범주형 데이터
머신러닝 모델은 숫자를 입력값으로 받아들임 → 문자열 혹은 범주형 데이터를 적절히 숫자로 변환(encoding)하는 과정이 필요하다.
범주형 데이터 (categorical data)
- nominal data: 순서가 없는 범주형 데이터 (성별, 도시명…)
- ordinal data: 순서가 있는 범주형 데이터 (학력, 만족도…)
범주형 데이터의 인코딩 방법
-
label encoding
- 각 카테고리를 숫자로 변환하는 방법이다.
- red → 1, green → 2, blue → 3
- 문제점: 카테고리 값의 크기나 순서가 없는 경우에도, 모델이 숫자 간의 크기 차이를 패턴으로 잘못 학습할 수 있음 ← ex) nominal data type인 color data
-
one-hot encoding
-
범주형 데이터를 이진벡터(binary vector)로 표현하는 방법이다.
-
데이터가 n개의 고유 범주값을 가지는 경우, 각 범주를 n차원의 벡터 공간에서 서로 직교하는 벡터로 표현한다.
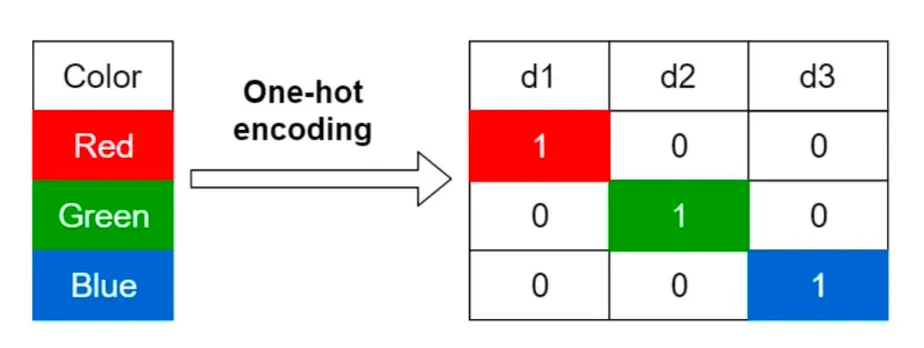
red = [1, 0, 0] green = [0, 1, 0] blue = [0, 0, 1] -
장점: 해석이 명확함, 범주 간의 우열관계를 제거함
-
단점:
- 고차원 문제: 영화가 10만개면 10만 차원 벡터
- sparse vector: 대부분이 0이라 비효율적인 표현이 될 수 있음
- 관계성 표현 불가: 액션 영화와 SF 영화의 유사성을 표현하지 못함
-
임베딩(Embedding)
복잡한 객체들을 고정된 차원의 벡터로 변환하는 기술이다.
- 임베딩 대상: 텍스트, 이미지, 비디오, 상품, 사용자 등
- 고정된 차원의 크기: 수십차원 ~ 수천차원
- 장점:
- 표현력: 비교적 저차원으로도 표현할 수 있는 데이터의 개수가 많다.
- 효율성: GPU로 빠른 벡터 연산이 가능하다.
- 유사성 보존: 비슷한 데이터는 벡터 공간에서도 가까이 위치한다.
- 필요성:
- 데이터의 벡터화: 복잡한 데이터를 벡터로 변환하면, 데이터 간의 유사성을 수치적으로 측정 가능하다.
- 차원 축소: 고차원 데이터를 저차원으로 축소해 처리 속도를 높이고 계산 자원을 절약할 수 있다.
- 의미 있는 표현 학습: 벡터 간 거리 또는 각도를 통해 데이터 간의 관계를 학습할 수 있다.
- 유형:
- 텍스트 임베딩: 단어나 문장을 고정된 크기의 벡터로 변환하여 의미와 문맥적 관계를 반영 → Word2Vec, BERT
- 이미지 임베딩: 이미지의 시각적 특징을 벡터로 변환하여 이미지 간의 유사성을 표현 → CNN 기반 이미지 임베딩
- 엔티티 임베딩: 사용자, 상품, 영화와 같은 다양한 엔티티를 벡터로 변환하여 엔티티 간의 관계를 학습 → 추천 시스템에서의 사용자-상품 간의 유사도 측정
Word Embedding
주변 단어와의 유사성 및 관계를 수치화하여, 벡터로 표현하는 딥러닝 기반 기술이다.
→ 단어를 컴퓨터가 이해할 수 있도록 숫자로 바꾸되, 의미도 보존하려는 것이다.
"사과" → [0.7, 0.2, 0.1]
"바나나" → [0.8, 0.3, 0.1]
"자동차" → [-0.6, 0.9, 0.2]- 목적: 단어를 one-hot encoding으로 표현할 경우, 차원이 너무 크고 단어 간의 관계성을 표현하지 못하는 문제를 극복하기 위함이다.
- 특징:
- Dense vector: 0과 1만 있는 one-hot encoding과 달리 모든 원소가 실수값으로 채워짐
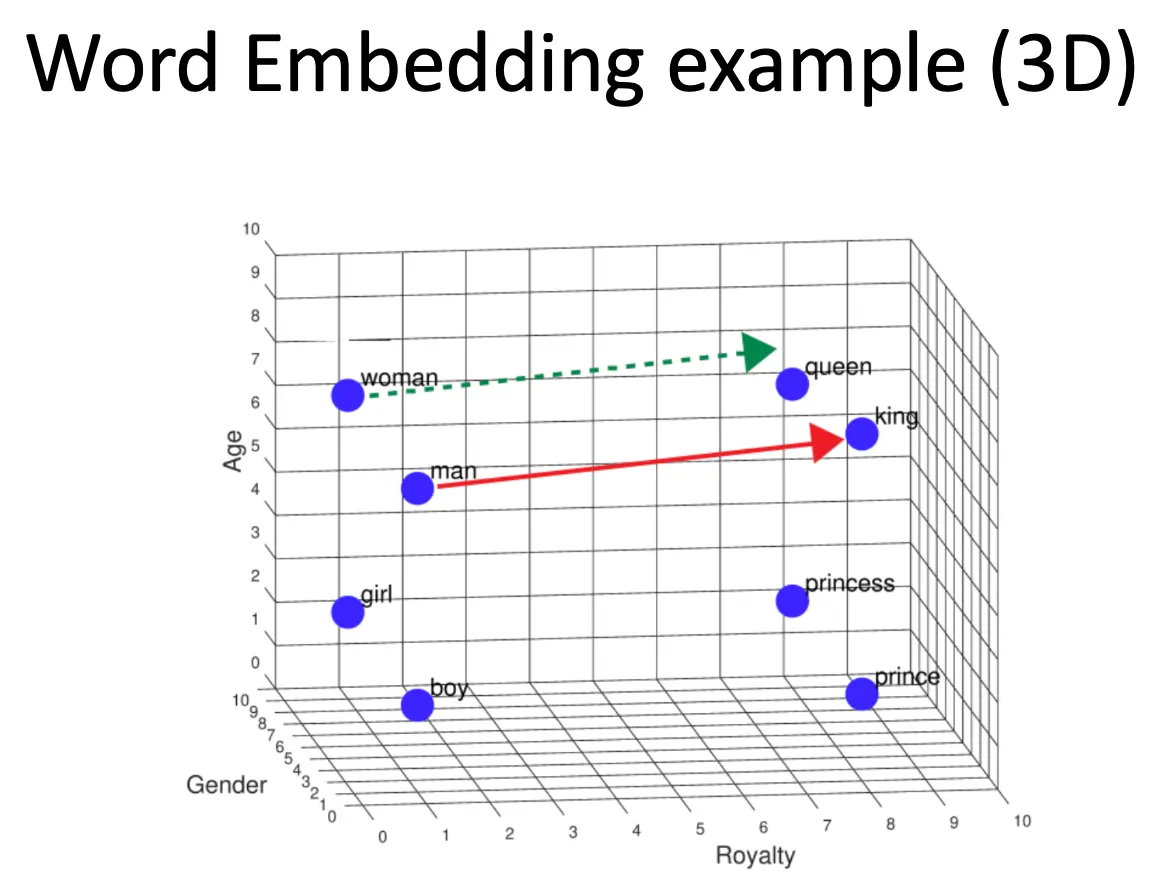
- 의미적 유사성 표현: “king”과 “queen” 같은 단어는 비슷한 방향의 벡터를 가짐
- 관계 해석 가능: 벡터 간 거리나 방향으로 관계 유추 가능 → (king − man + woman ≈ queen)
- 주요 학습 방법
- Word2Vec
- CBOW(Continuous Bag of Words): 주변 단어(context words)로 중심 단어(center word)를 예측함 → 문맥 전체를 보고 중심 단어 의미를 학습함
예: “The cat sat on the table.” → “The, cat, sat, on, the” → “table” 예측 - Skip-gram: 중심 단어로 주변 단어들을 예측함 → 적은 데이터나 희귀 단어에 강함
중심 단어 “cat” → “The”, “sat”, “on” 예측
- CBOW(Continuous Bag of Words): 주변 단어(context words)로 중심 단어(center word)를 예측함 → 문맥 전체를 보고 중심 단어 의미를 학습함
- GloVe, FastText라는 것들도 있다.
- Word2Vec
Machine Learning의 원리
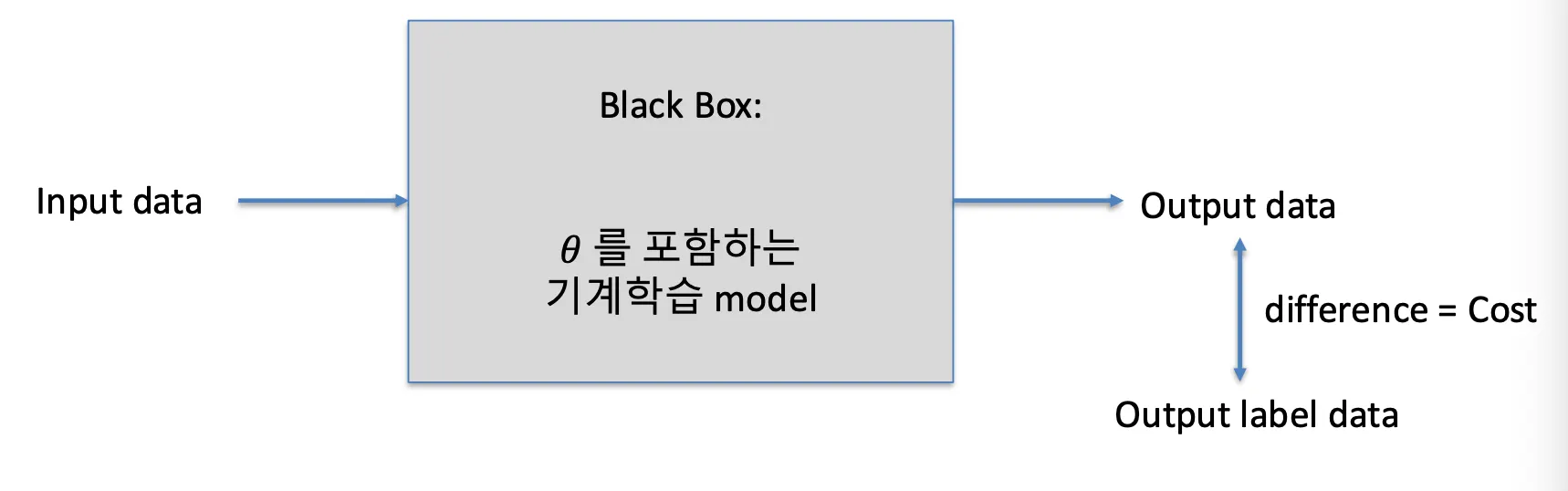
- 학습 데이터의 구성
- input data와 output data
- ex) photo → fruit
- 비용함수(Loss function)
- 학습(train): 학습 데이터에 대하여, 비용함수의 합이 최소가 되도록 하는 𝜃값들을 계산하는 과정이다.
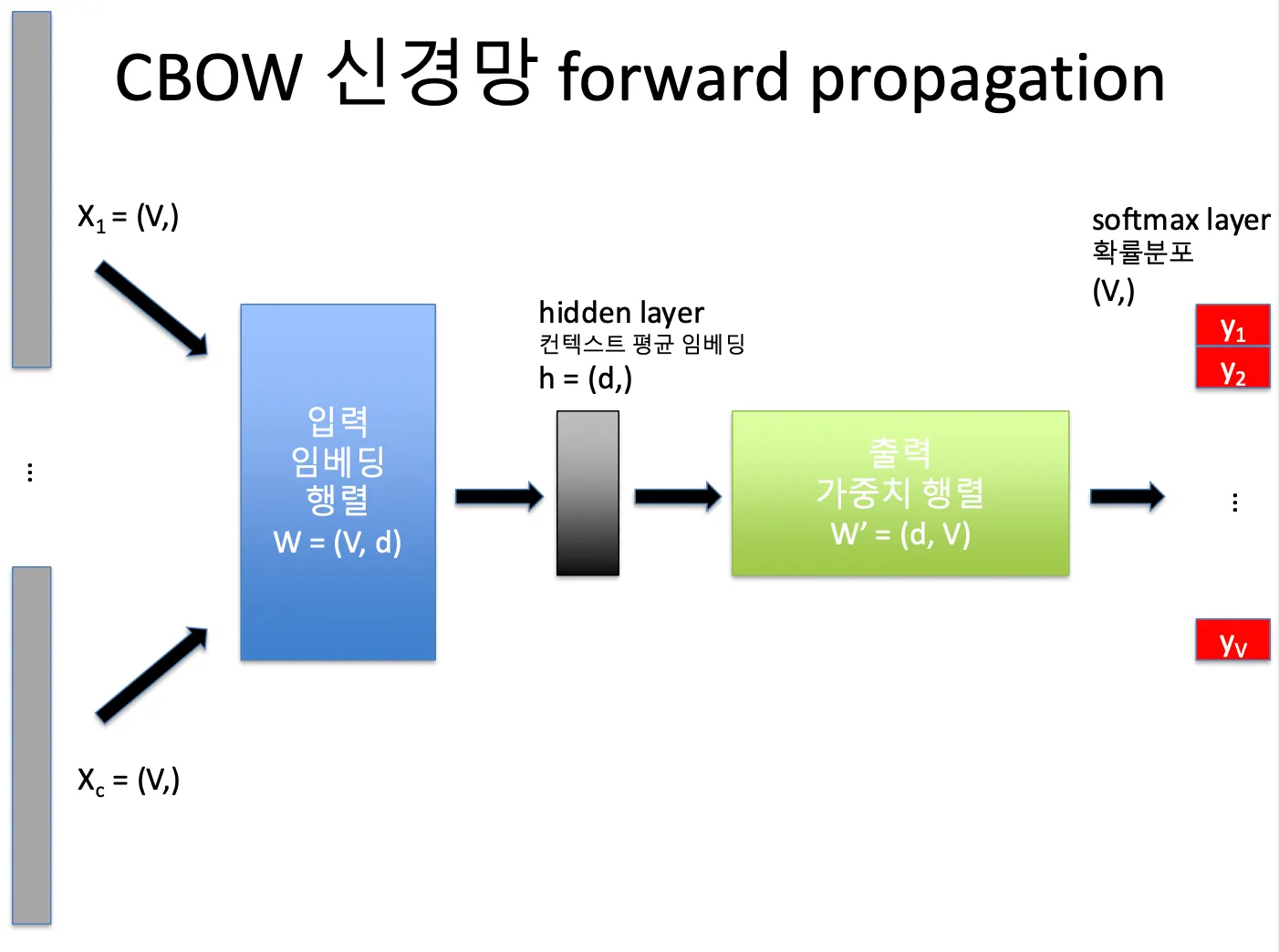
CBOW (Continuous Bag Of Words)
주변 단어(context words)로 중심 단어(center word)를 예측하는 방식이다.
“The cat sat on the mat.”
이라면, 중심 단어(center)는 “cat”,
주변 단어(context)는 “The”, “sat”, “on”, “the”.
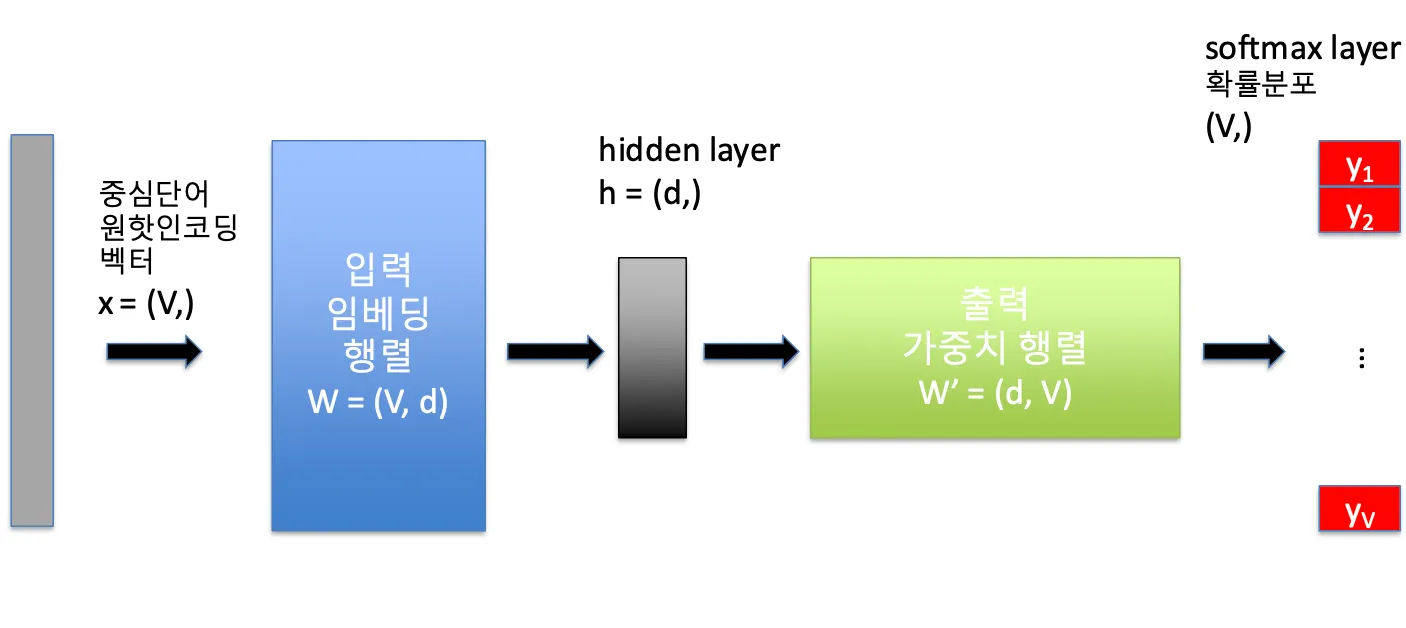
→ CBOW는 “The, sat, on, the”를 보고 “cat”을 맞히도록 학습하는 모델임| 기호 | 의미 | 예시 |
|---|---|---|
| V | 단어 사전(vocabulary) 크기 | 10,000개 단어 |
| d | 임베딩 벡터 차원 수 | 300 |
| c | 컨텍스트 단어 수 | 좌우 각각 2개씩이면 4 |
- 입력층 (input layer)
- 각 컨텍스트 단어를 원-핫 벡터로 표현 (크기 V)
- 예를 들어 “The” → [0,0,0,1,0,...]
- 컨텍스트 단어가 c개라면 → X의 크기 = (c, V)
- 입력 임베딩 행렬 (W)
- 크기: (V, d)
- 각 단어(행)는 d차원 벡터로 표현된다.
- 원-핫 벡터 × W → 단어의 임베딩 벡터를 얻는다.
- 즉, 컨텍스트 단어 c개를 임베딩하면 → (c, d) 행렬이 된다.
- 은닉층 (Hidden Layer)
- 컨텍스트 단어들의 임베딩을 평균(mean pooling)
- h는 (d,) 크기의 벡터
- h가 문맥의 의미를 요약한 벡터이다.
- 출력층 (Output Layer)
- 출력 가중치 행렬: W′ (d × V)
- 은닉층 h와 곱해서 단어별 점수(로짓)를 구한다.
- softmax를 적용해 확률로 변환 → 즉, 각 단어가 중심 단어일 확률이 된다.
- 손실 함수 (Loss)
- 예측 확률분포(y)와 실제 중심 단어의 원-핫 벡터(t) 사이의 차이를 Cross-Entropy Loss로 계산한다.
- 이 손실이 최소가 되도록 W, W′를 학습한다.
최종 학습 이후, 각 단어에 대한 임베딩은 W 행렬에 기반한다.
→ W 행렬의 각 행 = 각 단어의 최종 임베딩 벡터
| 단계 | 이름 | 역할 |
|---|---|---|
| 입력층 | 컨텍스트 단어 원-핫 | 주변 단어 입력 |
| 임베딩 행렬 W | (V, d) | 각 단어의 벡터 표현 |
| 은닉층 h | (d,) | 컨텍스트 단어 평균 |
| 출력층 W′ | (d, V) | 중심 단어 확률 계산 |
| 손실함수 | Cross-Entropy | 예측 오차 최소화 |
| 최종 산출 | W | 단어 임베딩 |
예시)
“The cat sat on the mat.”
입력: “The, sat, on, the”
출력: “cat”
→ 이 예측을 수많은 문장에서 반복하면서 “cat”
주변엔 “dog”, “kitten” 같은 단어들이 자주 등장한다는 걸 학습함
결과적으로 ‘cat’ 벡터는 ‘dog’ 벡터와 가까워짐Skip-gram
중심 단어(center word)로부터 주변 단어(context words)를 예측하는 방식이다.
“The cat sat on the mat.” → 중심 단어가 “cat”일 때, 모델은 “The”, “sat”, “on”, “the” 같은 주변 단어들을 예측하도록 학습한다.
| 기호 | 의미 | 예시 |
|---|---|---|
| V | 단어 사전 크기 | 10,000 |
| d | 임베딩 벡터 차원 | 300 |
| c | 예측할 컨텍스트 단어 수 | 4 (좌우 2개씩) |
- 입력층 (Input Layer)
- 입력은 하나의 중심 단어이다.
- 원-핫 인코딩 벡터: 크기 (V,)
- ex) “cat” → [0,0,0,1,0,...]
- 입력 임베딩 행렬 (W)
- 크기: (V, d)
- 원-핫 벡터 × W → 중심 단어의 임베딩 벡터 (d,) → “cat”의 의미를 담은 300차원 벡터 하나가 만들어진다.
- 출력 가중치 행렬 (W′)
- 크기: (d, V)
- 중심 단어 임베딩을 이용해 각 단어가 주변 단어일 확률을 예측한다. → 모든 단어에 대해 이 단어가 주변 단어일 확률 분포가 된다.
- 손실 함수 (Loss)
- 실제 주변 단어들은 원-핫 벡터로 표시된다.
- 예측 확률(y)과 실제 정답(one-hot)의 차이를 Cross-Entropy Loss로 계산한다.
- 이 손실을 최소화하도록 W, W′를 학습한다.
최종 학습 이후, 각 단어에 대한 임베딩은 W 행렬에 기반한다.
→ W 행렬의 각 행 = 각 단어의 최종 임베딩 벡터
이미지 임베딩
이미지를 embedding vector로 바꿔서 이미지 간의 유사성을 계산할 수 있게 하는 기술이다.
이미지 데이터는 픽셀값으로 표현됨 → width × height × channel (224×224×3 → 약 150,000차원)
고차원 픽셀 데이터를 그대로 비교하기엔 복잡하고 비효율적이다.
→ 딥러닝 모델(CNN 등…)을 이용해 의미 있는 특징만 추려서 저차원 벡터로 압축
- 목적:
- 유사도 계산 가능
- 검색 가능
- 분류 가능
- 임베딩 간 유사도 계산
방법 수식 특징 Euclidean Distance 두 벡터 간의 직선 거리 값이 작을수록 비슷 Cosine Similarity 두 벡터의 각도(방향) 비교 1에 가까울수록 비슷 Dot Product (내적) 방향이 비슷하면 값이 큼 코사인과 유사 (정규화된 경우 동일)
→ 보통 이미지 임베딩 비교엔 코사인 유사도를 많이 사용한다.
- Top-K 유사 객체 검색
- Brute-force
- 모든 임베딩과 하나씩 거리 계산
- Approximate Nearest Neighbor (ANN)
- 근사치로 빠르게 유사한 것만 찾아줌
- 대규모 데이터에 효율적
- Brute-force
ResNet-50
50층 깊이의 CNN 신경망 구조로서, Residual Connection(잔차 연결)을 도입해 학습 안정화를 시킨 모델이다.
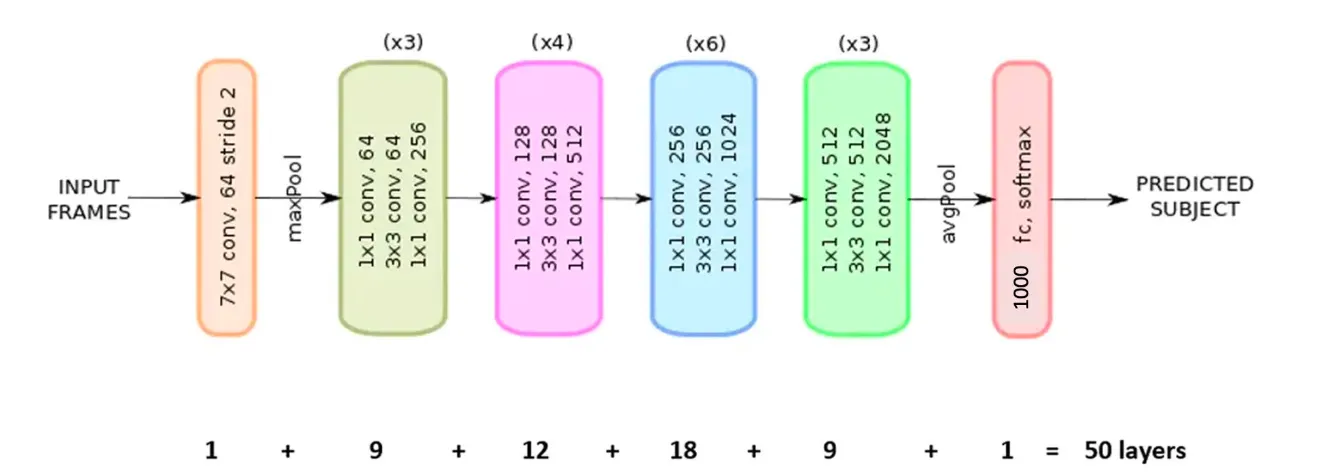
→ 기울기 소실 문제를 해결했다, 대규모 이미지 분류에서 강력한 성능을 보이는 딥러닝 모델 중 하나이다.
| 특징 | 설명 |
|---|---|
| Residual Connection | 이전 층의 입력을 다음 층 출력에 더함 → 기울기 소실(vanishing gradient) 방지 |
| 층 수 | 50개 (그래서 이름이 ResNet-50) |
| 출력 특징벡터(임베딩) | Fully Connected(FC) 층 이전의 2048차원 벡터 |
- ResNet-50 학습용 데이터와 및 비용함수
항목 내용 Input 데이터셋 ImageNet (약 128만 장 이미지, 1000개 클래스) 입력 크기 224×224×3 (가로×세로×RGB채널) 출력 1000차원 확률 벡터 (각 클래스 확률) 예시 [0.01, 0.0001, ..., 0.85, ..., 0.00005] → 가장 높은 0.85가 예측 클래스 손실함수 Cross-Entropy Loss
