
#JOIN 종류
💡 JOIN두 개의 테이블을 서로 묶어서 하나의 결과를 만들어 낼 때 사용
Left 집합과 Right 집합 간의 조건 있는 결합
→ 결과는 Cartesian Product의 subset
*참고 - Left 속성값과 Right 속성값 간의 조건 있는 결합을 말한다. (instance 간에 이루어지는 연산)
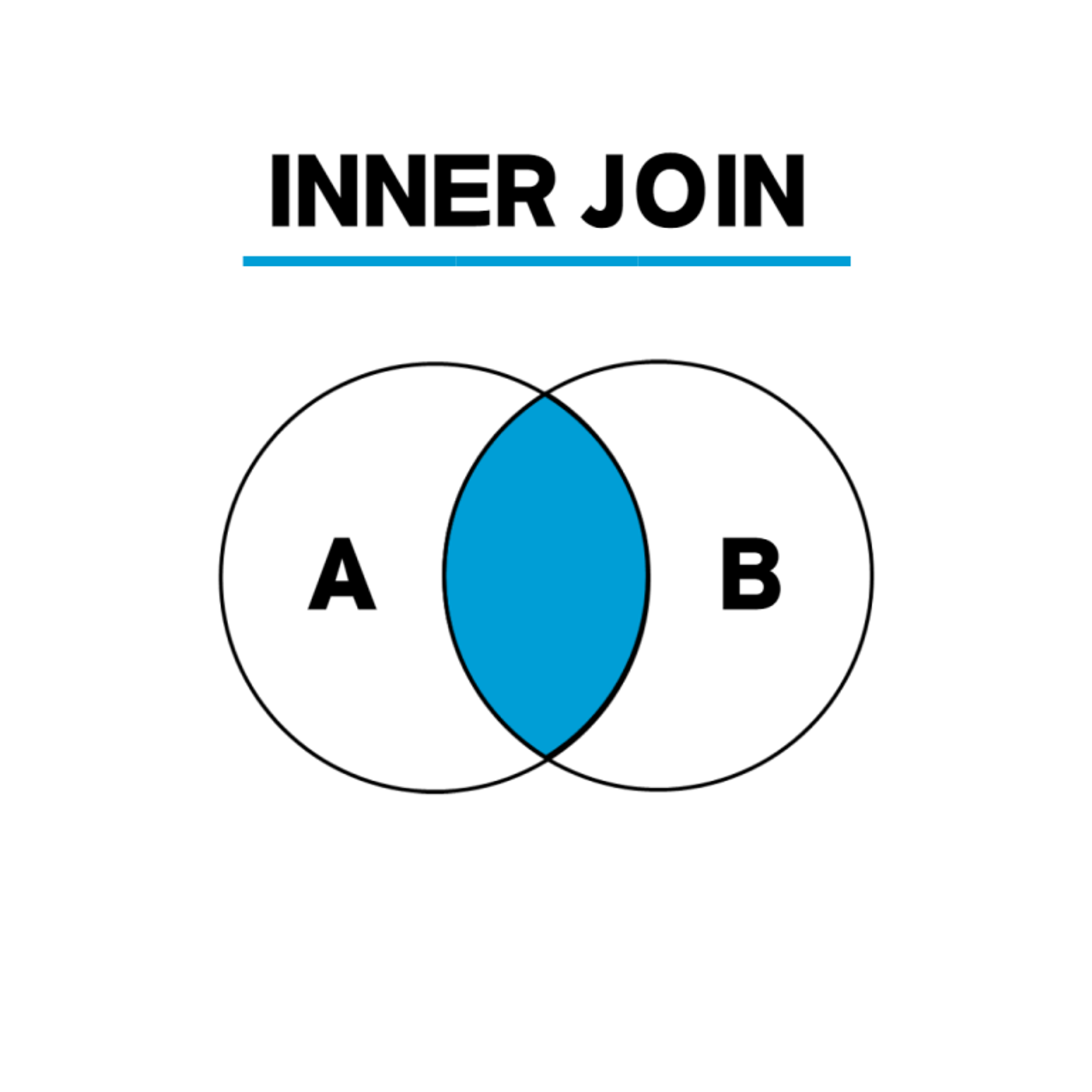
INNER JOIN(내부 조인)
두 테이블을 조인할 때, 두 테이블에 모두 지정한 열의 데이터가 있어야 함
SELECT <select_list>
FROM 테이블A
INNER JOIN 테이블B
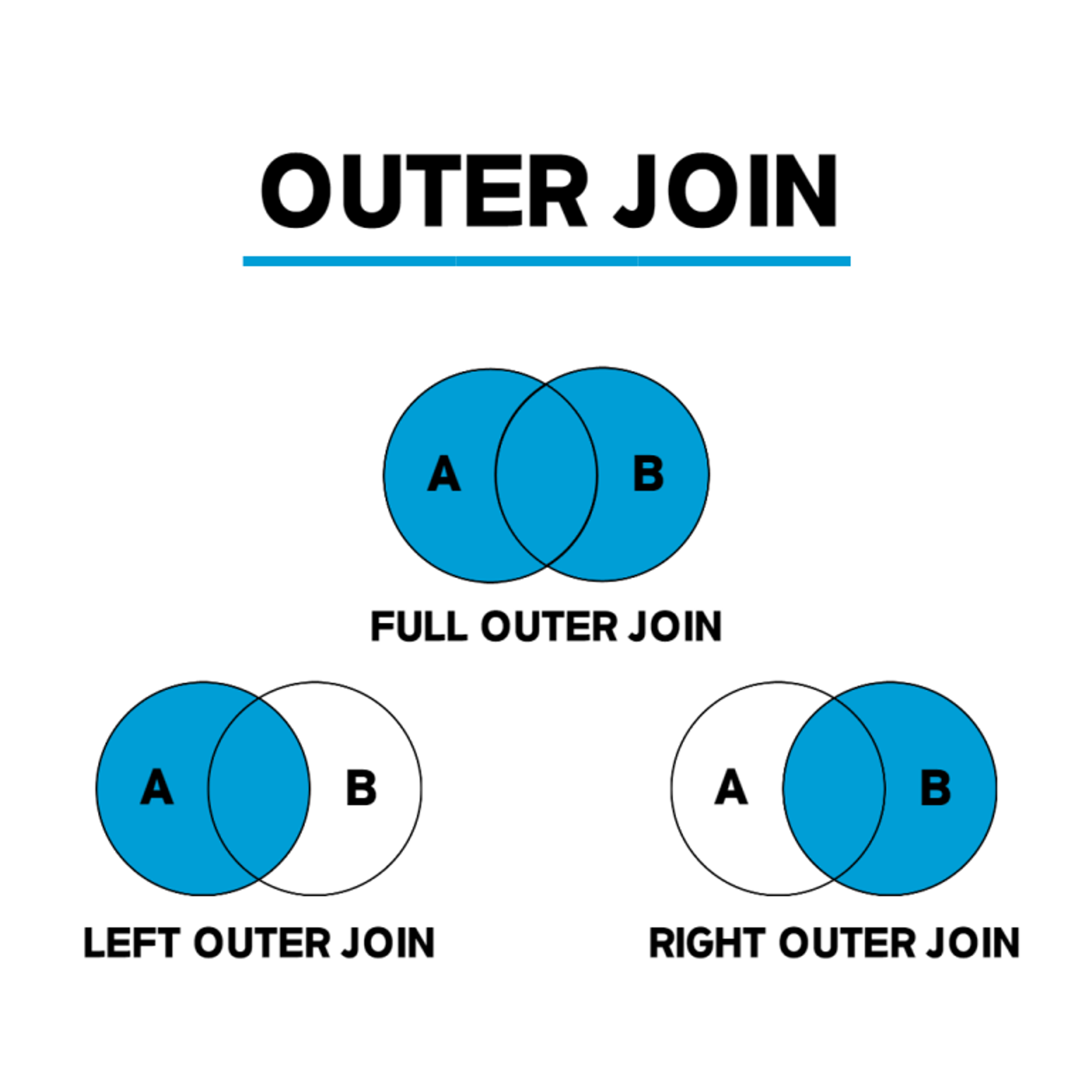
ON A.key = B.keyOUTER JOIN(외부 조인)
두 테이블을 조인할 떄, 1개의 테이블에만 데이터가 있어도 결과가 나옴
SELECT <select_list>
FROM 테이블A
FULL OUTER JOIN 테이블B
ON A.key = B.key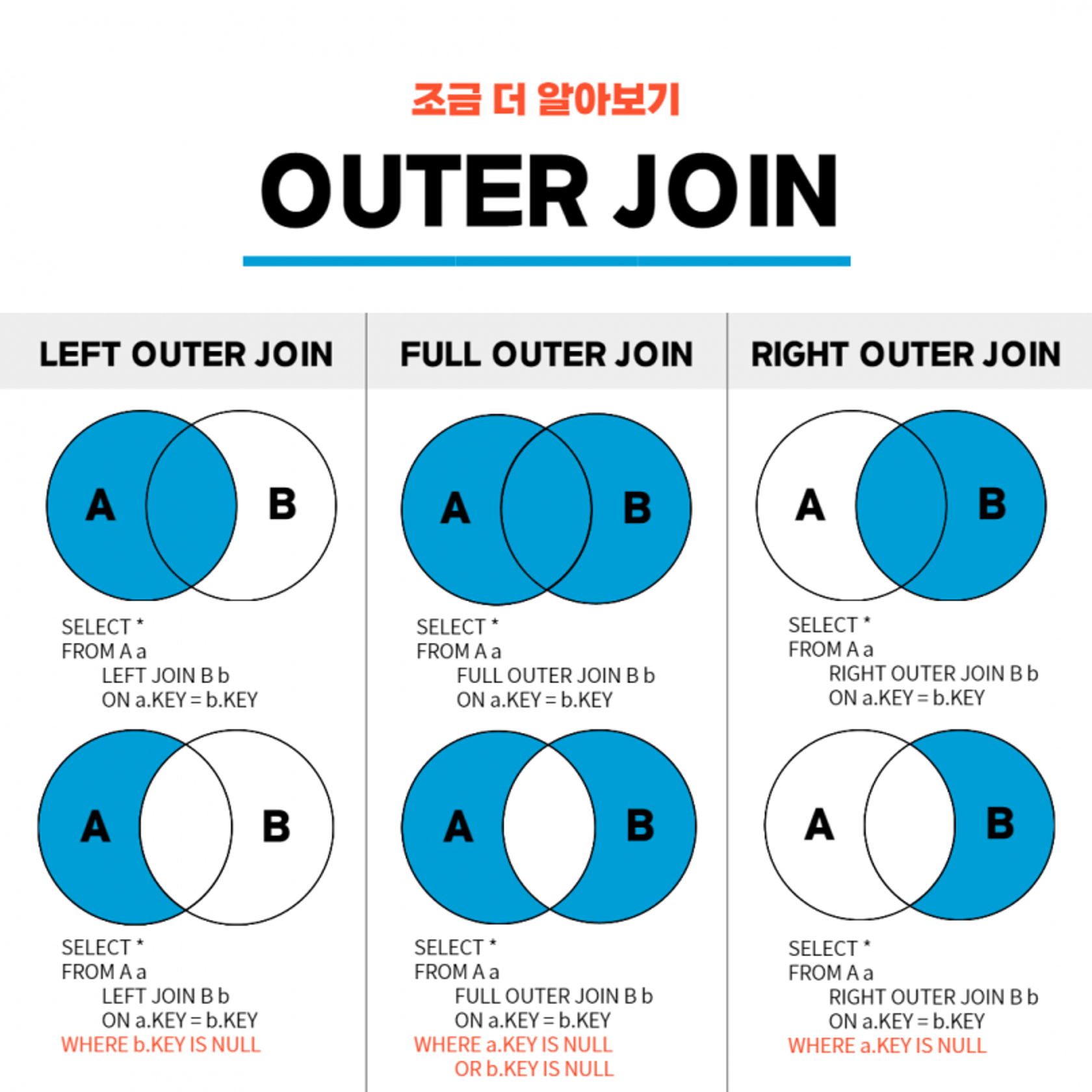
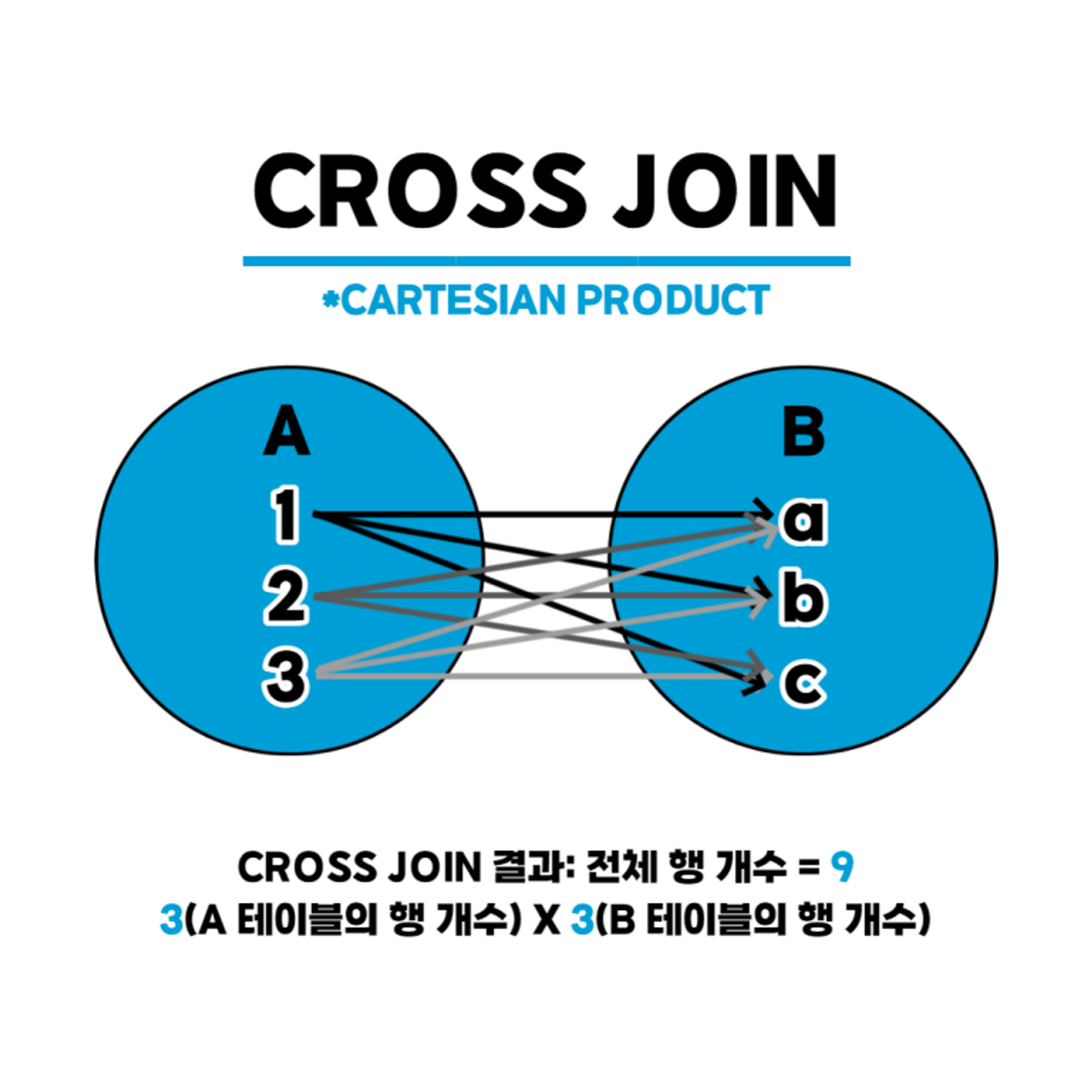
CROSS JOIN(상호 조인)
한쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인하는 기능
SELF JOIN(자체 조인)
자신이 자신과 조인한다는 의미로, 1개의 테이블을 사용함

*참고자료 - https://hongong.hanbit.co.kr/sql-기본-문법-joininner-outer-cross-self-join/
#@Column, @Table 의 역할과 옵션
@Column
객체 필드를 테이블 컬럼에 매핑할 때 사용
| 속성 | 기능 | 기본값 |
|---|---|---|
| name | 필드와 매핑할 테이블의 컬럼 이름 | 객체의 필드 이름 |
| insertable (거의 사용X) | 엔티티 저장 시 이 필드도 같이 저장 - false : 읽기 전용일 때 사용 → 이 필드는 데이터베이스에 저장 X | true |
| updatable (거의 사용X) | 엔티티 수정 시 이 필드도 같이 수정 - false : 읽기 전용일 때 사용 → 이 필드는 데이터베이스에 수정X | true |
| table (거의 사용X) | 하나의 엔티티를 두 개 이상의 테이블에 매핑할 때 사용 → 지정한 필드를 다른 테이블에 매핑할 수 있음 | 현재 클래스가 매핑된 테이블 |
| nullable(DDL) | null 값의 허용 여부를 설정 - false : DDL 생성 시 NOT NULL 제약조건이 붙음 | true *자바 기본 타입에서는 null 값을 입력할 수 없어 JPA는 기본적으로 기본 타입에 NOT NULL 제약 조건을 추가해준다. (but @Column을 명시하면 nullable=true의 기본값이 지정되므로 false로 바꿔주는 것이 안전) |
| unique(DDL) | @Table의 uniqueConstraints와 같지만, 한 컬럼에 간단히 유니크 제약조건을 걸 때 사용 *만약 두 컬럼 이상을 사용해서 유니크 제약조건을 사용하려면 클래스 레벨에서 @Table.uniqueConstraints를 사용해야 함 | |
| columnDefinition(DDL) | 데이터베이스 컬럼 정보를 직접 지정 가능 | 필드의 자바 타입과 방언 정보를 사용해서 적절한 컬럼 타입을 생성 |
| length(DDL) | 문자 길이 제약조건, String 타입에만 사용 | 255 |
| precision, scale(DDL) | - precision : 소수점을 포함한 전체 자릿수 - scale : 소수의 자릿수 BigDecimal 타입에서 사용 (BigInteger도 가능) → 아주 큰 숫자나 정밀한 소수를 다루어야 할 때만 사용 *double, float 타입에는 적용X | precision=19, scale=2 |
@Table
엔티티와 매핑할 테이블 지정 *생략 시 엔티티명=테이블명으로 지정됨
속성
| 속성 | 기능 | 기본값 |
|---|---|---|
| name | 매핑할 테이블 이름 | 엔티티 이름 사용 |
| catalog | catalog 기능이 있는 데이터베이스에서 catalog를 매핑 | |
| schema | schema 기능이 있는 데이터베이스에서 schema를 매핑 | |
| uniqueConstraints(DDL) | DDL 생성 시에 유니크 제약조건을 만든다. 2개 이상의 복합 유니크 제약조건을 만들 수 있다. *참고 - 이 기능은 스키마 자동 생성 기능을 사용해서 DDL을 만들 때만 사용됨 |
#양방향 연관관계
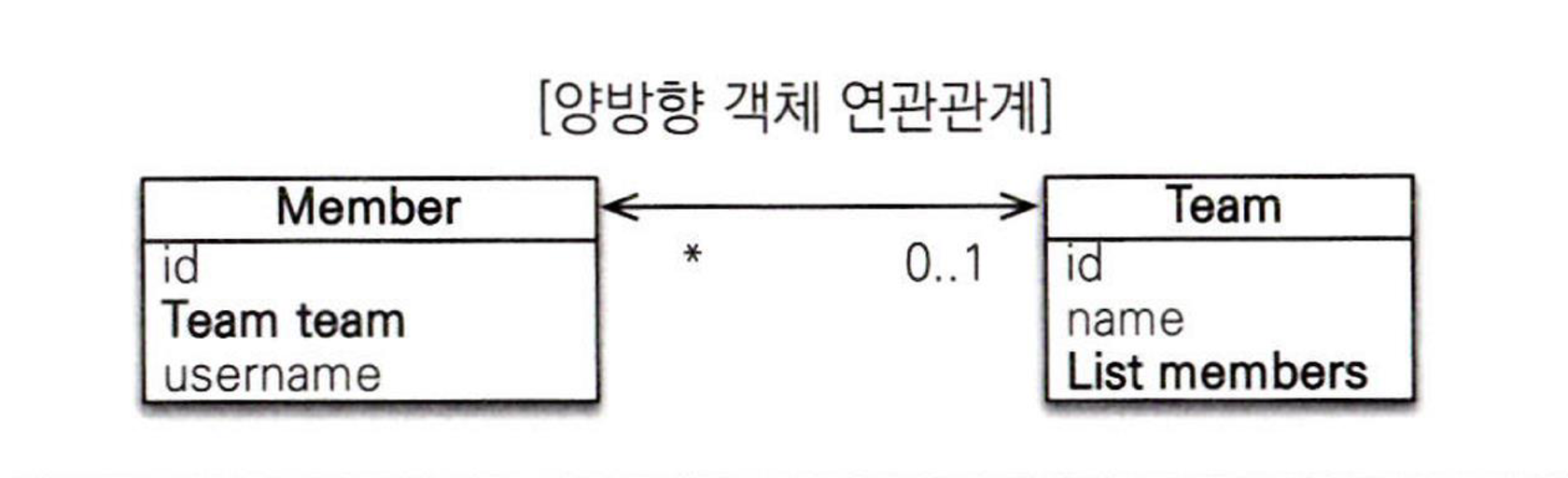
회원과 팀은 다대일 관계, 팀과 회원은 일대다 관계이다.
일대다 관계는 여러 건과 연관관계를 맺을 수 있으므로 컬렉션을 사용해야 한다.
*JPA는 List, Collection, Map, Set 등의 다양한 컬렉션을 지원한다.
양방향 관계를 매핑하려면 일대다 관계를 가지는 쪽의 엔티티에서 다음과 같이 필드를 추가할 수 있다.
*[참고] 데이터베이스 테이블은 원래부터 외래키를 통해 양방향 관계를 가지므로, 데이터베이스에 따로 추가할 내용은 없다.
@OneToMany(mappedBy = "member")
private List<Order> orders = new ArrayList<Order>();-
@OneToMany: 일대다 관계 매핑- mappedBy 속성 : 양방향 매핑일 때 사용 → 반대쪽 매핑의 필드명을 값으로 준다.
-
일대다 컬렉션을 조회하려면 아래와 같이 접근하면 된다.
Member member = em.find(Member.class, "member1"); List<Order> orders = member.getOrders(); // (Member -> Order) 방향으로 연관관계 데이터를 조회하는 '객체 그래프 탐색'
양방향 매핑의 규칙: 연관관계의 주인
연관관계 주인(객체) = 외래 키 관리자(테이블)
엄밀히 이야기하면 객체에는 양방향 연관관계라는 것이 없다. 단지 서로 다른 단방향 연관관계 2개를 애플리케이션 로직으로 잘 묶어서 양방향인 것처럼 보이게 한 것 뿐이다.
테이블은 원래부터 양방향 연관관계를 가지고 있는데, 만약 객체의 연관관계를 양방향으로 연결하여 연관관계 관리 포인트가 2곳이 된다면 객체의 참조는 둘인데 외래 키는 하나인 꼴이 된다. 따라서 두 객체 연관관계 중 하나를 정해서 외래 키를 관리할 연관관계의 주인을 결정해야 한다.
→ 이는 mappedBy 속성을 사용하여 지정할 수 있다. (주인이 아닌 쪽에서 주인을 지정)
| 연관관계 주인 | 주인이 아닌 것 |
|---|---|
| @ManyToOne | @OneToMany(mappedBy=”필드명”) |
| [FK]외래 키가 있는 곳 → 데이터베이스 연관관계와 매핑되는 부분 | [PK] 여기의 값을 기본적으로 가져야 한다. by 참조 무결성 |
| 자식 테이블 | 부모 테이블 |
| 진짜 매핑 ex. Member.team : 회원은 팀 변경이 가능 | 가짜 매핑 ex. Team.members : 팀은 회원 변경이 불가능(READ only. 객체 그래프 탐색만 가능) |
| 1:N에서 “N”에 해당 | 1:N에서 “1”에 해당 |
1:N관계에서 “N쪽이 1쪽을 참조하다”
연관관계의 주인만이 데이터베이스 연관관계와 매핑되고, 외래 키를 관리(등록, 수정, 삭제)할 수 있다. 반면, 주인이 아닌 쪽은 읽기만 할 수 있다.
위 예제 코드에서 Member와 Order 중에 주인은 Member일 것이고, Team과 Member 중에서는 Team이 될 것이다.
저장
// 회원에 팀을 저장할 때
member.setTeam(team) // 연관관계 설정(연관관계의 주인)
// 팀에 회원을 저장할 때
team.getMembers().add(member); // 무시(연관관계의 주인X)양방향 연관관계는 연관관계의 주인이 외래 키를 관리한다. 따라서 아래의 CASE는 데이터베이스(외래 키)에 영향을 주지 않으며, 데이터베이스에 저장할 때 무시된다.
그렇다고 해서 또 연관관계의 주인에만 값을 저장하고 주인이 아닌 곳에는 값을 저장하지 않아도 되는 것은 아니다. ORM은 객체와 관계형 데이터베이스 둘 다 중요하다. 따라서 순수한 객체로서의 연관관계까지 고려한다면, 객체 관점에서는 위와 같이 양쪽 방향에 모두 값을 입력해주는 것이 가장 안전하다. 양쪽 방향 모두 값을 입력하지 않으면 JPA를 사용하지 않는 순수한 객체 상태에서 심각한 문제가 발생할 수 있다.
📍 위와 같이 양방향 연관관계를 설정해주는 코드로 작성하면 순수한 객체 상태에서도 동작하며, 테이블의 외래키도 정상 입력될 수 있다!
🚨 주의점가장 흔히 하는 실수가 바로 주인이 아닌 곳에만 값을 입력하여 외래 키 값이 정상적으로 저장되지 않는 것이다. 이러한 문제가 발생하면 주인의 값을 입력했는지 확인해보는 것이 좋다.
→ 이와 같이 저장하면 데이터베이스 상의 테이블에는 null 값으로 들어가 있다.
연관관계 편의 메소드
위 코드에서 각각 메서드를 호출하여 구현한다면 실수로 하나만 호출하여 양방향이 깨질 수도 있다는 위험이 있어, 양방향 관계에서 두 코드를 하나인 것처럼 사용하는 것이 안전하다.
public void setTeam(Team team) {
// 연관관계 객체를 변경할 때, 기존의 관계를 제거하는 작업이 필요하다.
if (this.team != null) {
this.team.getMembers().remove(this);
}
this.team = team;
team.getMembers().add(this);
}기존의 관계가 삭제되지 않는 경우에도 이는 연관관계의 주인이 아닌 쪽에서 관계가 제거되지 않은 것이므로 DB에는 정상 반영되지만, 만약 영속성 컨텍스트가 아직 살아있는 상태에서 getMembers()를 호출한다면 기존의 제거되지 않은 관계의 객체가 반환될 것이다. 따라서 위와 같이 제거를 따로 처리해주는 것이 안전하다.
*실제 양방향 매핑을 구현하는 것은 비즈니스 로직의 필요에 따라 매우 복잡하다. 우선 단방향 매핑을 사용하고 반대 방향으로 객체 그래프 탐색 기능(JPQL 탐색 쿼리 포함)이 필요할 때 양방향을 사용하도록 코드를 추가해도 된다.
☑️ 정리
- 단방향 매핑만으로 테이블과 객체의 연관관계 매핑은 이미 완료되었다.
- 단방향을 양방향으로 만들면 반대방향으로 객체 그래프 탐색 기능이 추가된다.
- 양방향 연관관계를 매핑하려면 객체에서 양쪽 방향을 모두 관리해야 한다.
#CascadeType
영속성 전이: CASCADE
특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶은 경우에 영속성 전이 기능을 사용할 수 있다. ⇒ 자식을 저장하려면 부모에 등록만 하면 된다.
JPA는 CASCADE 옵션으로 영속성 전이를 제공한다. 즉, 영속성 전이를 사용하면 부모 엔티티 저장 시 자식 엔티티도 함께 저장할 수 있는 것이다.
// 부모 엔티티
@Entity
public class Parent {
@Id @GeneratedValue
private Long id;
@OneToMany(mappedBy = "parent")
private List<Child> children = new ArrayList<>();
}
// 자식 엔티티
@Entity
public class Child {
@Id @GeneratedValue
private Long id;
@ManyToOne
private Parent parent;
}저장
-
부모 1명에 자식 2명을 저장하는 경우
private static void saveNoCascade(EntityManager em) { // 부모 저장 Parent parent = new Parent(); **em.persist(parent);** // 1번 자식 저장 Child child1 = new Child(); child1.setParent(parent); // 자식 -> 부모 연관관계 설정 parent.getChildren().add(child1); // 부모 -> 자식 **em.persist(child1);** // 2번 자식 저장 Child child2 = new Child(); child2.setParent(parent); // 자식 -> 부모 연관관계 설정 parent.getChildren().add(child2); // 부모 -> 자식 **em.persist(child2);** }JPA에서 엔티티를 저장할 때 연관된 모든 엔티티는 영속 상태여야 하므로, 위와 같이 부모 엔티티를 영속 상태로 만든 뒤, 자식 엔티티도 각각 영속 상태로 만드는 과정이 필요하다.
→ 이때 영속성 전이(CASCADE)를 사용하면 부모만 영속 상태로 만들어도 나머지 연관된 자식까지 한 번에 영속 상태로 만들 수 있다. (3줄 → 1줄의 코드로 단순화!)
-
영속성 전이를 활성화하자! → CASCADE 옵션(PERSIST) 적용 🌟
@Entity public class Parent { @Id @GeneratedValue private Long id; **@OneToMany(mappedBy = "parent", cascade = CascadeType.PERSIST)** private List<Child> children = new ArrayList<>(); }위와 같이 영속성 전이를 활성화하고 나면 저장 시,
setParent(parent)만으로 연관관계가 추가됨과 동시에 부모를 persist 할 때 함께 영속 상태로 전이됨을 보장해준다.
*영속성 전이는 연관관계를 매핑하는 동작과는 아무 관련이 없고, 단지 엔티티 영속화 시 연관된 엔티티도 같이 영속화하는 편리함을 제공할 뿐이다.
⇒ 순서 상으로 1) 양방향 연관관계 추가 2) 영속 상태로 전이 로 이루어지는 것을 볼 수 있다!
삭제
- 위에서 저장한 부모와 자식 엔티티를 모두 제거하는 경우
Parent findParent = em.find(Parent.class, 1L); Child findChild1 = em.find(Child.class, 1L); Child findChild2 = em.find(Child.class, 2L); // 각각의 엔티티를 조회하여 하나씩 제거한다. (자식 -> 부모 순서로 ***by 외래 키 제약조건***) **em.remove(findChild1); em.remove(findChild2); em.remove(findParent);** - 영속성 전이를 활성화하자! → CASCADE 옵션(REMOVE) 적용 🌟
위 코드를 실행하면 DELETE SQL을 3번 실행하고, 부모는 물론 연관된 자식도 모두 삭제한다. 삭제 순서는 영속성 전이 활성 이전과 같이 자식을 먼저 삭제한 후에 부모를 삭제한다. by 외래 키 제약조건 *CASCADE 옵션 없이 위 코드 실행 시, 부모 엔티티만 삭제되어 자식 테이블에 걸려 있는 외래 키 제약조건에 의해, 데이터베이스에서 외래 키 무결성 예외가 발생하게 된다.Parent findParent = em.find(Parent.class, 1L); em.remove(findParent);
package javax.persistence;
public enum CascadeType {
ALL, // 모두 적용
PERSIST, // 영속
MERGE, // 병합
REMOVE, // 삭제
REFRESH, // REFRESH
DETACH; // DETACH
private CascadeType() {
}
}*여러 속성을 같이 사용할 수도 있다.
ex. cascade = { CascadeType.PERSIST, CascadeType.REMOVE }
→ 참고로, 이들은 em.persist(), em.remove() 실행 시 바로 전이가 발생하지 않고, 플러시를 호출할 때 전이가 발생한다.
