1주차 Introduction
What is Machine Learning?
과연 기계학습(Machine Learning)이란 무엇일까? 이에 대해 Arthur Samuel은 다음과 같이 말한다.
기계학습이란 컴퓨터가 명시적(explicit) 프로그램이 없어도 스스로 학습할 수 있는 능력을 연구하는 학문 분야이다.
Arthur Samuel, 1959
더 최근에 나온 Tom Mitchell의 정의를 살펴보자.
기계학습을 학습 과제(well-posed learning problem) 중심으로 정의하고 있다. 프로그램이 일정 수준의 작업 성능(P)을 가지고 작업(T)을 수행한다고 했을 때, 경험(E)이 증가함에 따라 작업(T)를 수행하는 성능(P)이 향상될 수 있다. 이 때 프로그램이 경험(E)으로부터 학습(learn)을 했다고 표현한다.
본 강의에서는 다양한 학습 알고리즘을 배울 예정이다. 학습 알고리즘도 여러 개가 있는데, 우리가 주로 배울 학습 알고리즘은 지도학습(Supervised Learning)과 비지도학습(Unsupervised Learning)이다.
지도학습(Supervised Learning)은 작업을 수행할 수 있는 방법을 컴퓨터에게 가르치는 것이 핵심이라면, 비지도학습(Unsupervised Learning)의 경우, 컴퓨터가 스스로 학습하도록 유도한다.
강화학습(Reinforcement Learning), 추천 시스템(Recommender Systems) 또한 기계학습 알고리즘이다. 그럼에도 불구하고 가장 많이 사용되는 알고리즘은 지도학습과 비지도학습이다(당시 강의 기준).
Supervised Learning
지도학습은 크게 회귀(regression)와 분류(Classification) 문제로 카테고라이징 될 수 있다. 또한, 알고리즘에게 데이터 집합을 제공할 때, 데이터에 정답(label)이 포함돼있는 것을 말한다.
Regression
We are trying to predict results within a continuous output, meaning that we are trying to map input variables to some continuous function.
Classification
We are instead trying to predict results in a discrete output. In other words, we are trying to map input variables into discrete categories.
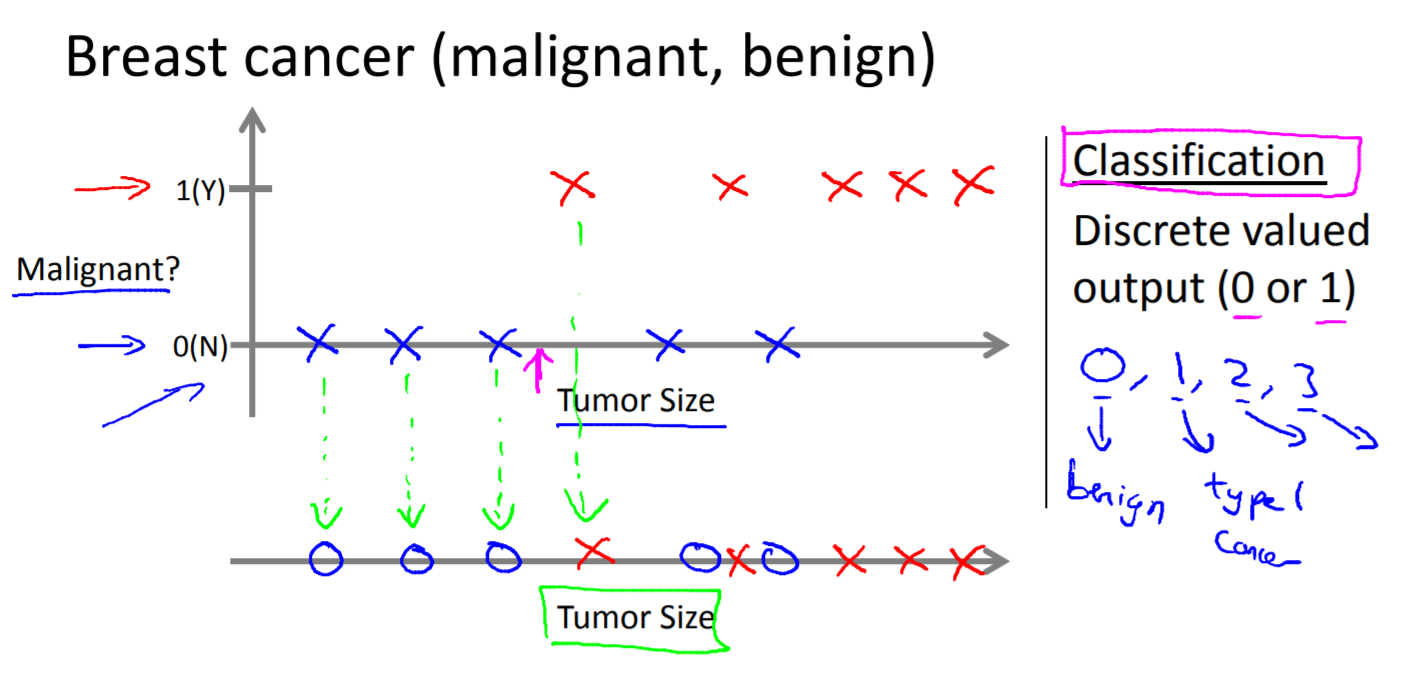
예를들어 의료기록을 보고 종양이 악성인지 양성인지 예측하고 싶다고 하자. 수집된 데이터 집합에서 가로 축에는 종양의 크기를, 그리고 세로 축에는 1 또는 0, 즉 yes 또는 no를 도식화 할 것이며, 해당 예시의 종양이 악성이면 1, 양성이면 0이다.
이것은 분류 문제(classification problem)의 예시이다. 분류라는 용어는 0 또는 1, 악성 또는 양성과 같이 불연속적인 결과값을 예측하려 한다는 것이다. 어떤 문제는 결과가 두 개보다 많을 수도 있다.
위의 예시에서는 하나의 특성(feature), 또는 속성(attribute)인 종양의 크기만 사용하여 분류를 진행하는데, 다른 문제에서는 한 개 이상의 특성이 주어지기도 한다.
그러면 특성이 무한대가 되는 경우에는 어떻게 할 것인가? 우리가 나중에 논의할 서포트 벡터 머신(Support Vector Machine)이라는 알고리즘에서의 깔끔한 수학적 방법을 사용하면 컴퓨터가 무한한 개수의 특성을 다룰 수 있게 된다.
Unsupervised Learning
비지도 학습(unsupervised learning)이라고 불리는 기계 학습 문제의 두번째 주요 유형에 대해 이야기 해보자.
 Supervised Learning 데이터 예시
Supervised Learning 데이터 예시
 Unsupervised Learning 데이터 예시
Unsupervised Learning 데이터 예시
비지도 학습에서는 데이터가 지도학습과는 다르게 주어진다. 어떤 레이블도 갖고 있지 않거나, 모두 같은 레이블을 갖고 있거나, 또는 아예 레이블이 없기도 한다. 그래서 우리에게 주어진 데이터 집합에 우리는 이것으로 무엇을 할지, 또 각 데이터가 무엇인지 알 수 없는 반면 "여기 데이터가 있는데, 여기서 어떤 구조를 찾을 수 있습니까?"라고 물을 뿐이다.
데이터 안에 있는 변수들간의 관계에서 클러스터링을 통해 구조를 얻어낸다고 생각하면 된다.
이러한 클러스터링의 활용 예시는 구글 뉴스, 데이터 센터, 은하계의 생성과 관련한 것들이 있다.
