0. Index란?
1000페이지 짜리의 데이터베이스 책이 있다고 상상해보자.
Index에 관한 내용을 찾고 싶은데 책의 앞에 위치한 "목차" 또는 "INDEX" 가 없다면 우리는 처음부터 끝까지 책을 읽어서 인덱스에 관한 내용을 찾아내야할 것이다.
딱 맞는 인덱스를 찾는다면 몇 시간이 걸려서 찾을 수도 있는 내용을 한번에 그 페이지로 점프해서 찾을 수 있다!
이처럼 인덱스는, 정렬되어있고 정보를 찾기 위한 페이지 정보를 주기 때문에 색인 시간을 확 줄일 수 있다!
Database에서의 🔍Index
추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조.
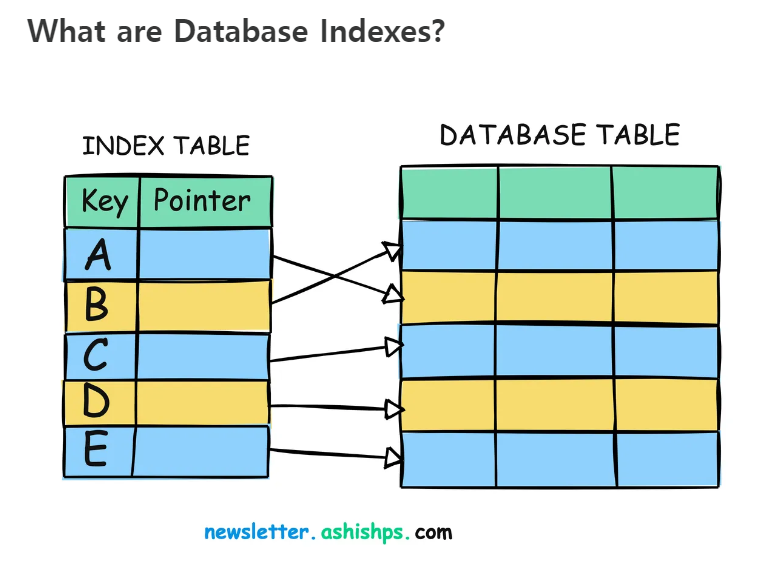
인덱스 된 열 값과 함께 테이블 해당 행에 대한 포인터가 보관된다.
인덱스가 없다면 데이터 베이스는 모든 테이블을 읽는FullScan을 하게 될 것이고 성능은 매우 느려질 것이다.
1. 인덱스 사용시 고려해야할 점 & 사용하는 이유?
인덱스 사용에 고려해야할 점
- 한번에 찾을 수 있는 값 : 데이터 중복이 적은 컬럼
- 인덱스 재정렬 최소화 : 데이터 삽입, 수정이 적은 컬럼
- 인덱스 목적은 검색 : 조회에 자주 사용되는 컬럼 (ex. JOIN / WHERE / ORDER BY)
👉🏻 만약 CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 걸게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있다.
👉🏻 UPDATE와 DELETE는 기존의 인덱스를 삭제하지 않고 '사용하지 않음'처리를 하기 때문이다. - 너무 많지 않은 인덱스 : 인덱스 또한 공간을 차지함
- 규모가 작지 않은 테이블
인덱스를 사용하는 이유
인덱스를 활용하면 조회뿐만아니라 UPDATE / DELETE의 성능이 함께 향상된다.
왜냐면 연산을 수행하기 위해선 조건에 대한 SELECT가 먼저 수행되어야 하기 때문이다.
인덱스의 장단점
- 장점
* 테이블을 조회하는 속도와 그에 따른 성능 향상 가능.- 전반적인 시스템의 부하를 줄일 수 있다.
- 단점
* 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요하다.- 인덱스를 관리하기 위해 추가 작업이 필요하다.
- 인덱스 잘못 사용하면 오히려 성능이 저하된다.
2. 인덱스 생성하는 법
단일 인덱스
CREATE ITEM
(
ITEM_NM VARCHAR(30)
, ITEM_PRICE INT
, CATEGORY VARCHAR(20)
, AMOUNT INT
)이런 간단한 ITEM테이블이 있다고 할 때 인덱스는 데이터 중복이 적은 컬럼이어야 한다.
또한 조회에 자주 사용되는 컬럼이라는 점 등을 미뤄보았을 때 현재 테이블에서는 ITEM_NM이 적절해 보인다.
CREATE INDEX idx_item_nm ON item (item_nm);이런식으로 인덱스를 생성해 주면 된다.
복합 인덱스
여러 컬럼을 조합하여 인덱스를 만드는 것도 가능하다.
이런 경우, 일반적으로 카디널리티가 높은 순으로 배치한다.
✔️카디널리티(Cardinality)
데이터의 중복 수치를 말하며, 카디널리티가 높다 = 중복이 적다 를 뜻한다.
CREATE INDEX idx_item_info1 ON item (item_nm, item_price);이렇게 복합인덱스를 설정하면 좀 더 유용한 검색 쿼리를 사용할 수 있다.
3. 인덱스의 자료구조
인덱스를 구현하기 위한 가장 대표적인 자료구조로 해시테이블과 B+ Tree가 있다.
해시 테이블(Hash Table)
- (Key, Value)로 데이터를 저장함.
- 빠른 데이터 검색이 필요할 때 유용함. > Key값을 이용해 고유한 index를 생성하여 그 index에 저장된 값을 꺼내오는 구조.
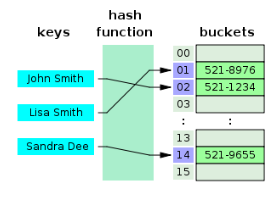
- 시간복잡도는 O(1), 매우 빠른 검색 지원함.
- 등호(=) 연산에만 특화되었기 때문에 값이 1이라도 달라지면 완전히 다른 해시값을 생성한다.
- 부등호 연산(<, >)이 자주 사용되는 데이터 베이스 검색을 위해서는 해시테이블이 적합하지 않다.
B+Tree
- DB의 인덱스를 위해 자식 노드가 2개 이상인 B-Tree를 개선시킨 자료구조.
- 리프노드(데이터노드)만 인덱스와 함께 데이터(Value)를 가지고 있고, 나머지 노드(인덱스노드)들은 데이터를 위한 인덱스(Key)만을 갖는다.
- 리프노드들은 LinkedList로 연결되어 있다.
- 데이터 노드 크기는 인덱스 노드의 크기와 같지 않아도 된다.
데이터베이스의 인덱스 컬럼은 부등호를 이용한 순차 검색 연산이 자주 발생될 수 있다.
때문에 BTree의 리프노드들을 LinkedList로 연결하여 순차 검색을 용이하게 하는 등 BTree를 인덱스에 맞게 최적화 한다.
👉🏻 B+Tree는 O(log2nlog2n{log_2n}) 의 시간복잡도를 갖지만 해시테이블보다 인덱싱에 더욱 적합한 자료구조가 되었다.
4. 인덱스 사용 시 유의할 점
4-1. 좌변은 건드리지 않는다.
## price 컬럼에 Index 가 적용된 경우
# 올바른 인덱스 사용
where price > 10000 / 100; // price 컬럼에 대한 Index Search
## 잘못된 인덱스 사용
where price * 100 > 10000; // price * 100 에 대한 Index X좌변(인덱스가 존재하는 쪽)을 변경하게 되면 price에 전부 100을 곱한 뒤 찾게된다 ㅎㄷㄷ..
4-2. LIKE, BETWEEN, <, >등 범위 조건의 컬럼은 Index가 적용되지만 그 뒤 컬럼은 Index가 적용되지 않는다.
4-3. AND는 ROW를 줄이지만 OR는 비교를 위해 ROW를 늘리므로 FULL-SCAN발생확률이 높다.
WHERE절에서 OR연산을 사용할 때는 이를 고려해야한다.
4-4. IN, = 은 다음 컬럼도 인덱스를 사용한다.
IN은 = 연산을 여러번 수행한 것이므로 다음 컬럼도 인덱스를 태울 수 있다.
[Database] 인덱스(index)란?
[MySQL] B-Tree로 인덱스(Index)에 대해 쉽고 완벽하게 이해하기
Database Indexes: A detailed guide
