Multiple Features
예전에는 feature를 하나만 사용해서 hypothesis 함수를 만들었는데, 과연 이게 많을때는 어떻게 해야할까?
이제는 n개의 feature이 있다고 가정하자.
간단하게 행렬의 식으로 표현할 수 있다.
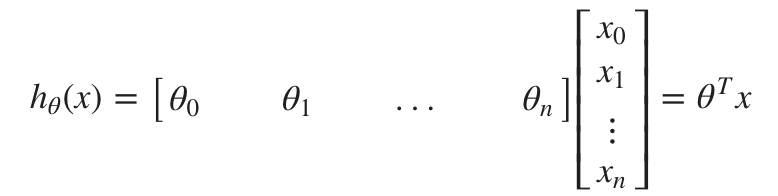
Gradient Descent for Multiple Variables
그렇다면 Multiple Variables에서 Gradient Descent는 어떻게 이루어지면 되는 것일까?
이 또한 변수만 많아진 것이고, 이전과는 크게 달라지는 것은 없다.
그냥 n이 1에서 더 늘어난 것이라 생각하면 된다.
즉 에도 n이 1일때처럼 적용해나가면 된다.
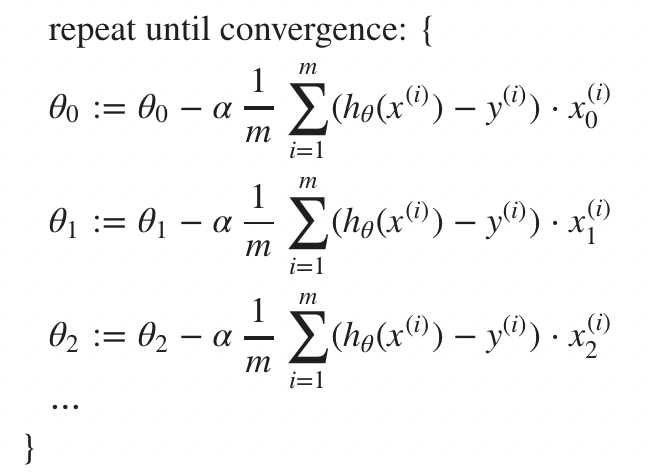
Gradient descent in Practce
Feature Scaling
여러개의 feature가 비슷한 scale이면 gradient descent가 좀 더 빠르게 수렴할 수 있다.
즉, Scaling 과정을 통해 feature들이 일정한 범위 및 비슷한 범위로 만들면 더욱 효과적으로 gradient descent를 수행할 수 있다.
Get every feature into approximately a -1 ~ 1 range.
꼭 위와같은 범위를 가져야하는 것은 아니고, 어느정도 근사하면 된다.
이와 관련된 범위에 대한 규칙은 사람마다 다르다. Andrew Ng 교수님은 -3 to 3이면 괜찮다고 생각.
이외에도 mean normalization 방법을 쓸 수도 있음. 이는 다음과 같음.

Learning Rate
Debugging
Gradient descent가 수렴하는데 필요한 반복 횟수는 정말 다양하다. 어떤 경우에는 30번만에 수렴할 수 있고, 어떤 경우에는 3000번 반복할 수도 있다. 또 300만 번 반복하는 경우도 있다.
보통은 cost function을 보면서 수렴 유무를 판단한다.
이를 자동으로 해주는 automatic convergence test도 있다.
learning rate alpha
learning rate 는 너무 작으면 천천히 수렴하게 되고, 너무 크면 수렴하지 않을 수가 있다.
이를 해결하기 위해서 교수님의 꿀팁은 3배씩 해가면서 learning rate를 찾아나가는 걸 제안하셨다.
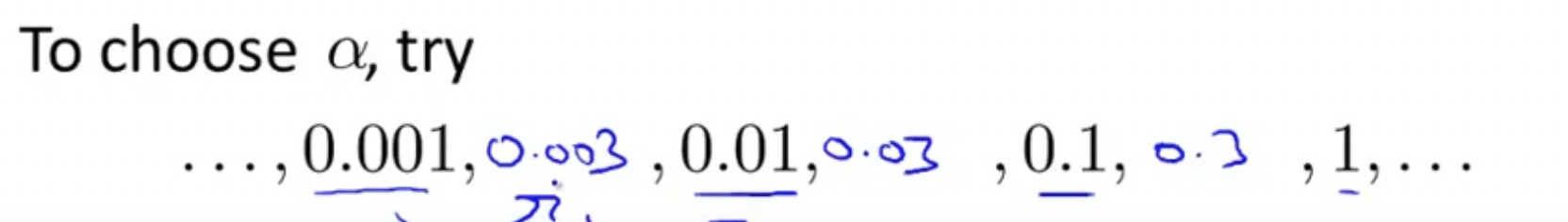
Features and Polynomial Regression
문제를 어떻게 이해하느냐에 따라 때로는 새로운 feature로 표현할 수 있게 된다.
원래 가지고 있던 feature들을 활용하여 3차 함수를 만들기도 하고, 루트를 씌워서 가공해서 만들 수도 있다.
즉 수학의 중요성을 느낀다.
