
#HTTP Method의 특징
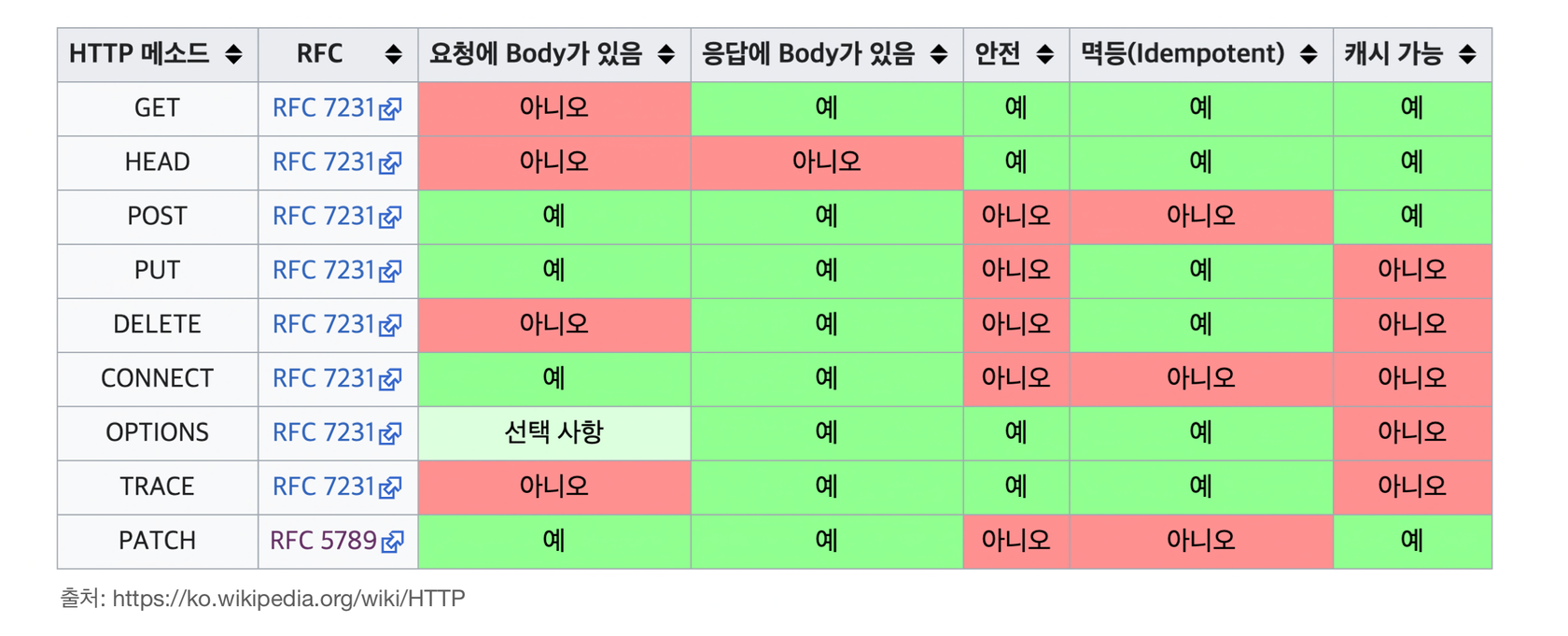
1️⃣ 멱등(idempotent)
f(f(x))=x; 몇 번을 호출해도 결과는 동일!
POST는 멱등 메서드 X
- 자동 복구 메커니즘
- 타임아웃으로 요청 실패 시, 다시 클라이언트가 재요청해도 되는가?
2️⃣ 캐시가능(Cacheability)
응답 결과를 캐시해서 사용해도 되는가? → YES! :
GET,HEAD,POST,PATCH
POST와PATCH의 경우, 본문 내용까지 캐시 키로 고려해야 하므로 거의 사용X
3️⃣ 안전(Safe)
호출해도 리소스의 변경이 일어나지 않는다
#@ResponseBody 와 @RequestBody 의 역할
직렬화(serialization) : Java Object → JSON 문자열
역직렬화(deserialization) : JSON 문자열 → Java Object
HTTP 요청 본문(=Body) 데이터는 Spring에서 제공하는 HttpMessageConverter를 통해 타입에 맞는 객체로 변환된다.
@ResponseBody = 응답본문
Java 객체(응답DTO)를 HTTP 요청 본문으로 매핑하여 클라이언트에 전송
📌 RestController
- 객체를 반환하기만 하면 객체 데이터는 Json형식의 HTTP 응답을 직접 작성한다. ⇒ 리턴값에 자동으로
@ResponseBody가 붙는 효과 - Data를 return하는 것이 주 용도이다.
@RestController는 크게@Controller+@ResponseBody두 개의 어노테이션의 조합으로 볼 수 있다.-
@Controller- @Component로 스프링이 이 클래스의 오브젝트를 알아서 생성하고 다른 오브젝트들과의 의존성을 연결한다는 의미 -
@ResponseBody- 이 클래스의 메서드가 리턴하는 것이 웹 서비스의 ResponseBody라는 의미⇒ 이 어노테이션을 사용하면 각 메소드마다
@ResponseBody설정 할 필요 X
-
📌 ResponseEntity
HTTP 응답의 바디뿐만 아니라 여러 다른 매개변수(status, header)를 조작하고 싶을 때 사용
@RequestBody = 요청본문
HTTP 요청 본문을 그대로 전달받아 Java 객체(요청DTO)로 변환하여 매핑
- @RequestBody를 사용하면 요청 본문의 JSON, XML, Text 등의 데이터가 적합한 HttpMessageConverter를 통해 파싱되어 Java 객체로 변환된다.
- @RequestBody를 사용할 객체는 필드를 바인딩할 생성자나 setter 메서드가 필요없다.
- 다만 직렬화를 위해 기본 생성자 는 필수다.
- 또한 데이터 바인딩을 위한 필드명을 알아내기 위해 getter나 setter 중 1가지는 정의되어 있어야 한다. *만약 getter나 setter 메서드가 모두 정의되어 있지 않으면, 실행 시 HttpMessageNotWritableException 예외가 발생한다.
📌 RequestParam
Request의 Parameter를 가져오는, 즉 쿼리 파라미터를 파싱하는 역할
→ 키와 값의 쌍으로 전송되는 단순 데이터에 유용
*@RequestParam과의 차이?
@RequestBody 로 데이터를 받을 때는 메서드의 변수명이 상관 없었지만, @RequestParam 으로 데이터를 받을 때는 데이터를 저장하는 이름으로 메서드의 변수명을 일일이 지정해줘야 한다.
| @RequestBody | @RequestParam | |
|---|---|---|
| 객체 생성 | 가능 | 불가능 |
| 각 변수별로 데이터 저장 | 불가능 | 가능 |
#Java Record
불변 데이터 객체를 쉽게 생성할 수 있도록 하는 데이터 클래스
특징
“final 클래스가 전제된다”
멤버변수-
private final 로 선언
-
필드별 getter 자동 생성 →
@Getter필요 Xex. member.getName() → member.name()
-
모든 필드를 인자로 하는 public 생성자 자동 생성 ⇒
@AllArgsConstructor필요X**Record는 인스턴스 필드 수정이 불가능하다는 차이점*⇒ 컴파일 타임에 필드 캡슐화를 자동으로 구현
-
메서드-
getter(), equals(), hashcode(), toString() 구현을 기본으로 제공
-
생성자를 작성하지 않아도 됨!
⇒ 컴파일 타임에 생성자 메서드와 기본 메서드를 자동으로 구현
-
✨이점
- 불변 데이터를 개체 간에 전달하는 작업에 대해 간단하게 처리 가능
- 적은 양의 코드로 명확한 의도 표현
- 기존 자바의 DTO 클래스로 적합!
🚨한계점
- 상속(extends)이 불가능함 → but, 인터페이스 구현(implements)은 가능
- 추상 클래스(abstratct) 선언 불가
- 엔티티 클래스로는 사용 불가 → JPA의 지연로딩에서 프록시 객체를 생성하는 부분이 불가능하기 때문
#OOP와 RDB에는 어떠한 패러다임의 불일치가 있는가?
객체와 관계형 DB의 데이터 표현방식과 처리 방법이 달라서 발생하는 현상
객체 모델과 연관관계
객체는 참조를 사용하여 다른 객체와 연관관계를 가지고 참조에 접근해서 연관된 객체를 조회한다면, 테이블은 외래키를 사용하여 다른 테이블과의 연관관계를 가지고 조인을 사용해서 연관된 테이블을 조회한다.
괸계형 데이터베이스에서는 조인 기능을 지원하고 있어 외래키의 값을 그대로 보관할 수 있다.
| 객체 모델 | 테이블 | |
|---|---|---|
| 외래키 | X | O |
| 참조 | O | X |
객체가 DB에 의존적이지 않게 하기 위해서는, 양쪽의 불일치를 해결해줘야 한다!
ORM은 이들 둘 사이에서 매핑(연결)해주는 역할을 담당함으로써, 연관관계에 관련된 패러다임의 불일치 문제 를 해결해준다.
객체지향의 특성이 DB에는 없다!
객체지향에는 상속, 추상화, 다형성 등의 고유한 특성이 있지만, DB에는 이러한 특성이 존재하지 않는다. 즉, 이 또한 표현방식과 처리, 기능이 서로 다르다고 볼 수 있다.
위와 같은 내용을 모두 OOP-RDB 간의 패러다임 불일치라고 한다.
#@GeneratedValue 의 옵션(생성 전략)
IDENTITY 전략 : 기본 키 생성을 데이터베이스에 위임한다.
데이터베이스에 엔티티를 저장해서 식별자 값을 획득한 후, 영속성 컨텍스트에 저장한다.
@Entity
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // 'ID INT NOT NULL AUTO_INCREMET PRIMARY KEY'
private Long id;
...
}데이터베이스에 값을 저장할 때 ID 컬럼을 비워두면 데이터베이스가 순서대로 값을 채워준다.
⇒ 데이터를 데이터베이스에 INSERT한 후에 기본 키 값을 조회 가능. 따라서 엔티티에 식별자 값을 할당하려면 JPA는 추가로 데이터베이스를 조회해야 한다.
🚨 주의엔티티가 영속 상태가 되려면 식별자가 반드시 필요한데, IDENTITY 전략은 엔티티를 데이터베이스에 저장해야 식별자를 구할 수 있으므로 em.persist()를 호출하는 즉시 INSERT 쿼리가 DB로 전달된다.
⇒ 이는 트랜잭션을 지원하는 쓰기 지연이 동작하지 않는다.
SEQUENCE 전략 : 데이터베이스 시퀀스를 사용해서 기본 키를 할당한다.
데이터베이스 시퀀스에서 식별자 값을 획득한 후, 영속성 컨텍스트에 저장한다.
*데이터베이스 시퀀스란? 유일한 값을 순서대로 생성하는 특별한 데이터베이스 오브젝트
@Entity
@SequenceGenerator( // 이는 @GeneratedValue 옆에 사용해도 된다.
name = "BOARD_SEQ_GENERATOR",
sequenceName = "BOARD_SEQ", // 매핑할 데이터베이스 시퀀스 이름
initialValue = 1, allocationSize = 1)
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "BOARD_SEQ_GENERATOR") // 'CREATE SEQUENCE BOARD_SEQ START WITH 1 INCREMENT BY 1'
private Long id;
...
}사용할 데이터베이스 시퀀스를 매핑하기 위해서 @SequenceGenerator로 BOARD_SEQ_GENERATOR라는 시퀀스 생성기를 등록하고, 이 이름으로 지정한 sequenceName을 이용해 JPA가 실제 데이터베이스의 BOARD_SEQ 시퀀스와 매핑할 수 있다.
키 생성 전략을 GeneratedType.SEQUENCE로 설정 후에, 등록한 시퀀스 생성기를 선택하면 이제부터 id 식별자 값은 BOARD_SEQ_GENERATOR 시퀀스 생성기가 할당하게 되는 것이다.
@SequenceGenerator 의 속성
| 속성명 | 기능 | 기본값 |
|---|---|---|
| name | 식별자 생성기 이름 | 필수 |
| sequenceName | 데이터베이스에 등록되어 있는 시퀀스 이름 | hibernate_sequence |
| initialValue | DDL 생성 시에만 사용됨. 시퀀스 DDL을 생성할 때 처음 시작하는 수를 지정 | 1 |
| allocationSize | 시퀀스 한 번 호출에 증가하는 수 ⭐ 성능 최적화에 사용됨 | 50 → 시퀀스를 호출할 때마다 값이 50씩 증가 (데이터베이스 시퀀스 값이 하나씩 증가하도록 설정되어 있으면 이 값을 반드시 1로 설정해야 한다.) |
| catalog, schema | 데이터베이스 catalog, schema 이름 |
사용 코드는 두 전략이 유사하지만, SEQUENCE 전략은 em.persist()를 호출할 때 먼저 데이터베이스 시퀀스를 사용해서 식별자를 조회하고, 조회한 식별자를 할당한 후에 엔티티를 영속성 컨텍스트에 저장한다.
따라서 트랜잭션 커밋 후 플러시가 일어나면 엔티티를 데이터베이스에 저장한다. → 이 부분의 식별자 값을 할당받는 시점 및 순서와 트랜잭션을 지원하는 쓰기 지연 동작 여부에서 차이점이 있다.
- IDENTITY는 데이터베이스에 저장 후, 식별자 값을 할당하기 위해 추가로 조회하는 과정에서 생성 시 데이터베이스와 2번 통신한다고 볼 수 있다.
- SEQUENCE는 데이터베이스 시퀀스를 통해 식별자를 조회하는 추가 작업을 필요로 하여 이 과정에서 데이터베이스와 2번 통신한다.
💡 **시퀀스 접근 횟수를 줄이는 전략 : allocationSize** JPA는 이 시퀀스에 접근하는 횟수를 줄이기 위해 `@SequenceGenerator.allocationSize` 를 사용한다. 여기에 설정한 값만큼 한 번에 시퀀스 값을 증가시키고 나서 그만큼 메모리에 시퀀스 값을 할당한다. ex. allocationSize=50일 때, 시퀀스를 한 번에 50 증가시킨 다음에 1~50까지는 메모리에서 식별자를 할당한다. 그리고 51이 되면 시퀀스 값을 100으로 증가시킨 다음, 51~100까지 메모리에서 식별자를 할당한다. → **여러 JVM이 동시에 동작해도 각각이 시퀀스 값을 선점하므로 기본 키 값 충돌 X**# 1. 식별자를 구하려고 데이터베이스 시퀀스를 조회한다. SELECT BOARD_SEQ.NEXTVAL FROM DUAL # 2. 조회한 시퀀스를 기본 키 값으로 사용해 데이터베이스에 저장한다. INSERT INTO BOARD ...
TABLE 전략 : 키 생성 테이블을 사용한다.
데이터베이스 시퀀스 생성용 테이블에서 식별자 값을 획득한 후, 영속성 컨텍스트에 저장한다.
키 생성 전용 테이블을 하나 만들고 여기에 이름과 값으로 사용할 컬럼을 만들어 데이터베이스 시퀀스를 흉내내는 전략
→ 모든 데이터베이스에 적용 가능 (의존 X)
@Entity
@TableGenerator( // 테이블 키 생성기 등록
name = "BOARD_SEQ_GENERATOR",
table = "MY_SEQUENCES", // 키 생성용 테이블 매핑
pkColumnValue = "BOARD_SEQ", allocationSize = 1)
public class Board {
@Id
**@GeneratedValue(strategy = GeneratedType.TABLE, generator = "BOARD_SEQ_GENERATOR")** // 테이블 키 생성기 지정
private Long id;
...
}이렇게 생성기를 등록해주고 나면, id 식별자 값은 BOARD_SEQ_GENERATOR 테이블 키 생성기가 할당한다.
@TableGenerator 의 속성
| 속성명 | 기능 | 기본값 |
|---|---|---|
| name | 식별자 생성기 이름 | 필수 |
| table | 키 생성 테이블명 | hibernate_sequence |
| pkColumnName | 시퀀스 컬럼명 | sequence_name |
| valueColumnName | 시퀀스 값 컬럼명 | next_val |
| pkColumnValue | 키로 사용할 값 이름 | 엔티티 이름 |
| initialValue | 초기값. 마지막으로 생성된 값이 기준 | 0 |
| allocationSize | 시퀀스 한 번 호출에 증가하는 수(성능 최적화에 사용됨) | 50 |
| catalog, schema | 데이터베이스 catalog, schema 이름 | |
| uniqueConstraints(DDL) | 유니크 제약 조건을 지정할 수 있다. |
- TABLE 전략은 값을 조회하며서 SELECT 쿼리를 사용하고 다음 값으로 증가시키기 위해 UPDATE 쿼리를 사용한다. 이 전략은 SEQUENCE 전략보다 DB와 한 번 더 통신한다는 단점이 있다.
- 최적화하는 방법은 SEQUENCE 전략과 동일하게 allocationSize를 사용하는 것이다.
AUTO 전략
선택한 데이터베이스 방언에 따라 IDENTITY, SEQUENCE, TABLE 전략 중 하나를 자동으로 선택한다.
ex. Oracle - SEQUENCE, MySQL - IDENTITY
이는 자동적으로 선택을 해주는 것이기 때문에 데이터베이스를 변경해도 코드를 수정할 필요가 없다는 장점이 있다.
SEQUENCE나 TABLE 전략이 선택된 경우에는 시퀀스나 키 생성용 테이블을 미리 만들어 두어야 한다.
*스키마 자동 생성 기능을 사용한다면 하이버네이트가 기본값을 사용해서 적절한 시퀀스나 키 생성용 테이블을 만들어준다.
*Oracle의 시퀀스, MySQL의 AUTO_INCREMENT 기능과 같이 데이터베이스 벤더마다 키 자동 생성을 지원하는 방식이 다르기 때문에 IDENTITY와 SEQUENCE 전략은 사용하는 데이터베이스에 의존한다.
#URL, URI 용어 정리
URI ? 네트워크 상 자원을 가리키는 일종의 고유 식별자(ID)
- Uniform - 리소스를 식별하는 통일된 방식
- Resource - 자원 → URI로 식별할 수 있는 모든 것 (제한 無)
- Identifier - 다른 항목과 구분하는 데 필요한 정보
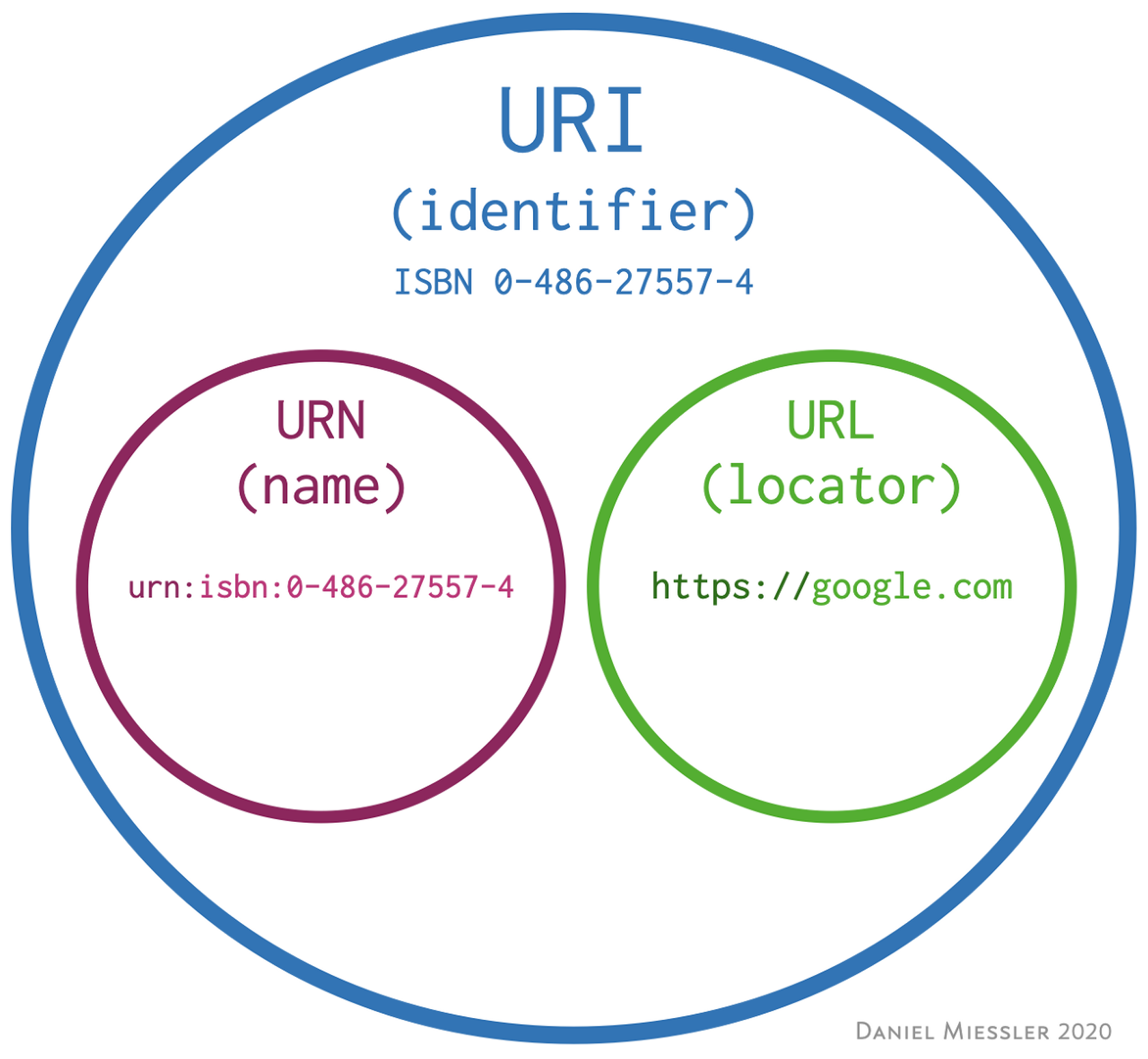
⭐URN, URL은 URI에 포함, 즉 URI의 종류
- URL(Location) : 리소스의 위치
- 리소스의 위치 변경 시 함께 변경필요. 즉, 영구적이지 않다
- “여기 찾아가면 원하는 데이터가 있다!”
- URN(Name) : 리소스의 이름
- 리소스의 위치정보가 아닌 실제 리소스의 고유한 이름으로 일정하게 유지됨
- “데이터의 이름 그 자체” →이름만으로는 실제 리소스를 찾기가 어려움

#Path Parameter, Query String
RESTful API는 상황에 따라 아래와 같은 방식으로 통신할수 있다. “데이터(자원)” 관점에서 요청과 응답이 이루어지는 메커니즘을 살펴보자
이때, 주의할 점은 API 설계 시 페이지 단위로 생각하지 않는다는 것이다
Path Parameter
요청을 경로로 구분하여 전달하는 방식
- 정제되지 않은 데이터 호출
- 원하는 조건의 데이터들, 하나의 데이터에 대한 정보를 받아올 때
- 필요한 상황, 정보에 따라 URI를 다르게 요청
ex. GET /members/1 , GET /members , GET /members/1/posts 🚨 Worst Case
GET /members/1/detail
GET /members/1/posts_filter
GET /members/1/posts_search
GET /members/1/withdraw_detailQuery String
? 뒤에 변수에 값을 담아 전달하는 방식
- 정제된 결과물
- 보다 정교하고 복잡한 조건으로 요청 가능 (Best Case👇🏻)
- 페이지네이션 ex. GET /members?offset=0&limit=100
- 정렬 ex. GET /members?ordering=-id (내림차순)
- 검색
- 필터링
- 페이지네이션 ex. GET /members?offset=0&limit=100
*참고 - https://velog.io/@haileeyu21/Session-RESTful-API-란-Path-parameters-Query-string
