목표
- Deep Neural Network의 학습 방법에 대해 알아보기
- Deep Neural Network가 학습할 때 Loss Function을 해석하는 두 가지 관점의 차이 이해하기 (두 가지 관점 -Backpropagation, MLE)
01. Machine Learning의 학습 방법

일반적인 Machine Learning의 분류 학습 절차
- 입력, 출력 데이터
- 모델 정의
- 모델의 파라미터 학습 -> 모델을 결정짓는 theta(θ)를 결정
- 출력값과 target(정답)과의 차이를 정의
- 최적의 파라미터 서치
- 최적 함수의 출력 계산
학습 과정
모델 학습을 통한 모델을 결정짓는 θ(parameter)를 결정하고, 모델의 출력값과 target(정답)과의 차이를 통해 최적의 파리미터를 서치한다. 그리고 학습을 통해 결정된 최적의 함수값에 대한 출력을 계산하면서 학습의 결과를 확인한다.
- Deep Neural Network의 학습
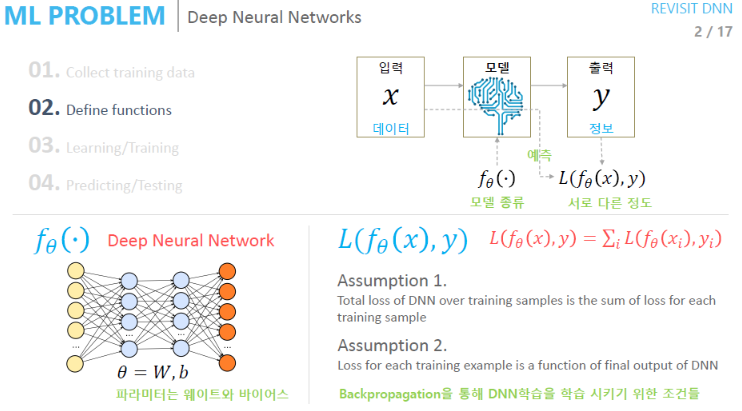
Training data가 준비되고 model이 준비된다면 Loss Function을 정의해줘야 한다. 이때 우리가 일반적으로 사용하는 Loss Function은 한정적이기 때문에 2가지 가정을 해야 한다.
- Training data 전체 Loss Function은 각 Loss에 대한 합이다.
- Network 출력 값과 타겟값에 대한 Loss를 구한다.
Backpropagation Algorithm을 적용하기 위해서는 일반적으로 위의 두 가지의 가정을 가정한다.
- 모델을 정해준 다음에 Loss Function을 정해줘야 한다.
- 이때 우리가 일반적으로 사용하는 Loss Function은 한정적이다. (Cross Entropy 또는 MSE)
- 2개의 가정을 기억하자.
- Training data 전체 Loss Function은 각 Loss에 대한 합이다.
- Network 출력 값과 타겟값에 대한 Loss를 구한다.
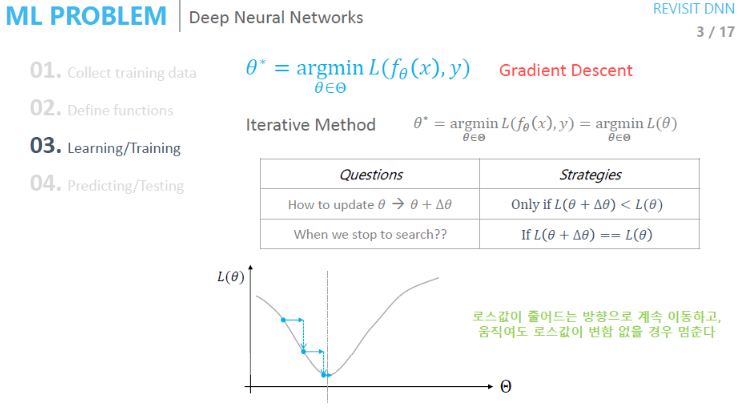
01-1. Gradient Descent
현재의 높이가 이동 전의 높이보다 낮다면 더 낮은 지점으로 이동을 하는 알고리즘이다.
Loss Function의 출력값과 모델의 파라미터가 있을 때, Gradient Descent Algorithm을 활용해 최적의 해를 구할 수 있다.
- 현재 θ에서 loss가 줄기만 한다면 loss를 바꾼다.
- 현재 θ와 다음 theta의 loss가 같다면 학습을 멈춘다.
- 이렇게 경사를 타고 내려가면서 최적의 해를 탐색한다.

- 전체 데이터에 대한 Loss Function 값은 각각의 데이터에 대한 Loss 값의 합이다.
- Loss Function의 기울기는 각각의 Loss Function에 대한 기울기의 합과 같다.
Backpropagation 알고리즘
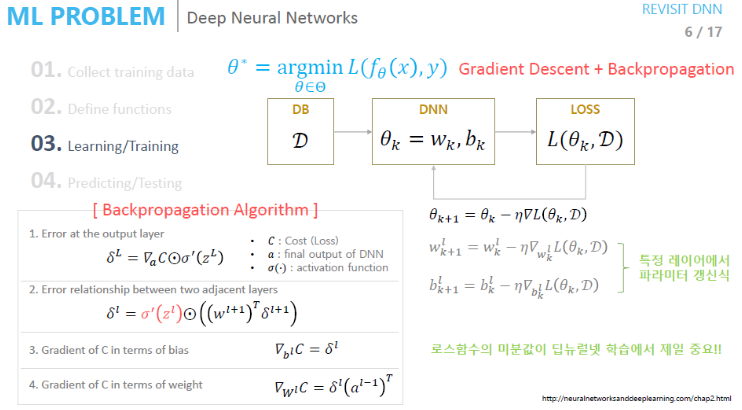
Deep Neural Network의 학습에서는 Loss Function의 미분값이 가장 중요하다.
Backpropagation type 1 - MSE 관점
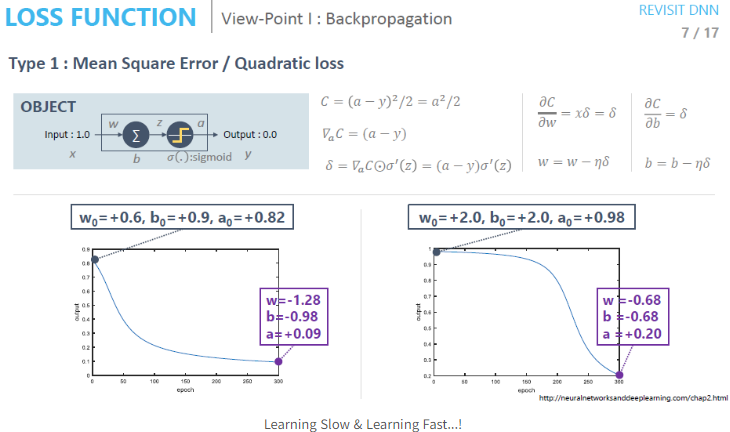
Q. One-Neural Network를 구성해서 학습을 시켰는데 왜 학습 결과가 다를까?
A. 오른쪽 아래의 Loss 값보다 왼쪽 아래의 Loss 값이 훨씬 더 빠르게 수렴하는 것을 볼 수 있는데, 초기값이 달라서 그렇다.
Back propagation 관점에서 살피기
- Sigmoid의 미분값이 0에 가까울 때와 조금 더 클 때의 차이
어떤 Activation Function을 쓰는지 그리고 해당 Activation Function이 Backpropagation에서 어떻게 동작하는지 생각해봐야 한다.
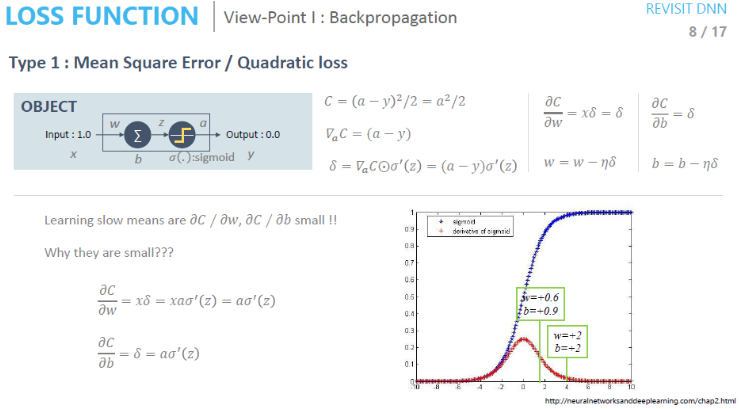
- 두 그래프의 Activation Function 미분 값을 보면 w가 0.6, b가 0.9일 때의 미분 값은 약 0.15 정도 되는 것을 볼 수 있다. 반면 w가 2, b가 2일 때는 미분 값이 약 0.01로 차이가 큰 것을 알 수 있다. 이는 Backpropagation 시 전파되는 gradient의 크기가 그만큼 줄어드는 것을 의미한다.
Backpropagation type 2 - Cross Entropy 관점
- MSE와 달리 Cross Entropy에서는 출력 레이어에서의 error 값에 대한 activation function의 미분 값이 곱해지지 않아 gradient vanishing problem에서 좀 더 자유로워진다.

Maximum Likelihood 알고리즘 유도방법

- MLE를 통해 최적의 파라미터 theta(θ)를 찾았다.
- 학습을 해서 찾은 값은 Gaussian 확률 분포에 대한 평균을 찾은 것이다.
- 이렇게 학습을 하게 되면 '확률분포'를 찾은 것이기 때문에 Sampling을 할 수 있다.
Summary
Neural Network의 학습 방법과 MLE의 학습 방법이 같다.
Neural Network의 최적해 학습 방법 Backpropagation이 정답과 출력 값의 차이를 기준으로 Network를 학습시킨다면 MLE 방법에서는 확률적인 관점으로 Network를 학습시킨다는 것이다.
- Network의 출력과 정답이 가깝기를 바란다.
- Network의 출력값과 정답 간의 차이를 확률적으로 해석할 것인가 (MLE)
- 정답과 출력간의 차이로 해석할 것인가 (Cross-Entropy)
- Deep Neural Network의 학습 방법에 대해 이해해보자.
- 모델이 데이터를 입력으로 받아 파라미터를 학습하고 최적의 파라미터를 찾는 과정을 이해한다.
- 최적의 해를 찾는 방법으로 Gradient Descent Algorithm을 배웠다.
- Backpropagation 알고리즘
- 오차역전파 방법의 핵심은 Loss Function의 미분값을 구하는 것이다.
- Backprop은 MSE 관점과 Cross-Entropy 관점에서 해석할 수 있다.
- CE(Cross Entropy) 방법은 MSE 방법에 비해 gradient vanishing problem에서 자유롭다.
- Maximum Likelihood Estimation 알고리즘
- Loss Function 최적화시키는 또 다른 방법으로는 MLE가 있다.
- 최적화 문제를 확률적 관점에서 해석하면 MLE 문제가 된다.
- Gaussian Distribution을 minimize하면 MSE 문제가 되고, Bernulli Distribution을 minimize하면 Cross-Entropy가 된다.
