1.학습한 내용
참조할 책 = 파이썬 라이브러리를 활용한 머신러닝
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
-기본 바탕 코드
pip install mglearn
import mglearn
-mglearn 인스톨 후 import
##책에서 데이터를 사용할 때만 사용하는 한정적인 패키지
#지도 학습 알고리즘
#업계의 관례 feature label(target)
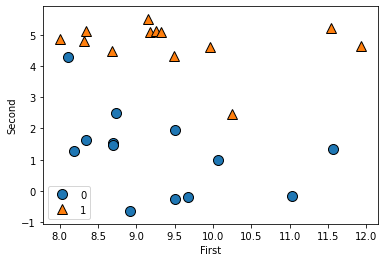
X, y = mglearn.datasets.make_forge()
mglearn.discrete_scatter(X[:,0],X[:,1],y)
plt.xlabel('First')
plt.ylabel('Second')
plt.legend()
print(X.shape)
#데이터 생성
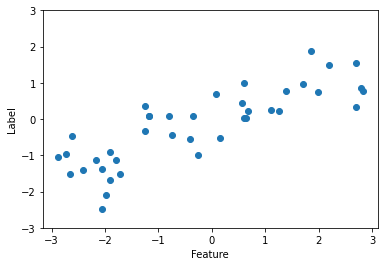
X, y = mglearn.datasets.make_wave(n_samples=40)
plt.plot(X,y,'o')
plt.ylim(-3,3)
plt.xlabel('Feature')
plt.ylabel('Label')
print(X.shape)
#분포를 표현하는 데이터를 만들 때 wave 사용, 샘플 개수 지정 가능
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print(cancer.keys())
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
#유방암 데이터
cancer.data.shape
(569, 30)
#데이터 모양 확인
#30가지의 요소에 의해서 유방암 데이터가 정의되고 있고 데이터는 569개가 쌓여있다
cancer.target
#양성(malignant), 음성(benign) 두 가지의 결과를 0과 1로 출력
cancer.target_names
cancer.feature_names
#음성과 양성, 그걸 결정짓는 30가지 요소의 이름을 알 수 있다
mglearn.plots.plot_knn_classification(n_neighbors=1)
#최근접 알고리즘, 이웃의 개수를 달리하면 결과가 달라진다
mglearn.plots.plot_knn_classification(n_neighbors=3)
#최근접 알고리즘은 속도가 빠르고 단순하지만 특정 데이터에선 정확하다.
#최근접 알고리즘은 가급적이면 짝수로는 설정하지 않는다(과반수 적용때문)

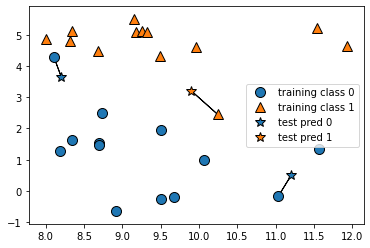
from sklearn.model_selection import train_test_split
X,y = mglearn.datasets.make_forge()
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)
#분류 테스트 = 데이터 쪼개기 train test split
#random state = 0을 주는 것은 결과를 서로 맞추기 위한 것(선생님과 우리)
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=5)
#분류할때는 classifier
#최근전 분류 알고리즘 세팅, 최근접의 개수에 따라 결과물이 달라진다
clf.fit(X_train,y_train)
#학습용 데이터 학습
clf.predict(X_test)
#테스트 예상 결과, y_test의 원본 데이터와 비교해서 정확도(Acc) 평가 가능
#원본 테스트 데이터 = y
clf.score(X_test,y_test)
0.8571428571428571
-테스트데이터 정확도
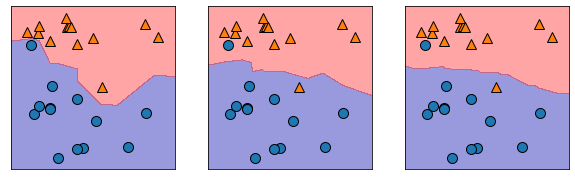
fig, axes = plt.subplots(1,3,figsize=(10,3))
for n_neighbors, ax in zip([1,3,9],axes):
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X,y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=0.4)
mglearn.discrete_scatter(X[:,0],X[:,1],y, ax=ax)
#최근접 개수 1,3,5에 따른 다른 결과 확인
#subplots로 한 라인에 다수의 그림 그리기 가능
#axes는 축, axis는 중심축
#zip은 두 가지를 결합해주는 도구
#축의 개수 변화에 따른 그림 변화를 알아볼 수 있다
#1개의 경우 데이터의 특성이 도드라지게 나타난다
#축이 늘어나면서 데이터의 속성이 완화된다
#학습에 사용된 데이터를 가지고 테스트를 하면 안된다 = 답을 알려주고 시험을 치는것과 같다
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
random_state=66)
#비슷한 작업을 해보자
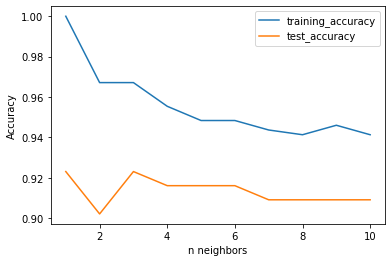
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1,11)
for n_neighbors in neighbors_settings:
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train,y_train)
training_accuracy.append(clf.score(X_train,y_train))
test_accuracy.append(clf.score(X_test,y_test))
#2개의 변수 ,1~11리스트, 리스트값 반복 후 저장,fit으로 학습
#학습정확도(훈련정확도)
#테스트 정확도(학습-모델-X테스트-y테스트와 비교) = 이 값이 잘나와야 한다
print(training_accuracy)
print(test_accuracy)
#학습정확도는 100%에서 점점 떨어진다
#테스트정확도는 떨어지다가 올라가다 떨어지는 점을 확인할 수 있다
#가장 최상의 개수를 몇개를 봐야하는가를 결정지을 수 있다
plt.plot(neighbors_setteings,training_accuracy,label='training_accuracy')
plt.plot(neighbors_setteings,test_accuracy,label='test_accuracy')
plt.legend()
plt.xlabel('n neighbors')
plt.ylabel('Accuracy')
#X축은 최근접 개수(반복수), Y축은 정확도
#최근접 개수가 많을수록 데이터정확도는 무뎌짐을 확인할 수 있다
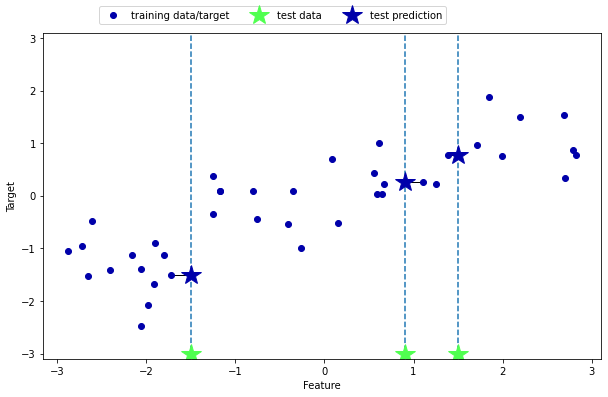
mglearn.plots.plot_knn_regression(n_neighbors=1)
#regression 사용, x축이 얼마일 때 y축은 얼마를 맞추는것
#키와 신발사이즈라고 했을 때 대충 키가 얼마일때 신발사이즈는 얼마라고 떄려잡는것
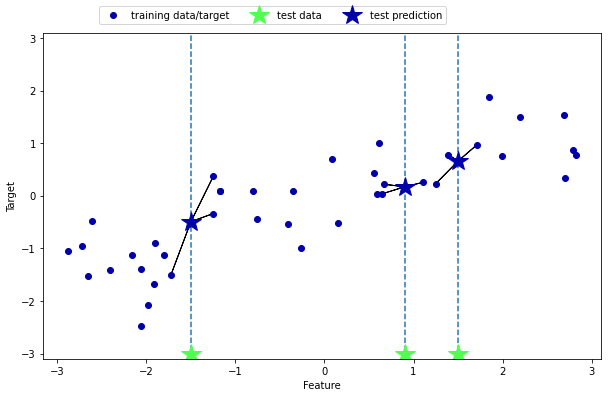
mglearn.plots.plot_knn_regression(n_neighbors=3)
#값이 늘어 갈 수록 데이터의 특성이 완화됨을 볼 수 있다
from sklearn.neighbors import KNeighborsRegressor
X, y = mglearn.datasets.make_wave(n_samples=40)
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)
reg = KNeighborsRegressor(n_neighbors=3)
reg.fit(X_train,y_train)
#테스트 데이터 형성 - 학습 - 예측
reg.predict(X_test)
#y test는 Xtest의 예측한 결과와 비교해 정확도를 분석하기 위해 predict에 사용하지 않는다
array([-0.05396539, 0.35686046, 1.13671923, -1.89415682, -1.13881398,
-1.63113382, 0.35686046, 0.91241374, -0.44680446, -1.13881398])
reg.score(X_test,y_test)
0.8344172446249605
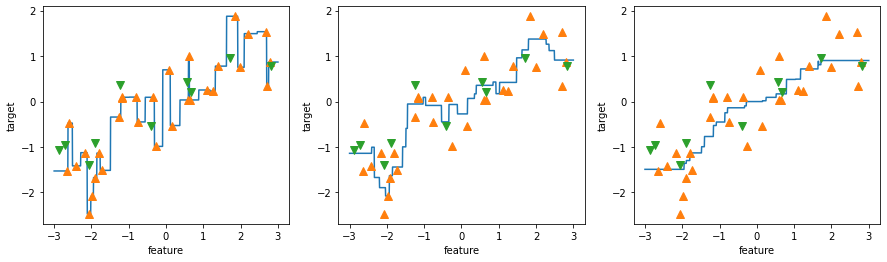
fig, axes = plt.subplots(1,3, figsize=(15,4))
line = np.linspace(-3, 3, 1000).reshape(-1, 1)
for n_neighbors, ax in zip([1,3,9], axes):
reg = KNeighborsRegressor(n_neighbors=n_neighbors)
reg.fit(X_train, y_train)
ax.plot(line, reg.predict(line))
ax.plot(X_train, y_train, '^', markersize=8)
ax.plot(X_test, y_test, 'v', markersize=8)
ax.set_xlabel('feature')
ax.set_ylabel('target')
#관례적으로 정해진 값들은 대문자, 변수들은 소문자로 사용한다
#실제로 일을 할 땐 Data가 계속 바뀐다 -> 모델의 정확도를 높이는게 목표 중 하나
선형회귀
#선형회귀는 데이터에 따라서 안맞을 확률이 크다
#고장난 시계도 하루에 두번은 맞는다
mglearn.plots.plot_linear_regression_wave()
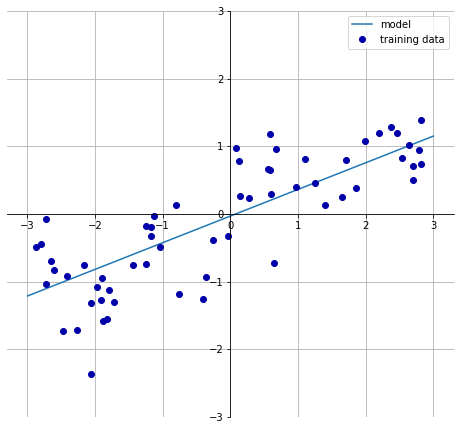
from sklearn.linear_model import LinearRegression
X, y = mglearn.datasets.make_wave(n_samples=60)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
lr = LinearRegression().fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
0.6700890315075756
0.65933685968637
print(lr.coef)
print(lr.intercept)
[0.39390555]
-0.031804343026759746
#coef = 기울기
#intercept = 절편 (내부적으로 정의된 것들은 _로 끝난다)(파이썬 관습)
#fit을 하면 모델 내부적으로 기울기, 절편값이 미리 정의가 된다
#보스턴 집값 데이터
#데이터 준비하는 작업들이 시간이 제일 많이 걸린다
#사이킥런에서 선택할 수 있는 알고리즘은 많지 않다
#정확도를 어떻게 높일지 고민하는데 시간이 든다
X, y = mglearn.datasets.load_extended_boston()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
lr = LinearRegression().fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
0.9520519609032728
0.607472195966587
#학습 정확도는 높으나 테스트 정확도에서는 확실히 떨어지는 모습을 보여준다
Ridge 릿지회귀
#제약을 걸어서 학습을 줄이는 것을 릿지라고 한다
#데이터가 너무 tight하게 붙어서 학습 = 오버피팅 문제
#데이터가 너무 boxy하게 학습 = 언더피팅 문제
#오버피팅과 언더피팅 사이에 최적화된 값을 찾아내는게 목표
from sklearn.linear_model import Ridge
ridge = Ridge().fit(X_train, y_train)
print(ridge.score(X_train, y_train))
print(ridge.score(X_test, y_test))
0.8857966585170941
0.7527683481744756
#학습정확도는 떨어지지만 테스트 정확도는 올라갔다(선형회귀에 비해)
ridge10 = Ridge(alpha=10).fit(X_train, y_train)
print(ridge10.score(X_train, y_train))
print(ridge10.score(X_test, y_test))
0.7882787115369616
0.6359411489177312
ridge01 = Ridge(alpha=0.1).fit(X_train, y_train)
print(ridge01.score(X_train, y_train))
print(ridge01.score(X_test, y_test))
0.9282273685001984
0.7722067936480149
#제약 값의 alpha
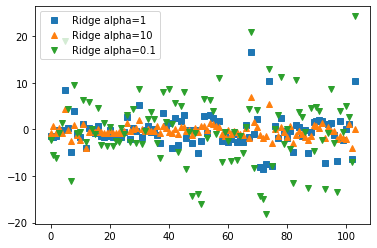
plt.plot(ridge.coef, 's', label='Ridge alpha=1')
plt.plot(ridge10.coef, '^', label='Ridge alpha=10')
plt.plot(ridge01.coef_, 'v', label='Ridge alpha=0.1')
plt.legend()
#alpha 값에 따라 데이터의 분산이 어떻게 다른가를 볼 수 있다
Lasso 라쏘회귀
from sklearn.linear_model import Lasso
lasso = Lasso().fit(X_train, y_train)
print(lasso.score(X_train, y_train))
print(lasso.score(X_test, y_test))
0.29323768991114596
0.20937503255272272
lasso001 = Lasso(alpha=0.01).fit(X_train, y_train)
print(lasso001.score(X_train, y_train))
print(lasso001.score(X_test, y_test))
0.8961122320864717
0.7677995670886714
lasso00001 = Lasso(alpha=0.0001).fit(X_train, y_train)
print(lasso00001.score(X_train, y_train))
print(lasso00001.score(X_test, y_test))
0.9420931515237063
0.6976541391663641
#제약을 더 줄였더니 학습정확도는 올라갔지만 테스트정확도는 감소했다
#학습용데이터에 최적화된 것
lasso0 = Lasso(alpha=0).fit(X_train, y_train)
print(lasso0.score(X_train, y_train))
print(lasso0.score(X_test, y_test))
0.9426383219008584
0.6916323869060212
#제약이 없을 때 => 테스트정확도가 떨어진다 => 선형회귀와 별반 다르지 않다
#분류에 대한 선형 모델
#평균선을 통해 분류가 가능하다
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
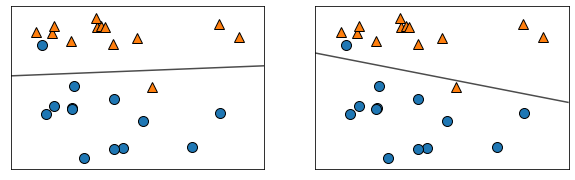
X, y = mglearn.datasets.make_forge()
fig, axes = plt.subplots(1,2, figsize=(10, 3))
for model, ax in zip([LinearSVC(), LogisticRegression()], axes):
clf = model.fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=False, eps=0.5,
alpha=0.7, ax=ax)
mglearn.discrete_scatter(X[:,0],X[:,1],y,ax=ax)
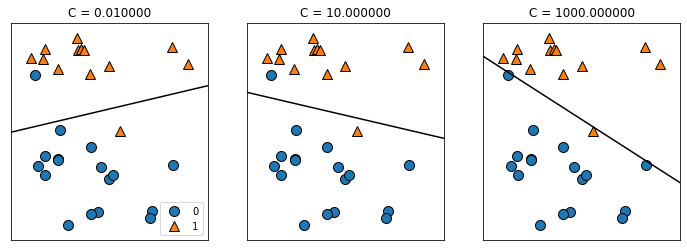
mglearn.plots.plot_linear_svc_regularization()
#정규화
#유방암 데이터 분류
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data,
cancer.target,
random_state=42)
logreg = LogisticRegression(max_iter=5000).fit(X_train, y_train)
print(logreg.score(X_train, y_train))
print(logreg.score(X_test, y_test))
0.960093896713615
0.965034965034965
#정확도를 찾아간다는 것은 오차를 줄여나간다는 것 = 최적의 값을 찾는 것
#그래프의 선이 내려가는 선인지 올라가는 선인지 파악해야한다
#=>경사하강법(최적점을 찾아야 하니까) = 수학에서의 미분
#최적의 포인트를 찾아내기 위한 알고리즘들은 deeplearning에서 많이 사용
#LogisticRegression의 기본값은 100
#최적의 알고리즘을 찾아내는 것을 자동화시키는것
#automated machine learning = AutoML
#신경망(Neural Network)
#인공지능 분야에서 쓰이는 알고리즘
#인간의 뇌구조를 모방, 신경세포 100억개
#인간의 뇌 = 뉴런과 뉴런 사이에는 전기신호를 통해 정보 전달
#여러개의 인공뉴런들이 모여 = 인공신경망
#뉴런들이 모인 단위를 층(layer), 여러층으로 구성될 수 있음
2. 학습내용 중 어려웠던 점
-선형회귀와 라쏘회귀 릿지회귀를 구별함에 있어서 직접 데이터를 시험해 봄으로 좀 더 이해하기가 편했던 것 같다. 모든 코드들이 아직 어떻게 동작하는지 다 이해는 하지 못하지만 조금씩은 알아가는 것 같아 좋은 것 같다.
3. 해결방법
-점차 내용들을 깊이 보게되는 것 같은데 코드와 작성된 결과들을 비교해보면서 다시 떠올려보는게 많이 도움이 되는 것 같다.
4. 학습소감
-날이 조금씩 더워지면서 졸리는 부분이 있는데 최대한 코드 설명해주시는 부분에 집중해 받아적으며 졸음을 쫓아봐야겠다.
