
Abstract
Person Re-ID 목표는 중복되지 않는 여러 카메라에서 특정 인물을 식별하는 것이다. 본 논문에서는 closed-world setting과 open-world setting으로 나누어 설명한다.
Closed-world setting은 3가지 deep feature representation learning, deep metric learning, ranking optimization의 다른 관점에서 분석한다. 하지만 성능이 포화되면서 person re-id의 관심은 open-world setting으로 옮겨가고 있다. 논문에서는 open-world setting을 5가지 측면으로 분석한다. 기존 method의 이점 분석, powerful AGW baseline 디자인, 4가지 다른 re-id task에서 12개의 dataset으로 4가지의 다른 re-id task 달성, 새로운 평가 지표인 mINP, 중요한 미해결 문제를 다룬다.
Introduction
Person Re-ID는 query가 주어졌을 때, 이 인물이 다른 시간에 다른 장소에 나타났는지, 또는 동일한 카메라에 다른 시간에 나타났는지 여부를 확인하는 것이다. 이때 query는 image, video sequence, text description으로 표현될 수 있다.
Re-ID의 도전과제
different viewpoints, varying low-image resolutions, illumination changes, unconstrained poses, occlusions, heterogeneous modalities, complex camera environments, background clutter, reliable bounding box generations 등
초기연구
초기에는 hand-crafted feature construction with body structure 또는 body structure에 초점을 두었으나, 연구 지향적인 시나리오와 실제는 여전히 큰 격차가 있다. 그래서 본 논문에서는 포괄적인 조사를 하고, 다양한 Re-ID 작업에 대한 powerful baseline을 개발하고 여러 미래의 방향성에 대해 논의한다.
3가지 주요 차별점
- 기존 딥러닝 방법론에 대한 심층적이고 포괄적인 분석을 제공
- AGW(Attention Generalized mean pooling with Weighted triplet loss)와 mINP(mean Inverse Negative Penalty) 제안
- closed-world와 open-world application의 격차를 줄이기 위한 연구 방향 논의
일반적인 person re-id 시스템 구축 과정
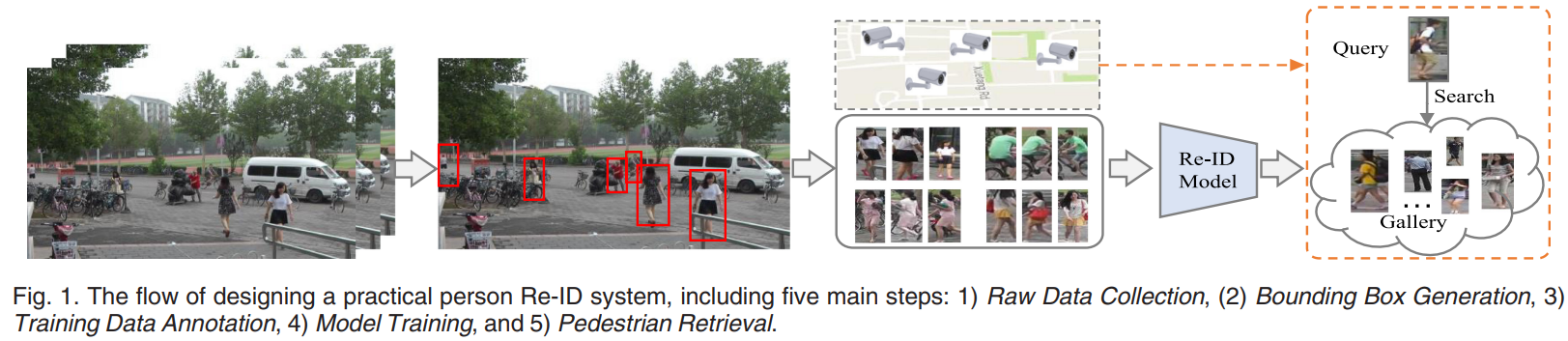
- Raw Data Collection: 감시 카메라에서 raw video data 획득
- Bounding Box Generation: raw video data에서 사람 이미지를 포함하는 bounding box 추출
- Training Data Annotation: 카메라 간 라벨 주석
- Model Training: 주석이 달린 이미지/비디오로 판별력 있고 견고한 re-id 모델 학습
- Pedestrian Retrieval: query와 gallery set에서 feature representation을 추출하고, query-to-gallery 유사도를 계산하여 ranking list를 얻는 단계
Closed-world와 Open-world의 단계별 차이점
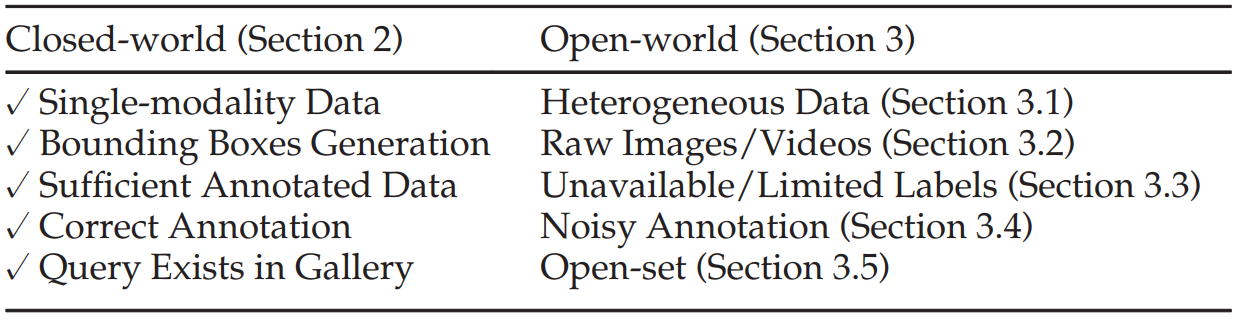
- heterogeneous data: infrared images, sketches, depth images, text descriptions
Closed-World Person Re-ID
아래와 같은 가정을 전제로 한다.
1. 인물은 이미지 또는 비디오 형태의 single-modality 가시광선 카메라로 캡처된다.
2. 인물은 bounding box로 표현된다.
3. 모델 학습에 필요한 충분한 주석이 달린(annotated) 학습 데이터가 있다.
4. annotation은 일반적으로 정확하다.
5. query person은 gallery set에 포함되어 있어야 한다.
그리고 closed-world Re-ID 시스템은 3가지 주요 구성요소(feature representation learning, deep metric learning, ranking optimization)를 포함한다.
Feature Representation Learning
특징 학습 전략은 4가지 범주로 나뉜다.
1) Global Feature
: 추가 주석 없이 각 사람 이미지에 대한 global feature vector를 추출한다. 초기 딥러닝 적용에서 주로 사용되었으며, IDE(ID-discriminative Embedding) 모델이 널리 사용된다.
- Attention Information: attention 메커니즘은 feature representation 학습을 강화한다.
i) Group1 (Intra-image attention): pixel level attention, channel-wise feature re-weighting, background suppressing 등을 통해 이미지 내에서 중요한 부분을 강조한다.
ii) Group2 (Cross-image attention): context-aware attentive feature learning, attention consistency property를 통해 여러 이미지 간의 관계를 활용한다.
2) Local Feature
: part/region 별 특징을 집계하여 misalignment에 강건하게 만든다.
- Automatic body part detection: human parsing 또는 pose estimation으로 자동으로 생성된 신체 부위 특징을 사용한다.
- Horizontal division: 이미지를 수평으로 분할하여 부분 특징을 학습한다.
3) Auxiliary Feature
: 추가적인 주석 정보(semantic attributes)나 생성/증강된 훈련 샘플을 사용하여 특징 표현을 강화한다.
- Semantic Attributes: 사람의 속성(성별, 옷 색깔)을 활용하여 일반화 능력을 향상한다.
- Viewpoint Information: 시점 정보를 활용하여 신원 판별적이고 시점 불변적인 특징 표현을 학습한다.
- GAN Generation: GAN을 사용하여 다양한 자세나 카메라 스타일을 가진 사람 이미지를 생성하여 데이터 증강 및 도메인 적응에 활용한다.
- Data Augmentation: Random Erasing, batch DropBlock 등 이미지에 무작위 노이즈를 추가하거나 특정 영역을 드롭하여 모델의 강건함과 일반화 능력을 향상한다.
4) Video Feature
: 각 사람이 여러 프레임으로 구성된 비디오 시퀀스로 표현되는 비디오 기반 re-id에서 풍부한 외형 및 시간 정보를 포착한다.
- RNN 구조, attention mechanism, snippet-level learning strategy 등이 시간 정보 모델링에 사용된다.
- 노이즈가 많은 프레임이나 폐색된 영역 처리를 위해 informative frames selection, affine hull 등이 활용된다.
5) Architecture Design
대부분의 re-id 연구는 이미지 분류용 네트워크 아키텍처(ex. ResNet50 등)를 backbone으로 채택하지만, re-id에 특화된 수정이나 새로운 아키텍처도 제안되었다. (ex. FPNN, BraidNet, MLFN, OSNet, Auto-ReID)
Deep Metric Learning
거리 측정 학습은 특징 표현 학습을 안내하는 loss function 설계를 통해 이뤄진다.
- Loss Function Design
-
Identity Loss ()
Re-ID 훈련을 이미지 분류 문제로 간주하며, 각 identity를 고유한 클래스로 취급한다. 일반적으로 softmax cross-entropy를 사용한다.
label smoothing이 오버피팅을 방지하고 일반화 능력을 향상하는데 사용된다.
-
Verification Loss ()
pariwise 관계를 최적화한다. contrastive loss는 동일한 신원의 샘플 간 거리는 가깝게, 다른 신원의 샘플 간 거리는 멀게 한다. binary verification loss는 입력 이미지 쌍이 동일한 신원인지 여부를 분류한다.
-
Triplet Loss ()
retrieval ranking 문제로 간주하며, anchor 샘플, 동일한 신원의 positive sample, 다른 신원의 negative sample로 구성된 triplet을 사용한다. hard triplet mining이 중요하며, quadruplet network로 확장되기도 한다.
-
OIM Loss ()
memory bank 스키마를 사용하여 online instance matching을 수행한다.
- Training Strategy
불균형한 샘플 수와 positive/negative 샘플 쌍 문제를 다루기 위해 identity sampling, adaptive sampling, sample re-weighting, multi-loss dynamic training 등이 사용된다.
Ranking Optimization
테스트 단계에서 검색 성능을 향상하는 데 중요한 역할을 한다.
- Re-Ranking: 초기 순위 목록을 최적화하기 위해 gallery-to-gallery 유사도를 활용한다. (ex. k-reciprocal reranking)
- Rank Fusion: 여러 방법으로 얻은 다수의 순위 목록을 융합하여 검색 성능을 향상한다.
Datasets and Evaluation
CMC(Cummulative Matching Characteristics)와 mAP(mean Average Precision)는 Re-ID 시스템 평가에 널리 사용되는 두 가지 지표이다. 최근 데이터셋은 이미지 및 ID 수가 급격히 증가하고, 카메라 수도 많아지며, bounding box 생성이 자동화되는 추세이다. 딥러닝 기술의 발전으로 Market-1501과 같은 데이터셋에서 이미지 기반 Re-ID는 인간 수준 이상의 Rank-1 정확도를 달성했습니다. part-level feature learning과 attention mechanism은 성능 향상에 기여했으며, multi-loss 훈련도 효과적인 것으로 나타났습니다. 그럼에도 불구하고, MSMT17과 같은 대규모의 도전적인 데이터셋이나 cross-dataset evaluation에서는 여전히 개선의 여지가 큽니다.
Open-World Person Re-Identification
실제 응용에 직면하는 다양한 시나리오를 다룬다.
Heterogeneous Re-ID (이중 모달리티 Re-ID)
- Depth-Based Re-ID: depth images를 활용하여 조명/옷 변화에 강건한 Re-ID를 수행한다.
- Text-to-Image Re-ID: 텍스트 설명으로 사람 이미지를 검색한다.
- Visible-Infrared Re-ID: 가시광선과 적외선 이미지 간의 cross modality 매칭을 처리한다. GAN 기술이 모달리티 간의 불일치를 줄이는 데 활용된다.
- Cross-Resolution Re-ID: low-resolution 및 high-resolution 이미지 간의 매칭을 수행한다.
End-to-End Re-ID
bounding box 생성에 대한 의존도를 줄이기 위해 person detection과 Re-ID를 단일 프레임워크에서 공동으로 수행한다. Person Search, Multi-Camera Tracking 등과 관련이 있다.
Semi-Supervised and Unsupervised Re-ID
- Unsupervised Re-ID: 주석이 없는 데이터에서 불변 특징(invariant components)을 학습하거나, cross-camera label estimation(ex. dynamic graph matching, iterative clustering)을 통해 pseudo labels을 생성하여 딥러닝 모델을 훈련한다.
- Unsupervised Domain Adaptation: 라벨이 있는 소스 데이터셋에서 학습한 지식을 라벨이 없는 타겟 데이터셋으로 전이한다.
- Target Target Image Generation: GAN을 사용하여 소스 도메인 이미지를 타겟 도메인 스타일로 변환하여 타겟 도메인에서도 지도 학습을 가능하게 한다. (ex. PIGAN, SPGAN)
- Target Domain Supervision Minig: 소스 데이터셋에서 잘 훈련된 모델을 사용하여 라벨이 없는 타겟 데이터셋에서 직접 감독 신호를 추출한다. (ex. exemplar memory learning, meta-learning, self-paced contrastive learning(SpCL)). 최근 unsupervised re-id는 성능이 크게 향상되었지만, 지도 학습과의 격차는 여전히 존재한다.
Noise-Robust Re-ID
데이터 수집 및 주석 어려움으로 인한 노이즈 문제를 해결한다.
- Partial Re-ID: 폐색이 심하여 사람 신체의 일부만 보이는 경우의 Re-ID 문제를 다룬다. (ex. VPM, PGFA)
- Re-ID with Sample Noise: 부정확한 탐지/추적 결과로 인해 이미지/비디오 시퀀스에 이상치 영역/프레임이 포함된 경우이다. pose estimation cues 또는 attention cues를 활용하여 노이즈 영역의 영향을 줄인다.
- Re-ID with Label Noise: 주석 오류로 인한 라벨 노이즈를 다룬다. label smoothing 기술이나 feature uncertainty를 모델링하는 방법이 사용된다.
Open-Set Re-ID and Beyond
open-set Re-ID는 query person이 gallery set에 없을수도 있는 시나리오에서 person verification 문제로 공식화된다. Adversarial PersonNet(APN)과 같은 방법이 연구되었다.
- Group Re-ID: 개인이 아닌 그룹의 사람을 연결하는 것을 목표로 한다.
- Dynamic Multi-Camera Network: 새로운 카메라나 프로브에 대한 모델 적응이 필요한 동적으로 업데이트되는 감시 시스템이다.
An Outlook: Re-ID in Next Era
mINP: A New Evaluation Metric for Re-ID
현재 널리 사용되는 CMC 및 mAP 지표는 가장 어려운(hardest) 올바른 매치(correct match)를 찾는 비용을 완전히 반영하지 못한다. 이를 위해 새로운 평가 지표은 mINP(mean Inverse Negative Penalty)가 제안된다.
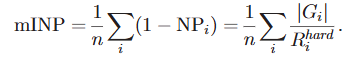
여기서 는 query i의 가장 어려운 올바른 매치의 순위 위치를 나타내고, 는 query i에 대한 올바른 매치의 총 수를 나타낸다. mINP 값이 클수록 더 좋은 성능을 의미하며, 이는 모든 올바른 매치를 찾는 데 드는 노력을 추가로 평가한다.
A New Baseline for Single-/Cross-Modality Re-ID
AGW(Attention Generalized mean pooling with Weighted triplet loss)는 BagTricks를 기반으로 설계된 새로운 강력한 baseline이다.
1. Non-local Attention (Att) Block
Non-local attention block을 사용하여 모든 위치에서 특징의 가중합을 얻고, 이는 residual learning 전략을 포함한다.
2. Generalized-mean (GeM) Pooling
학습 가능한 풀링 계층인 generalized-mean (GeM) pooling을 채택하여 fine-grained instance retrieval을 위한 도메인 특정 판별 특징을 포착한다.
여기서 는 back-propagation 과정에서 학습되는 풀링 하이퍼파라미터이다.
3. Weighted Regularization Triplet (WRT) loss
softmax cross-entropy를 사용하는 identity loss와 함께 weighted regularized triplet loss를 통합한다. 이는 추가적인 margin 파라미터 없이 긍정 및 부정 쌍 간의 상대적 거리 최적화를 수행한다.
<br<
AGW는 single modality 및 교차 모달리티(visible-infrared) Re-ID 작업에서 경쟁력 있는 성능을 달성한다. 특히 mINP 지표에서도 우수한 성능을 보인다.
Under-Investigated Open Issues
1. Uncontrollable Data Collection: 현실적인 복합 환경에서의 데이터 수집 문제
- Multi-Heterogeneous Data: 다양한 모달리티와 해상도를 자동으로 처리할 수 있는 시스템
- Cloth-Changing Data: 옷이 바뀌는 상황에서의 사람 재식별
2. Human Annotation Minimization: 사람의 주석 작업 최소화
- Active Learning: 사람의 개입을 통해 새로운 데이터에 대한 라벨을 얻고 모델을 업데이트함
- Learning for Virtual Data: 합성 데이터셋을 활용하여 실제 데이터셋과의 격차를 줄이는 연구
3. Domain-Specific/Generalizable Architecture Design: Re-ID에 특화되거나 여러 도메인에 일반화될 수 있는 아키텍처 설계
- Re-ID Specific Architecture: OSNet, Auto-Re-ID 문제에 최적화된 아키텍처
- Domain Generalizable Re-ID: 여러 소스 데이터셋에서 학습하여 새로운, 보지 못한 데이터셋에서도 성능을 유지하는 모델
4. Dynamic Model Updating: 동적으로 업데이트되는 감시 시스템에 대한 모델 적응
- Model Adaptation to New Domain/Camera: 새로운 카메라가 추가되거나 도메인이 변경될 때 모델을 적응시키는 방법
- Model Updating with Newly Arriving Data: 새로운 데이터가 도착할 때 모델을 효율적으로 업데이트하는 증분 학습(incremental learning) 방법
5. Efficient Model Deployment: 확장성 문제를 해결하기 위한 효율적인 모델 설계
- Fast Re-ID: hashing 기술을 활용하여 검색 속도를 높이는 방법
- Lightweight Model: model distillation 등을 통해 경량화된 모델 설계
- Resource Aware Re-ID: 하드웨어 구성에 따라 모델을 적응적으로 조정하는 Deep Anytime Re-ID (DaRE)와 같은 방법
결론
이 논문은 Person Re-ID 분야에 대한 포괄적인 조사를 제공하며, closed-world 설정과 open-world 설정에서의 과제를 심층 분석한다. 제안된 AGW baseline과 mINP 평가 지표는 미래 Re-ID 연구에 중요한 지침을 제공한다.
