1. 학습한 내용
Preprocessing 데이터 전처리
Data Preprocessing
-데이터를 분석하기 용이하게 고치는 모든작업
-데이터 전처리 과정에서 80~90%를 소비
-알고리즘이나 파라메터가 잘못된 경우에는 지속적인 실험으로 문제를 개선할 수 있지만 데이터 자체의 문제일 경우 실험결과가 개선되지 않는다
-데이터 오류 => 결측치, 데이터 오류, 이상치, 데이터 형식, 범주형 데이터 etc
-이를 해결하기 위해 Scaling, Sampling, Dimensionality reduction, Categorical Valiable to Numeric Variable
Scaling
-변수의 크기가 너무 작거나 너무 큰 경우 결과에 미치는 영향력이 일정하지 않을 수 있기 때문에 변수의 크기를 일정하게 맞추어 주는 작업
-scikit-learn 함수 = Min-Max 스케일링, z-정규화를 이용한 Standard 스케일링
-Min-Max 스케일링 = 갑의 범위가 0~1사이로 변경됨, 특정 값들이 전체에 미치는 영향 줄임
-전체적인 수치를 1 기준으로 비율이 조정되기 때문에 모든 Feature들이 같은 조건에서 학습 될 수 있게 함
-먼저 필요한 패키지를 가져옵니다.
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
-여기까지가 기본적으로 불러와야할 코드
abalone_columns = list()
for l in open('data/abalone_attributes.txt'):
abalone_columns.append(l.strip())
data = pd.read_csv('data/abalone.txt', header=None, names=abalone_columns)
-수치들을 맞춰주는 작업 = Scaling
-성별이란 label 데이터를 뽑기
label = data['Sex']
-삭제 = del
del data['Sex']
-데이터 각 변수별 기초통계량 확인 가능
data.describe()
-float = 실수형
data.info()
-Scaling 공식
data = (data - np.min(data)) / (np.max(data)-np.min(data))
from sklearn.preprocessing import MinMaxScaler
mMscaler = MinMaxScaler()
mMscaler.fit(data)
-명령어
mMscaled_data = mMscaler.fit_transform(data);
-Standard Scaling
-표준정규분포화 시켜서 스케일링하는 방식
-데이터 평균 = 0, 표준편차 = 1 이 되도록 스케일링함
-z = x - 데이터평균 / 데이터 표준편차
from sklearn.preprocessing import StandardScaler
sdscaler = StandardScaler()
sdscaled_data = sdscaler.fit_transform(data)
-Sampling
-클래스 불균형 문제를 해결하기 위함
-분류를 목적으로 하는 데이터셋에 클래스 라벨의 비율이 균형적으로 맞지 않고
-한쪽으로 치우치게 되어 각 클래스의 데이터를 학습하기 어려워지는 경우
-적은 클래스의 경우 증가 oversampling
-많은 클래스의 경우 감소 undersampling
-가장 쉽게 샘플링하는 방법은 random으로 데이터 선택, 복제, 제거하는 방식
-복제하는 경우 = 선택된 데이터가 많아지게 되면서 과접합 될 수 있다
-제거하는 경우 = 정보 자체의 손실이 생길 수 있다
-샘플링 알고리즘은 imblearn에서 제공
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
ros = RandomOverSampler()
rus = RandomUnderSampler()
oversampled_data, oversampled_label = ros.fit_resample(data,label)
oversampled_data = pd.DataFrame(oversampled_data, columns = data.columns)
oversampled_data
undersampled_data, undersampled_label = rus.fit_resample(data,label)
undersampled_data.shape
-SMOTE(Synthetic Minority Oversampling Technique)
-임의의 샘플링은 과적합, 손실의 문제가 있어 SMOTE알고리즘이 대책으로 제시
-수가 적은 클래스의 점을 하나 선택해 k개의 가까운 데이터샘플을 찾고 그 사이에 새로운 점을 생성하는 방식
-데이터 손실이 없고 과적합을 완화 시킬수 있다
from sklearn.datasets import make_classification
data, label = make_classification(n_samples=1000, n_classes=3,
n_clusters_per_class=1,
weights=[0.05,0.15,0.8], class_sep=0.8,
random_state=2022)
-cluster = 집합
-informative = 관계계수 (관계를 가지는 개수 값)
-redundant = 불필요한
-class_sep = 데이터 집적도
plt.scatter(data[:,0],data[:,1],c=label,linewidth=1,edgecolor='black')

from imblearn.over_sampling import SMOTE
smote = SMOTE(k_neighbors=5)
-리샘플링
smoted_data, smoted_label = smote.fit_resample(data,label)
-각각 클래스 비율 확인
print('원본 데이터의 클래스 비율 \n{}'.format(pd.get_dummies(label).sum()))
print('\nSMOTE 결과 \n{}'.format(pd.get_dummies(smoted_label).sum()))
-제일 값이 큰 데이터로 맞춰준다
-남자 여자 성소수자 => 다수결로 뭔가 결정할 때 소수의 피해가 커질수 밖에 없다
-남자 100 여자 97 소수7 => SMOT 샘플링 => 제일 많은 100에 맞춰진다
plt.scatter(smoted_data[:,0],smoted_data[:,1],
c=smoted_label,linewidth=1,edgecolor='black')

-Dimensionality Redection 차원축소
-차원의 저주 = 저차원에서는 발생하지 않던 현상들이 고차원에서 발생하는 현상
-이유? = 고차원으로 갈수록 공간 크기 증가,데이터가 존재하지 않는 빈공간 생김 = 문제
-필요없는 변수를 제거하고 과적합을 방지위해 데이터차원을 축소
-사람이 해석하기에도 어려움이 있어 차원을 축소하는 작업을 함
-픽셀단위로 쪼개지는 그림파일 = x,y,c(color값)의 정보로 구성, 2차원 데이터
-=> 두번째 줄을 첫번째 줄 뒤로 붙이는 식으로 일자로 만들어서 해석, 1차원 데이터
-상하좌우같은 것은 컴퓨터에겐 의미가 없다
#차원 축소
from sklearn.datasets import load_digits
digits = load_digits()
data = digits.data
label =digits.target
#digits의 데이터를 뽑아내기
데이터 모양 바꿔주기 = numpy 명령어 reshape
plt.imshow(data[0].reshape(8,8))
print('Label:{}'.format(label[0]))

#Principal Component Analysis(PCA 주성분 분석)
#대표적인 차원축소 기법
#데이터를 가장 잘 표현하는 축으로 Projection해서 사용
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
#데이터의 주 성분을 얼마나 줄일지를 결정, 지금같은 경우 2차원으로 줄이겠다는 것
new_data = pca.fit_transform(data)
new_data.shape
new_data[0]
#기존에 있던 데이터들을 합쳐서 차원을 축소(64->2)
plt.scatter(new_data[:,0],new_data[:,1],
c=label,linewidth=1,edgecolor='black')
#데이터들이 군집을 이루고 있어서 학습이 가능하다
#Categorical Variable to Numeric Variable 범주형 변수와 숫자 변수
#범주형 데이터란 차의 등급을 나타내는 소,중,대와 같이 범주로 분류될 수 있는 변수를 의미
#주로 데이터 상에서 문자열로 표시, 문자와 숫자가 매핑되는 형태로 표현되기도 함
#컴퓨터가 데이터를 활용하여 모델화하고 학습하기 위해서는 데이터를 모두 수치화해야함
#수치화 방법 = Label Encoding, One-hot Encoding
#Label Encoding
#n개의 범주형 데이터를 0~n-1의 연속적인 수치 데이터로 표현
#간단한 방법이지만 문제를 단순화 시킬수 있음
#One-hot Encoding
#n개의 범주형 데이터를 n개의 비트 벡터로 표현
#너무 큰 데이터에 대해서는 쓸데없는 데이터가 너무 많아 지기 때문에 사용치 않는다
data = pd.read_csv('data/abalone.txt',header=None,
names=abalone_columns)
#전복 데이터
label = data['Sex']
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
label_encoded_label = le.fit_transform(label)
label_encoded_label.reshape(-1,1)
result = pd.DataFrame(data = np.concatenate([label.values.reshape((-1,1)), label_encoded_label.reshape((-1, 1))], axis=1),
columns=['label', 'label_encoded'])
#데이터를 판다스에 있는 데이터프레임으로 바꿔서 보기 좋게 바꾸는 것
#숫자로 표현된 데이터, 벡터 표로 표시된 데이터(구별이 훨씬 편하다)
#그래서 One-hot Encoding 사용
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)
#옵션을 false값으로 바꿔놓은 것 = 디폴트 값으로 출력하면 매트릭스가 됨, false로하면 배열이 됨
one_hot_encoded = ohe.fit_transform(label.values.reshape(-1,1))
print(one_hot_encoded)
-와인 데이터
from sklearn.datasets import load_wine
wine = load_wine()
print(wine.DESCR)
data = wine.data
label = wine.target
columns = wine.feature_names
-데이터 불러오기
data = pd.DataFrame(data,columns=columns)
data.head()
-판다스 데이터프레임화
data.shape
-데이터 모양확인
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data = scaler.fit_transform(data)
-데이터 학습
#차원 축소
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
data = pca.fit_transform(data)
data.shape
#데이터 확인 => 크기맞추기 => 차원낮추기
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(data)
cluster = kmeans.predict(data)
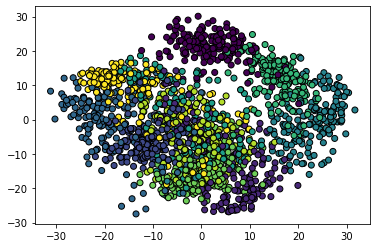
#와인데이터 -> 숫자의 편차가 커서 minmax로 스케일링, pca로 차원낮추고,
#kmeans 알고리즘으로 알고리즘을 합쳐 이 데이터가 3등분 할 수있게 학습
#kmeans는 라벨링이 없는 데이터 3그룹을 만든것
#새로운 데이터를 주면 데이터가 세 그룹 중 어느 곳에 속할지 판단
#예측한 결과가 cluster에 저장
#데이터 시각화
plt.scatter(data[:,0],data[:,1],
c=cluster,linewidth=1,edgecolor='black')
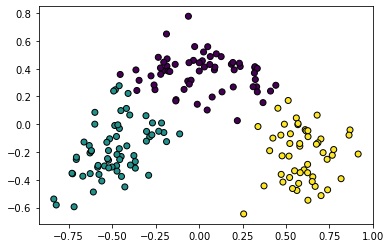
#Hierarchical Clustering
#거리와 유사도를 기반으로 클러스터를 형성
#각 데이터 포이튼 클러스터로 할당, 가까운 클러스터끼리 병합, 1개의 클러스터가 될때까지 반복
#토너먼트식으로 반복
#어떻게 가장 가까운 클러스터를 찾을까?
#single = 두 클러스터 내의 가장 가까운 점 사이 거리
#complete = 두 클러스터 내의 가장 먼 점 사이 거리
2. 학습내용 중 어려웠던 점
-강의 시간이 긴 것도 있지만 분량이 방대하다보니 소화하기가 쉽지 않다. 어떤 경우에 어떤걸 쓴다는 정도로만 알고 넘어가는 경우들이 많은 것 같다. 정말 쉽지 않다.
3. 해결방법
- 그날 봤던걸 한 번이라도 다시 꾸준히 해보는 것 말고는 방법이 없는 것 같다.
4. 학습소감
- 뭔가 지식들에 치여서 쌓아가기보단 떠밀려가는 느낌이다. 선생님이 말씀하신 것 중에 지난주보다 한 줄의 코드라도 더 이해했다면 실패한게 아니라는 말에 위안을 받는다. 좀 더 힘내자.
