앤드류 응(Andrew Ng) 교수님의 머신러닝 강좌 (3주차 Solving the Problem of Overfitting)
The Problem of Overfitting
 좌측부터 underfit, just right, overfit 그래프를 나타낸다.
좌측부터 underfit, just right, overfit 그래프를 나타낸다.
Underfitting(High bias)은 가설 함수가 데이터의 트렌드를 따라가지 못하는 것을 의미하고, Overfitting(High Variance)은 가설함수가 훈련데이터는 정확히 예측하지만, 새로운 데이터에 대해서 예측을 하지 못하는 문제를 의미한다.
이러한 용어들은 linear regression과 logistic regression 모두에게 적용이 되고, 이러한 Overfitting Problem을 해결하기 위해서는 2가지 Option이 존재한다.
Addressing overfitting
- Reduce number of features
1) 직접 feature를 관리한다.
2) model selection algorithm을 사용한다. - Regularization
1) 모든 feature를 그대로 두지만, 의 magnitude를 관리한다.
2) Regularization works well when we have a lot of slightly useful features.
Cost Function
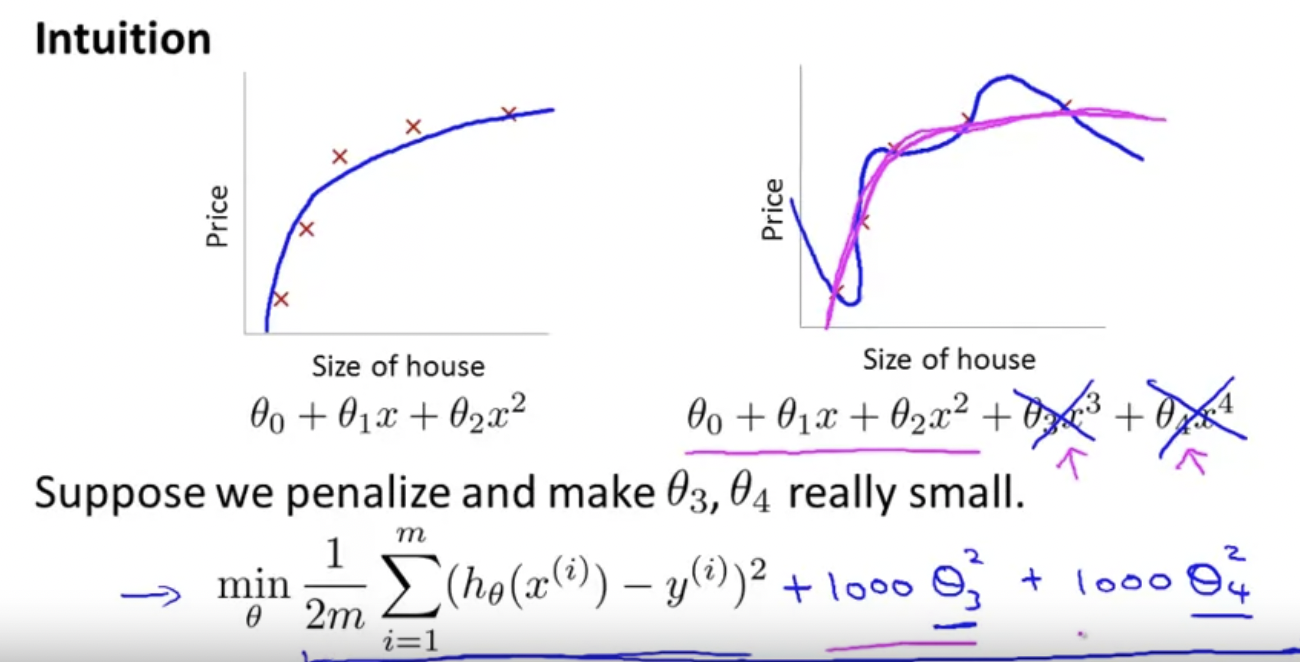
위에서 보는 것과 같이 Feature 갯수가 많아질수록(표현이 부정확하다) Overfitting 하는 것을 볼 수 있다. 이를 해결하기 위해 몇개의 를 penalize하여 미치는 영향을 작게 하는 것이 필요하다.
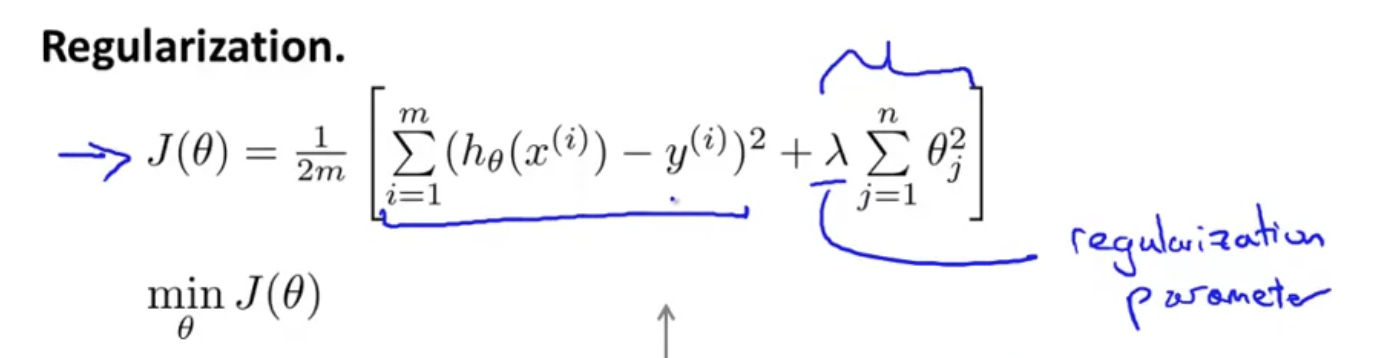
이를 구현하기 위해 regularization parameter (lambda)를 이용하여 Cost function을 정의한다. 이를 활용하여 학습을 시키면 Overfitting Problem을 해결할 수 있다. 하지만 가 너무 크게되면 가 underfit하는 문제가 발생할 수 있다. 따라서 적절한 값의 를 사용하는 것 또한 중요하다.
Regularized Lineal Regression
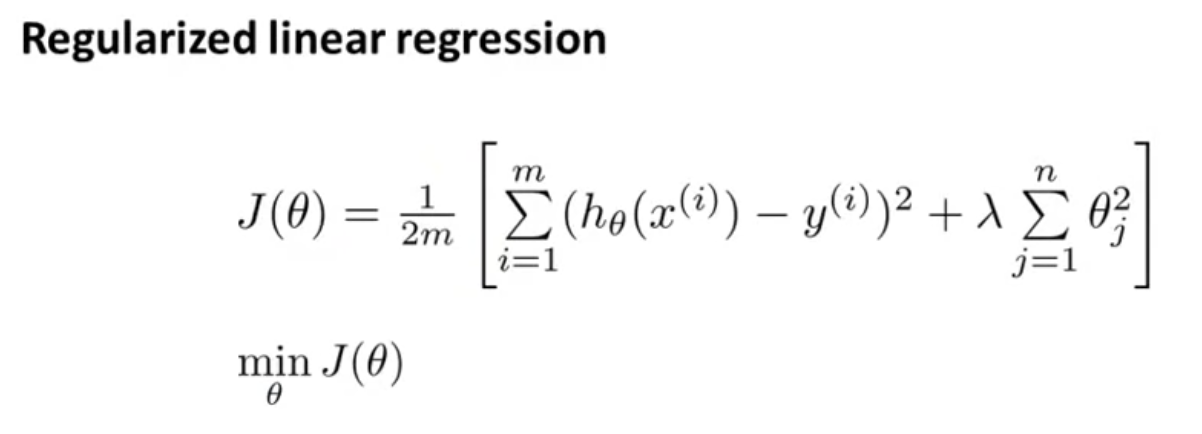
이전에 얻어진 Cost Function을 활용하여 최소화 하는 값을 찾으면 된다.
2가지 방법인 Gradient descent와 Normal equation이 있다.
Gradient Descent
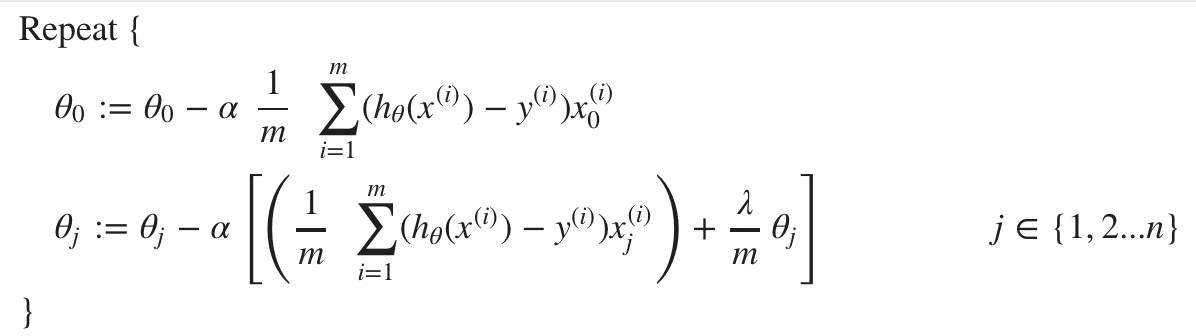
Normal Equation
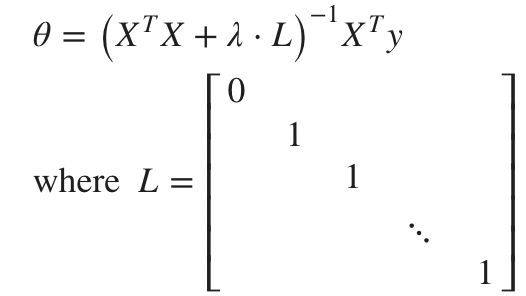
Regularized Logistic Regression
Logistic Regression 또한 Overfitting 문제를 가지게 되며, 이를 해결하기 위해 Regularization Parameter를 이용하여 해결할 수 있다.

즉, 이로인해 얻어지는 Cost Function은 다음과 같다.
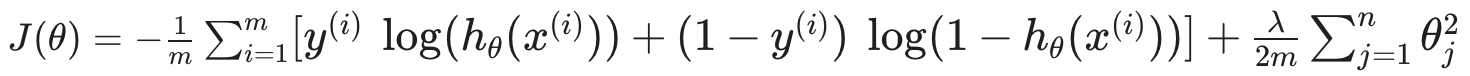
이후 Linear Regression과 동일하게 Gradient Descent 등과 같은 최적화 알고리즘을 통하여 를 찾아내면 된다.
Gradient Descent

예전에도 언급한 것처럼 얼핏 보면 Linear Regression과 다를것이 없어 보이지만, 자체가 Sigmoid 함수로 이루어져 있어 다르다는 것을 알아두어야 한다.
