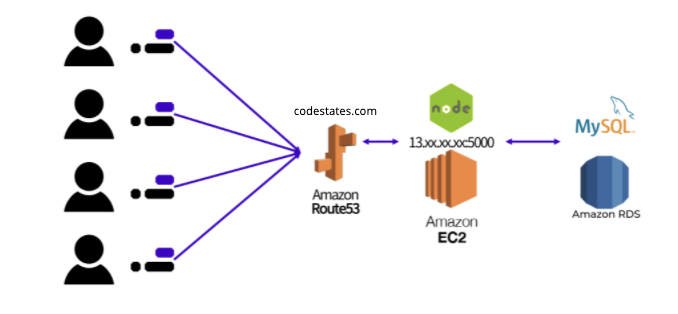
(이미지 출처: 코드스테이츠)
1. 배포(deployment)
1. 배포란?
배포란 개발용으로 사용하고 있는 내 컴퓨터 외 다른 컴퓨터에 개발 내용을 올리고 다른 사용자들이 원격으로 접속하여 서비스를 사용할 수 있도록 구동하는 것을 가리킨다.
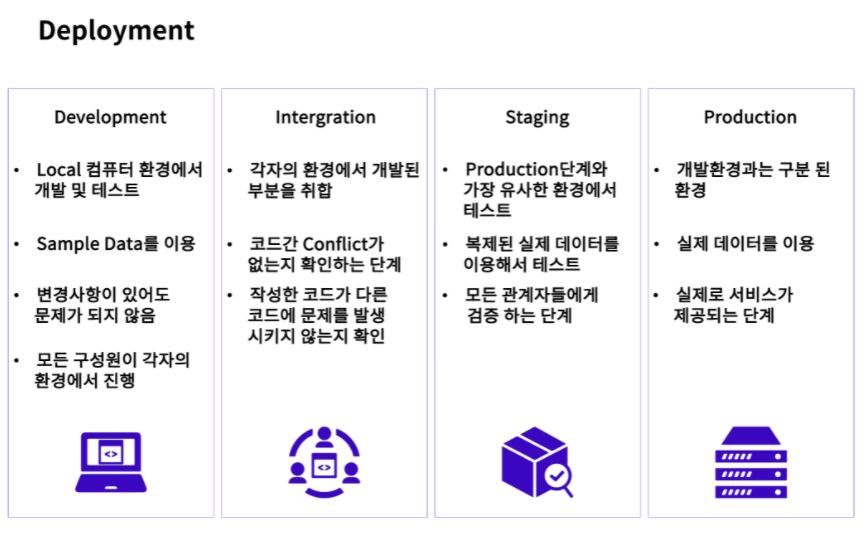
2. 배포 과정에 따른 개발 환경
개발(development) : 개발 서버에서 서비스를 개발한다.
통합(integration) : 기존 서비스나 개발 내역과 충돌이 없도록 개발 내용을 통합한다. 충돌이 발생하는 경우 1.개발 단계로 돌아가서 수정한다.
스테이지에 올리기(staging) : 사용자들에게 배포 직전 비슷한 환경을 구현하여 놓고 내부적으로 마지막 컨펌을 받는다.
운영(production) : 실제로 서비스가 운영되는 서버에 서비스가 올라간다.
(이미지 출처: 코드스테이츠)
3. 배포 과정 중 설정 사항
- 배포 과정 중 개발 서버와 배포 후 운영 서버 간 설정들이 상이할 수 있어 이 부분을 잘 챙겨야 한다.(배포에서는, development & production 환경의 차이를 이해하고 환경 설정을 코드와 분리하는 것이 중요하다)
- nodeJS 버전, 의존성, port 위치, hostname, 사용하고 있는 url, 파일 경로, API 키 등의 설정이 제대로 적용되어 있는지 확인한다.
특히 API Key나 pem 파일 등은 모두에게 공개되지 않도록 적절히 제외해야 한다. - 개발 서버에서의 경로와 운영 서버에서의 경로 관리를 위해 상대주소를 사용하거나 환경 변수를 사용하는 방법도 있다.
- npm이나 yarn을 통해 서비스 운영에 필요한 모듈들이 잘 설치될 수 있도록 의존성 설치 시 --save 옵션을 적극적으로 사용하고 pack.json의 의존성 부분을 잘 체크해야 한다.
4. 배포 플랫폼
다양한 배포 플랫폼이 있고, 이 중 하나를 선택하여 배포를 진행할 수 있다.
Heroku, Digital Ocean, AWS, Microsoft Azure, Firebase 등...
2. AWS
1. 클라이언트 배포
- SPA 즉, 클라이언트 사이드는 AWS의 S3 클라우드 서비스를 통해 제공 가능하다.
- S3란? Simple Storage Service, 파일을 저장하는 클라우드 서비스이다.
- s3는 파일을 저장해서 호스팅하는데 특화되어 있다.
- 파일을 저장하고 읽고 쓰고 할 수 있는 서비스로 이 기능을 수행하는데 - 다른 aws 블럭에 비해 비용 대비 가장 효율적이다. cf) EC2에서도 정적 파일을 읽고 쓸 수 있으나 S3보다 비용이 더 든다.
- 구축 과정
- aws에서 s3 서비스를 선택해 버킷을 생성(버킷 이름, 위치 지정)한다.
- 버킷에서 정적 웹사이트 호스팅이 가능하도록 설정을 변경한다.
- 실행 될 html 문서의 이름과 오류 발생 시 사용할 html 문서의 이름을 명시한다.(ex. index.html)
- 버킷의 권한을 public으로 변경한다. (사용자들의 서비스 접근이 가능하도록)
- 정책 생성기 도움을 받아 정책을 생성한다.
- 기존에 개발해두었던 클라이언트 폴더가 배포되면 api를 호출하는 부분이 EC2 ip와 port를 사용할 수 있도록 설정한다.
- npm run build 혹은 yarn build하여 정적 파일로 만든다. (react의 경우 build라는 명령어가 있어서 정적 파일이 만들어진다.)
- build한 정적 폴더 전부를 버킷에 업로드한다.
- 버킷의 엔드포인트를 클릭하여 S3에 업로드 된 파일을 확인한다.
2. 서버 배포
- 서버 사이드 배포를 위해서는 AWS의 EC2 클라우드 서비스를 통해 구현 가능하다.
- EC2란?
- 가상 환경의 컴퓨터
- 이 컴퓨터의 환경을 원하는 이미지(이미지: 컴퓨터를 사진처럼 똑같은 상태로 찍어낸 것)로 구동시켜서 사용할 수 있다.
- 컴퓨터를 대여하여 서버로 사용할 수 있게 제공하는 클라우드 서비스, EC2에 nodeJS 환경을 구축하고 운영서버를 가동할 수 있고 사용자들은 원격으로 접속하게 된다.
- 구축과정
- 기존에 개발했던 서버 폴더에서 배포 환경에 영향을 받는 변수를 파악해 배포 상황에 맞게 값이 설정될 수 있게 한다.
- AWS RDS를 데이터베이스로 쓸 수 있도록 config 정보에 production 모드를 준비하고 RDS host 주소와 RDS port를 지정해둔다.
- S3로부터 api 요청을 받으므로 S3 엔드포인트를 cors에서 허용한다.
- 서버 폴더를 깃헙 저장소에 올려둔다.
- EC2 인스턴스 시작을 눌러 os를 ubuntu로 선택하여 버전과 메모리 등을 선택한다.(Amazon Machine Image = AMI 선택)
- EC2에 접속이 가능하도록 spem 키페어를 받는다. 한 번 발급받은 키페어는 다시는 받을 수 없으므로 잘 저장해둔다.
선택한 서버의 이름을 지정한다. - '연결' 버튼을 눌러 설명문을 보고 pem 파일과 퍼블릭IP를 사용해서 인스턴스 연결을 한다. .ssh 폴더에 spem 파일을 옮겨 넣는다.
- chmod 400 pem키 이름을 터미널에 입력한다.
- 터미널에서 ssh -i ~/.ssh/<pem 이름> ubuntu@ <EC2 퍼블릭 ip> 구문으로 ubuntu 서버로 접속한다.
- 가상컴퓨터 내에서 nvm을 설치한 후 node, mysql 설치, sequelize cli와 pm2를 전역에 설치한다.
- 깃헙 저장소에 저장해두었던 서버 폴더를 git clone 받고 npm install을 한다.
- vim으로 .env 파일을 만들어서 환경 변수를 설정한다.
- 이제 환경변수를 production으로 지정하여 app.js를 실행시킨다.
- 다시 aws EC2로 돌아가서 보안 설정을 한다.
- EC2의 보안 그룹에서 inbound에서 ssh 기본 설정과 더불어 http 프로토콜을 위치와 무관하게 허용하도록 한다.
- 사용자 지정 TCP로 위치와 무관하게 접속하도록 하되 port는 서버가 사용하는 port로 지정한다.
- pm2의 사용: 터미널을 끌 때 EC2 서버가 같이 꺼지는 상황을 피하기 위해서 pm2라는 패키지를 사용한다. pm2 start app.js를 하면 서버를 계속 켜둔 상태와 같게 된다.
- 기존에 개발했던 서버 폴더에서 배포 환경에 영향을 받는 변수를 파악해 배포 상황에 맞게 값이 설정될 수 있게 한다.
3. 데이터베이스 연결
-
서버 사이드 중 DB를 운영 서버에 구현하기 위해서는 AWS의 RDS 서비스를 통해 구현한다.
-
RDS란? Relational Database Service, 관계 기반의 데이터 베이스를 제공하는 서비스로 sql setup이 되어 있는 DB를 장착한 최적화 된 컴퓨터를 대여하는 개념이다.
-
구축과정
- aws RDS에서 데이터베이스 생성을 누른다.
- 엔진은 mySql로 선택, mySql 버전 선택한다.
- DB 인스턴스 식별자 aws에서 해당 db를 식별하는 이름을 지정해준다.
- RDS에서 사용할 master name과 master password를 지정한다.
- 퍼블릭 엑세스 사용 가능성 설정을 정해준다 : 개발 초기에는 다양한 mySQL 클라이언트 프로그램으로 테스트를 하므로 허용을 해주고, 후반부에는 허용하지 않는 것으로 변경하는 것이 좋다.
- 데이터베이스 이름에 데이터베이스로 사용할 database 이름을 넣는다.
RDS에서 사용할 포트를 지정한다. 기본이 3306이므로 변경해서 지정하는 것이 좋다. - db 생성 버튼을 누르면 셋업이 진행된다. (다소 시간이 걸리는 과정)
- RDS 생성이 완료되면 클라이언트 터미널에서도 RDS의 mySQL에 접근할 수 있다.
- 터미널에서
mysql -u <RDS master name> --host <RDS endpoint> -P <RDS port> -p를 실행하고 비밀번호로<RDS master password>를 입력한다.
여기서 중요한 것...!
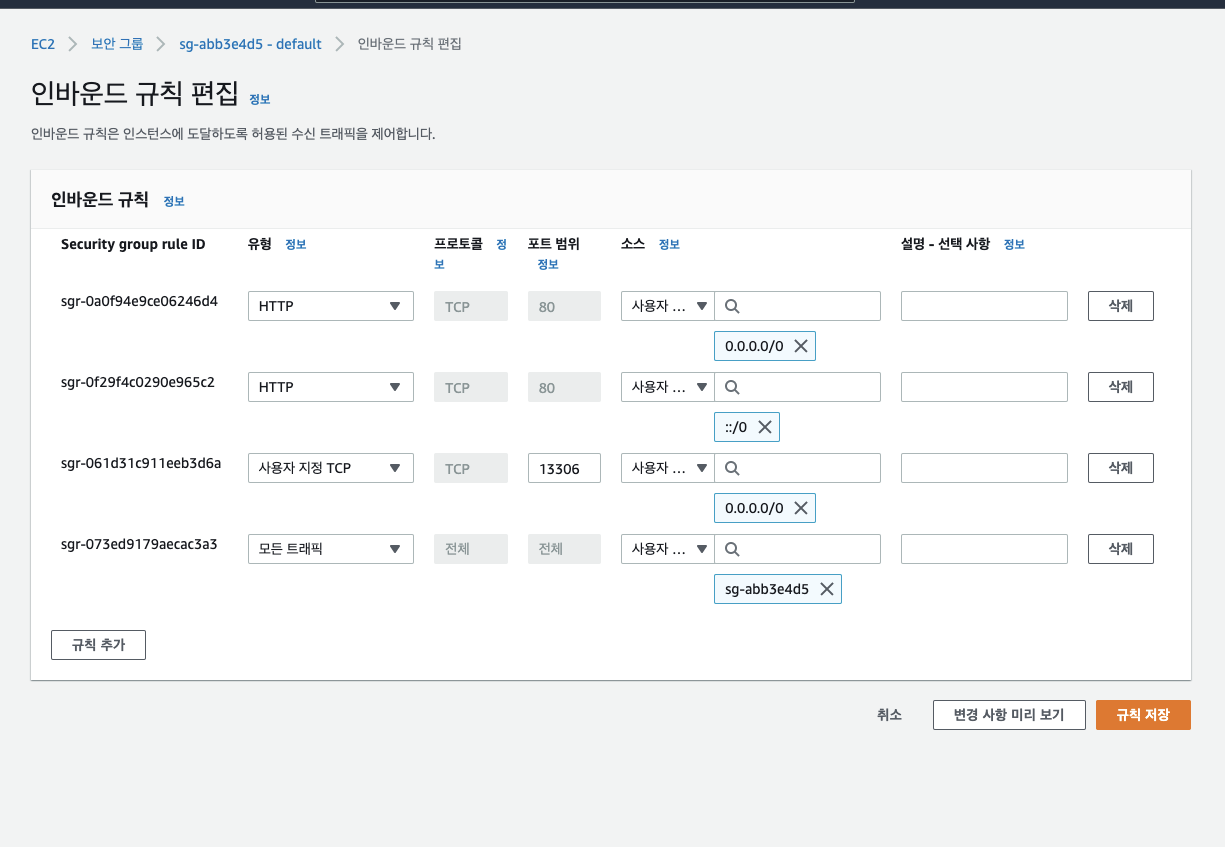
- EC2 서버에서 DB를 RDS로 쓰게 하기 위해서는 RDS 측 보안 설정을 해주어야 한다.
- RDS 보안 그룹 중 inbound 그룹을 선택하여 사용자 지정으로 RDS가 사용하는 port를 지정하고 사용자 지정 TCP로 모든 사용자의 요청을 받을 수 있도록 규칙을 수정한다.

우당탕탕 개발일기📝🤖