어야합니다
#include <stdio.h>
#include <stdlib.h>
int main(){
int p,*s;
int i,j;
print("malloc함수 사용\n");
p = (int*)malloc(sizeof(int)*3);
for(i=0;i<3;i++){
printf("할당된 곳의 초기값 p[%d] >> %d\n",i,s[i]);
}
free(p);
printf("\ncalloc함수 사용\n");
s = (int*)calloc(p,sizeof(int)*3);
for(i=0;i<3;i++){
print("할당된 곳의 초기값 s[%d] >> %d\n",i,s[i]);
}
free(p);
}malloc 함수와 calloc 함수의 예제입니다
배열에서 사용한다면 필요한 배열의 메모리만큼 사용되기 때문에 효율적으로 관리 할 수 있습니다
int main() {
char* p[3];
char temp[100];
int i, size;
for(i = 0; i < 3; i++) {
printf("%d 번째 문자열:", i + 1);
fgets(temp, sizeof(temp), stdin); // 입력한 문자열을 입력받는다
size = strlen(temp); // 입력한 문자열의 길이를 계산한다
p[i] = (char*) malloc(sizeof(char) * (size + 1)); //입력한 길이 + 1 (널문자)의 크기의 메모리를 확보한다
strcpy(p[i], temp); //입력한 문자열 temp의 내용을 메모리를 확보한 공간에 복사한다
}
printf("\n입력과 반대로 출력(포인터)\n");
for(i = 2; i >= 0; i--) {
printf("%d : %s\n", i + 1, p[i]); //포인터 배열에 저장된 문자열을 출력한다
}
for(i = 0; i < 3; i++) {
free(p[i]); //할당된 메모리 3개를 운영체제에 반납한다
}
}메모리를 동적으로 할당하여 문자열을 반대로 출력하는 코드입니다
TCP/IP 프로그래밍에서 심도있게 다룰 예정입니다
구조체
구조체는 여러개의 변수들을 한 블럭에 묶어 조금 더 쉽게 사용하도록 해주는 도구입니다
타입스크립트의 오브젝트와 유사하다고 할 수 있겠지만, 전혀 다른 것이니 유의해야합니다
struct book //
{
int a;
float b;
char c;
char d[5];
};구조체 변수 b1을선언합니다 (실제 저장공간을 확보함)
그 후 각각 서로다른 자료형의 변수들을 선언해줍니다
struct book b1;
구조체 변수의 멤버 변숫값을 대입합니다
b1.a = 10;
b1.b = 1.1f;
b1.c = 'A';
printf("b1.a >> %d\n",b1.a);
printf("b1.b >> %f\n",b1.b);
printf("b1.c >> %c\n",b1.c);
printf("b1.d >> %s\n",b1.d);그 후 구조체이름.변수이름 으로 변수를 사용할 수 있습니다
int main(){
struct student {
char name[10];
int kor;
int eng;
float avg;
};
struct student s;
printf("이름 : ");
scanf("%s",&s.name,9);
printf("국어 점수 : ");
scanf("%d",&s.kor);
printf("영어 점수 : ");
scanf("%d",&s.eng);
s.avg = (s.kor + s.eng) / 2.0f;
printf("학생이름 : %s\n",s.name);
printf("국어 점수 : %d\n",s.kor);
printf("영어 점수 : %d\n",s.eng);
printf("평균 점수 : %.1f\n",s.avg);
}위 코드는 학생 정보를 관리하는 구조체를 만드는 코드입니다
구조체 포인터
구조체에서 포인터를 사용할 수 있습니다
포인터의 개념과 구조체의 개념을 알고있다면 쉽게 이해할 수 있습니다
이 때 . (도트 연산자) 대신 -> (화살표 연산자) 를 사용하여 포인터 변수에 접근할 수 있습니다
#include <stdio.h>
int main(){
struct student
{
char name[10];
int kor;
int eng;
float avg;
};
struct student s;
struct student* p;
p = &s; //포인터 p에 s의 주소를 대입한다
printf("이름 : ");
scanf("%s",p->name,9);
printf("국어 점수 : ");
scanf("%d",&p->kor);
printf("영어 점수 : ");
scanf("%d",&p->eng);
p->avg = (p->kor + p->eng) / 2.0f;
printf("학생이름 : %s\n",p->name);
printf("국어 점수 : %d\n",p->kor);
printf("영어 점수 : %d\n",p->eng);
printf("평균 점수 : %.1f\n",p->avg);
}공용체
union student2{
int tot;
char grade;
};
union student2 u;
u.grade = 'A';
u.tot = 300;
printf("총점 >> %d\n",u.tot);
printf("등급 >> %c\n",u.grade); 공용체는 구조체와 유사하지만, 메모리 공간을 공유합니다
따라서 위 코드는 나중에 들어간 값만 먼저 출력됩니다
열거형
열거형은 서로 연관된 상수들을 그룹화하여 정의하는 데이터 형식입니다
열거형은 프로그램에서 사용되는 명칭을 간결하고 의미있게 표현할 수 있는 장점이 있습니다.
enum week{sun,min,tus,wed,thu,fri,sat};
enum week ww;
ww = sat;
if(ww == sun){
printf("오늘은 일요일입니다\n",ww);
}
else{
printf("오늘은 일요일이 아닙니다\n",ww);
}
}Network
네트워크란?
-
무언갈 연결하는 것
-
한 장비에서 다른 장비를 연결해서 정보나 자료, 자원의 공유가 편해졌습니다
Network : 길
H/W, S/W : 교통수단
Network의 핵심키워드 : 연결성 (유/무선 모두 포함)
네트워크의 시작점 : 전쟁
빠른 군사 정보를 공유할 목적으로 통신이 발전됐습니다
최초의 인터넷 : 미국방성과 4개의 대락과 연결 패킷교환을 성공한 알파넷
연결된 네트워크간에는 서로 동일한 프로토콜 (protocol)을 사용합니다
한번에 하나의 프로토콜만 사용합니다
인터넷 (Internet)
-
전세계의 수많은 WAN와 LAN이 연결된 거대한 네트워크
-
정보를 공유하기 위한 통신망의 집합체
인터넷을 하기 위해선 '웹브라우저'를 사용합니다
ex) www.naver.com
인터넷을 하려면 'IP'주소라는 것이 필요합니다
인터넷 초창기에는 IP주소를 외워서 사용했습니다
인터넷을 하는 과정
네트워크 설정에 등록된 DNS Server에 도메인 이름을 질의합니다
그 후 DNS Server는 보유하고 있는 (타 서버에서 제공받은) IP 주소를 제공합니다
Client 는 제공받은 IP를 갖고 수많은 장비를 경유해서 서버에 서비스 요청합니다
서버는 정상적인 요청인지 확인 후 서비스를 제공합니다
DNS (Domain Name System)
도메인의 이름체계
ex) www.11st.co.kr.
-
" . " (Root Domain)
최상위 도메인
모든 도메인의 이름 시작
모든 도메인에 공통적으로 들어가 생략합니다
전 세계에 13대의 Root DNS server가 존재합니다
(미국10대, 노르웨이, 네덜란드, 일본)
-
" co.kr " (Top Level Domain)
서비스 기관의 속성
국가의 속성을 의미합니다 (필요에 따라 사용하지 않기도 합니다)
.com, .edu, .org 등... 이 있습니다
-
" 11st " (Second Level Domain)
서비스(회사) 의 이름
이 이름만 알면 도메인을 사용할 수 있습니다
-
" www " (Host Name)
서비스 하는 서버의 이름 (사전적 의미)
서비스의 종류를 의미합니다
인트라넷 (Intranet)
-
회사에서 쓰는 여러 가지 프로그램들을 마치 인터넷을 사용하는 것 처럼
쓰도록 만들어 놓은 것 (내부의 네트워크)
-
인트라넷 역시 TCP/IP 프로토콜을 사용하고 웹 브라우저를 이용해
마치 인터넷을 사용하듯이 사내 업무를 처리할 수 있습니다
엑스트라넷 (Extranet)
-
기업의 인트라넷을 그 기업의 종업원 이외에도 협력 회사나 고객에게
사용할수있도록한것
Network 분류
구성범위에 따른 네트워크 분류
-
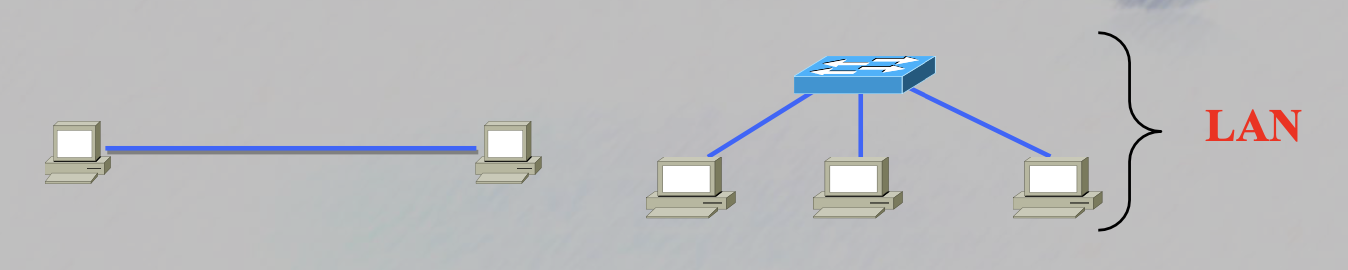
LAN (Local Area Network)
-
WAN (Wide Area Network)
LAN
근거리 통신망
한정된 좁은 지역에 구성된 네트워크
LAN 구성 장비로는 Switch(Bridge), HUB 등이 있습니다
WAN
원거리 통신망
넓은 지역을 연결하는 네트워크 , 서로 멀리 떨어진 곳을 네트워크로 연결 하는 것입니다
관리는 ISP 업체가 담당합니다
WAN 구성 장비로는 Router가 있습니다
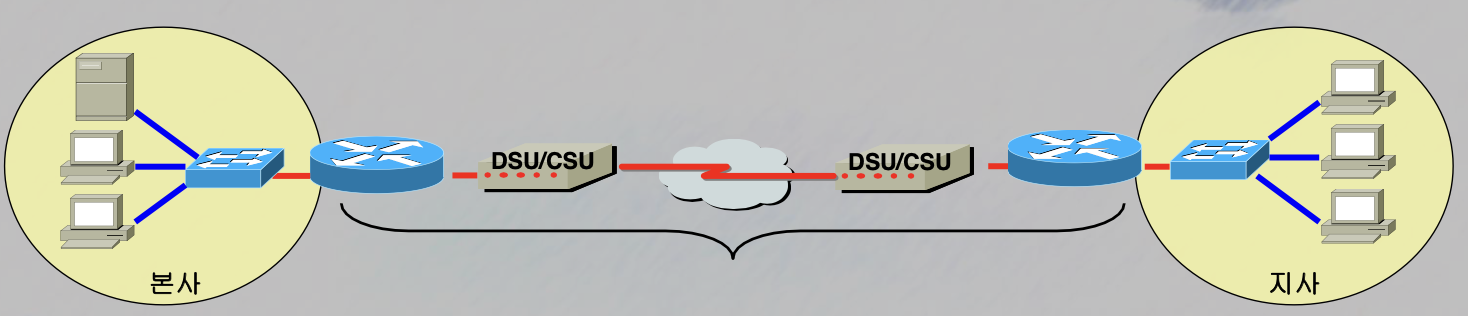
참
DSU / CSU (증폭 변조장치)
증폭시키는 이유
멀리 보내기 위해 (멀리 갈수록 세기가 약해지기때문에)
변조시키는 이유
컴퓨터는 디지털신호이지만, 전기 신호는 아날로그 신호이기 때문에
isp 업체(통신사)가 담당합니다
네트워크를 만드는 방법
이더넷 (Ethernet)
우리나라에서 사용하고 있는 네트워킹 방식의 거의 90% 이상이 이더넷 방식입니다
“대충 알아서 눈치로 통신하자” 라는 개념
CSMA / CD
(Carrier Sense Multiple Access / Collision Detection)
-
CS (Carrier Sense)
이더넷 환경에서 통신을 원하는 PC가 네트워크상에 통신이 일어나고 있는지 확인하는 것
-
MA (Multiple Access)
네트워크 상에서 두 개 이상의 PC나 서버가 동시에 네트워크 상에 데이터를 실어 보내는 경우 -
CD (Collision Detection)
두 개의 장비들이 데이터를 동시에 보내려 다 부딪치는 경우를 Collision이라 합니다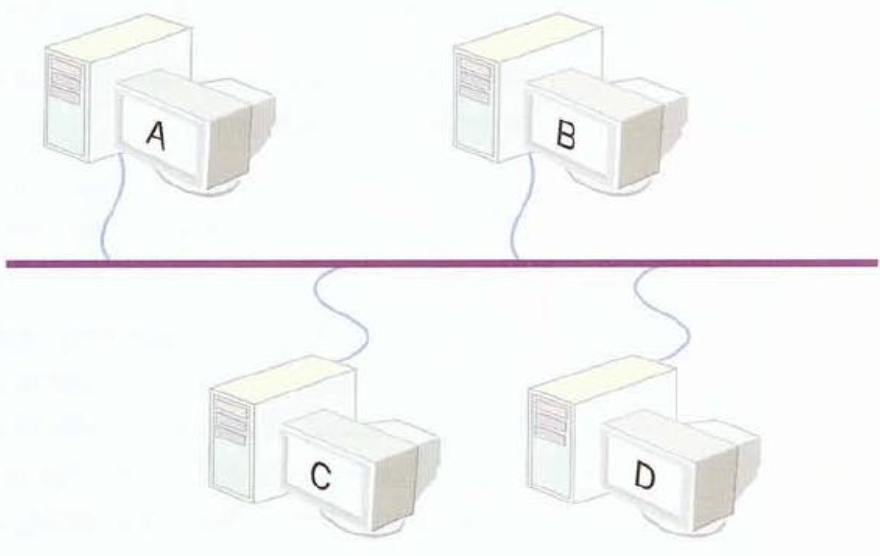
토큰링
옆으로 전달하는 방식으로 통신이 이루어짐
한 네트워크 상에서 오직 토큰을 가진 한 pc, 이 네트워크 에데이터를 실어보낼 수 있습니다
데이터를 다 보내고 나면 바로 옆 pc에게 토큰을 건네주는 방식
토큰을 가지고 있는 pc가 전송할 데이터가 없다면 토큰을 다시 옆 pc에게 전달합니다
충돌이 발생하지 않음 (토큰을 가지고있는 컴퓨터만 데이터를 전송하니까)
but 토큰이 돌아올때까지 기다려야하기 때문에 느릴수도있다
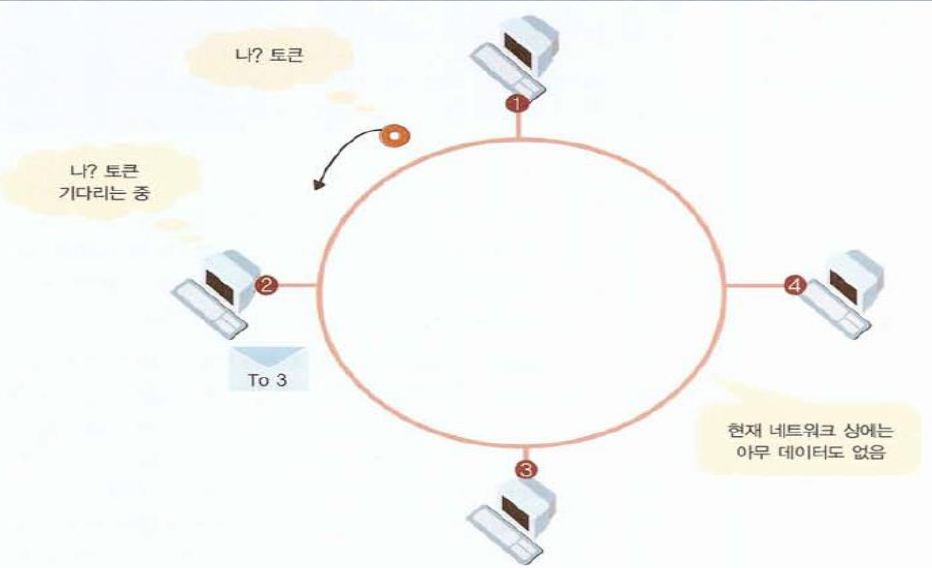
네트워크의 주소체계
-
MAC address (물리적 주소)
-
IP address (논리적 주소)
각 장비들은 정확한 통신을 위해 네트워크 상에서 서로 구분 해야합니다
-
이 역할을 하는 것이 바로 MAC(Media Access Control) address
-
TCP/IP Protocol을 사용하는 네트워크 (ex. Internet) 에서는 IP address를 사용하여 통신
하지만 최종적으로 MAC address를 사용하여 데이터를 전달
-
네트워크 장비의 인터페이스는 고유의 MAC address를 가지고 있습니다
(ex. NIC 카드, Router, Switch 등)
MAC address
Media Access Control
-
네트워크에 연결된 장비들이 가지는 48bit(6 Octet)의 고유한 주소
(전 세계에서 유일한 주소이다.)
-
Physical address, 즉 물리적 주소라고 부릅니다
-
이진수로 48bit인 주소이지만 16진수로 표현
-
이진수 4개를 묶어 16진수 한 자리로 표현합니다
즉, 16진수 12자리로 MAC address를 표현
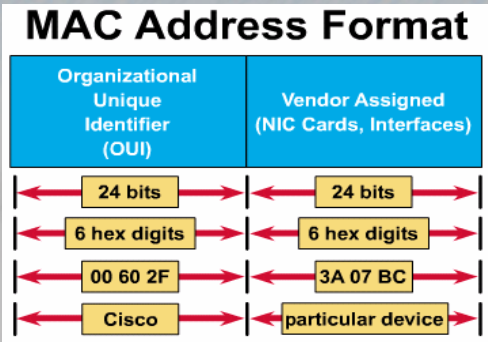
앞의 24bits (6개의 16진수)는 생산자(생산 회사)를 나타내는 코드로 OUI라고 합니다
OUI를 보면 어느 회사(메이커) 에서 생산했는지 알 수 있습니다
뒤의 24bits는 회사에서 각 장비에 분배하는 Host identifier 즉, 시리얼 넘버입니다
IP address
Internet Protocol
이진수 32비트로 구성된 주소체계
8bit씩4octet로구분,각octet을10진수로변환해서 표현합니다
- Logical address(논리적 주소)라고 부릅니다
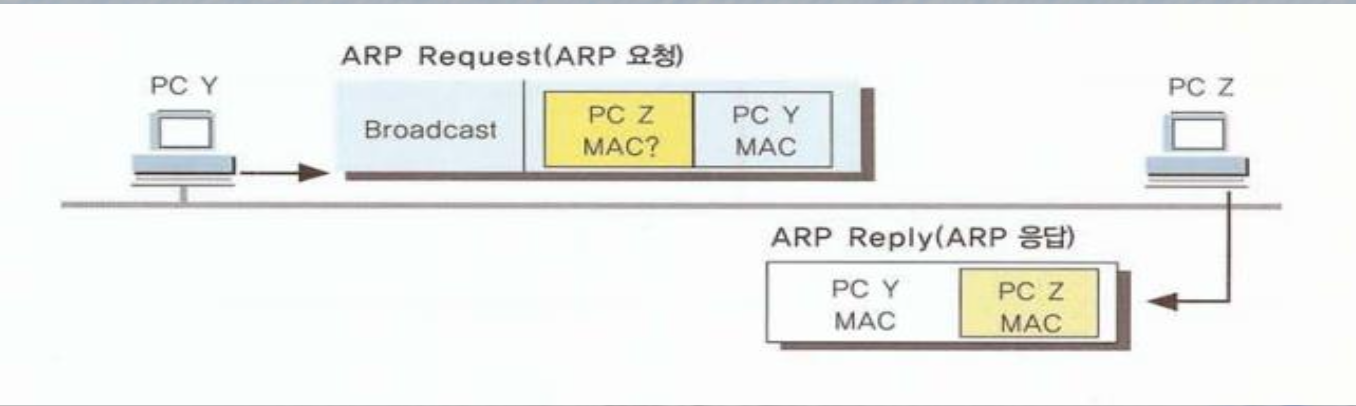
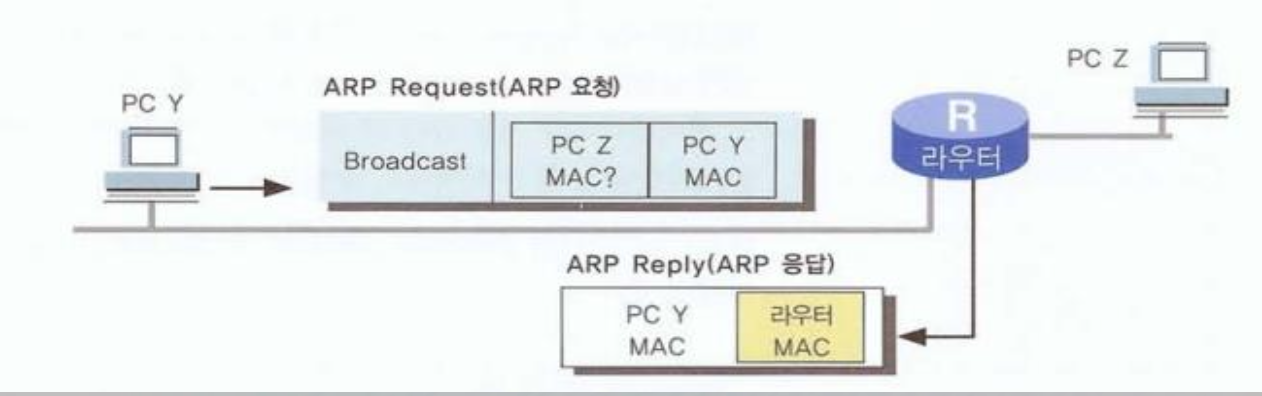
ARP
Address Resolution Protocol
일반적으로 IP 주소만을 보기 때문에 IP주소로만 통신을 한다고 생각하지만d
IP 와 MAC을 하나로 묶는(바인딩) 절차
ex) 스마트폰의 개통
IP 주소와 MAC 주소를 서로 매핑하는 절차를 ARP라고 합니다
통신방식에 따른 네트워크 분류
유니캐스트 (Unicast)
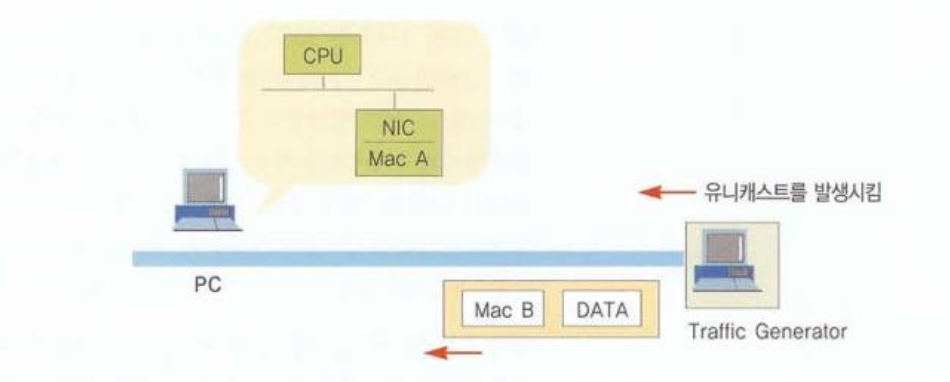
수신측이 한 곳으로 정해져있는 경우
즉, 정확한 특정 목적지의 주소 하나만 가지고 일 대 일로 전달하는 방식
ex) 일대일 카카오톡, 편지
유니캐스트 통신 방식은 그 목적지 주소가 아닌 다른 PC들의 CPU 성능을
저하시키지는 않습니다
브로드캐스트 (Broadcast)
일 대 전체 (제한된 불특정 다수) 전달 방식
제한된 범위
-
같은 네트워크
-
같은 망
-
하나의 브로드캐스트 도메인
불특정 다수에게 전부 전송하는 경우
-
Destination IP address : 255.255.255.255
-
Destination MAC address : FF-FF-FF-FF-FF-FF
동일 Network에 연결된 모든 네트워크 장비에게 보내는 통신
(즉, Broadcast Domain안의 모든 장비들에게 전송)
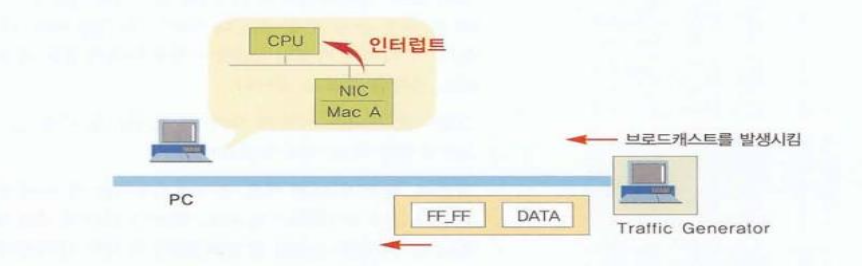
브로드캐스트 주소가 오면 PC의 랜카드는 자신의 MAC 주소가 같지 않아도
이 브로드캐스트 패킷을 CPU로 보내게 된다
그래서 과도한 브로드캐스트는 전체 네트워크 성능뿐 아니라,
PC 자체의 성능을 하락시킨다
멀티케스트 (Multicast)
일 대 그룹(대상이 명확한 집단 / 대상이 정해진 집단) 전송방식
정해진 특정 그룹으로 전송하는 경우
-
Destination IP address : 224.0.0.5
-
Destination MAC address : 01-00-5E-00-00-02
특정 다수에게 전송하는 방식
라우터나 스위치에 이 기능을 지원해주어야만, 사용이 가능하다
ARP (Address Resolution Protocol)
네트워크 상에서 IP 주소를 물리적 네트워크 주소로 대응(bind)시키기 위해 사용되는 프로토콜
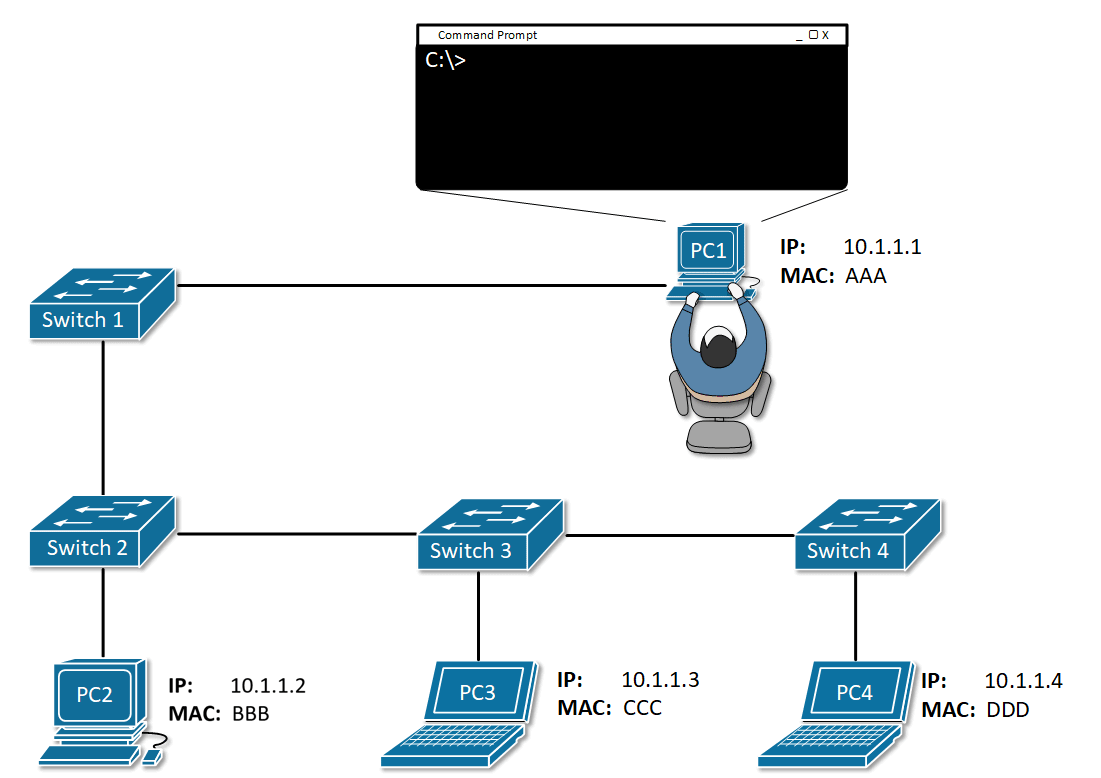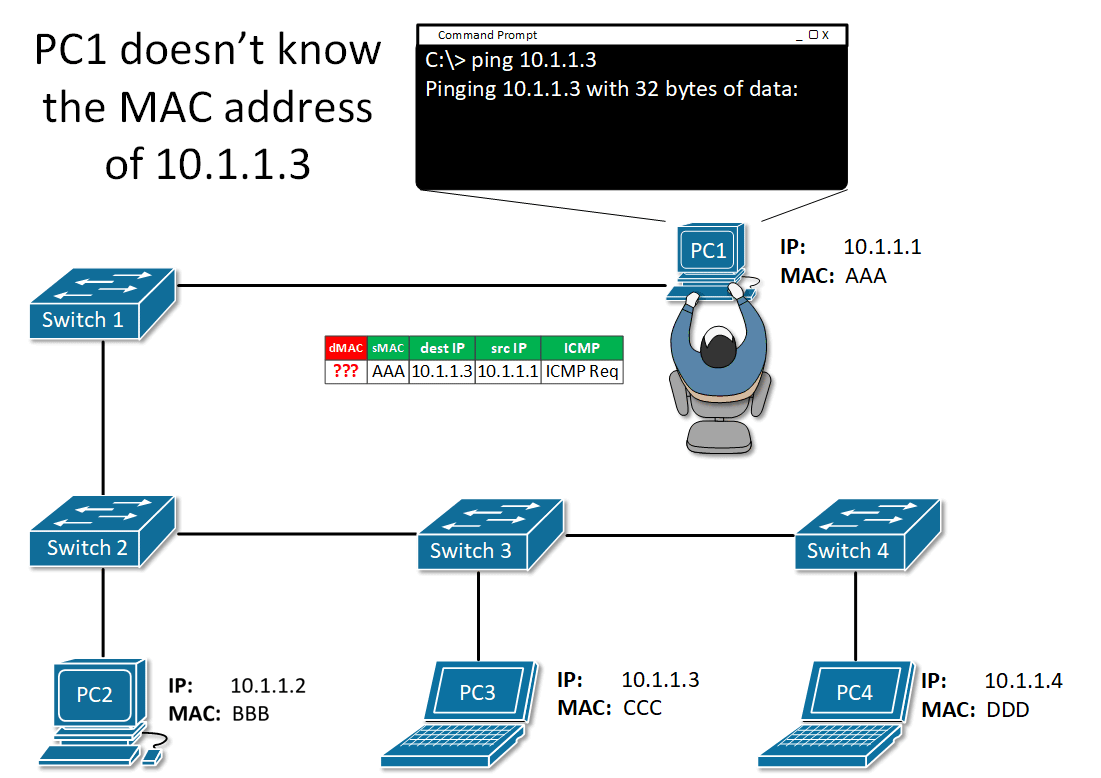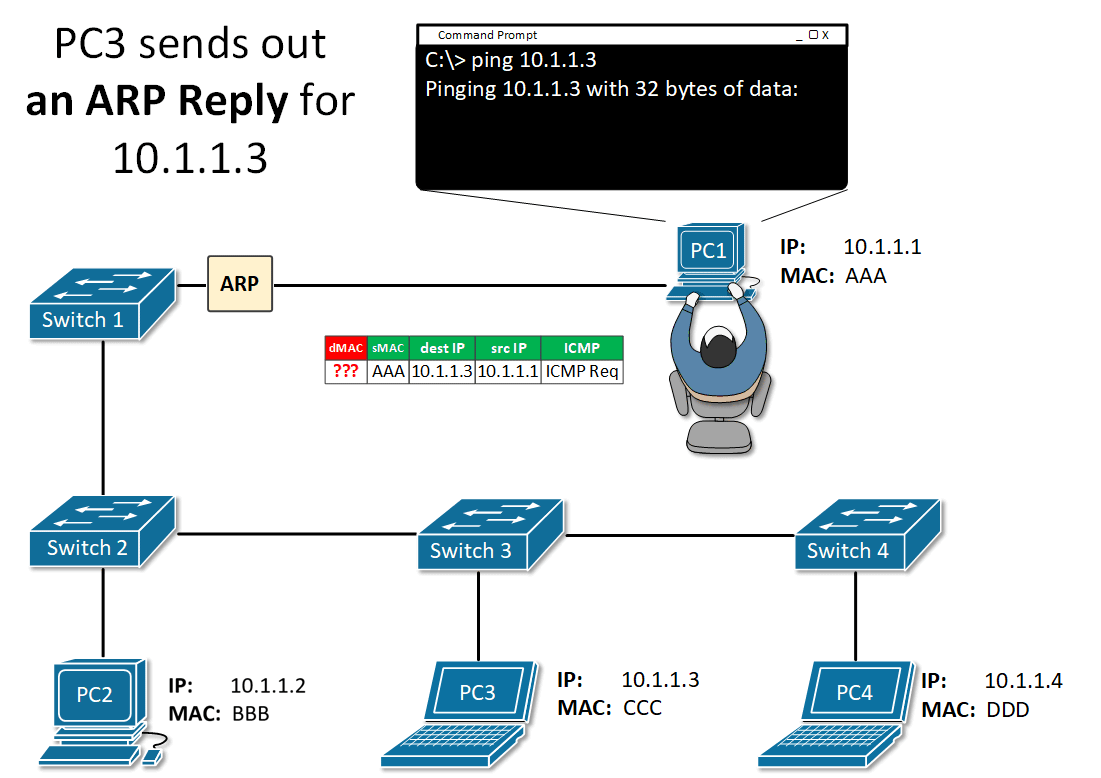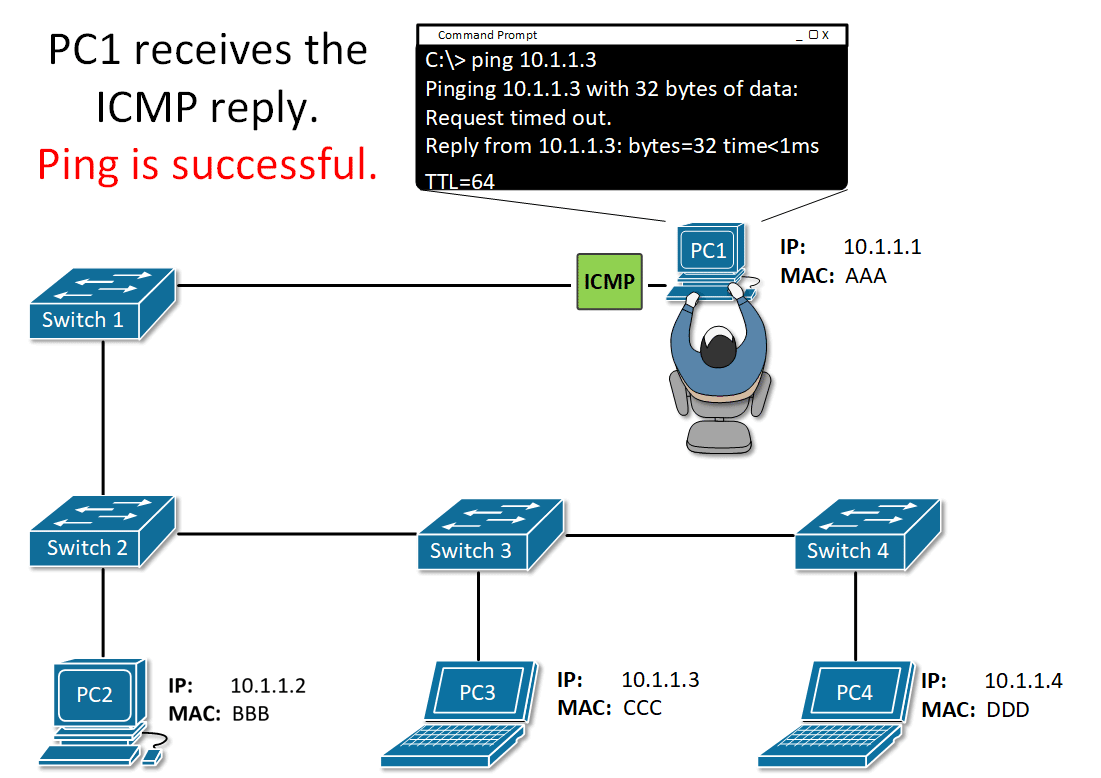
실습
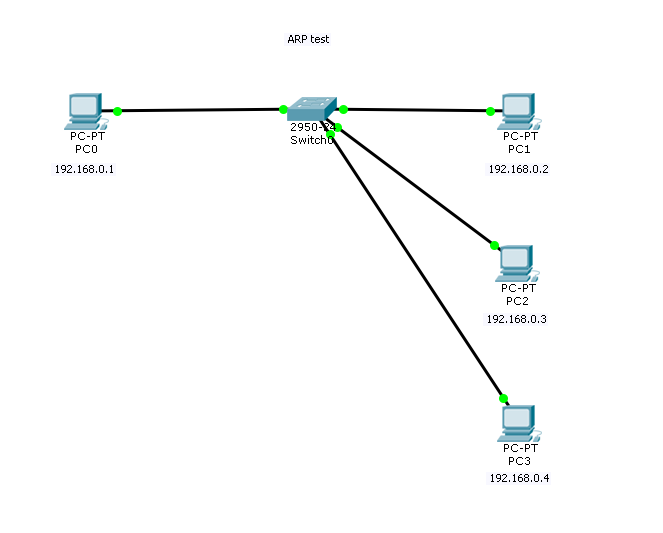
ARP 실습

ip 설정
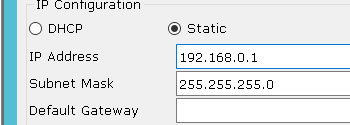
ip 주소를 입력하면 서브넷 마스크가 자동으로 채워짐
메모에 있는대로 PC3번까지 아이피를 입력해줌

프로토콜
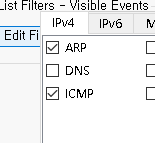
ARP와 ICMP만 설정

ICMP ( Internet Control Message Protocol)
ip는 신뢰성를 제공하지 않는 프로토콜임
그래서 icmp를 통해서 목적지 주소의 상태 여부를 확인 할 수 있음
회신된 상태 메세지에 따라서 통신 여부를 확인할 수 있음
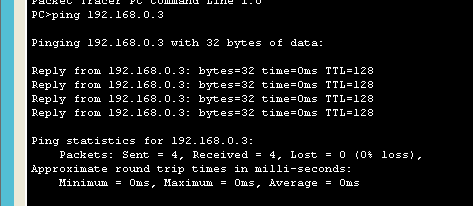
ping 이라는 유틸리티를 이용하여 icmp 를 사용할 수 있음

pc0에 커맨드 프롬프트를 열고
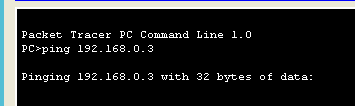
이렇게 입력해주면
메세지가 생성됨
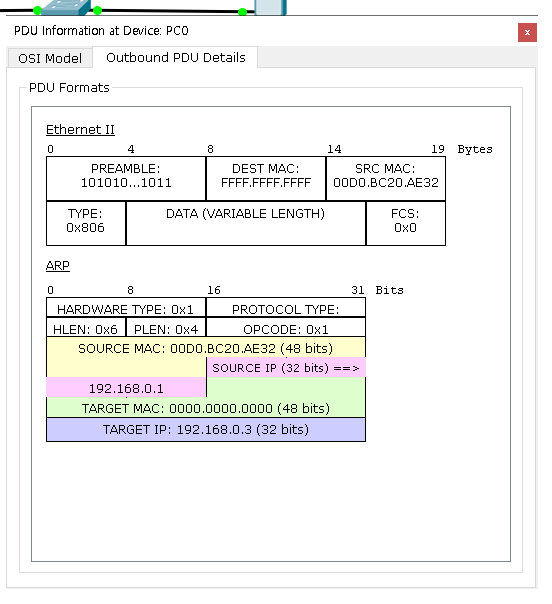
ARP 메시지의 정보에서 Outbound PDU Detailes로 가면
주고받는 데이터의 정보를 확인할 수 있음
캡쳐 포워드를 누름


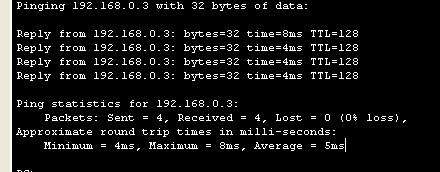
더이상 눌리지 않을때 까지 누르고 확인함
총 4번이 전송된것을 확인할 수 있음
회산된 TTL 값으로 알 수 있는 정보 2가지
-
운영체제 : window -128 / linux -64
-
라우터를 1대 경유할때마다 1씩 차감됨
(단, 공유기 / 보안처리된 라우터는 포함 안됨)
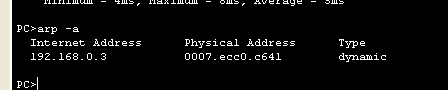
arp - a는 arp목록을 보여줌
ARP 특징
-
Dynamic 은 메모리에 저장됨
-
Rebooting 시 소멸됨
-
저장수명시간은 300초 (운영체제마다 상이함)
-

dynamic에서 static으로 바꾸는 법
apr -s 192.168.0.2 aaaa.bbbb.cccc
영구 보존은 가능하지만, 커널메모리에 저장되고, 어디에 저장되는지 알 수 없음
static의 단점
- 장비가 교체되면 통신 거부가 일어남
컴퓨터가 교체되면
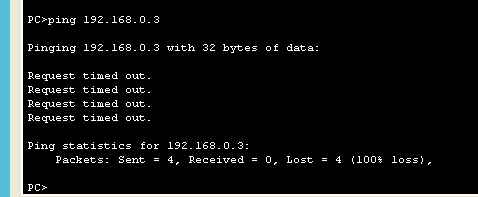
요청시간 초과가 나옴
arp -d 192.168.0.3 으로 수동 초기화 해주면 해결 가능
패킷 트레이서는 위 기능을 지원하지 않기 때문에 재부팅을 해주어야함
정리
arp 재설정 방법
-
재설정 시간을 기다린다
-
arp -d 명령어로 수동 초기화 해준다
-
재부팅
네트워크 프로토콜
-
서로 다른 네트워크가 통신을 하기 위한 언어 혹은 약속
-
네트워크 상에는 많은 규칙이 존재하는데 서로 연결된 네트워크는 같은 규칙을 사용해야 함
대표적인 네트워크 protocol로 인터넷 환경에서 데이터를 전송하는 TCP/IP가 있음
- 통신을 하는데 있어 약속 사항은 전부 통신 protocol (논리적, 물리적인 부분을 모두 포함)
OSI 7 Layer
국제 표준화 기구(ISO)가 1984년에 발표한 OSI 7 Layer는
통신이 일어나는 과정을 7단계로 구분해서
한눈에 들어올 수 있도록 보여줌
-
컴퓨터 통신 구조의 모델과 앞으로 개발될
프로토콜의 표준적인 뼈대를 제공하기 위해서
개발된 참조 모델
OSI 7 Layer 모델
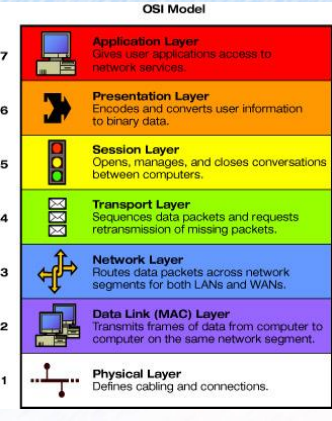
순서가 중요함 (피데네트세프에 로 외우자)
장점
-
데이터의 흐름이 한 눈에 보임
-
Trouble shooting이 쉬움
-
네트워크 동작 과정을 쉽게 습득할 수 있음
-
표준 모델이기 때문에 여러 회사 장비를 사용가능
1계층 : Phtsical Layer (물리 계층)
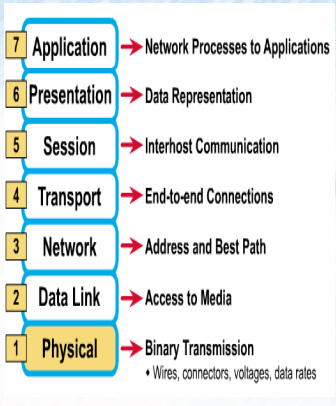
-
네트워크 통신을 위한 물리적인 표준 정의
-
물리적인 표준정의
-
두 장치간의 기계적인 그리고 절차적인 연결을 정의 하는 계층
-
케이블의 종류, 커넥터, 신호의 세기(전기, 전압 등...)
-
계층 통신단위 : 비트
-
계층 장비 : 리피터, 허브
-
리피터 : 증폭, 연장
-
허브 : 증폭, 연장, 멀티 포트
-
2계층 : Data link Layer (데이터 링크 계층)
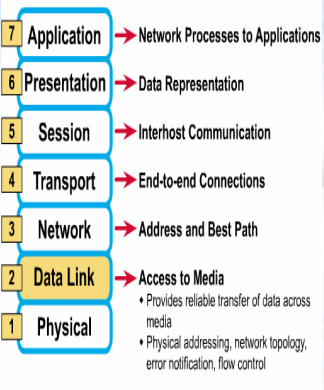
-
논리적인 개통구간
-
물리적 계층을 통한 데이터 전송에 신뢰성을 제공
-
프레임을 안전하게 전송하는 것을 목적으로 함
-
계층 통신 단위 : 프레임
-
계층 장비 : 스위치, 브릿지
-
계층 주소 : Mac
피지컬 레이어를 통해 송수신되는 정보의 오류와
흐름을 관리하여
안전한 정보의 전달을 수행할 수 있도록 도와주는 역할
통신의 오류도 찾아주고 재전송도 하는 기능을 가지고 있음
3계층 : Network (네트워크 계층)
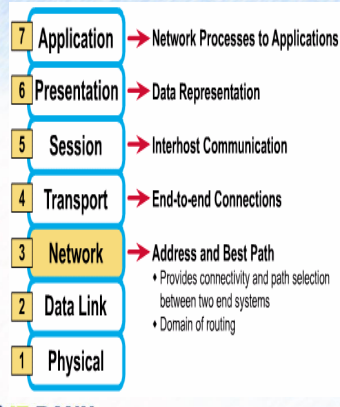
-
라우팅 프로토콜을 이용해서 Best path선택
-
계층 통신단위 : 패킷
-
계층 장비 : 라우터
-
계층 주소 : ip, ipx (현재 사용 안됨)
Logical address (IP, IPX)를 담당하고 packet(패킷)의 이동 경로를 결정함
데이터를 목적지까지 가장 안전하고 빠르게 전달함
라우터 : 서로다른 네트워크로 통신할 수 있게 해줌
동적 라우팅 2가지 방식
-
Distance Vector
홉카운트 (라우터 경유) 만으로 최적경로 선택
-
장점 : 설정이 간단함
-
단점 : 대규모에서는 사용불가 (최대 15홉)
다양한 네트워크에서는 비효율적
-
-
Link State
장치간의 속도 및 적은 수의 라우터 등 종합 연산을 통하여 최적경로 선택
-
장점 : 빠른속도를 유연하게 유지할 수 있음
-
단점 : 설정이 복잡하다
많은 리소스 (자원) 을 소모하므로 라우터의 성능이 좋아야함
-
4계층 : Transport Layer (전송 계층)
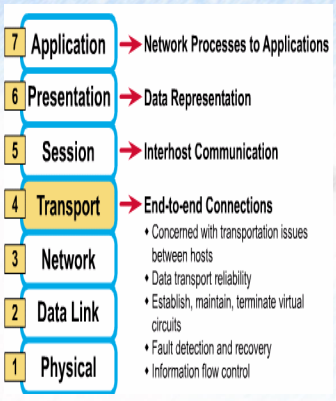
-
정보를 분할하여 전송하고, 목적지에 도달하기 전 하나로 합치는 과정을 담당
-
계층 통신 단위 : 세그먼트
-
계층 장비 : 게이트웨이
-
계층 프로토콜
-
TCP : 신뢰성, 연결지향성, 속도가 느림
목적지까지 안전하게 도달해야하는 성향의 통신
( http / https / ftp / ssh / Telent / 등 ...)
-
UDP : 비신뢰성, 비연결지향성, 속도가 빠름
많은 양의 데이터를 빠르게 목적지까지 전송만 하면 되는 경우
(dns / dhcp / 스트리밍 / 등...
-
목적지 컴퓨터에서 발신지 컴퓨터 간의 통신에 있어서
에러제어 (error control) 와 흐름제어 (flow control)을 담당
5계층 : Session Layer (세션 계층)
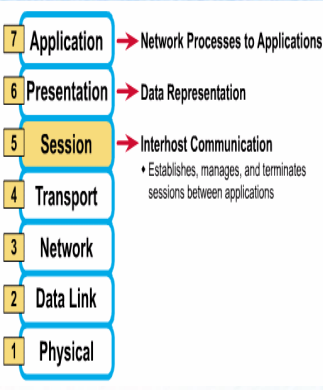
네트워크 상에서 통신을 할 경우 양쪽 호스트 간에 최초 연결이 되게 하고
통신 중 연결이 끊어지지 않도록 유지 시켜주는 역할을 한다
6계층 : Presentation Layer (표현 계층)
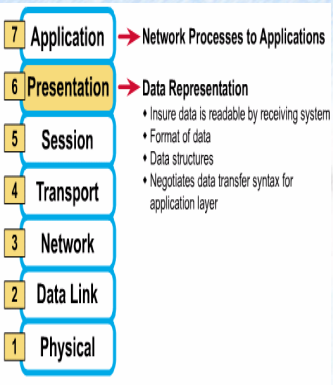
'
- 전송하는 데이터의 포맷(유형) 을 결정
다양한 데이터 포맷을 일관되게 상호 변환하고 압축기능 및 암호화, 복호화 기능을 수행
- ASCII, EBCDIC, GIF, JPEG, AVI,
MPEG 등...
7계층 : Application Layer (응용계층)
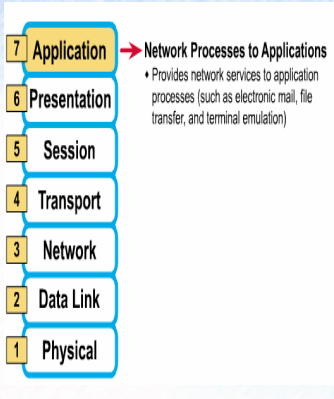
-
사용자 인터페이스의 역할을 담당하는 계층
-
사용자와 가장 가까운 프로토콜 정의
-
HTTP(80), FTP(20, 21), Telnet(23), SMTP(25), DNS(53), TFTP(69) 등...
옆에 숫자는 포트 숫자를 의미함
Encapsulation (캡슐화)
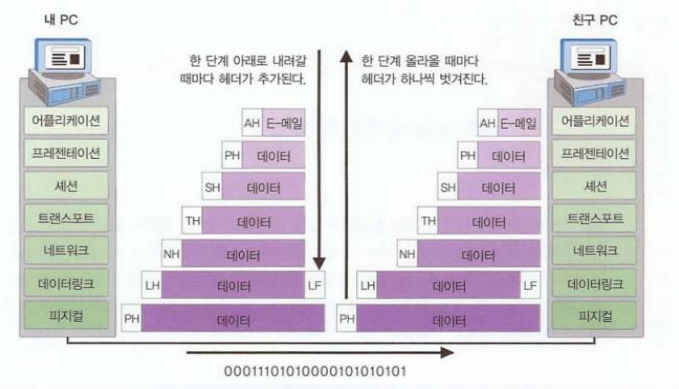
- De-Encapsulation (수신)
IP address
IP addressing
2진수 변환
1) 10.21.100.4
00001010.00010101.01100100.00000100
2) 165.111.17.90
10100101.01101111.00010001.01011010
3) 192.128.134.72
11000000.10000000.10000110.01001000
IP address
- ip는 논리적인 주소
TCP / IP 를 사용하는 네트워크 상에 연결되 장비들에게는 고유의 IP 주소가 부여됨
- IP address는 네트워크 부분과 호스트 부분으로 구성
IP address = Network ID + Host ID
-
하나의 네트워크란, 하나의 Broadcast Domain
-
하나의 네트워크란, L3장비
(3계층 장비 : 라우터) 를 거치지 않고 통신이 가능한 영역 -
다른 네트워크와 통신하가 위해서는 라우터를 거쳐야 한다
네트워크와 호스트를 구분하는 방법
(중요)
동일 네트워크에소는 Network 부분은 모두 같고, Host 부분이 모두 달라야 한다
이렇게 IP 주소를 network 부분과 host 부분으로 구분해주는 역할을 하는것이 Subnet mask 이다
IP Address Class
IP 주소를 효율적으로 배분하기 위해 정해진 약속

네트워크 클래스의 구분

첫 번째 옥텟을 보고 구분할 수 있음
EX ) 123.5.67은 Class A임
127.0.0.1
- LocalHost (자기자신)
0.0.0.0
- All-zero
0과 127은 특별한 역할이 있기 때문에 전체 범위에서 빠짐
Class A ( 0 ~ 127)
0과 127은 제외되고, 1 ~ 126까지 사용
-
Default Subnet Mask : 255.0.0.0 (/8)
-
A Class 사설주소 : 10.0.0.0 ~ 10.255.255.255
사설IP는 공인IP와 통신이 불가능 -
Network 숫자 : 128개 (2개는 예약), 네트워크 당 Host 숫자 : 16,777,214 개
첫 번째 옥텟이 10이면 무조건 Class A

Class B (128~191)
-
Default Subnet Mask : 255.255.0.0 (/16)
-
Class 사설주소 : 172.16.0.0 ~ 172.31.255.255
-
Network 숫자 : 16,384개, 네트워크 당 Host 숫자 : 65,534개
Class C (192~223)
-
Default Subnet Mask : 255.255.255.0 (/24)
-
C Class 사설주소
192.168.0.0 ~ 192.168.255.255 -
Network 숫자 : 2,097,152 개, 네트워크 당 Host 숫자 : 254 개
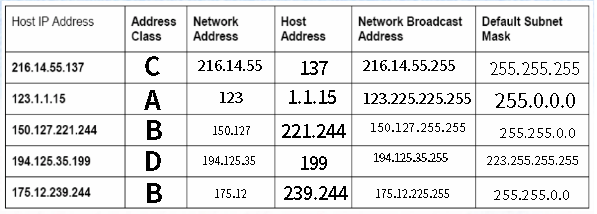
연습
Subnet mask
Subnet mask
Subnet mask(1)
메인이 아닌 어떤 가공을 통한 네트워크를 만들기 위해서 씌우는 마스크
총 네트워크 범위에서 Network field에 ‘1’을 할당하고 Host field에 ‘0’을 할당한 값이 Subnet mask
- 네트워크를 할당 받으면 Host 부분은 사용자 마음대로 사용
network ID
편하게 넷아이디라고 부름
ip대역대의 대표주소를 의미
주로 라우팅 할 때 많이 사용됨
- IP 주소와 Subnet mask를 AND 연산 하면 Network ID 값을 구할 수 있음
Subnet mask(1)
ex)
IP address : 210.5.1.7
Subnet mask : 255.255.255.0
11010010.00000101.00000001.00000111
11111111.11111111.11111111.00000000
11010010.00000101.00000001.00000000
= 210.5.1.0 (Network ID)
11010010.00000101.00000001.11111111
= 210.5.1.255 (Broadcast)
- Host field를 모두 ‘0’으로 채우면 Network ID
- Host field를 모두 ‘1’로 채우면 Broadcast 주소
Network ID와 Broadcast 주소는 IP 주소로 사용할 수 없음
- 사용 가능한 IP주소 : 210.5.1.1 ~ 210.5.1.254
(총 호스트의 숫자 - 2) = 2^n - 2 = 사용 가능한 IP주소의 숫자
Subnet mask (3)
2진수로 표현했을 때 (맨 왼쪽부터)
1이 연속적으로 나와야 함
ex)
-
255.255.255.0 => Subnet mask 사용 가능
-
255.255.255.10 => Subnet mask 사용 불가능
-
255.255.255.128 => Subnet mask 사용 가능
Subnet mask의 규칙
255.255.255.0 (128 / 192 / 224 / 240 / 248 / 252 / 254 / 255)
255.255.255 ( 254 / 252 / 248 / 240 / 224 / 192 / 128 / 0) .0
Prefix 란 Subnet mask의 ‘1’이 들어간 bit의 숫자
(Subnet mask의 다른 표현 방법)
ex)
255.255.255.0 => /24
255.255.0.0 => /16
255.0.0.0 => /8
255.255.255.128 => /25
255.255.255.224 => /27
Subnet mask (4)
ex 1)
1.1.1.1 과 1.1.2.1은 같은 네트워크에 속해 있는가?
=> 같은 네트워크
클래스 A는 첫 번째 옥텟이 똑같아야함
ex 2)
128.13.4.1과 128.13.5.2는 같은 네트워크 속해 있는가?
=> 같은 네트워크
클래스 B는 두 번째 옥텟까지 똑같아야함
Subneting
IP Address Class
이렇게 Subnet mask를 각 Class별 default 값으로 사용하는 것을 Classful 하다고 표현함
ex)
한 사무실에서 200대의 PC를 사용할 때 어느 Class의 IP를 배정하는 것이 좋은가?
=>Class C가 적당하다. Class A 나 Class B는 사용 호스트의 수에 비해 IP를 낭비함
Subneting
Subneting
IP를 효율적으로 낭비 없이 분배하고 Broadcast Domain의 크기를 작게 나눠주는 것
Classless
Class별 default Subnet mask를 사용하지 않고 적당한 크기의 Subnet mask로 사용자의 상황에 따라 하나의 네트워크를 작게 여러 개로 나눠 사용
- 즉, Classful Network를 여러 개의 Network로 나누는 것
2가지의 서브네팅
1) 피자조각의 크기
- 네트워크 호스트의 크기를 갖고 서브네팅
2) 피자 조각의 개수
- 하나의 네트워크를 여러개의 네트워크로 나누는 경우

리눅스 #1
운영체제 (Operating system)
- 장치를 사람이 쓰기 쉽게 만들어주는 역할
운영체제의 종류
-
사용 장치
-
desktop OS : windows / MAC OS / Linux
-
workstation OS : Unix / Linux / windows server
-
-
사용 환경
-
CLI : Command Line Interface
명령줄을 이용한 환경 (CUI / TUI) 화면에 글자만 보임
-
GUI : Graphic User Interface
그래픽을 이용한 환경
-
Linux 특징
-
오픈소스 운영체제
-
다양한 회사에서 소스를 가져다가 Linux 운영체제를 만들어냄
- Linux는 계열과 종류가 다양함
-
Unix 기반의 대표적인 운영체제
운영체제 사용 방식
single booting mode
-
하나의 장치에 하나의 운영체제만 설치
-
부티 시 boot loader 가 설치된 운영체제 바로 부팅
multi booting mode
-
하나의 장치에 여러개의 운영체제를 설치
-
부팅 시 boot loader가 설치된 운영체제 중 사용자가 선택한 운영체제로 부팅
-
운영체제 간 자료 취급 방법 등의 각종 호환성 문제로 현재는 잘 사용되지 않는 방식
virtual booting mode
-
가상의 컴퓨터를 만들어서 별도 운영체제를 설치하고 사용
-
실제 컴퓨토는 single booting mode 를 사용
- 가상화 환경을 제공하는프로그램을 이용하여 가상 컴퓨터를 만들고 가상 컴퓨터 내부에 별도의 운영체제를 설치하여 사용
-
가상 컴퓨터는 별도의 파일로 저장
- 복사나 백업 등의 관리작업이 굉장히 쉬워짐
가상화 환경 프로그램
virtual box
-
oracle 제품
-
무료로 사용
-
인터페이스가 불편하게 구성
-
메뉴들이 숨겨져 있는 경우가 있음
-
a기능의 설정을 하기 위해 b 기능의 설정을 제어하는 경우도 존재
-
VMware workstation
-
VMware 회사 제품 ( VMware : Virtual Machine software)
-
여러가지 제품군이 존재
-
workstation player
-
개인 사용시 무료
-
pro의 거의 모든 기능을 사용할 수 있음
-
-
workstation pro
-
유료
-
모든 메뉴를 사용할 수 있음
-
-
실습
새 가상컴퓨터 만들기
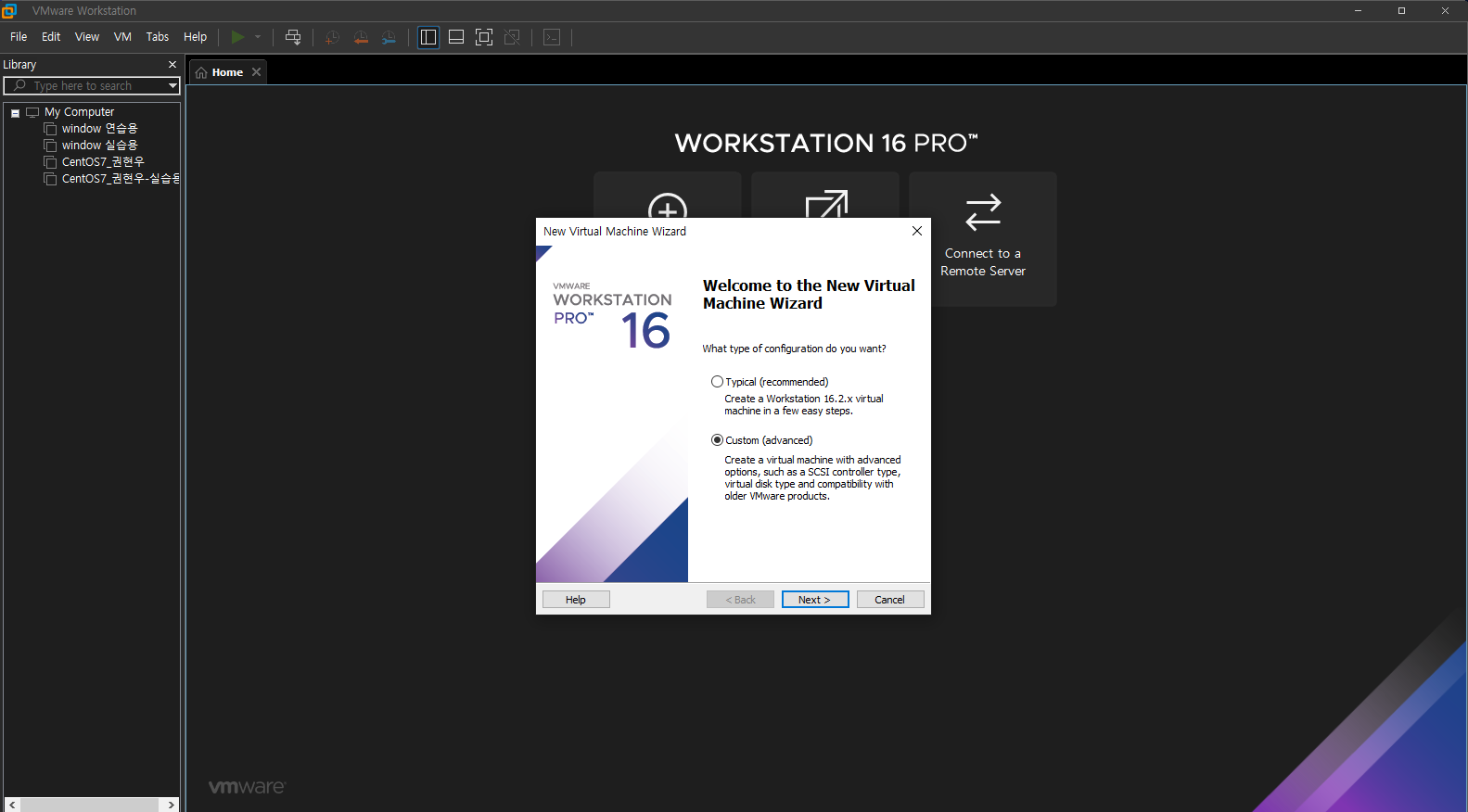
Vmware workstation에서 create a New Virtual Machine
커스텀으로 설치 진행
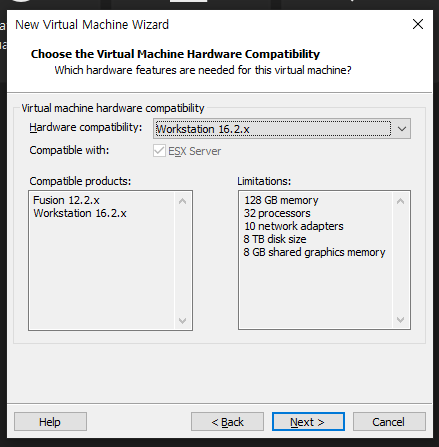
가장 높은 버전 사용
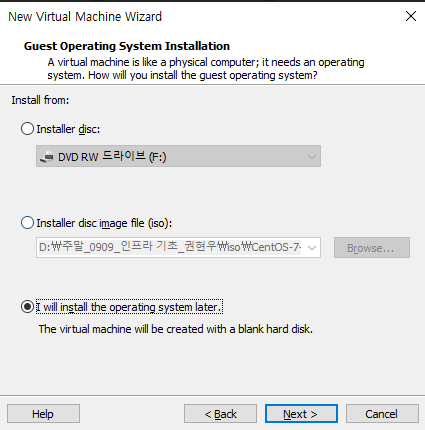
나중에 설치하기로 진행
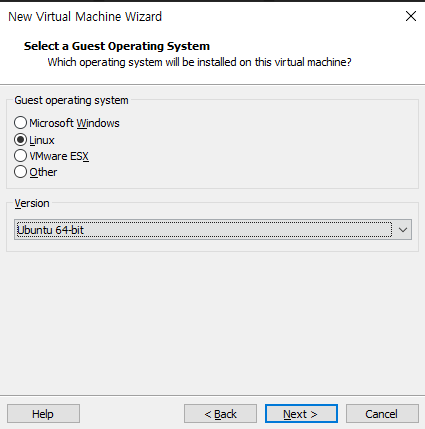
Linux와 Ubuntu 64bit 선택
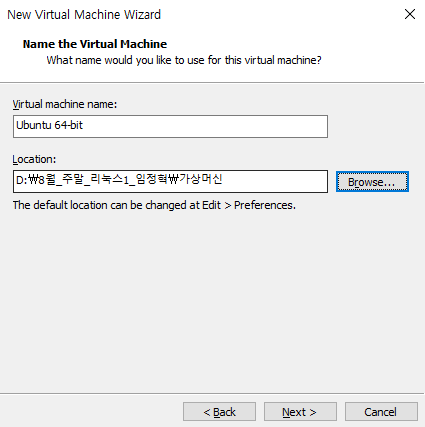
가상머신의 이름과 가상머신이 저장될 파일의 경로 설정
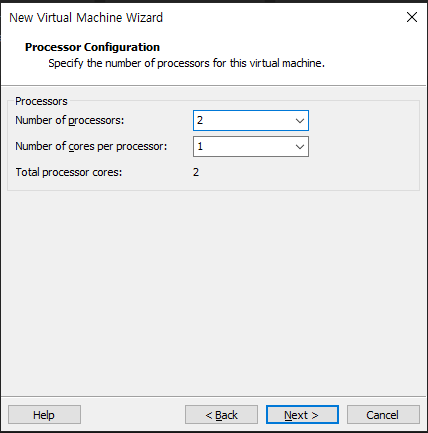
CPU의 수와 코어의 수를 선택 한 후 진행
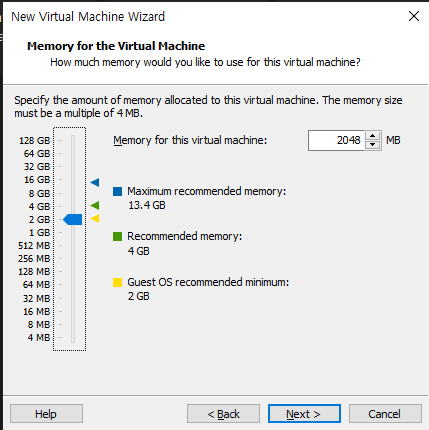
RAM 용량 선택
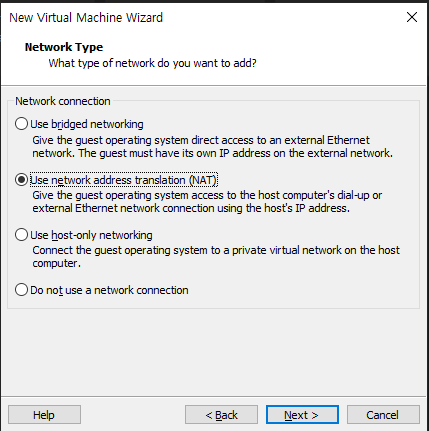
네트워크 타입 선택
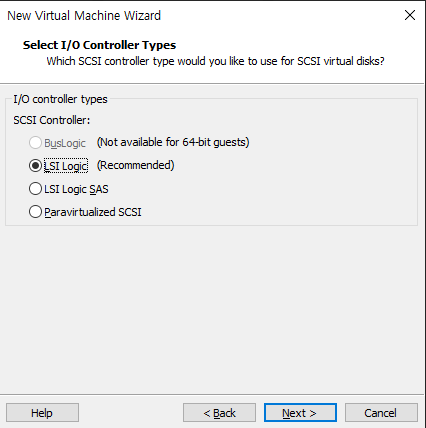
입출력 장치 선택
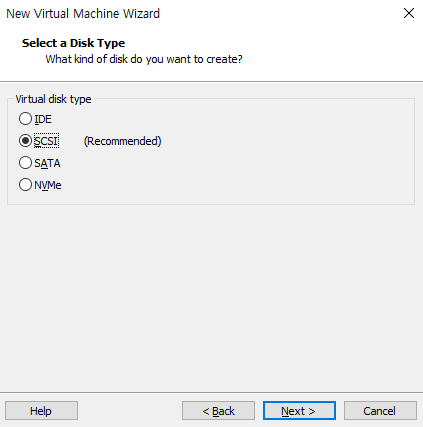
디스크 타입 선택
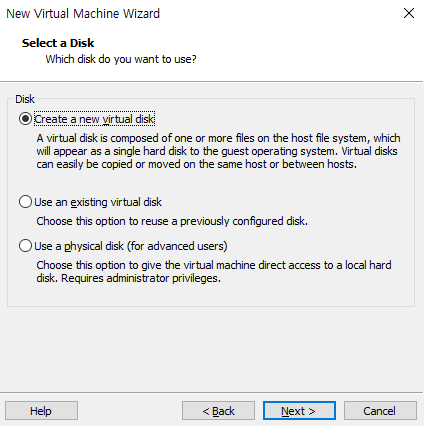
가상 디스크 선택
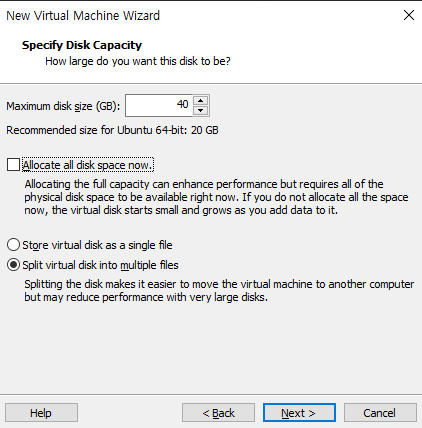
디스크 용량을 40GB로 늘림
디스크의 일부분을 램 처럼 사용할 것이기 때문
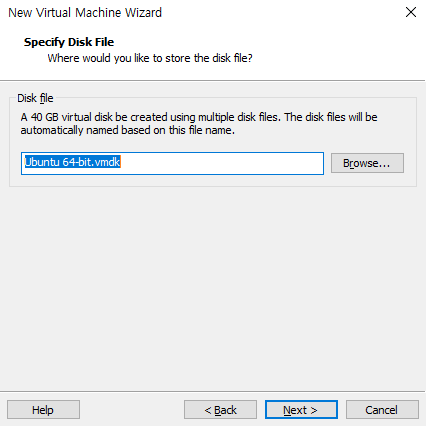
가상머신의 디스크 파일이름 확인
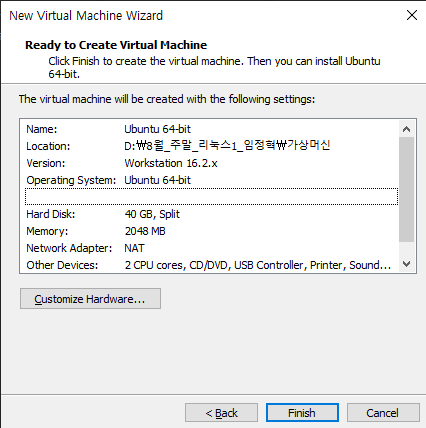
가상머신의 세부 사항 점검 후 진행
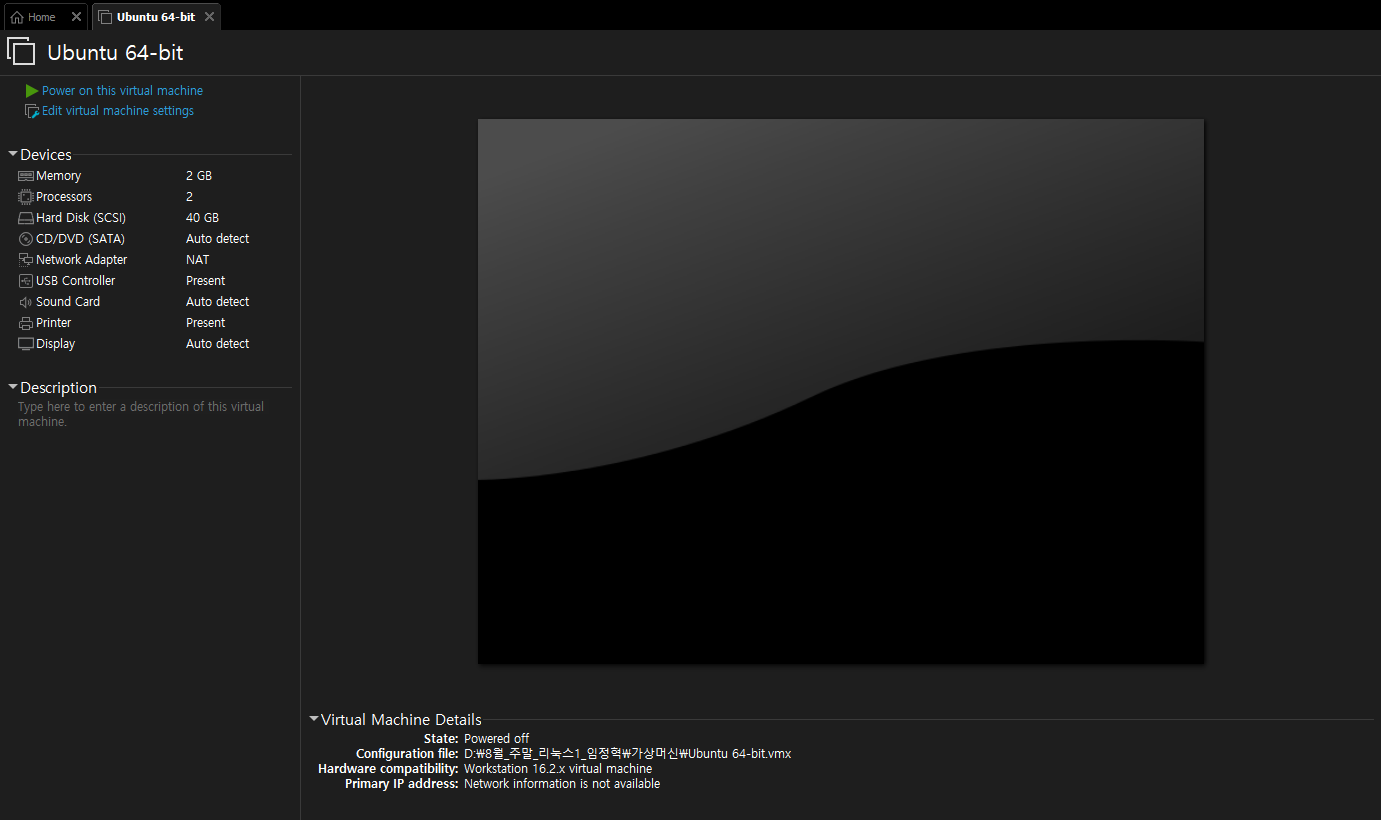
가상 컴퓨터 생성 완료
edit virtual machine setting 클릭
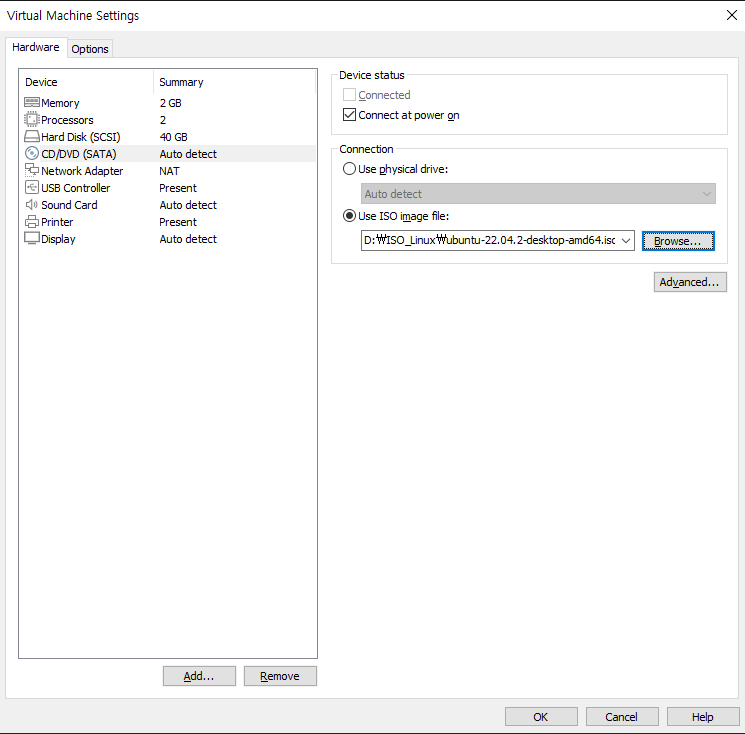
CD / DVD 항목에서 다운받은 iso 파일 경로 입력
필요없는 장치들 제거 후 진행
Linux 설치
power on 버튼 클릭
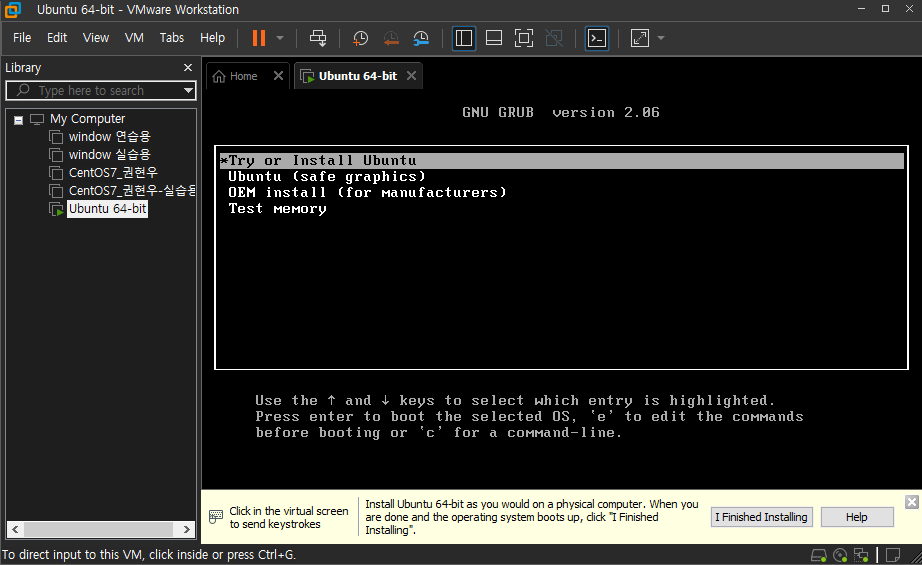
-
host 환경 -> guest 환경 : guest 화면 클릭
-
guest 환경 -> host 환경 : ctrl + alt
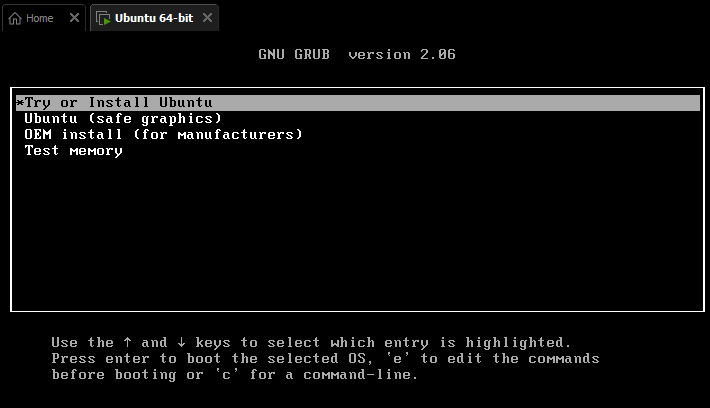
try ot install ubuntu 항목 선택 후 진행
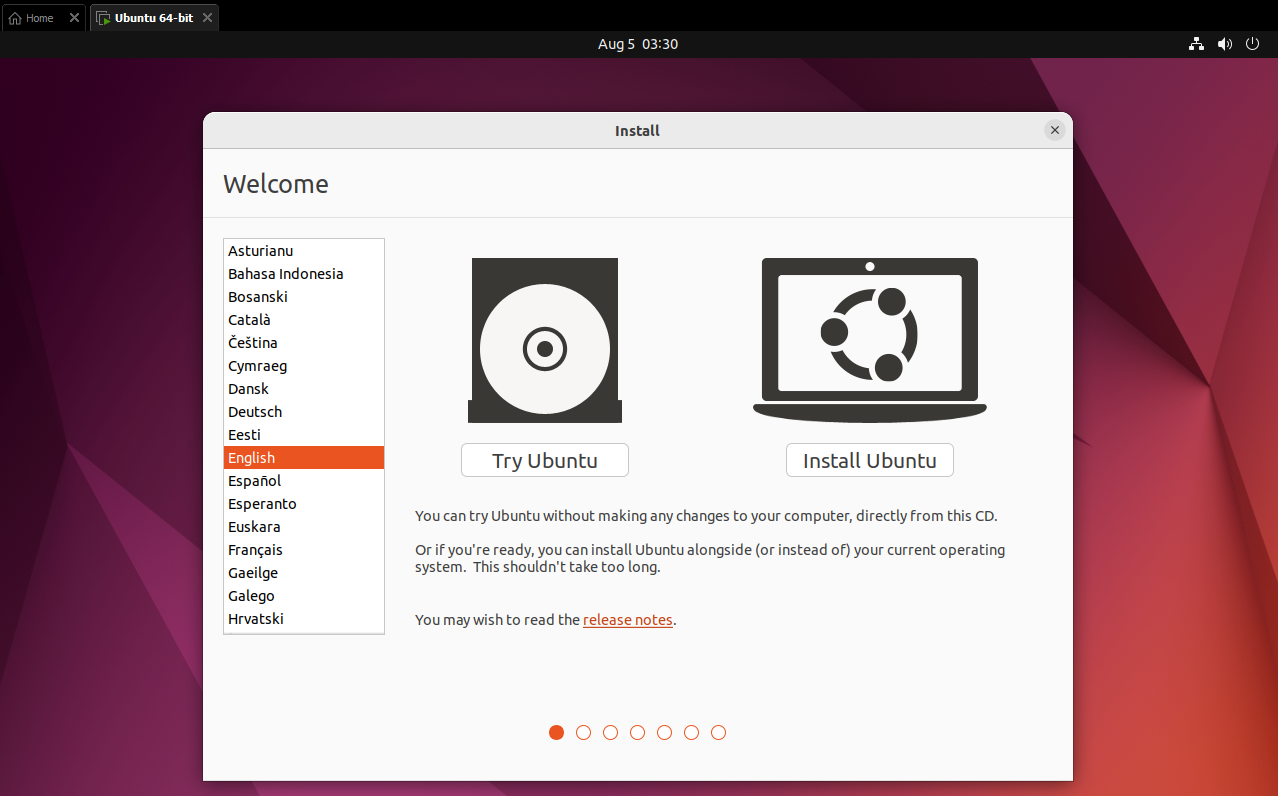
try ubuntu 로 진입
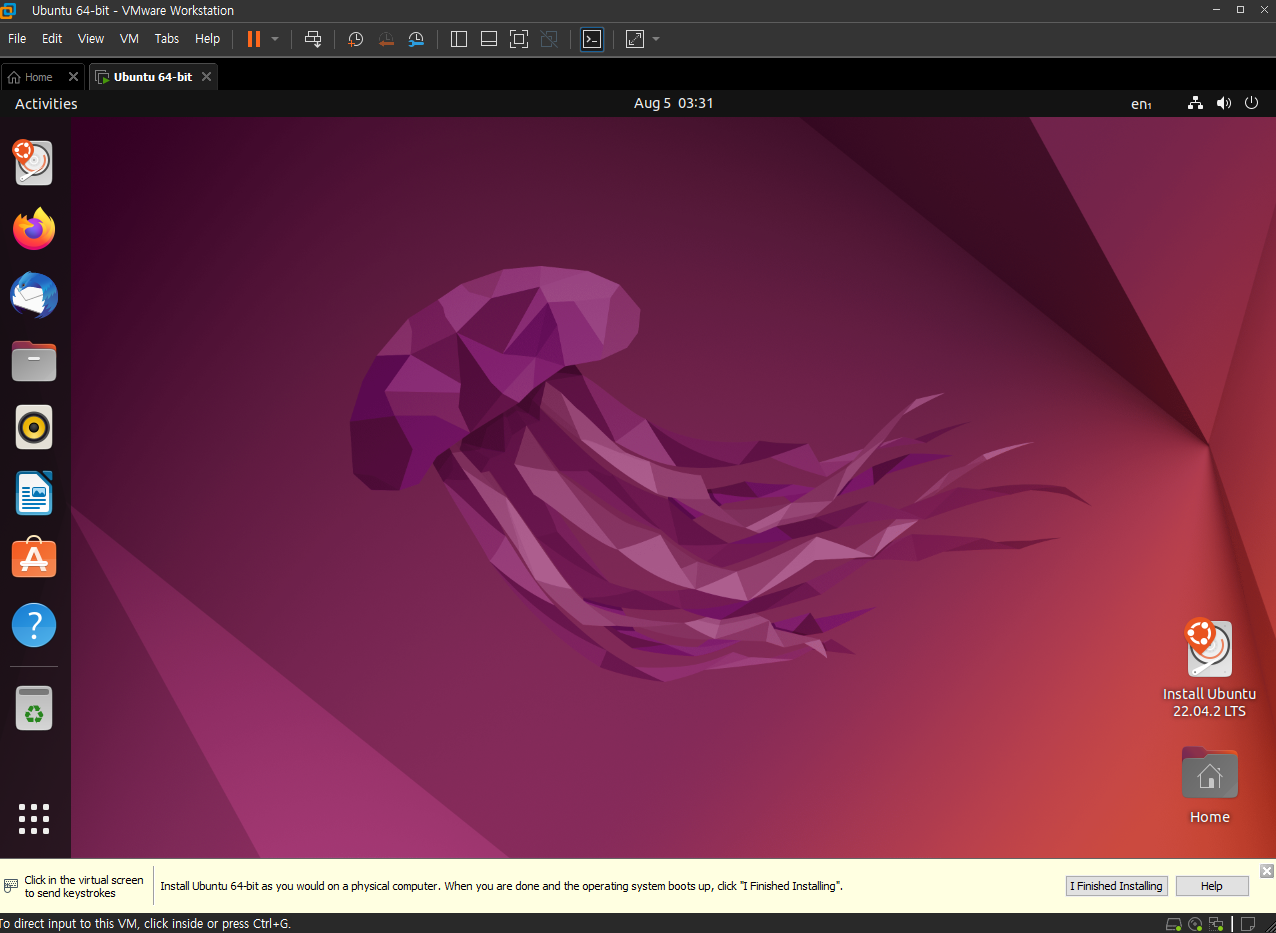
(진입 모습)
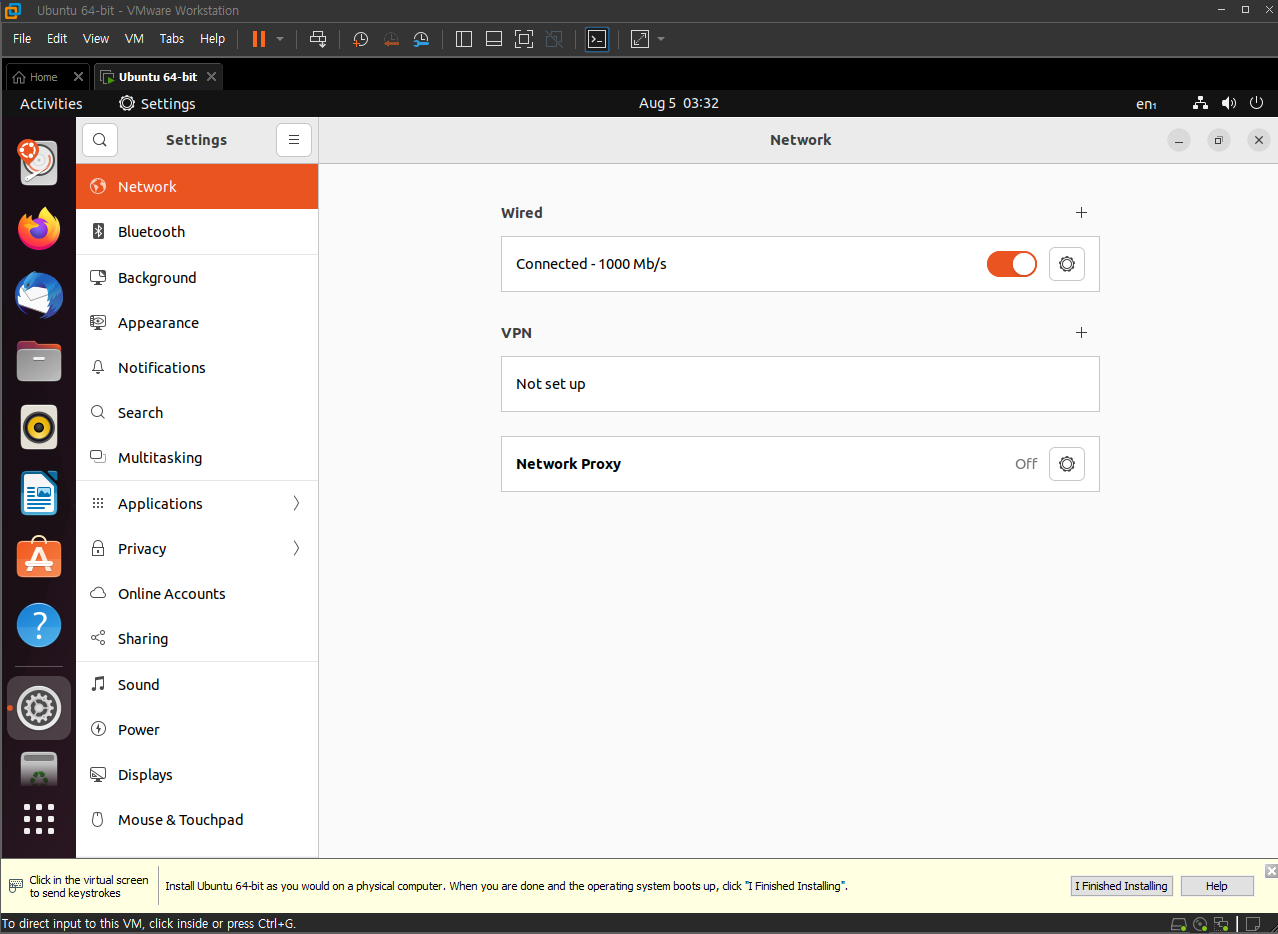
settings 진입 후 디스플레이 설정에서 1920 * 1080 으로 설정
install Ubuntu 더블클릭
한국어 설정 후 계속하기
키보드 레이아웃 - korean으로 진행
변경 없이 계속하기
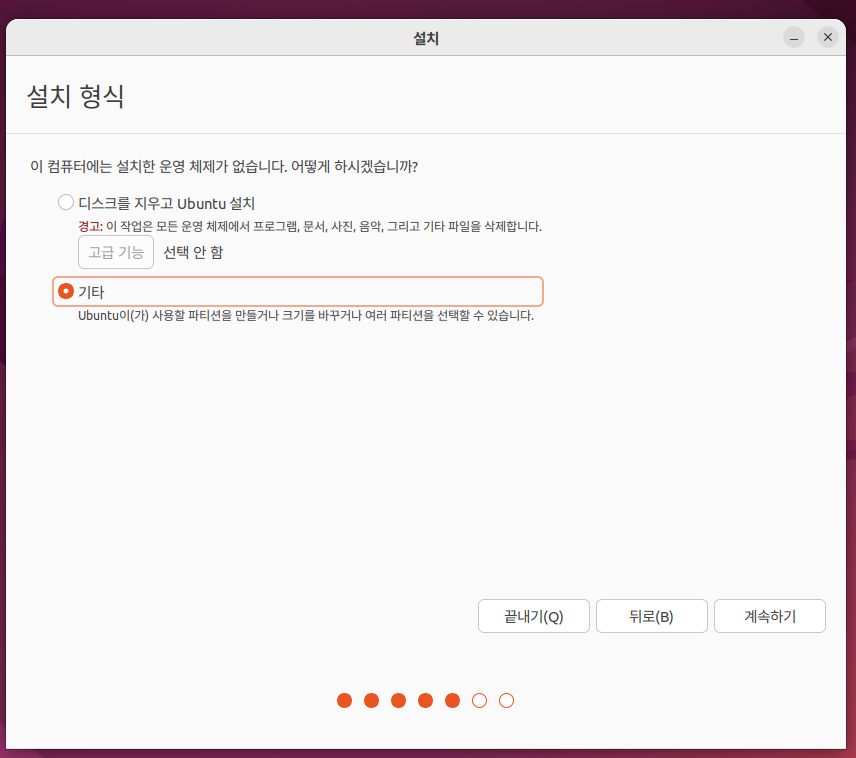
기타로 진행
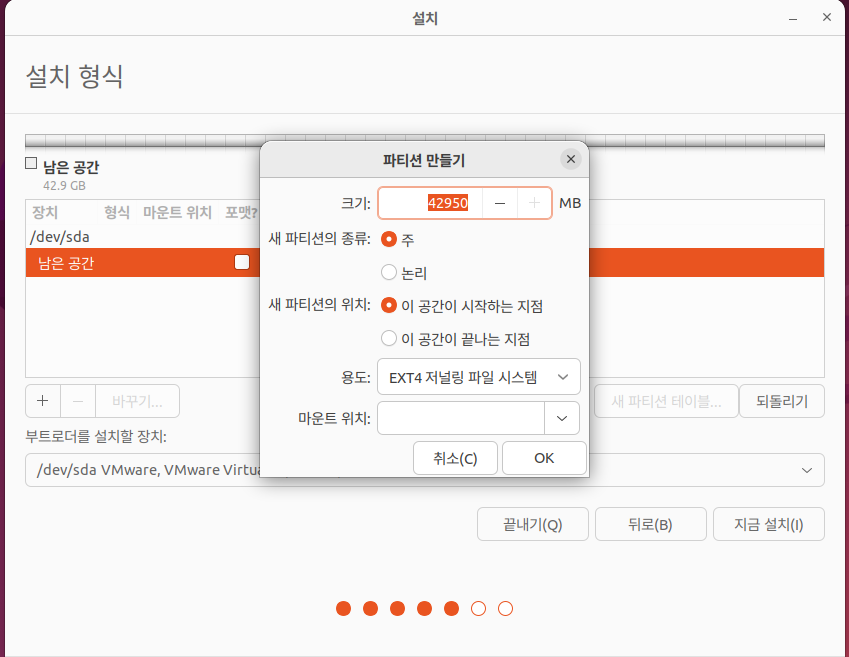
새 파티션 테이블 후 남은공간 클릭 후 + 버튼
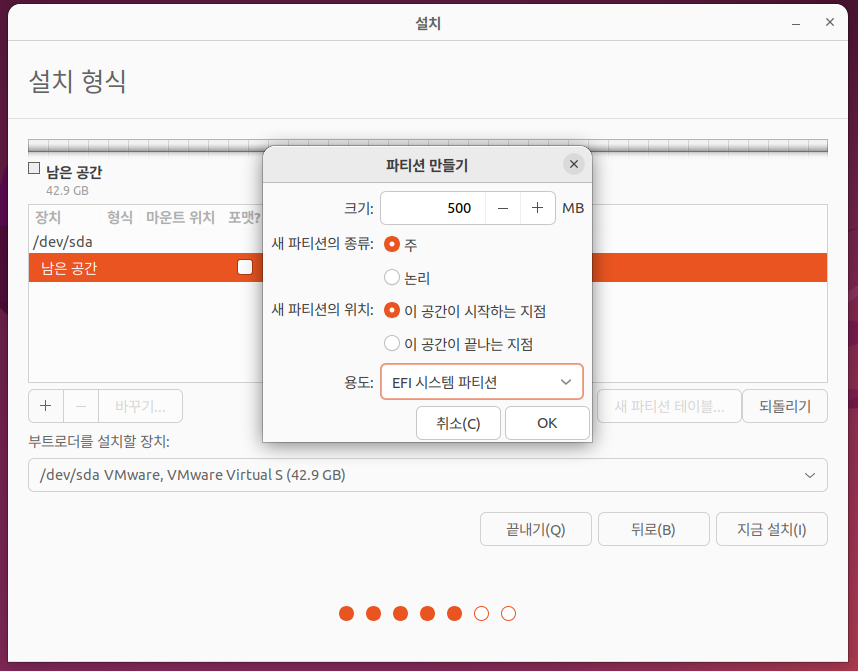
크기를 500mb 설정 후 용도를 EFI 시스템 파티션 설정
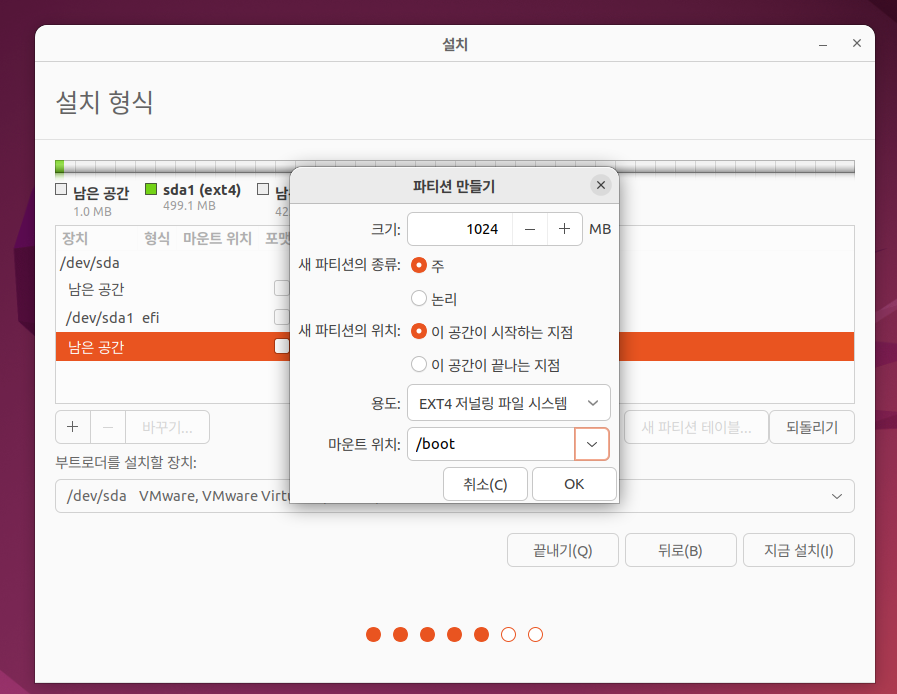
용량이 가장 큰 남은 공간에서 + 버튼 클릭 후 크기와 마운트 위치 지정
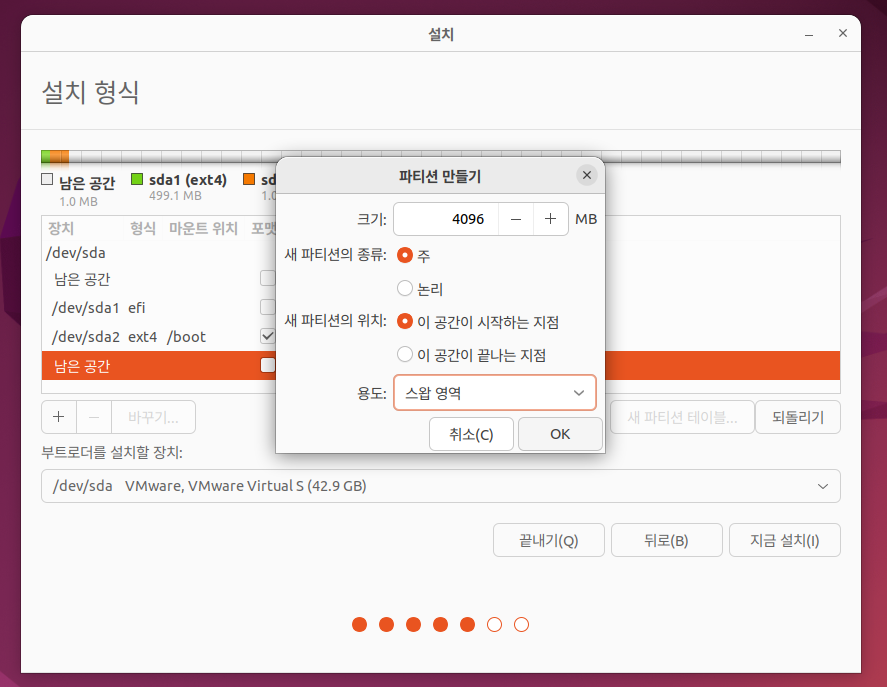
다시 남은 공간에 크기와 스왑영역을 지정
- 스왑영역 : 가상 메모리, 디스크를 램 처럼 사용할 수 있게 해줌
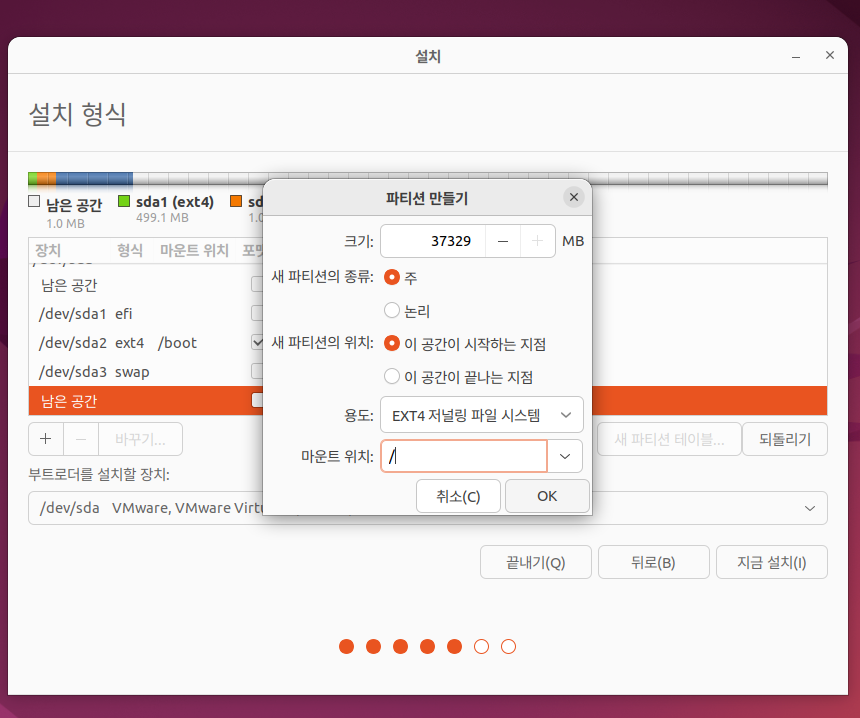
다시 + 버튼 후 크기는 기본값 유지 한 채 마운트 위치는 / 로 지정
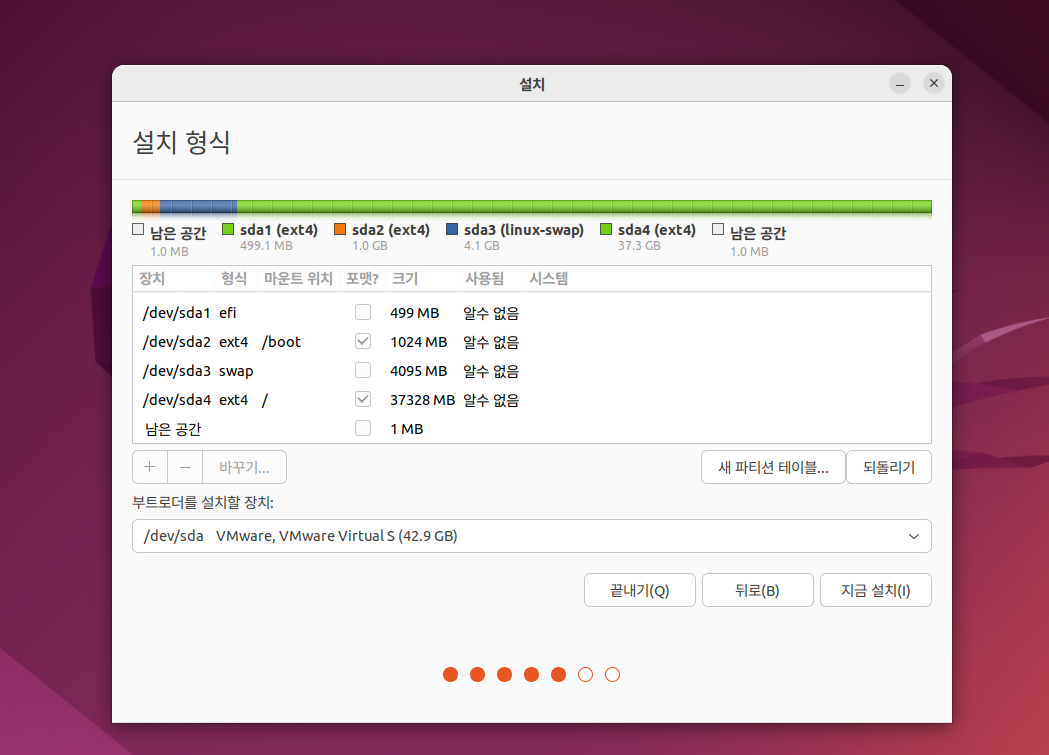
(해당 과정 끝 모습)
지금 설치 누른 후 계속하기로 진행
지금 다시 시작하기
엔터 누르고 로그인 화면 진입
Linux 설치 완료
기본 프롬프트 구성
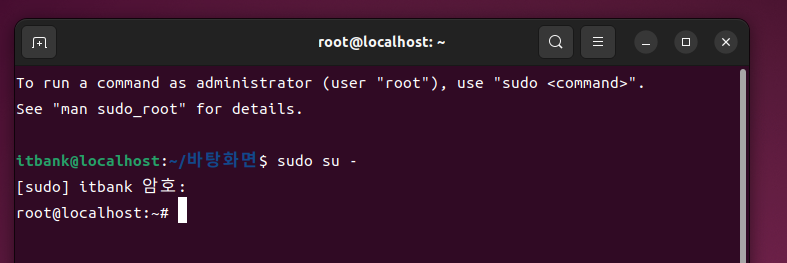
root@localhost:~#
-
root : 사용자명 / 어느 사용자로 로그인 했는지 표시
-
localhost : 장치명 / 현재 어느 장치에 연결되어 있는지 표시
-
~ 현재 위치한 디렉토리
- 디렉토리 : CLI 환경에서 사용하는 폴더
-
# : 사용 권한 ( # : 관리자 권한 / $ : 일반 사용자 권한)
리눅스 #2
기본 디렉토리
-
Linux의 최상위에는 / 라는 이름의 디렉토리가 존재하고, Linux 내부의 모든 파일 / 디렉토리는 / 내부 어딘가에 위치
- / 디렉토리를 기준으로 tree 구조로 운영첵제가 구성되어있다
관리자 계정으로 로그인시 root 디렉토리에 접근할 수 있다
- / 디렉토리를 기준으로 tree 구조로 운영첵제가 구성되어있다
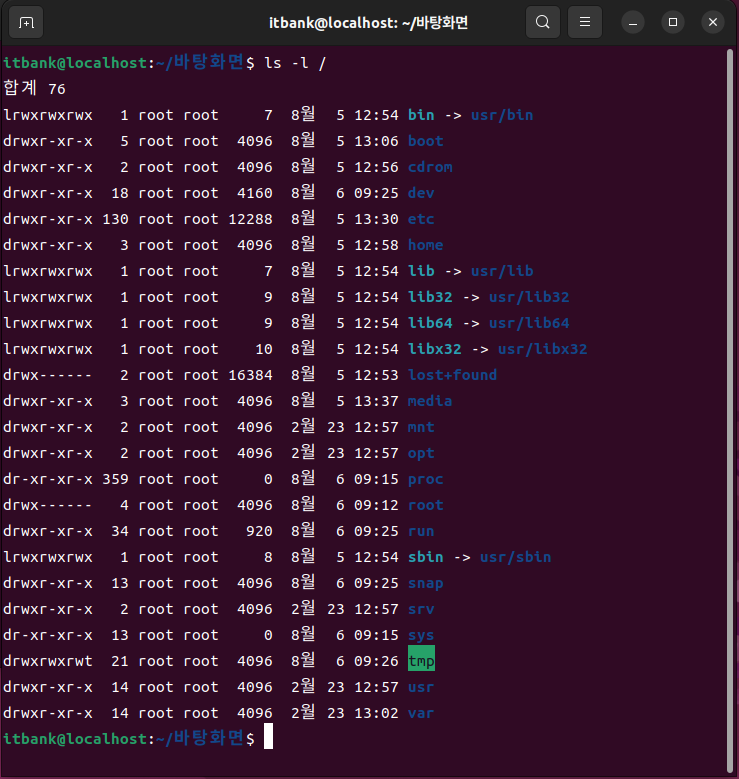
-
-> 표시가 있는 항목은 symbolic link로, 바로가기 역할을 한다
- ex) bin -> usr/bin : /bin은 /usr/bin으로 연결된다
-
/ 내부에 생성되어있는 디렉토리
-
/bin : 공용 명령어 (일반 사용자 + 관리자) 들이 저장된 디렉토리로 연결되는 link 파일
-
/sbin : 시스템 제어 명령어 (관리자 명령어) 들이 저장된 디렉토리로 연결되는 link 파일
-
/boot : 부팅에 관련된 각종 설정 파일과 이미지 파일들이 저장된 디렉토리
-
/cdrom : cd를 편하게 연결할 수 있도록 만들어놓은 디렉토리
-
/dev : 장치파일이 생성되는 디렉토리
-
/ect : 각종 설정 파일과 OS의 환경 설정 파일이 저장되는 디렉토리
-
/home : 일반 사용자들의 홈 디렉토리가 생성되는 기본 위치
-
/root : 관리자 root의 홈 디렉토리
-
/lib ~ : 각종 라이브러리가 저장된 디렉토리로 연결되는 link 파일
-
/media : local device를 사용하기 편하게 연결해주는 디렉토리
- local device : 내 장치에 직접 연결되는 장치
-
/mnt : remote device를 사용하기 편하게 연결해주는 디렉토리
- remote device : local device를 제외한 모든 장치
-
/usr : 대부분의 응용 프로그램들이 설치되는 위치
-
/opt : /usr에 저장되지 않은 프로그램들이 저장되는 위치
-
/proc : 실행중인 프로세스에 대한 가상 파일들이 저장되는 디렉토리
-
/run : 실행중인 각종 서비스에 필요한 파일들이 생성되는 디렉토리
-
/snap : snap 명령어를 이용한 프로그램 관리를 하기 위헤 존재하는 디렉토리
-
/srv : 서버 동작시 외부 사용자가 비교적 쉽게 접근할 수 있는 디렉토리
-
/sys : 시스템 동작 과정에서 필요한 각종 파일들이 생성되는 디렉토리
-
/tmp : 임시 파일(디렉토리) 가 생성되는 디렉토리
-
/var : 러그 등 자주 변경되는 시스템 파일들이 저장되는 디렉토리
-
-
홈 디렉토리 : 사용자 개인 디렉토리, 로그인 시 최초 접속 위치
기본적으로 다른 사용자의 접근 불가능 (다른 사람은 접근 불가능)
명령어 입력 시 주의 사항
-
명령줄 한 줄에는 하나의 명령어만 사용
-
여러 명령어를 순차적으로 적용시키는 존재
-
기호들을 사용하지 않으면 한 줄의 명령어에는 하나의 명령어만 사용
-
-
대소문자를 엄격하게 구분
경로
-
파일 / 디렉토리에 찾아가는 길
-
절대 경로와 상대경로로 구분 (두 가지 방식 전부 사용 가능해야 한다)
-
절대경로 ./ 를 기준으로 파일 / 디렉토리에 찾아가는 방식
-
상대경로 : 내 현재 위치를 기준으로 파일 / 디렉토리에 찾아가는 방식
cd ./ : 현재 디렉토리
cd ../ : 상위 디렉토리
-
기초 명령어
-
형식
명령어 [옵션] [보조옵션] [대상]
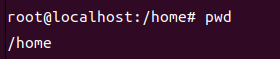
pwd
내 현재 위치를 절대 경로로 출력
cd
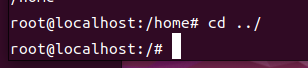
내 현재 위치를 다른 디렉토리로 변경할 때 사용
(= 다른 디렉토리로 이동)
형식은 기본 형싣으로 사용
-
대상
directory : 해당 디렉토리로 이동
. : 현재 디렉토리로 이동 (의미 X)
.. : 상위 디렉토리로 이동
생략 : 명령어를 입력한 사용자 자신의 홈 디렉토리로 이동
~ : 명령어르 입력한 사용자 자신의 홈 디렉토리로 이동
~ 사용자명 : 해당 사용자의 홈 디렉토리로 이동(관리자 전용)
ls
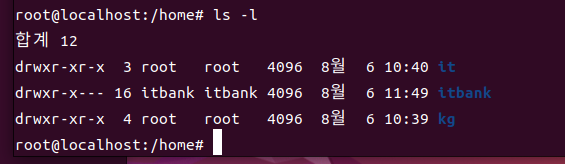
-
대상에 따라 출력되는 범위가 달라진다
-
파일을 대상으로 하면 파일 자체를 출력
-
디렉토리를 대상으로 하면 디렉토리 내부의 목록을 출력
-
대상을 생략하면 현재 위치하 디렉토리 내부의 목록을 출력
-
-
대상을 생략할 수 있고, 여러개의 파일과 디렉토리를 대상으로 한 번에 지정할 수 있다
- 여러개 대상의 정보를 확인할 때 파일과 디렉토리를 함께 지장할 수 있다
- 여러개 대상의 정보를 확인할 때 파일과 디렉토리를 함께 지장할 수 있다
-
옵션
-l : 자세한 정보를 함께 출력
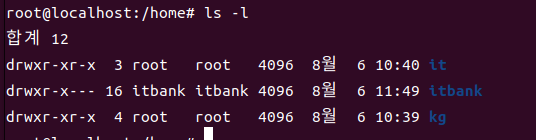
-a : 대상이 디렉토리인 경우 내부의 숨겨진 항목을 함께 출력

-d : 대상이 대렉토리인 경우 디렉토리 자체의 정보를 출력

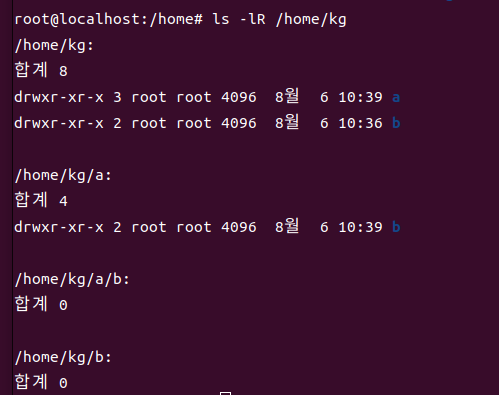
-R : 대상이 디렉토리인 경우 하위 디렉토리가 존재하면 그 내부까지 출력
-
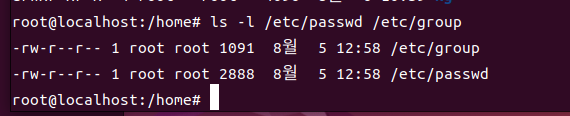
자세한 정보 출력 내용
-rw-r--r 1 root root 2888 8월 5 12:58 /etc/passwd
- : 대상의 종류 ( - : 파일 / d : 디렉토리)
rw-r--r : 허가권
1 : link 개수
root root : 소유권 (허가권과 소유권을 권한이라고 말함)
2888 : 크기 (byte 단위 / 디렉토리는 용량출력 불가능)
8월 5 12:58 : 마지막으로 수정된 날짜와 시간
/etc/passwd : 대상의 경로와 이름
cp
- copy : 복사 + 붙여넣기
-
기본적으로는 파일만 복사 가능
- 별도의 옵션을 사용하면 디렉토리도 복사할 수 있다
-
원본의 이름을 유지하면서 복사 + 이름을 변경하면서 복사 가능
- 이름을 변경하면서 복사 할 때는 원본을 하나만 사용
-
형식
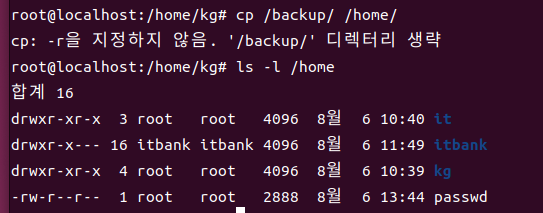
cp [옵션] 원본 ... [원본] 복사할 위치 [+이름]
-
옵션
- -i : 원본이 이미 있는 경우 덮어쓸 것인지 물어보는 옵션

- -r : 디렉토리 복사를 위한 옵션
(-r 옵션이 없을 경우)
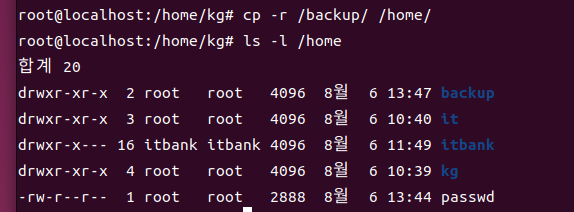
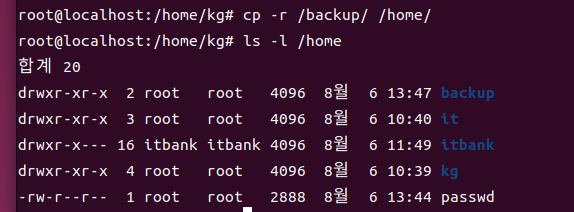
(-r 옵션이 있는 경우)
리눅스 #3
기초 명령어
mv
-
- move : 잘라내기 + 붙여넣기
-
원본의 이름을 유지하면서 이동 + 이름을 변경하면서 이동 가능
-
이름을 변경하면서 이동할 때는 우너본 하나만 사용
-
이름바꾸기 명령어로 가능
-
-
cp 명령어와 사용법이 동일함
-
파일과 디렉토리 전부 이동 가능
-
옵션
- -i : 이동할 위치에 동일한 이름의 개체가 이미 있는경우 덮어쓸 것인지 물어보는 옵션
mkdir
-
make directory : 디렉토리 생성
-
빈 디렉토리를 생성
-
생성하려는 디렉토리의 경로 (상위 디렉토리)가 없으면 생성 X
- 단, 별도의 옵션을 생산해서 함께 생산할 수 있음
-
형식은 기본형식으로 사용
-
옵션
- -p : 생성하려는 디렉톹리의 경로 (상위디렉토리) 가 없다면 함께 생성하는 옵션
rmdir
-
remove directory : 디렉토리 삭제
-
빈 디렉토리의 삭제만 가능
-
형식은 기본형식으로 사용
-
옵션
- -p : 상위 디렉토리의 삭제를 시도
rm
-
remove : 삭제
-
기본적으로 파일의 삭제 가능
- 디렉토리는 별도의 옵션을 사용
-
휴지통 개념 없기 때문에 바로 완전 삭제가 된다
-
옵션
-
-i : 확인 메세지 출력
-
-r : 디렉토리도 삭제
-
alias
-
단축어 등록
-
형식
-
alias : 현재 등록된 키워드 등록
-
alias 키워드='명령어[옵션]'
-
cat
-
특정 내용을 출력
-
형식
-
cat : 입력한 내용을 그대로 출력
-
cat 파일명 : 해당 파일의 내용 전체를 출력
-
-
기호
-
. : 현재 디렉토리
-
.. : 상위 디렉토리
-
~ : 홈 디렉토리
-
* 모든 종류, 모든 길이의 문자를 대처하는 문자
-
> : redirection : 기호 왼쪽 명령어가 동작하여 화면에 출력되는 내용을 기호 오른쪽에 저장
기호 오른쪽에 없는 이름을 넣으면 해당 이름의 파일로 생성
이미 존재하는 이름을 넣으면 > 기호는 덮어쓰기
>> 는 내용 추가를 함
-
| : pipe, 여러 명령어를 순차적으로 동작시키는 기호
-
-
괄호
[] 생략이 가능한 항목을 묶어주는 괄호
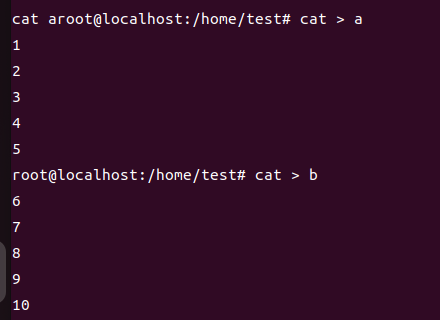
a랑 b를 이렇게 쓰고
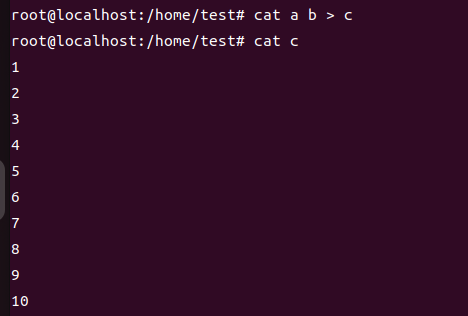
이러면 파일 두 개 합칠 수 있음
touch
-
대상이 없으면 새로운 빈 파일 생성
대상이 있르면 마지막으로 수정된 날짜와 시간 갱신
-
형식 : 기본형식 사용
head
-
파일의 내용을 처음 10줄만 출력
-
형식 : 기본 형식 사용
-
옵션
- -숫자 : 숫자 만큼 출력
tail
-
파일의 내용을 마지막 10줄만 출력
-
형식 : 기본 형식 사용
-
옵션
- -숫자 : 숫자 만큼 출력
more
-
출력되는 내용을 화면 높이에 맞춰 끊어서 출력
-
지나간 내용을 다시 볼 수 없다
-
다른 명령어와 일반적으로 (| 기호 사용)
-
형식 : 기본 형식
-
동작 후 추가 입력
-
enter : 한 줄 너어가기
-
spacebar : 한 화면 넘어가기
-
q : more 중간에 종료
-
-
less
-
more와 같은 동작 + 지나간 내용을 다시 볼 수 있다
-
일반적으로 다른 명령어들과 함께 사용
-
형식 : 기본 형식 사용
-
동작 후 추가 입력
-
enter : 한 줄 너어가기
-
k : 한 줄 돌아가기 ( 위 방향키 )
-
spacebar : 한 화면 넘어가기 ( = page down)
-
page up : 한 화면 돌아가기
-
shift + g : 마지막 줄로 이동
-
g : 첫 줄로 이동
-
q : less 종료
-
-
nl
-
출력되는 내용에 줄 번호를 함께 출력
-
다른 명령오들과 함꼐 사용 (| 기호 사용)
-
형식 : 기본 형식 사용
wc
-
파일의 내용이 몇 줄, 몇 단어, 몇 글자인지 출력
-
옵션
-
-w : 줄의 수 (개행문자로 구분)
-
-c : 단어의 수 (개행문자와 공백문자로 구분)
-
-l : 글자의 수 (특수문자 모두 포함)
-
date
-
장치에 설정된 날짜와 시간을 출력
-
형식은 기본 형식으로 사용
rdate
- 인터넷에 존재하는 시간값을 제공하는 서버(time서버)의 시간을 출력

-
형식 rdate[옵션]<타임서버>
-
옵션
- -s : time 서버의 시간값을 내 장치에 설정
cal
- 달력 출력
-
형식
-
cal : 달력 출력
-
cal 숫자 : 해당 년도 달력을 출력
-
cal 숫자1(월) 숫자2(년) : 해당 년도의 해당하는 달을 출력
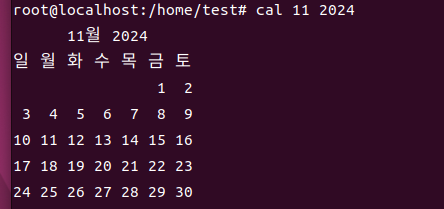
리눅스 #4
기초 명령어
-
find
-
검색 명령어
-
범위를 지정하고 옵션으로 검색할 내용을 작성할 수 있음
-
형식
- find [범위] ...[범위] 옵션 [값] ....[옵션] [값]
-
옵션
-
-name : 이름으로 검색
-
-type : 개체 형식으로 검색
-
-newer : 마지막으로 수정된 날짜와 시간을 기
준으로 더 새로운 개체 검색 -
-exec : 일반적으로 마지막 옵션으로 사용
검색 결과들을 대상으로 특정 명령을 동작시키기 위해 사용- find PATH [-options] -exec rm {} \;
-
man
-
특정 명령이나 파일에 대한 설명을 제공
-
형식
- man {명령어 | 파일명}
-
enter : 한 줄 너어가기
-
k : 한 줄 돌아가기 ( 위 방향키 )
-
spacebar : 한 화면 넘어가기 ( = page down)
-
page up : 한 화면 돌아가기
-
shift + g : 마지막 줄로 이동
-
g : 첫 줄로 이동
-
q : less 종료
-
/내용 : 특정 내용을 검색 (검색 후 n을 눌러서 다음 찾기 shift + n 눌러서 이전 찾기)
시스템 종료
-
shutdown -h now
-
poweroff
-
halt
-
init 0
시스템 재부팅
-
shutdown -r now
-
reboot
-
init 6
vi 에디터 사용방법 (리눅스 쉬어가기)
vi 에디터
-
굉장히 오래 된 CLI 환경의 문서 편집기
-
90년대에 vi 에디터를 기반으로 한 vim 편집기가 만들어짐
- 그 후로 vi 에디터를 말하면 vim 에디터를 말한다
-
사용환경
-
명령모드 : 기본 사용 환경, 커서 이동, 복사/ 잘라내기/붙여넣기, 실행취소/다시실행, 삭제, 입력/실행 모드 전환
-
입력모드 : 내용의 편집을 위한 환경, 파일 내용의 입력/ 수정/ 삭제, 명령 모드 전환
-
실행모드 : 그 외 대부분의 기능들을 위한 환경, 명령 모드 전환
-
(ex 모드)
-
-
vi 실행 명령
-
vi : 빈 파일 열기
-
vi 파일명 : 해당 파일 열기
-
명령모드 사용방법
커서이동
-
1) 글자 단위 커서 이동
-
h : 한 글자 왼쪽으로 이동
-
j : 한 글자 아래로 이동
-
k : 한 글자 위로 이동
-
l : 한 글자 오른쪽으로 이동
-
-
2) 단어 단위 커서 이동
( 소문자로 입력하면 특수문자를 별개의 단어로 인식
대문자로 입력하면 공백문자와 개행문자만으로 단어를 구분)-
w : 다음 단어의 첫 글자로 이동
-
b : 이전 단어의 첫 글자로 이동
-
e : 다음 단어의 마지막 글자로 이동
-
-
3) 줄 내부 커서 이동
-
0 : 줄의 첫 글자로 이동
-
$ : 줄의 마지막 글자로 이동
-
-
4) 화면 내부
-
H : 화면의 첫 줄로 이동
-
M : 화면의 가운데 줄로 이동
-
L : 화면의 마지막 줄로 이동
-
-
5) 문서 내부 커서 이동
- gg : 문서의 첫 줄로 이동 ( = [[ )
- G : 문서의 마지막 줄로 이동 ( = ]] )
- :숫자 : 숫자 만큼의 라인으로 이동
입력모드 전환
-
i : 커서 왼쪽으로 내용 입력
I : 그 줄의 맨 왼쪽에서 내용 입력
-
a : 커서 오른쪾으로 내용 입력
A : 커서 맨 오른쪽에서 내용 입력
-
o : 커서 아래쪽에 빈 줄 삽입 후 내용 입력
O : 커서 위쪽으로 빈 줄 삽입 후 내용 입력
-
s : 커서가 있던 글자를 지우고 내용 입력
S : 그 줄 전체가 사라지고 내용 입력
실행취소
-
u : 마지막으로 수행한 동작 취소 (되도리기)
- 닥시 누르면 취소한동작을 재수행 (다시 실행)
삭제
커서가 있는 줄의 내용만 삭제
-
x : 커서 뒤쪽의 내용을 삭제 (delecte 기능)
- 뒤쪽의 내용을 다 지우면 앞쪽의 내용을 삭제(backspace 전환)
-
X : 커서 앞쪽의 내용을 삭제 (backspace 기능)
- 앞쪾 내용을 다 지운 후 기능 전환
복사, 잘라내기, 붙여넣기
-
yy : 커서가 있는 줄 복사
-
숫자 + yy : 커서가 있는 줄 부터 숫자만큼의 줄 복사
-
y + 커서이동 : 커서가 이동해야 하는 만큼 복사
-
-
dd : 커서가 있는 줄 잘라내기
-
숫자 + dd : 커서가 있는 줄 부터 숫자만큼의 줄 잘라내기
-
d + 커서이동 : 커서가 이동해야 하는 만큼 잘라내기
-
-
p : 커서 오른쪽으로 붙여넣기
-
p : 커서 왼쪽으로 붙여넣기
실행모드 사용방법
줄 번호 출력, 숨기기
- :set nu : 줄 번호 출력
- :set nonu : 줄 번호 숨기기
찾기(검색)
-
/찾을내용 : 맨 위에서 아래로 탐색
-
?찾을내용 : 맨 아래에서 위로 탐색
-
동작 후 추가 입력
-
n : 검색 방향으로 다음 찾기
-
N : 검색 방향의 반대 방향으로 다음 찾기
-
찾아 바꾸기 (치환)
-
:[범위]s/찾을 내용/바꿀 내용/[옵션]
-
범위
-
생략 : 커서가 위치한 줄에서 특정 내용을 찾아 서 변경
-
n : n번째 줄에서 특정 내용을 찾아서 변경
-
n1,n2 : n1 번째 줄 부터 n2 번째 줄 까지 범위에서 특정 내용을 찾아서 변경
-
% : 문서 전체에서 특정 내용을 찾아서 변경
-
-
옵션
- g : 한 줄에 변경해야 하는 내용이 여러개인 경우 전체를 변경
-
커서 위치 확인
- f : 현재 파일의 이름과 커서의 위치를 출력
Linux 명령어 동작
- :! 명령어 : vi를 잠시 멈추고 Linux 명령어 동작
파일에 다른 내용 삽입
(: 뒤에 숫자를 입력해서 숫자번째 줄을 기준으로 동작 가능)
-
:.! 명령어 : 커서가 있던 줄의 내용을 지유고 명령어 동잡 결과 삽입
- 결과가 출력되는 명령어 사용
-
:r! 명령어 : 커서가 있는 줄 아래로 명령어 동작 결과 삽입
- 결과가 출력되는 명령어 사용
-
:r 파일명 : 커서가 있는 줄 아래로 다른 파일의 내용 삽입
저장, 종료, 불러오기
( !를 붙여서 강제 동작이 가능)
-
w : 저장
- w 파일명 : 다른 이름으로 저장
-
q : 종료
-
wq : 저장하고 종료
- wq 파일명 : 다른 이름으로 저장하고 종료
-
-
e 파일명 : 기존 문서를 종료하고 다른 파일 불러오기
- enew : 기존 문서를 종료하고 새 파일 열기
화면 분활
ctrl + w + n : 화면 분활
ctrl + w + w : 분활된 화면 간 커서 이동
리눅스 #5
사용자 / 그룹
사용자 계정
-
운영체제를 사용하기 위해 로그인 하는 계정
-
운영체제를 사용하는 사람들에게 각각 만들어주는 계정
-
권한을 부여하기 위해 사용
그룹
-
여러 사용자 계정을 하나의 객체로 묶어주기 위해 사용하는 계정
-
그룹에 권한을 부여하여 그룹에 소속된 모든 사용자들이 동일한 권한을 적용
사용자 계정
사용자 계정에 관련된 파일
#1
사용자 계정의 일반적인 정보가 저장된 파일
/etc/passwd
파일 정보 보는 방법
itbank:x:1000:1000:dust,,,:/home/itbank:/bin/bash-
itbank : 사용자명, 뒤의 정보가 어느 사용자의 정보인지 표시
-
x : 비밀번호, passwd 파일에는 보안상의 이유로 암호를 표시 X
-
1000(왼) : UID, 해당 사용자의 고유 번호
-
1000(오) : GID, 해당 사용자가 주요 그룹으로 지정한 그룹의 고유 번호
-
dust,,, : 사용자 별칭, GUI 환경에서 표시되는 이름, ID로 사용 X
-
/home/itbank : 사용자의 홈 디렉토리를 절대경로로 출력
- 홈 디렉토리에 찾아갈 때 무조건 이 정보를 참조한다
-
/bin/bash : shell, 사용자가 어떤 shell을 사용하는지 출력
UID / GID
-
UID : User ID, 사용자의 고유 번호
-
GID : Group ID, 그룹의 고유 번호
-
0 : root
-
1 ~ 999 : system or service accounts
-
1000 ~ : 일반 사용자 or 그룹
shell
-
운영체제에 명령어를 전달해주는 역할
-
shell은 종류가 다양하고, 운영체제에 따라 기본 설치되어 있는 shell이 다르다
-
현재 설치된 shell은 /etc/shells 파일에서 확인 가능
#2
사용자 계정의 고급 정보가 저장된 파일
/etc/shadow
파일 내용 보는 방법
itbank:$y$~$~~$~~~:19574:0:99999:7:::-
itbank : 사용자명, 뒤의 정보가 어느 사용자의 정보인지 표시
-
$y$~$~~$~~~ : 비밀번호, 사용자의 비밀번호를 암호화하여 저장
-
19574 : 암호 생성 일자, 1970년 1월 1일을 기준으로 며칠 후에 생성된 암호인지 표시
-
0 : 암호 최소 사용 일자
-
99999 : 암호 최대 사용 일자(암호 만료 일자)
-
7 : 암호 만료 전 경고 일자
(이 후의 정보는 거의 사용 X, 생략)
#3
사용자/그룹의 생성과 삭제 과정에서 적용되는 여러가지 설정이 저장된 파일
/etc/login.defs
사용자 계정 생성
useradd [옵션][값] ... [옵션][값] 사용자명
-
옵션
-
-u : UID 지정, 생성하는 사용자 계정의 고유 번호를 지정
-
-g : GID 지정, 함께 생성되는 그룹이 아닌 다른 그룹을 주요 그룹으로 사용
-
-m : make directory, 홈 디렉토리 생성
-
-c : 별칭 지정
-
-s : shell 지정, 운영체제에 설치된 shell을 절대경로로 작성
-
-d : 생성될 홈 디렉토리의 경로와 이름을 지정
절대경로로 작성, 홈 디렉토리의 상위 디렉토리(경로)는 미리 생성되어 있어야 한다
-
-k : skel 지정, 기본 디렉토리인 /etc/skel이 아닌 다른 디렉토리를 skel로 사용할 때 작성
-
-D : 사용자 생성 시 적용되는 몇 가지 기본 설정을 확인하는 옵션, 이 옵션을 사용하면 사용자 생성 X
추가 옵션을 사용하여 기본 정보 변경이 가능(ex. -b 옵션을 함께 사용하여 홈 디렉토리 생성 위치 변경)
-
/etc/skel
사용자 생성 시 함께 만들어지는 홈 디렉토리 내부에 복사될 개체들을 담아놓는 디렉토리
사용자 홈 디렉토리의 뼈대가 되는 디렉토리
이 디렉토리에 기본적으로 저장된 개체들은 사용자 홈 디렉토리의 필수 요소
/etc/default/useradd
사용자 생성 시 적용되는 몇 가지 기본 설정을 저장한 파일
useradd의 -D 옵션 사용 시 출력되는 정보는 이 파일의 내용이다
리눅스 #6
사용자 계정 정보 수정
-
usermod 옵션 값 [옵션][값]...[옵션][값] 사용자명
-
옵션은 useradd의 옵션 몇 가지를 제외 하고 전부 동일하게 사용 가능
-
-m 옵션은 move directory의 의미로 사용
-
-k 옵션과 -D 옵션은 usermod에서는 사용하지 않음
-
사용자 삭제
userdel [옵션] 사용자명
-
옵션
- r : 사용자 소유의 파일 / 디렉토리를 함께 삭제
그룹
-
여러 사용자를 하나의 그룹에 소속시켜서(하나로 묶어서) 사용
-
그룹에 관련된 파일
- /etc/group : 해당 그룹의 일반적인 정보를 저장한 파일
-
파일 내용 보는 방법
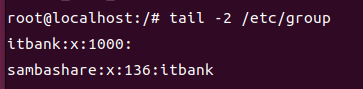
itbank:x:1000 :
itban : 그룹명, 뒤의 정보들이 어느 그룹의 정보인지 출력
x : 암호, 그룹은 암호를 사용하지 않는다
1000 : GID, 해당 그룹의 고유번호
마지막 필드 : 해당 그루븽 일반 소속된 사용자 목록
그룹 생성
groupadd [옵션][값]...[옵션][값] 그룹명
- 옵션
- -g : GID 지정
그룹 정보 수정
gorupmode 옵션 값 [옵션][값]...[옵션][값] 그룹명
-
옵션
-
-g : GID 지정
-
-n : 이름 변경
-
그룹 삭제
gropdel 그룹명
- 사용자가 주요 그룹으로 지정한 그룹은 삭제할 수 없다
사용자 + 그룹
-
사용자가 그룹에 소속되는 방식을 크게 두 가지로 나눔
1 ) 사용자가 그룹을 자신의 주요 그룹으로 사용( GID로 사용)
2) 사용자가 그룹에 일반 소속
- 사용자는 필요에 따라 여러 그룹에 빌반 소속 시킬 수 있다
-
사용자가 그룹에 소속되는 방식은 필요에 따라 제어할 수 있다
1) 주요 그룹(GID) 지정
-
사용자를 생성하면 사용자의 이름과 같은 이름의 그룹을 함께 생성하고
만들어지는 사용자는 함께 생성된 그룹을 자신의 주요 그룹을 지정
2) 일반 소속
-
사용자는 처음에 일반 소속된 그룹이 없는 상태
-
usermod 명령의 -G 옵션을 사용하거나 gpasswd 명령을 사용하여 사용자가 일반 소속된 그룹의 정보를 제어할 수 있다
(단 usermod의 -G 옵션은 가급적 사용하지 않는다)
-
passwd
-
사용자의 암호를 제어하는 명령어
-
형식
-
passwd : 명령어를 입력한 사용자 자신의 암호를 변경 ( 모든 사용자 가능)
-
passwd 사용자명 : 해다 ㅇ사용자의 암호를 변경( 관리자만 가능)
-
gpasswd
-
그룹의 일반 소속된 사용자 목록을 보여주는 명령어
-
형식 : gpasswd 옵션 값 그룹명
-
옵션
-
-a : 그룹에 특정 사용자를 일반 소속
-
-d : 그룹에서 특정 사용자를 제외
-
권한
파일이나 디렉토리를 사용할 수 있는지 정하는 개념
(허가권 + 소유권 = 권한)
허가권
-
실제 적용되는 권한 값들을 나열해놓은 영역
-
ls 옵션의 -l 옵션이나 -n 옵션을 사용했을 때 나오는 내용 중 개체 형식 문자 뒤에 붙은 9자리 문자가 허가권 영역
-
8종류의 문자로 각종 권한을 표현 : r,w,x,-,s,S,t,T
-
r,w,x,- : 일반 권한 표현 문자
-
s,S,t,T : 특수 권한 표현 문자
-
-
일반 권한 표현 문자의 의미
-
r : 읽기
-
파일 : 파일 내용을 읽기 위한 권한 (cat,head, tail, less, vi로 열었을 때 등)
-
디렉토리 : 디렉토리 내부 목록 확인을 위한 권한 (ls 명령어, GUI 환경에서 폴더 열었을때 등)
-
-
w : 쓰기
-
파일 : 파일의 내용을 수정하기 위한 권한 ( 문서 편집 후 저장, > 기호를 이용하여 덮어쓰기 / 내용추가 등)
-
디렉토리 : 디렉토리 내에 하위 파일 / 디렉토리를 생성 또는 삭제하기 위한 권한
-
-
x : 접근 / 실행
- 파일 : 실행 (파일에 x 가 없으면 일반 문서 파일, x가 있다면 실행파일 (ex. 명령어 등))
- 디렉토리 : 접근 ( 디렉토리에 x 가 없으면 해당 디렉토리와 내부의 갸ㅐ체드를 사용할 수 없다
-
- : 권한 없음
-
허가권 영역에서 r,w,x 문자를 대체하여 입력
- 이 입력된 권한은 없는 권한이다
-
허가권 9자리의 권한 문자는 3개씩 끊어서 Owner, Group., Other 영역으로 구분
각 영역엑는 r,w,x가 순서대로 들어가고, 특정 권한이 없으면 r,w,x 대신 - 이 들어간다
-
Owner : 소유자 ( 파일 / 디렉토리를 소유하고 있는 사용자) 를 위한 권한 영역
-
Group : 그룹 사용자( 파일 /디렉톨티를 소유하고 있는 그룹에 소속된 사용)를 위한 권한 영역
-
Other : 그 외 사용자를 위한 권한
(Linux의 모든 파일/ 디렉토리는 반드시 하나의 사용자와 하나의 그룹이 소유하도록 되어있다)
-
허가권 표현 방법
-
문자를 이용한 방법 : r,w,x,- 문자를 보이는 순서대로 읽어주는 방법
-
숫자를 이용한 방법 : 권한 문자를 바탕으로 숫자값을 계산
-
영역 분리
-
r = 4, w = 2, x = 1, - = 0 을 각 영역의 문자에 대입 후 영역별 합을 계산
-
각 영역에서 구한 합에 Owner은 100, Group은 10, Other은 1을 곱해서 전체 합 계산
-
허가권 변경
chmod [옵션] 권한값 대상 [대상]...[대상]
-
권한값 작성 방식 : 권한값을 숫자 또는 문자로 입력
-
숫자로 입력 : numeri method : 변경할 권한 전체를 숫자로 입력
-
문자로 입력 : symbolic method : 영역 문자에 +,- 기호를 사용하여 더하거나 뺸다
-
symbolic method 에서 사용하는 영역 문자
-
u : Owner
-
g : Group
-
o : Other
-
-
-
소유권
자바 변수의 타입
기본형 변수 (primitive type)
아래 8가지 종류들로, 실제 연산을 위한 값들이 메모리에 저장된다
자바는 C언어와 달리 참조형 변수간의 연산을 할 수 없으므로 실제 연산에 사용되는 것은 모두 기본형 변수이다
-
논리형 (Boolean) : true / false로 구분되며, 조건식과 논리 게이트에 사용된다.
-
문자형 (char) : 문자를 저장하는데 사용되며, 하나의 문자만 저장할 수 있다. 저장되는 값은 유니코드 값으로 정수형과 크게 다르지 않다
-
정수형(byte, short, int, long) : 정수를 저장하는데 사용되며 int형이 가장 많이 사용된다.
-
실수형 (float, double) : 주로 소수점이 붙은 값을 저장하는데 사용된다
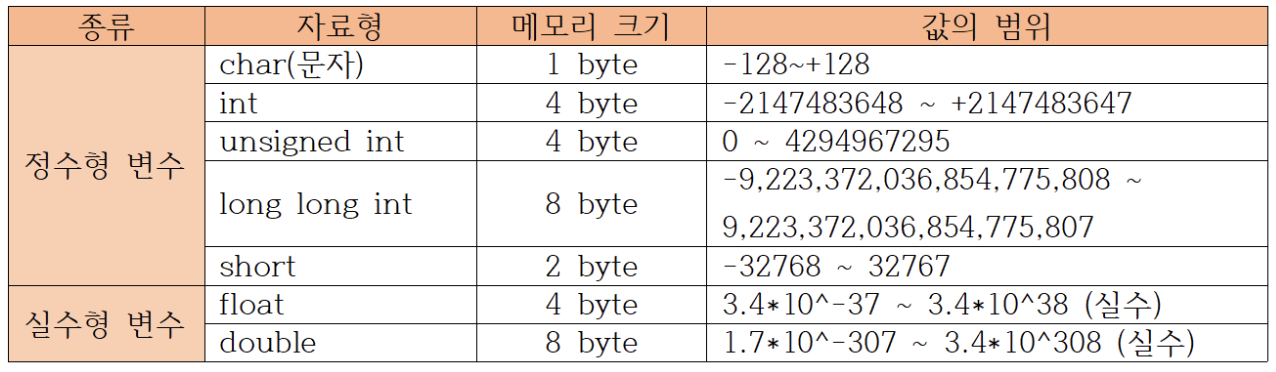 각 타입들의 변수들이 저장할 수 있는 값의 범위는 위와같다
각 타입들의 변수들이 저장할 수 있는 값의 범위는 위와같다
참조형 변수 (referemce type)
객체의 주소를 저장하기 위한 변수이다. 8개의 기본형을 제외한 나머지 타입
참조형 변수를 선언할 때는 변수의 타입으로 클래스의 이름을 사용하므로 클래스의 이름이 참조변수의 타입이 된다
참조변수의 선언
기본형 변수와 같이 변수 이름 앞에 타입을 적어주면된다. 여기서 참조변수의 타입은 클래스의 이름이다
Date today = new Date(); //Date 객체를 생성해서 그 주소를 today에 저장함
Data타입의 today라는 참조변수를 선언한 것이다
new 연산자의 결과로 참조변수 today에 Date 객체의 주소를 저장했다
상수, 리터럴 (literal & constant)
-
변수 : 하나의 값을 저장하기 위한 공간
-
상수 : 값을 한번만 저장할 수 있는 공간
-
리터럴 : 그 자체로 값을 의미하는 것
상수
상수는 한번 값을 저장하면 이후에 값을 변경하지 못한다
상수를 선언함과 동시에 초기화를 해주어야한다
상수의 이름은 모두 대문자로 하는것이 관례이며, 여러 단어로 이루어져있는 경우 ' _ ' 으로 구분한다
package Ch02;
public class EX02 {
public static void main(String[] args) {
// TODO Auto-generated method stub
final int MIN_SPEED = 10; // 상수 MIN_SPEED를 선언 & 초기화
final int MAX_SPEED; // 에러 : 선언과 동시에 초기화 해주어야함
final int MAX_VALUE = 10;
MAX_VALUE = 20; // 에러 : 상수의 값은 변경 불가
}
}
리터럴
수학에서 사용되는 상수 용어가 프로그래밍에서 '한 번 저장하면 변경할 수 없는 저장공간' 이라는 의미로 정의하였기 때문에 이와 구분하기 위해 리터럴이라는 용어를 사용한다
상수가 필요한 이유
삼각형과 사각형의 넓이를 구해서 변수에 저장하는 코드이다
int triangleArea = (20 * 10) / 2; // 삼각형 면적
int reactangleArea = 20 * 10; // 사각형 면적 식이 간단해서 의미가 없지만, 만약 값이 10과 20을 사용하지 않게 된다면 여러곳을 수정해야한다
final int WIDTH = 20;
final int HEIGHT = 10;
int reactangleArea = WIDTH * HEIGHT; // 사각형 면적
int triangleArea = (WIDTH * HEIGHT) / 2; // 삼각형 면적 하지만 상수를 사용하게 된다면 값을 바꾸기 위해 초기화를 다른 수로 저장하면되고, 상대적으로 가독성이 좋다.
이처럼 상수는 리터럴에 의미있는 이름을 붙여서 코드의 이해와 수정을 쉽게 만든다
객체지향
코드 간의 관계를 맺어 줌으로써 보다 유기적으로 프로그램을 구성하는 것
-
코드의 재사용이 쉽다
새로운 코드를 작성할 때 기존의 코드를 이용하여 쉽게 작성할 수 있다 -
코드의 관리가 용이하다
코드간의 관계를 이용해서 적은 노력으로 쉽게 코드를 변경할 수 있다 -
신뢰성이 높은 프로그래밍을 가능케 한다
제어자와 메서드를 이용해서 데이터들을 보호하고 올바른 값을 유지하도록 하며, 코드의 중복을 제거하여 코드의 불일치로 인한 오작동을 막을 수 있다
클래스 & 객체 #1
클래스 & 객체
클래스
-
정의 : 객체를 정의해둔 것
-
용도 : 객체를 생성하는데 사용된다
객체의 설계도라고 정의할 수 있다.
객체
-
정의 : 실제로 존재하는 것 (사물 또는 개념)
-
용도 : 객체가 가지고 있는 기능과 속성에 따라 다름
객체 & 인스턴스
클래스로 부터 객체를 만드는 과정을 클래스의 인스턴스화 (instantiate) 라고 하며, 어떤 클래스로부터 만들어진 객체를 그 클래스의 인스턴스 (instance) 라고 한다
책상은 책상 클래스의 인스턴스다 라고 할 수 있다
클래스 --> (인스턴스화) --> 인스턴스(객체)
객체의 구성요소
객체는 속성 + 기능으로 이루어져있다
일반적으로 객체는 다수의 속성과 다수의 기능을 갖는다
여기서 속성과 기능을 멤버라고 부른다
-
속성 : 멤버변수, 특성, 필드, 상태
-
기능 : 메서드, 함수, 행위
예를들어 Tv클래스를 만들어보았다
class TV {
String color; // 색깔
boolean power; //전원 상태
int channel; // 채널
void power(){
power = !power;
}
void setChannelp(){
channel++;
}
void setChannelDown(){
channel--;
}
}인스턴스의 생성과 사용
package CH06;
class Tv {
String color; // 색깔
boolean power; //전원 상태
int channel; // 채널
void power(){
power = !power;
}
void setChannelp(){
channel++;
}
void setChannelDown(){
channel--;
}
}
public class EX01 {
public static void main(String[] args){
Tv t;
t = new Tv();
t.channel = 7;
t.setChannelDown();
System.out.println("현재 채널 : "+ t.channel);
}
}
-
Tv t;
Tv클래스 타입의 참조변수 t를 선언한다 -
t = new Tv();
new 연산자에 의해 Tv클래스의 인스턴스가 메모리의 빈 공간에 생성된다 -
t.channel = 7;
참조 변수 t에 저장된 주소에 있는 인스턴스의 멤버변수 channel애 7을 저장한다 -
t.channelDown();
참조변수 t가 참조하고있는 Tv 인스턴스의 channelDown 메서드를 호출한다.인스턴스는 참조변수를 통해서만 다룰 수 있으며, 참조변수의 타입은 인스턴스의 타입과 일치해야한다
class Tv {
String color; // 색깔
boolean power; //전원 상태
int channel; // 채널
void power(){
power = !power;
}
void setChannelp(){
channel++;
}
void setChannelDown(){
channel--;
}
}
public class EX02 {
public static void main(String[] args){
Tv t1 = new Tv();
Tv t2 = new Tv();
System.out.println("t1의 channel 값 : " + t1.channel);
System.out.println("t2의 channel 값 : " + t2.channel);
t1.channel = 7;
System.out.println("t1의 channel 값을 7로 변경");
System.out.println("t1의 channel 값 : " + t1.channel);
System.out.println("t2의 channel 값 : " + t2.channel);
}
}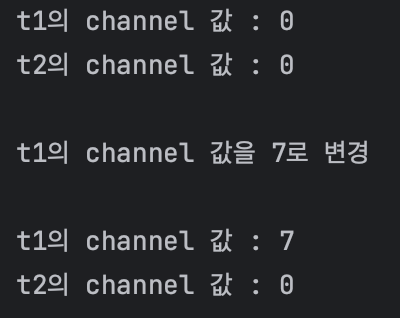
같은 클래스로부터 생성되었을지라도, 각 인스턴스의 속성은 서로 다른 값을 유지할 수 있으며, 메서드의 내용은 모든 인스턴스에 대해 동일하다
package CH06;
class Tv {
// Tv의 속성(멤버변수)
String color; // 색상
boolean power; // 전원상태(on/off)
int channel; // 채널
// Tv의 기능(메서드)
void power() { power = !power; } // TV를 켜거나 끄는 기능을 하는 메서드
void channelUp() { ++channel; } // TV의 채널을 높이는 기능을 하는 메서드
void channelDown() { --channel; } // TV의 채널을 낮추는 기능을 하는 메서드
}
public class EX03 {
public static void main(String[] args){
Tv t1 = new Tv();
Tv t2 = new Tv();
System.out.println("t1의 channel 값 : " + t1.channel);
System.out.println("t2의 channel 값 : " + t2.channel);
t2 = t1;
t1.channel = 7;
System.out.println("t1의 channel 값을 7로 변경");
System.out.println("t1의 channel 값 : " + t1.channel);
System.out.println("t2의 channel 값 : " + t2.channel);
}
}

참조변수에서는 하나의 값만이 저장될 수 있으므로 둘 이상의 참조변수가 하나의 인스턴스를 가리키는(참조하는) 것은 가능하지만, 하나의 참조변수로 여러개의 인스턴스를 가리키는 것은 가능하지 않다
클래스 & 객체 #2
객체 배열
많은 수의 객체들을 다뤄야 할 때, 배열로 다루면 편리할 것이다
- 길이가 3인 객체 배열 tvArr을 생성하면 각 요소는 참조변수의 기본값인 null로 자동 초기화 된다
Tv tv1, tv2, tv3;
Tv[] tvArr = new Tv[3]; // 길이가 3인 Tv타입의 참조변수 배열
tvArr : 0x100 >> (0x100) >> tvArr[0] : null, tvArr[1] : null, tvArr[2] : null
이렇게 객체 배열을 생성하는 것은 그저 객체를 다루기 위한 참조변수들이 만들어진 것일 뿐, 아직 객체가 저장되지 않았다
객체를 생성해서 객체 배열의 각 요소에 저장하는 것을 잊으면 안 된다
tvArr[0] = new Tv();
tvArr[1] = new Tv();
tvArr[2] = new Tv();배열의 초기화 블럭을 사용하면 다음과 같이 한 줄로 간단히 할 수 있다
Tv[] tvArr = { new Tv(), new Tv(), new Tv()};단, 다루어야할, 객체의 수가 많을 때는 for 문을 사용하면 된다
Tv[] tvArr3 = new Tv[100];
for(int i=0; i < tvArr1.length; i++){
tvArr3[i] = new Tv();
} 모든 배열이 그렇듯이 객체 배열도 같은 타입의 객체만 저장할 수 있다.
package CH06;
class Tv {
// Tv의 속성(멤버변수)
String color; // 색상
boolean power; // 전원상태(on/off)
int channel; // 채널
// Tv의 기능(메서드)
void power() {
power = !power;
} // TV를 켜거나 끄는 기능을 하는 메서드
void channelUp() {
++channel;
} // TV의 채널을 높이는 기능을 하는 메서드
void channelDown() {
--channel;
} // TV의 채널을 낮추는 기능을 하는 메서드
}
public class EX05 {
public static void main(String[] args){
Tv[] tvArr = new Tv[3];
for(int i=0; i < tvArr.length; i++){
tvArr[i] = new Tv();
tvArr[i].channel = i+10; // tvArr[i]의 channel에 i + 10을 저장
}
for(int i = 0; i < tvArr.length; i++){
tvArr[i].channelUp();
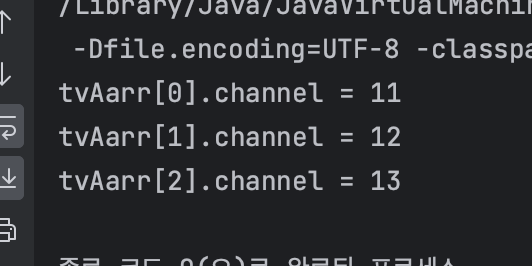
System.out.printf("tvAarr[%d].channel = %d%n",i,tvArr[i].channel);
}
}
}
클래스의 또 다른 정의
클래스는 객체를 생성하기 위한 틀이며 클래스는 속성과 기능으로 정의되어있다
이것은 객체지향 이론의 관점에서 내린 정의이고, 이번엔 프로그래밍 관점에서 클래스의 정의와 의미를 공부할 것이다
1. 데이터와 함수의 결합
프로그래밍 언어에서 데이터 처리를 위한 데이터 저장 형태의 발전과정은 다음과 같다
-
변수 : 하나의 데이터를 저장할 수 있는 공간
-
배열 : 같은 종류의 여러 데이터를 하나의 집합으로 저장할 수 있는 공간
-
구조체 : 서로 관련된 여러 데이터를 종류에 상관없이 하나의 집합으로 저장할 수 있는 공간
-
클래스 : 데이터와 함수의 결합 (구조체 + 함수)
2. 사용자정의 타입 (user-defined type)
사용자정의 타입이란, 기본 자료형 이외에 프로그래머가 서로 관련된 변수들을 묶어서 하나의 타입으로 새로 추가하는 것
시간을 표현하기 위해서 다음과 같은 3개의 변수를 선언하였다
int hour;
int minute;
int second;만약 3개의 시간을 다루어야한다면, 다음과 같이 해야한다
int hour1, hour2,hour3;
int minute1, minute2, minute3;
int second1, second2, second3;
이렇게 다뤄야 할 시간의 개수가 늘어날 때마다 변수를 늘려주어야 한다
int[] hour = new int[3];
int[] minute = new int[3];
float[] second = new float[3];배열로 처리한다면 데이터의 개수가 늘어나도 배열의 길이만 변경해주면 되기 때문에, 변수를 매번 선언해줘야 하는 불편함과 복잡성은 사라지지만,
하나의 시간을 구성하는 시, 분, 초가 따로 분리되어있기 때문에 프로그래밍 수행 과정에서 올바르지 않은 데이터가 될 가능성이 있다
이런 경우 시, 분, 초를 하나로 묶는 클래스를 정의해야 한다
class Time {
int hour;
int minute;
int second;
}변수 + JVM 메모리 구조
선언 위치에 따른 변수의 종류
변수의 종류를 결정짓는 중요한 요소는 '변수가 선언된 위치' 이다
변수의 종류를 파악하기 위해서는 변수가 어느 영역에 선언되었는지 확인하는 것이 중요하다
class Variables{
int iv; // 인스턴스 변수
static int cv; // 클래스 변수 (static 변수, 공유변수)
void method() {
int lv; // 지역변수
}
}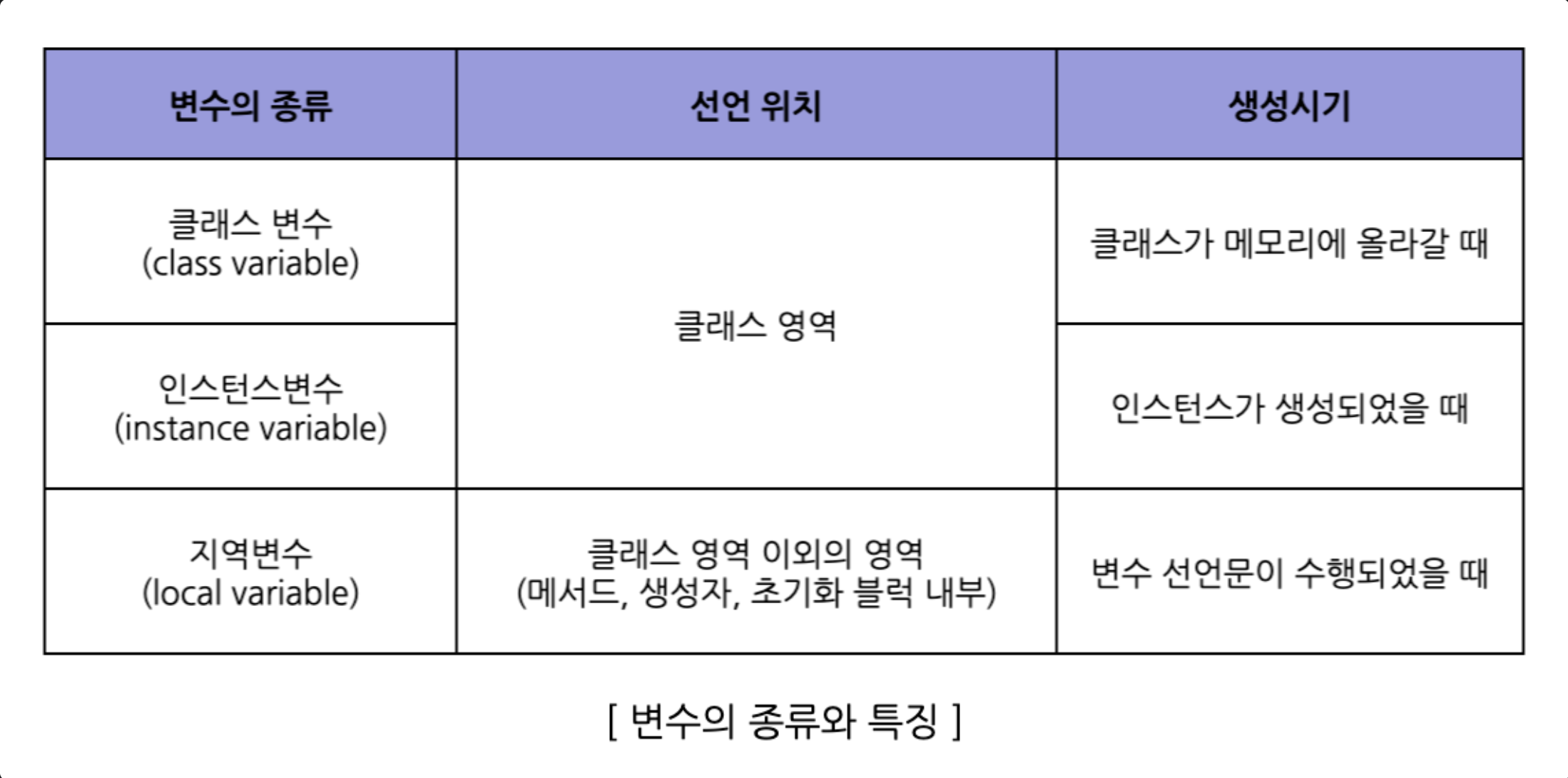
인스턴스 변수 (instance variable)
-
클래스 영역에 선언된다
-
클래스의 인스턴스를 생성할 때 만들어진다
인스턴스 변수의 값을 읽어오거나 저장하기 위해서는 인스턴스를 생성해야한다
-
인스턴스는 독립적인 저장공간을 가지므로 서로 다른 값을 가질 수 없다
-
인스턴스마다 고유한 상태를 유지해야하는 속성의 경우 인스턴스 변수로 선언한다
클래스 변수 (class variable)
-
선언 하는 법 : 변수 앞에 static을 붙인다
-
모든 인스턴스는 공통된 변수를 공유한다
-
한 클래스의 모든 인스턴스들이 공통적인 값을 유지해야하는 속성의 경우 클랫 변수로 선언해야한다
-
인스턴스를 생성하지 않아도 언제라도 바로 사용할 수 있다
-
메모리에 로딩 될 때 생성되어 프로그램이 종료될 때 까지 유지된다
-
맨 앞에 public를 붙이면 프로그램 어디서나 접근할 수 있는 전역변수의 성격을 갖는다
지역변수 (local variable)
-
메서드 내에 선언되어 메서드 네에서만 사용 가능하다
-
메서드가 종료되면 소멸된다
클래스 변수 & 인스턴스 변수
두 변수의 차이를 이해하기 위해 트럼프 카드를 클래스로 정의해보았다
카드 클래스를 작성하기 위해서 먼저 카드의 속성과 기능을 알아야 한다
카드의 무늬, 폭, 높이 정도를 생각했다
어떤 변수를 클래스 변수로, 어떤 변수를 인스턴스 변수로 선언할지 생각한다
class card {
String kind; // 무늬
int number; // 숫자
static int width = 100; // 폭
static int height = 250; // 높이
}각 card 인스턴스는 각 카드마다 다른 무늬와 숫자를 가지고 있어야 하므로 인스턴스 변수로 선언하였고,
모든 카드의 폭과 높이는 같아야하기 때문에 클래스 변수로 선언하였다
카드의 폭이 변하는 경우 모든 카드의 width 변수값을 변경하지 않고, 한 카드의 width 값만 변경하여도 모든 카드의 width 값이 변경된다
package CH06;
class Card {
String kind; // 무늬
int number; // 숫자
static int width = 100; // 폭
static int height = 250; // 높이
}
public class EX08 {
public static void main(String[] args){
System.out.println("card.width : " + Card.width);
System.out.println("card.height : " + Card.height);
Card c1 = new Card();
c1.kind = "Heart";
c1.number = 7;
Card c2 = new Card();
c2.kind = "Spade";
c2.number = 4;
System.out.println("c1은 " + c1.kind + "," + c1.number + " 이며, 크기는" + c1.width + "," + c1.height);
System.out.println("c2는 " + c2.kind + "," + c2.number + " 이며, 크기는" + c2.width + "," + c2.height);
System.out.println("c1의 width와 height 값을 각각 50 80 으로 변경합니다");
c1.width = 50;
c1.height = 80;
System.out.println("c1은 " + c1.kind + "," + c1.number + " 이며, 크기는" + c1.width + "," + c1.height);
System.out.println("c2는 " + c2.kind + "," + c2.number + " 이며, 크기는" + c2.width + "," + c2.height);
}
}
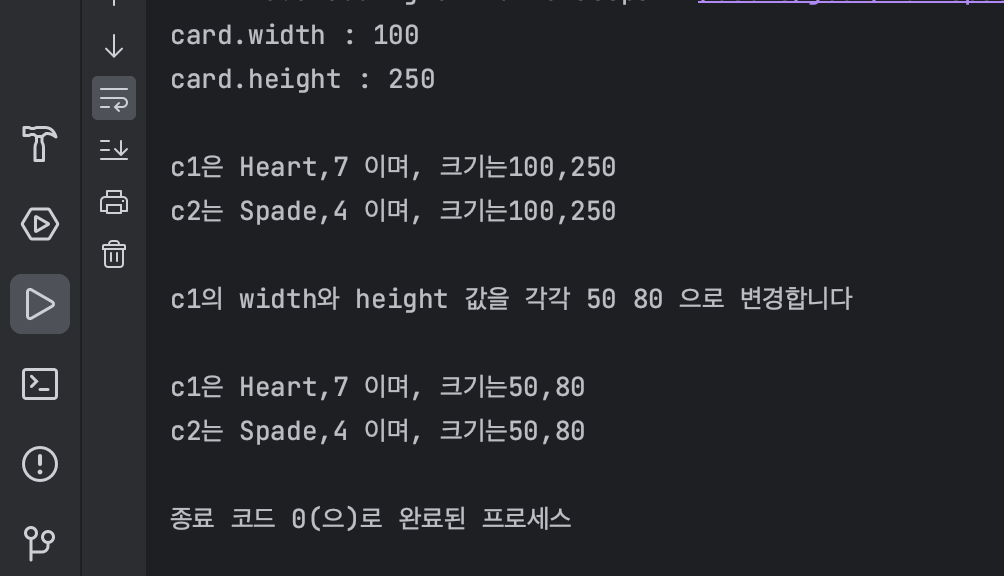
Card의 클래스 변수(static 변수)인 width와 height는 Card 클래스의 인스턴스를 생성하지 않고도 사용할 수 있다
Card 인스턴스인 c1와 c2는 클래스 변수인 width와 height를 공유하기 때문에 c1의 height 와 width를 변경하면 c2의 height 와 width 또한 변경된다
Card.width, c1.width, c2.width는 모두 같은 저장공간을 참조하므로 항상 같은 값을 갖는다
JVM의 메모리 구조
응용프로그램이 실행되면, JVM은 시스템으로부터 프로그램을 수행하는데 필요한 메모리를 할당받고 JVM은 이 메모리를 용도에 따라 영역으로 나누어 관리한다
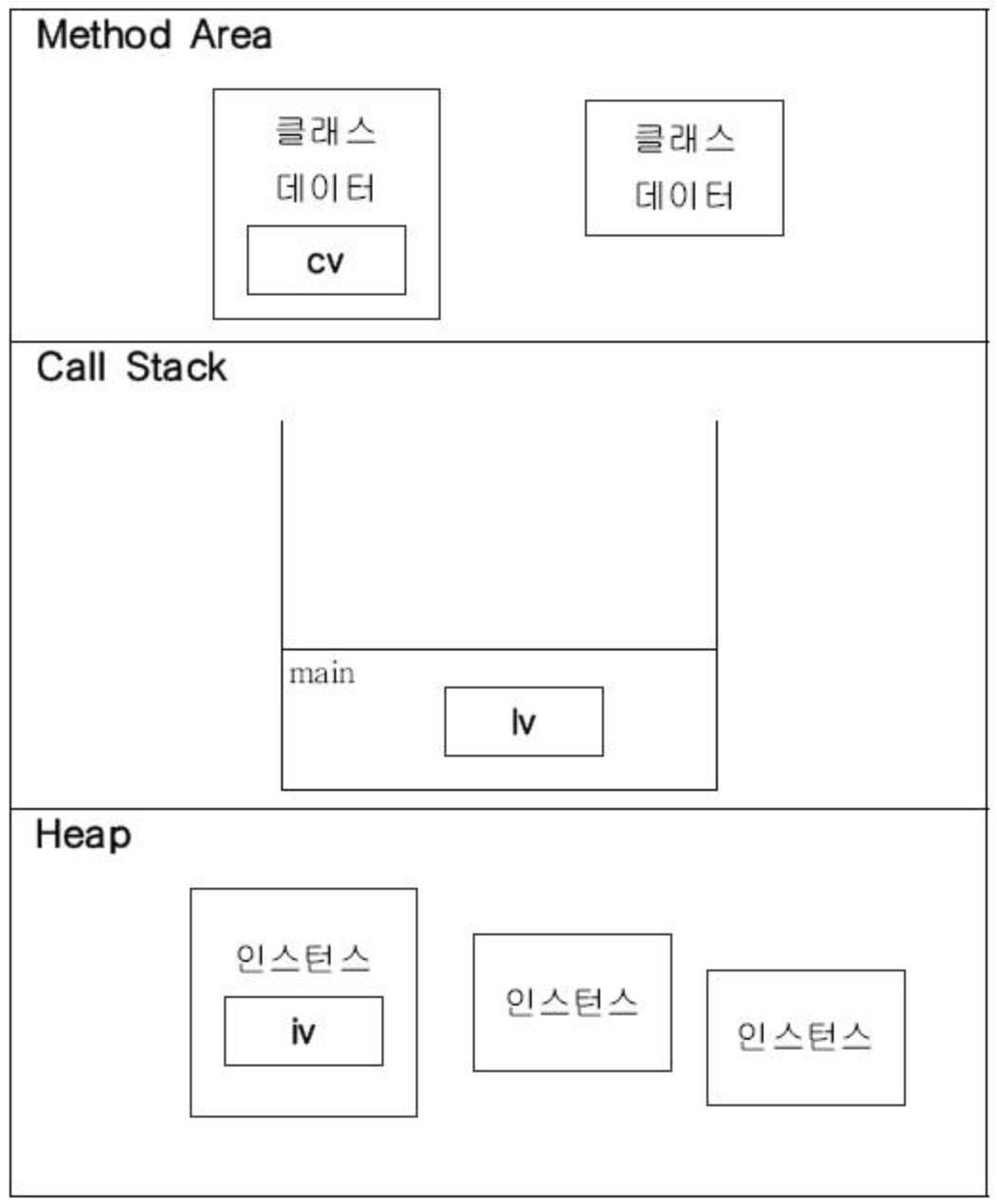
메서드 영역 (Method AREA)
프로그램 실행 중 어떤 클래스가 사용되면 JVM은 해당 클래스의 클래스파일(*.class)을 읽어서 분석하여 클래스에 대한 정보 (클래스 데이터)를 이곳에 저장한다. 이 때, 그 클래스의 클래스 변수 (class variable)도 이 영역에 함께 생성된다
힙 (heap)
인스턴스가 생성되는 공간, 프로그램 실행 중 생성되는 인스턴스는 모두 이곳에 생성된다
즉 인스턴스 변수들이 생성되는 공간이다
호출스택 (call stack & exection stack)
호출스택 메서드의 작업에 필요한 메모리 공간을 제공한다
메서드가 호출되면, 호출스택에 호출된 메서드를 위한 메모리가 할당되며, 이 메모리는 메서드가 작업을 수행하는 동안 지역변수 (매개변수 포함) 들과 연산의 중간결과 등을 저장하는데 사용된다
메서드가 작업을 마치면 할당되었던 메모리 공간을 반환되어 비워진다
동작 순서
-
메서드가 호출되면 수행에 필요한 만큼의 메모리를 스택에 할당받는다
-
메서드가 수행을 마치고 나면 사용했던 메모리를 반환하고, 스택에서 제거된다
-
호출스택의 제일 위에 있는 메서드가 현재 실행중인 메서드이다
-
아래에 있는 메서드가 바로 위의 메서드를 호출한 메서드이다
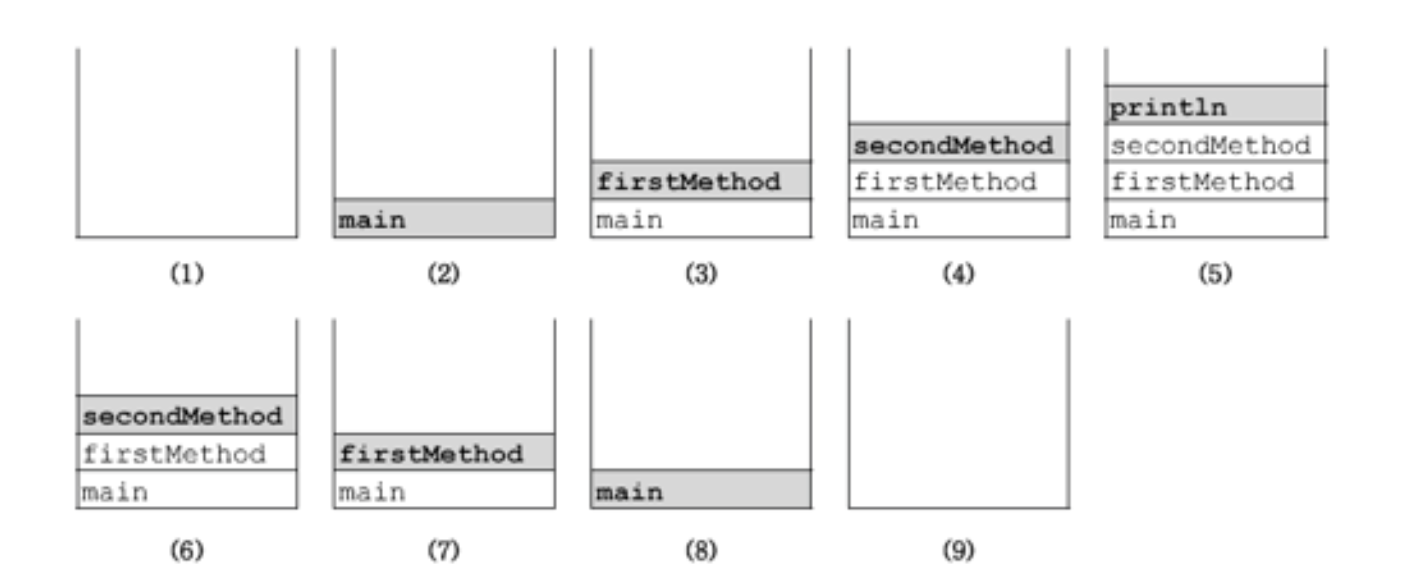
package CH06;
public class EX09 {
public static void main(String[] args){
firstMethod(); //
}
static void firstMethod(){
secondMethod();
}
static void secondMethod(){
System.out.println("secondMethod()");
}
}
메서드
클래스 메서드 (static 메서드) & 인스턴스 메서드
변수에서와 같이 static이 붙어있으면 클래스 메서드, 없으면 인스턴스 메서드이다
-
클래스 메서드도 클래스 변수처럼 객체를 생성하지 않고 호출이 가능하다
-
반면 인스턴스 메서드는 객체를 생성하여 호출해야한다
인스턴스 메서드
인스턴스 메서드는 인스턴스 변수와 관련된 작업을 하는, 즉 메서드의 작업을 수행하는데 인스턴스 변수를 필요로 하는 메서드이다
인스턴스 변수는 인스턴스(객체)를 생성해야만, 사용가능하기 때문에 인스턴스 메서드 또한 인스턴스를 생성해야만 호출 할 수 있다
클래스 메서드 (static 메서드)
인스턴스와 관계 없는 (인스턴스 변수나 인스턴스 메서드를 사용하지 않는) 메서드를 클래스 메서드라고 정의한다
물론 인스턴스 변수를 사용하지 않는다고 해서 반드시 클래스 메서드로 정의해야 하는 것은 아니지만, 특별한 이유가 없다면 클래스 메서드로 정의하는 것이 일반적이다
정리
#1
클래스를 설계할 때 멤버변수 중 모든 인스턴스에 공통적으로 사용하는 것에 static를 붙인다
-
생성된 각 인스턴스는 서로 독립적이기 때문에 각 인스턴스의 변수 (iv) 는 서로 다른 값을 유지한다
-
그러나 모든 인스턴스에서 같은 값이 유지되어야 하는 변수는 static을 붙여서 클래스 변수로 정의해야 한다
#2
클래스 변수 (static 변수)는 인스턴스 변수를 사용할 수 없다
- static이 붙은 변수 (클래스 변수) 는 클래스가 메모리에 올라갈 때 이미 자동적으로 생성되기 때문이다
#3
클래스 메서드에는 인스턴스 변수를 사용할 수 없다
-
인스턴스 변수는 인스턴스가 반드시 존재해야 사용할 수 있지만, 크래스 메서드는 인스턴스 생성 없이 호출이 가능하므로 클래스 메서드가 호출되었을 때 인스턴스가 존재하지 않을 수 있다
-
반면에 인스턴스 변수나 인스턴스 메서드에서는 static이 붙은 멤버들을 사용하는 것이 언제나 가능하다. 인스턴스 변수가 존재한다는 것을 의미하기 때문이다
#4
메서드 내에서 인스턴스 변수를 사용하지 않는다면 static을 붙이는 것을 고려한다
-
메서드의 작업내용 중에서 인스턴스 변수를 필요로 한다면 static을 붙일 수 없다
-
인스턴스 변수를 필요로 하지 않는다면 static을 붙이자. 메서드 호출시간이 짧아지므로, 성능이 향상된다. static을 안 붙인 메서드는 실행시 호출되어야할 메서드를 찾는 괒어이 추가적으로 필요하기 때문에 시간이 더 걸린다
package CH06;
class MyMath2 {
long a,b;
// 인스턴스 변수 a,b 만을이용해서 작업하므로 매개변수가 필요없다
long add() {
return a + b;
}
long subtract() {
return a - b;
}
long multiply() {
return a * b;
}
long divide() {
return a / b;
}
// 인스턴스변수와 관계없이 매개변수만으로 작업이 가능하다.
static long add (long a, long b) {
return a + b;
}
static long substract (long a, long b) {
return a - b;
}
static long multiply (long a, long b) {
return a * b;
}
static long divide (long a, long b) {
return a / b;
}
}
public class EX10 {
public static void main(String[] args) {
//클래스 메서드 호출, 인스턴스 생성없이 호출 가능
System.out.println(MyMath2.add(200L, 100L));
System.out.println(MyMath2.substract(200L, 100L));
System.out.println(MyMath2.multiply(200L, 100L));
System.out.println(MyMath2.divide(200L, 100L));
MyMath2 mm = new MyMath2();
mm.a = 200L;
mm.b = 100L;
System.out.println(mm.add());
System.out.println(mm.subtract());
System.out.println(mm.multiply());
System.out.println(mm.divide());
}
}
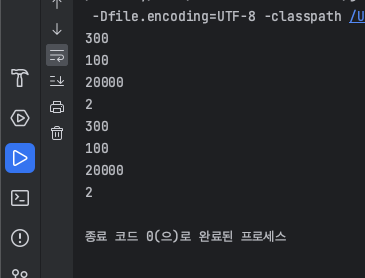
인스턴스 메서드인 add()와 같이 매개변수가 없는 인스턴스 메서드들은 a와 b만으로도 충분히 작업이 가능하기 때문에 매개변수를 선언하지 않았다
반면 static long add(long a, long b) 와 같이 매개변수와 static가 있는 있는 클래스 메서드 들은 매개변수 만으로 작업을 수행하기 때문에 매개변수를 선언ㄹ하였다
그리고 인스턴스 매서드들은 인스턴스를 생성해야 사용할 수 있다
클래스 멤버와 인스턴스 멤버간의 참조와 호출
인스턴스 멤버가 존재하는 시점에 클래스 멤버는 항상 존재하지만, 클래스 멤버가 존재하는 시점에 인스턴스 멤버가 존재하지 않을 수도 있기 때문에 같은 클래스에 속해있는 멤버들 간에는 별도의 인스턴스를 생성하지 않고 서로 참조 또는 호출이 가능하다
class TestClass {
void instanceMethod() {}
static void staticMethod() {}
void instanceMethod2() {
instanceMethod();
staticMethod();
}
static void staticMethod2() {
instanceMethod(); // 에러 >> 인스턴스 메서드를 호출할 수 없다
staticMethod();
}
}같은 클래스 내의 메서드는 서로 객체의 생성이나 참조변수 없이 직접 호출이 가능하지만, static메서드는 인스턴스 메서드를 호출할 수 없다
class TestClass2 {
int iv;
static int cv;
void instanceMethod(){
System.out.println(iv);
System.out.println(iv);
}
static void staticMethod(){
System.out.println(iv); // 에러 >> 인스턴스 변수를 사용할 수 없다
System.out.println(cv);
}
}메서드간의 호출과 마찬가지로 인스턴스 메서드는 인스턴스 변수를 사용할 수 있지만, static메서드는 인스턴스 변수를 사용할 수 없다
Java String Class Method
문자열 관련 메서드
-
.toLowerCase() : 지정 된 문자열을 소문자로 반환
-
.toUpperCase() : 지정 된 문자열을 대문자로 반환
String str = new String("Java is Easy");
System.out.println("기본 : " + str );
System.out.println("소문자 변환" + str.toLowerCase());
System.out.println("대문자 변환" + str.toUpperCase());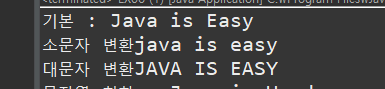
- .replace("old","new") : 지정 된 문자를 새로운 문자로 치환
String str = new String("Java is Easy");
String changeStr = new String();
changeStr = str.replace("Easy", "Hard");
System.out.println("문자열 치환 : " + changeStr);
- .split(regex) : 지정 된 값을 기준으로 문자열을 분리
이 메서드의 경우 배열을 이용하여 분리 된 문자열을 따로 저장
String str = new String("Java is Easy");
String[] arrStr = str.split("is");
System.out.println("문자열 분리:" + arrStr[0] + "*");
System.out.println("문자열 분리:" + arrStr[1] + "*");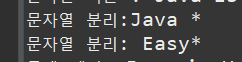
- .trim() : 지정된 문자열의 앞 뒤공백을 제거
String Str2 = new String(" Java is Hard ");
System.out.println("공백 제거" + Str2.trim() );
Java 접근 제한자
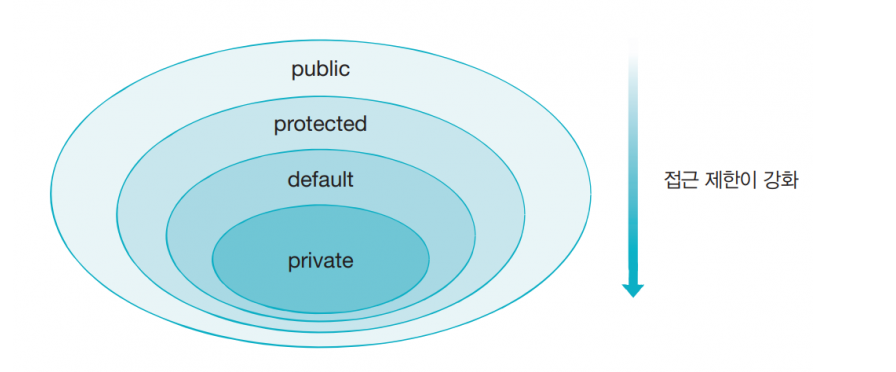
Public
-
동일 패키지 클래스 내부, 외부에서 모두 접근이 가능한 접근 제한자
-
다른 패키지의 클래스 또한 접근이 가능하다
-
public 접근 제한자 적용범위 : (클래스 내부, 외부)
-
일반 클래스, 중첩 클래스, 필드, 생성자, 메소드
-
Public은 내외부 모두 접근이 가능하므로, 전부 적용이 가능
-
package Day06;
import java.util.Scanner;
class AccessModifier1 {
public String name;
public int age;
public String addr;
}
public class EX01 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner input = new Scanner(System.in);
AccessModifier1 am = new AccessModifier1();
System.out.print("이름 : ");
am.name = input.next();
System.out.print("나이 : ");
am.age = input.nextInt();
System.out.print("주소 : ");
am.addr = input.next();
System.out.println("이름 : " + am.name);
System.out.println("나이 : " + am.age);
System.out.println("주소 : " + am.addr);
input.close();
}
}
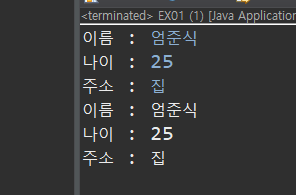
다른 클래스에서도 접근 가능하기 때문에 오류가 발생하지 않는다
Private
-
클래스 내부에서만 접근이 가능하며 다른 클래스에서는 접근이 불가능하다
-
다른 패키지의 클래스 또한 접근이 불가능하다
-
Private 접근 제한자 적용 범위 (클래스 내부)
-
중첩 크랠스, 필드, 생성자, 메소드
-
내부에서만 접근이 가능하므로, 클래스 내부에서만 사용 가능
-
package Day06;
import java.util.Scanner;
class AccessModifier2 {
private String name;
private int age;
private String addr;
}
public class EX02 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner input = new Scanner(System.in);
AccessModifier2 am = new AccessModifier2();
System.out.print("이름 : ");
am.name = input.next();
System.out.print("나이 : ");
am.age = input.nextInt();
System.out.print("주소 : ");
am.addr = input.next();
System.out.println("이름 : " + am.name);
System.out.println("나이 : " + am.age);
System.out.println("주소 : " + am.addr);
input.close();
}
}
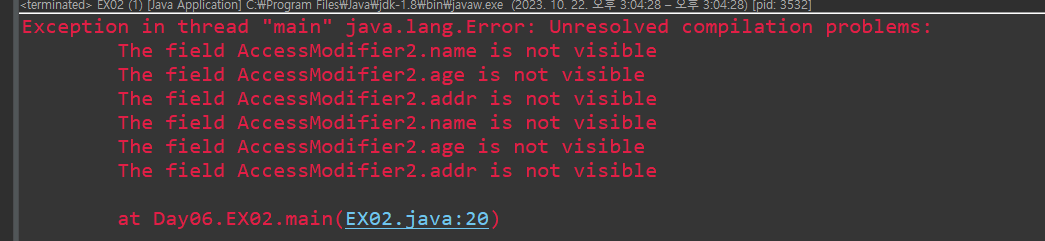
The field AccessModifier2.name is not visible
다른 외부의 클래스에서는 접근 불가능하기 때문에 오류가 발생한다
Protected
-
동일 패키지에서는 접근이 가능하며, 다른 패키지에서는 접근이 불가능하다
-
상속된 자식 클래스에서는 어디에서든 접근이 가능하다
-
Protected 접근 제한자 적용범위 (클래스 내부)
-
중첩 클래스, 필드, 생성자, 메소드
-
동일 패키지 접근이 가능하지만, 클래스 내부에서만 사용 가능
-
상속 된 클래스에서만 접근을 허용하는 것이 목적이다
-
Default
-
접근 제한자에 대한 명시가 없을 경우 Default 접근 제한자가 설정된다
-
동일 패키지에서는 접근이 가능하며, 다른 패키지에서는 접근이 불가능하다
-
Default 접근 제한자 적용범위 (클래스 내부, 외부)
-
일반 클래스 중첩 클래스, 필드, 생성자, 메소드
-
동일 패키지에서 접근이 가능하므로 전부 적용이 가능
-
package Day06;
import java.util.Scanner;
class AccessModifier3 {
private String name;
private int age;
private String addr;
}
public class EX03 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner input = new Scanner(System.in);
EX04 am = new EX04();
System.out.print("이름 : ");
am.name = input.next();
System.out.print("나이 : ");
am.age = input.nextInt();
System.out.print("주소 : ");
am.addr = input.next();
System.out.println("이름 : " + am.name);
System.out.println("나이 : " + am.age);
System.out.println("주소 : " + am.addr);
input.close();
}
}
package Day07;
public class EX04 {
String name;
int age;
String addr;
}

다른 패키지 파일에서 선언된 변수들의 접근 제한자가 명시되어있지 않으니 Default 로 적용되었다
사용하기 위해선 public을 사용해야 한다
information hiding & Encapsulation + Getter & Setter
정보 은닉 (information hiding)
클래스의 필드변수의 접근 제한을 통해 클래스의 정보를 숨기는 행위를 의미한다
-
모든 멤버변수가 외부에 공개되어있을 경우 누구나 클래스의 멤버변수 값을 임의로 조작할 수있는 상태가 만들어질 수 있다
-
클래스의 정보은닉을 구현하기 위해서는 멤버변수의 접근제한자 Private 설정을 통해 외부에서의 접근 제한을 명시한다
-
접근제한이 설정 된 멤버변수의 값은 객체 내부의 검사 및 검증 작업을 진행 한 후 멤버변수의 값을 변경할 수 있도록 구현한다
정보 은닉이 필요한 이유
EX)
자동차의 속도를 저장하느 멤버변수의 값이 외부에 공개되어있을 경우 외부 사용자가 자동차의 속도를 저장하는 멤버변수에 임의적으로 접근하여 음수값 데이터를 설정 할 경우 멤버변수의 무결성이 깨지는 상황이 발생하게 된다
캡슐화 (Encapsulation)
-
하나의 온전한 기능을 수행 할 수 있는 클래스를 저의한 것을 의미한다
-
클래스의 구성요소인 Field, Method, Constructor, Getter & Setter, Access Modifier 둥 이 정의된 상태를 말한다
-
클래스의 캡슐화를 진행할 경우 객체 내부에서 발생하는 검증 및 검사등의 작업은 외부에서 알 수 없는 상태가 구현된다
Getter & Setter
접근 제한이 설정 된 필드 변수에 접근하기 위한 메서드
-
Getter Method : 필드 변수의 값을 사용할 때 사용
-
Setter Method : 필드 변수의 값을 설정할 떄 사용
이름 지정 방식
-
Getter, Setter 는 프로그래머들간 약속 된 이름 구조 (다른 이름 사용 가능)
-
Getter Method 이름지정 기본형식 : get + Field name ( getName )
-
Setter Method 이름지정 기본형식 : set + Field name ( setName )
접근 제한자
접근 제한자에 따라 [공개형, 비공개형, 읽기 전용] 등으로 구성할 수 있다
- 공개형 : 외부에서 자유롭게 Setter & Getter를 사용할 수 있다
-
비공개형 : 외부와 연결 가능한 Method를 추가 구성 후 사요한다
-
읽기 전용의 경우 Setter는 비공개 / Getter는 공개 형식으로 구성한다
this
this
this 는 객체 자기 자신을 의미한다
-
객체 내부에서 인스턴스 멤버에 접근 시 사용된다
-
주로 생성자와 메서드의 매개변수의 이름이 필드 이름과 동일할 때 사용한다
-
매개변수는 지역변수로 구성되며, 인스턴스 변수보다 우선순위가 높다
-
지역변수와 필드 이름이 동일 한 경우 인스턴스 변수에 접근이 불가능하다
-
만약 동일이름 구조에서 인스턴스 변수에 접근하기 위해서는 this를 사용한다
this 사용 예제
this를 사용하지 않았을 때
package Day06;
import java.util.*;
class Person1 {
String name = "펭수";
int age = 20;
public void setPerson(String name, int age) {
name = name;
age = age;
}
}
public class EX29 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Person1 per = new Person1();
Scanner input = new Scanner(System.in);
System.out.print("이름 입력 : ");
String name = input.next();
System.out.print("나이 입력 : ");
int age = input.nextInt();
per.setPerson(name, age);
System.out.println("이름 : " + per.name);
System.out.println("나이 : " + per.age);
input.close();
}
}
값이 변경되지 않는다
this를 사용했을 때
package Day06;
import java.util.*;
class Person2 {
String name = "펭수";
int age = 20;
public void setPerson(String name, int age) {
this.name = name;
this.age = age;
}
}
public class EX30 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Person2 per = new Person2();
Scanner input = new Scanner(System.in);
System.out.print("이름 입력 : ");
String name = input.next();
System.out.print("나이 입력 : ");
int age = input.nextInt();
per.setPerson(name, age);
System.out.println("이름 : " + per.name);
System.out.println("나이 : " + per.age);
input.close();
}
}
값이 변경된다
사진들

이렇게 유용한 정보를 공유해주셔서 감사합니다.