DataBase
1.쿼리 튜닝(Feat. MS-SQL) - 튜닝의 기본/쿼리 최적화 방법

첫 회사는 쿼리를 짜면 DBA가 튜닝을 해 주고 인덱스 힌트와 옵션까지 다 지정해서 피드백을 주었기 때문에 튜닝에 대한 중요성을 인지하지 못 했고, 개발자는 튜닝은 할 줄 몰라도 된다고 생각했다. 그런데 첫 회사가 특이했던 것 같다... 이직 후 단순 조회를 하면서도
2.관계형 데이터베이스(RDBMS) 조인 알고리즘 종류 - Nested Loop Join / Hash Join / Sort Merge Join
줄여서 NL JOIN이라고도 함. 2개 이상의 테이블에서 하나의 집합을 기준으로 순차적으로 상대방 Row를 결함하여 원하는 결과를 조합하는 조인방식 조인 조건에 해당하는 데이터를 찾으면 바깥쪽 루프의 다음 행으로 넘어가며 안쪽 루프는 처음부터 다시 시작. 선행 테이블의
3.실행계획에서 I/O비용과 예산 연산자 비용이 작은 것 보다 높은 것이 빠른 이유? (Feat. ChatGPT 4.0)
ChatGPT에게 다음과 같이 물어보았다. : 실행계획에서 I/O 비용과 예산 연산자 비용이 작은것보다 높은게 빠른이유실행 계획에서 I/O 비용과 CPU 비용(연산자 비용)이 높은 것이 왜 때로는 더 빠를 수 있는지 이해하기 위해서는, 데이터베이스 쿼리 최적화와 관련된
4.[DataBase]DB Query Optimization(Index)
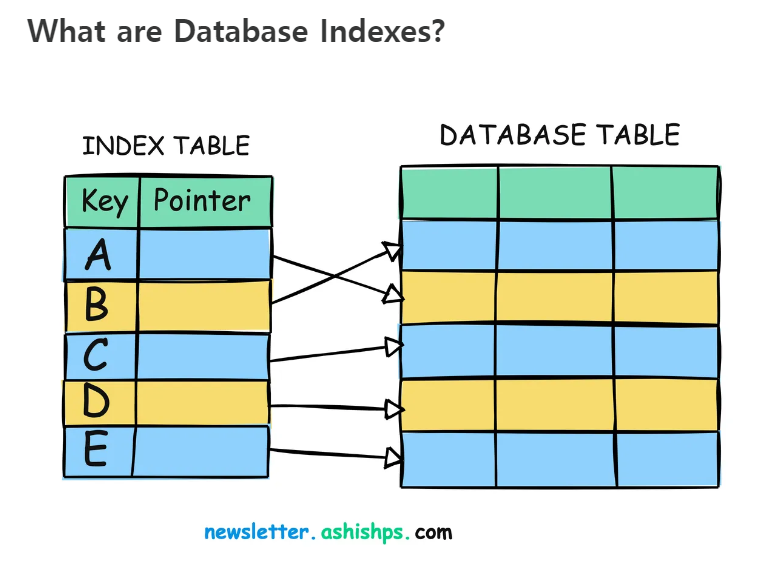
1000페이지 짜리의 데이터베이스 책이 있다고 상상해보자. Index에 관한 내용을 찾고 싶은데 책의 앞에 위치한 "목차" 또는 "INDEX" 가 없다면 우리는 처음부터 끝까지 책을 읽어서 인덱스에 관한 내용을 찾아내야할 것이다. 딱 맞는 인덱스를 찾는다면 몇 시간이
5.[DataBase]간단한 E-Commerce 프로젝트를 통해 알아보는 Indexing 🔍(Index로 성능 개선해보기.)

이커머스 프로젝트, 인덱스를 통해 성능 향상시키기.
6.[DataBase]간단한 E-Commerce 프로젝트를 통해 알아보는 Indexing 🔍(Index로 성능 개선해보기2)
0. 전 테스트에서 간과한 것. 그냥 몇 만건의 데이터를 넣어놓고 api에서 여러번 조회 부하테스트를 넣는걸로 테스트가 가능할거라 생각했다. 전에 한게 아까워서 그대로 두는게 절대아니고^..^ 나름의 유의미한 데이터가 되지않을까..하여 놔둔다. 👉🏻적은 데이터가
7.Database Connection Pool(데이터베이스 커넥션 풀)을 사용하지 않으면 일어나는 일!!?

데이터 커넥션에 대해 알고계신가요? 그럼 데이터베이스 커넥션 풀은요? 데이터베이스 풀을 써야하는 이유와 적절히 써야하는 이유에 대해 알아보아요.
8.[DataBase] 쿼리 최적화를 하는 10가지 방법

DB최적화는 왜 중요할까? 시스템이 동작하는데 있어 가장 중요한 요소는 뭘까?