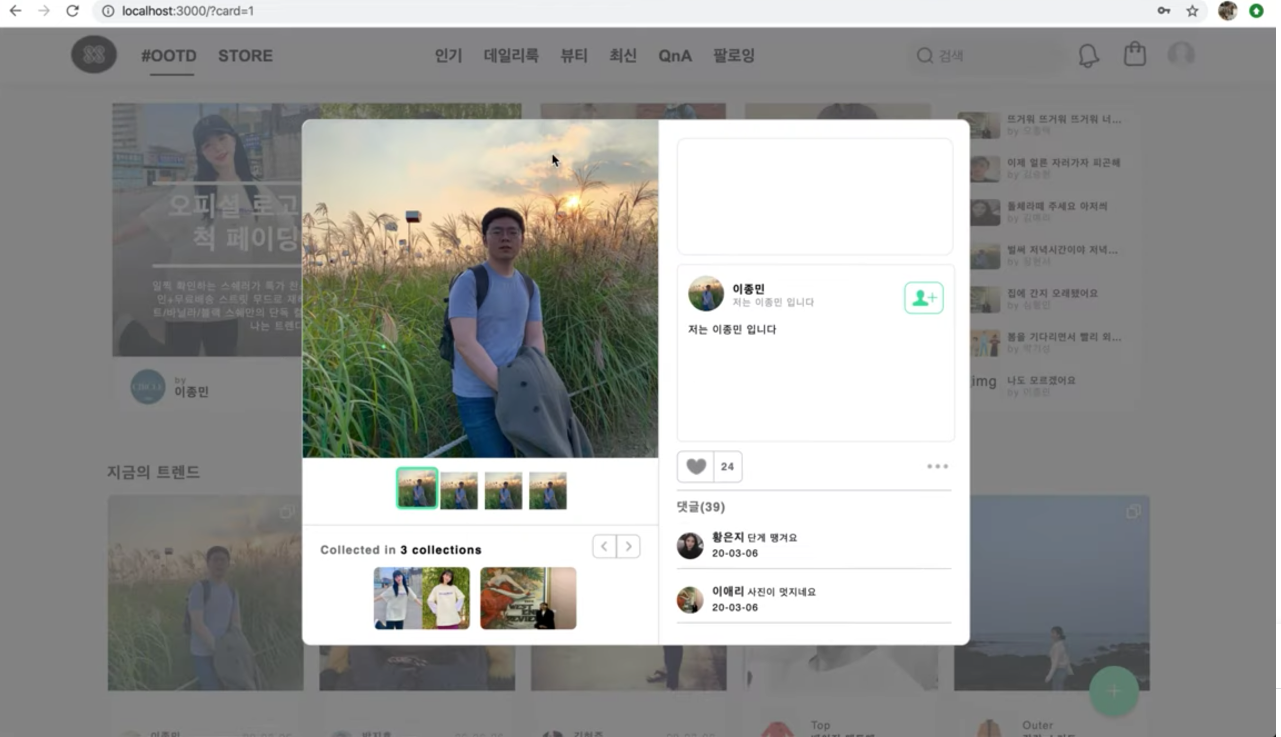
현재 개발을 공부하고 있는 위코드에서 1차 프로젝트를 진행했습니다. 위코드를 시작한지 27일차부터 39일차까지 약 2주 간 스타일쉐어 클론을 진행했는데요, 저는 당연하게도 백엔드 부분을 맡아서 진행했습니다.
Wetyle Share 프로젝트_Back-End
이번 프로젝트는 10대 ~ 20대 여성을 주요 고객으로 가진 SNS & 커머스 서비스인 스타일쉐어를 클론하는 프로젝트였습니다. 처음 하고 싶은 프로젝트를 생각해보는 단계에서 주변 개발자분들에게 문의를 해봤는데, 백엔드 개발자가 되는데 커머스와 SNS를 경험해보는게 좋다고 하더군요. 그래서 제가 아는 서비스 중 이 두 가지를 모두 충족하는 스타일쉐어를 프로젝트 아이디어로 제시하게 되었고, 다행히 선정되어 팀장으로 프로젝트를 진행할 수 있었습니다.
개발 인원은 프론트엔드 개발자 4명, 저를 포함한 백엔드 개발자 2명이었고, 약 2주간 개발을 진행했습니다. 개발 깃허브는 아래에서 확인하실 수 있습니다.
데모 영상은 아래에서 확인하실 수 있습니다.
적용 기술은 아래와 같습니다. 세부 기능 구현은 위의 깃허브에서 확인해보세요! ERD와 API 문서도 확인하실 수 있습니다.
- Python, Django web framework
- Beautifulsoup, Selenium
- Bcrypt
- JWT
- KAKAO social login
- MySQL
- AWS EC2, RDS, S3
- CORS headers
프로젝트에서 맡은 역할
팀에서는 팀장으로서 Scrum 방식으로 프로젝트를 진행하고, 백엔드로서는 대부분의 기능 구현에 참여했습니다.
- Store 브랜드, 상품정보 크롤링(OOTD는 개인정보 이슈가 있어서 크롤링하지 않음)
- 프로젝트 초기 세팅
- 기본 회원가입 / 로그인 모델, 뷰 작성
- 카카오 소셜 로그인
- 데이터 모델링
- 상품을 제외한 모든 모델 작성
- 상품 상세, 로그인 실시간 체크를 제외한 모든 뷰 작성
- Mysql DB 구축 및 데이터 업로더 제작
- AWS EC2 서버 배포
- AWS RDS 구축
- AWS S3 구축 및 이미지 업로더 연결
잘한점
- 데이터 모델링을 프로젝트 초기에 잘 잡아놔서 이후 모델 작성이나 뷰 작성에서 문법적인 문제 말고는 별다른 이슈가 없었음
- 크롤링을 어느정도 선에서 멈춘 것. 프로젝트 자체가 모든 데이터를 그대로 보여주기 위함이 아니라 기능을 구현할 수 있다는 걸 보여주기 위함이므로 특정 카테고리만 크롤링하고 나머지는 진행하지 않았음
- PostMan으로 API 문서를 작성하면서 진행해서 프론트엔드 개발자들과 소통하는데 편리했음
아쉬운점
- 기간 상의 문제로 모든 기능을 구현해보지 못하고 취사선택을 해야했음
- 성능에 대한 부분은 크게 생각하지 못했음. 일단 기능을 구현하는데 신경을 썼고, 실제 쿼리가 돌아가는 속도에 대해서는 select_related, prefetch_related를 고려하는데 그쳤음
- 여러 기능을 작성해보고 싶어서 한 기능에 대해 깊이 들여다보지는 못했음
해결/개선 방법
- 쿼리 속도를 테스트하는 방식을 미리 숙지하고 각 코드를 완성한 후 코드의 효율성에 대해 고려해보겠음
- 프론트와 원하는 기능에 대한 협의를 하고, 정말 제대로 파보고 싶은 기능은 제대로 만들어보겠음
기록하고 싶은 코드/함수/로직
1) 스타일 뷰
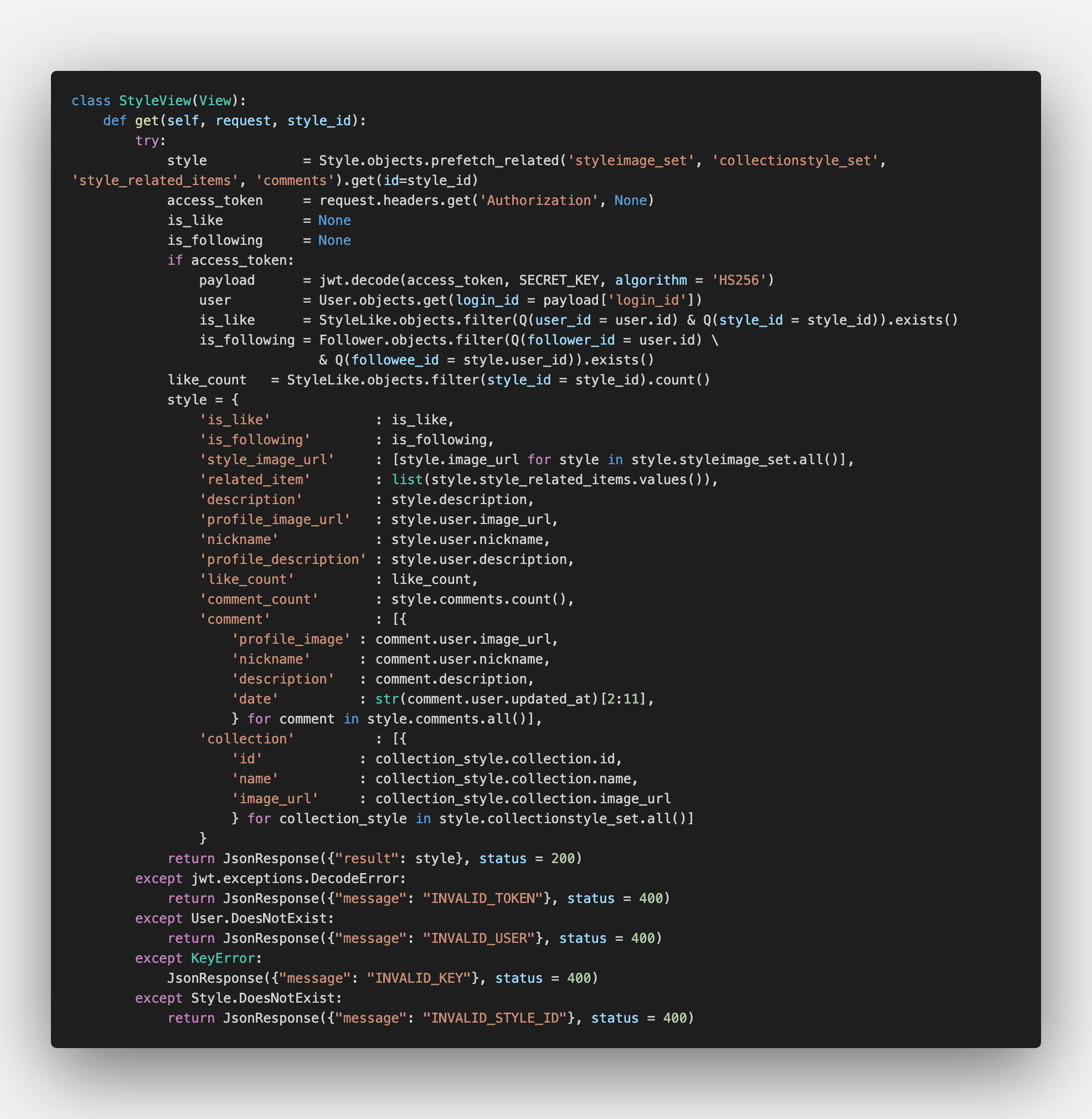
가장 공수가 많이 들어갔던 코드가 이 스타일 뷰 였습니다. SNS의 메인 요소이기도 했고, 스타일을 참조하고 있는 여러요소들과의 관계를 생각해서 효율적인 코드를 작성하는게 중요했습니다.
스타일을 참조하고 있는 이미지 URL 리스트, 연관 아이템, 댓글, 컬렉션_스타일들을 처음에는 각각의 테이블에서 시작해 현재의 스타일 아이디를 이용해서 원하는 정보를 가져오는 방식으로 짰었습니다. 하지만 이런 방식으로는 각 정보를 가져올 때마다 새로운 쿼리를 불러와야하고, 말이 관계형 관계지, 효율성은 따지지 못한 관계였습니다.
스타일과 관련된 모든 정보를 스타일 객체를 시작으로 불러올 수 있다는 걸 새삼 깨닫게 되고, 이점을 이용해 코드를 작성했습니다. 특정 스타일 객체를 불러올 때 연관된 테이블 데이터들을 prefetch_related로 캐싱해두고, 각각의 데이터를 불러올 때 사용했습니다.
이렇게 하니 코드도 훨씬 간결하면서 가독성이 좋아지고, 효율성면에서도 좋아졌다고 생각합니다. 앞에서 말했듯이 직접 속도를 측정하면서 하지는 않아서 기회가 되면 실질적인 차이를 비교해봐야겠습니다.
그리고 프로젝트 막바지에 is_like와 is_following이라는 정보를 추가해서 프론트에 제공했는데, 이 정보가 없으면 뷰 자체에서는 현재 유저가 좋아요를 하고 있는지, 팔로우를 하고 있는지 체크는 되지만 정작 프론트에서는 현재 상태에 대한 정보를 알 수 없다는걸 깨달았습니다. DB에서 True, False만 파악하면 되는게 아니라 실제로 프론트에 영향을 미칠 수 있는 정보까지 제공해야한다는 점을 여기서 깨달아서 좋았습니다.
2) 팔로잉 카드 뷰
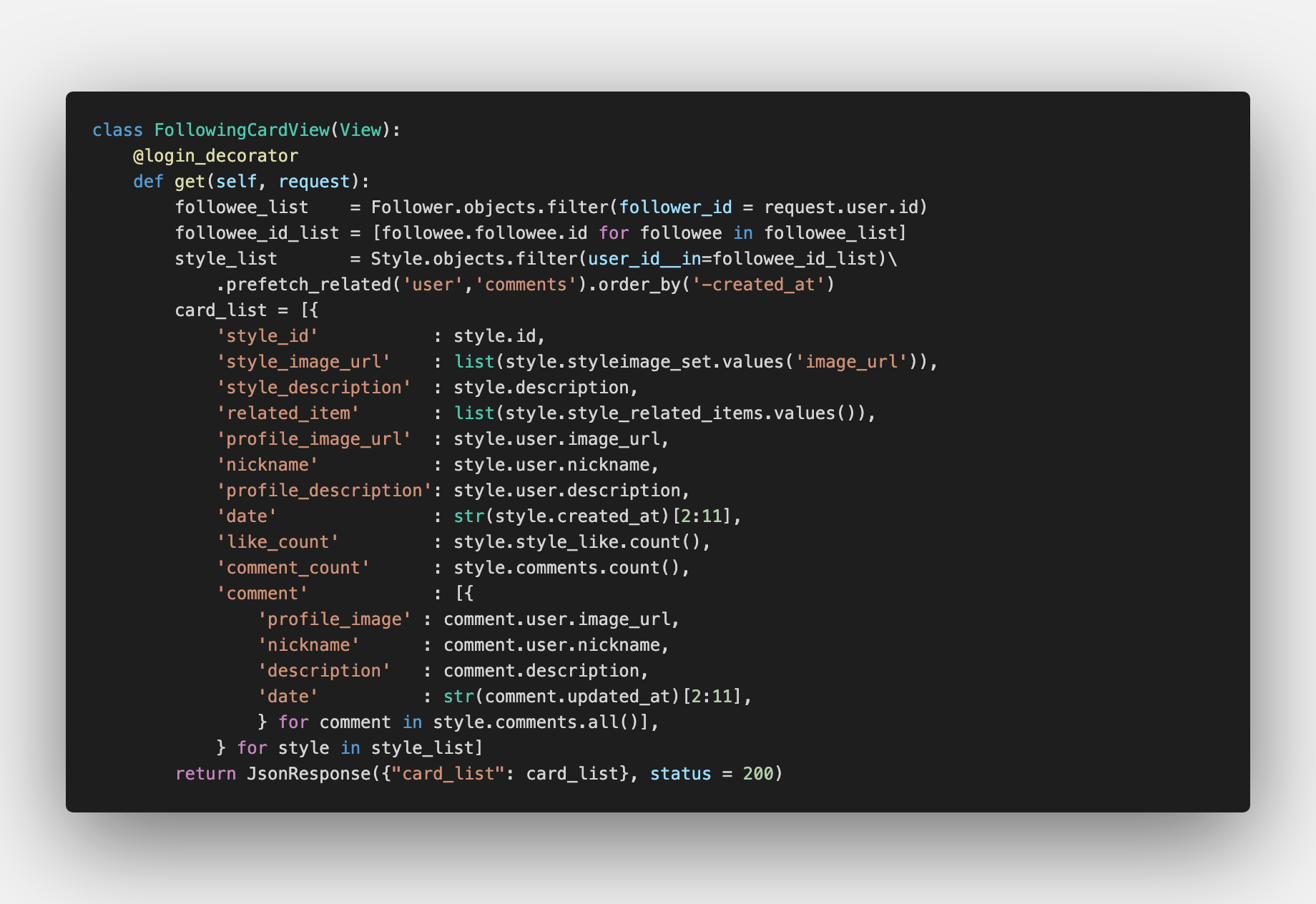
팔로잉 카드 뷰는 현재 내가 팔로우하고 있는 사람들의 게시물을 최근 순으로 뿌려주는 뷰 입니다. 여기서 만났던 문제점은 팔로우하고 있는 사람들의 리스트는 뽑을 수 있겠는데, 이 사람들이 올린 스타일 카드를 각각 필터링해서 정렬하는 방법을 알지 못했습니다. for 문을 돌려서 각자의 카드 리스트는 뽑아도, 이건 이미 객체로 변환된 다음이라 이 결과물들을 최신순으로 정렬하지 못했습니다.
이런저런 방법을 다 써보다가 어렴풋이 리스트를 기준으로 필터를 할 수 있는 방법이 있지 않을까 하고 찾아봤더니 방법이 있었습니다. 찾고 나서 기쁘기도 했지만 좀 허무하기도...
아직 장고의 모든 기능을 알지 못하다보니 이런 부분에서 막히는 부분이 있는 것 같습니다. 시간이 되는 한에서 문서를 좀 더 읽어보면 이후 프로젝트에서도 도움이 되겠죠!
3) 인기 카드 뷰
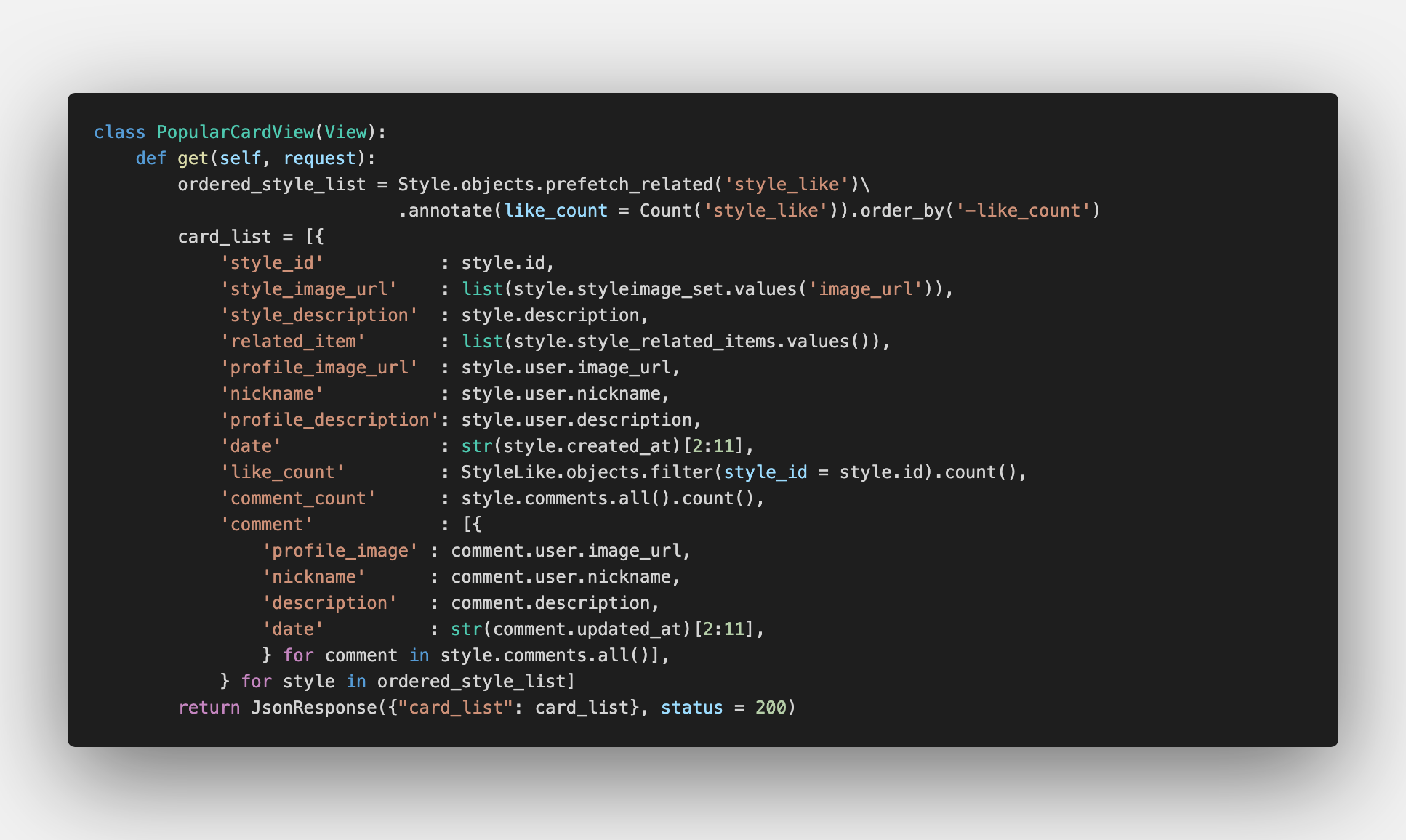
여기서 배웠던 부분은 annotate 기능 입니다. 원하는 변수를 주석처럼 ORM 안에서 처리하고, 이 변수를 이후 처리 과정에서 활용할 수 있다는 점이 신선했습니다. ORM을 만든 당신은 천재...
4) 유저 - 팔로워 모델
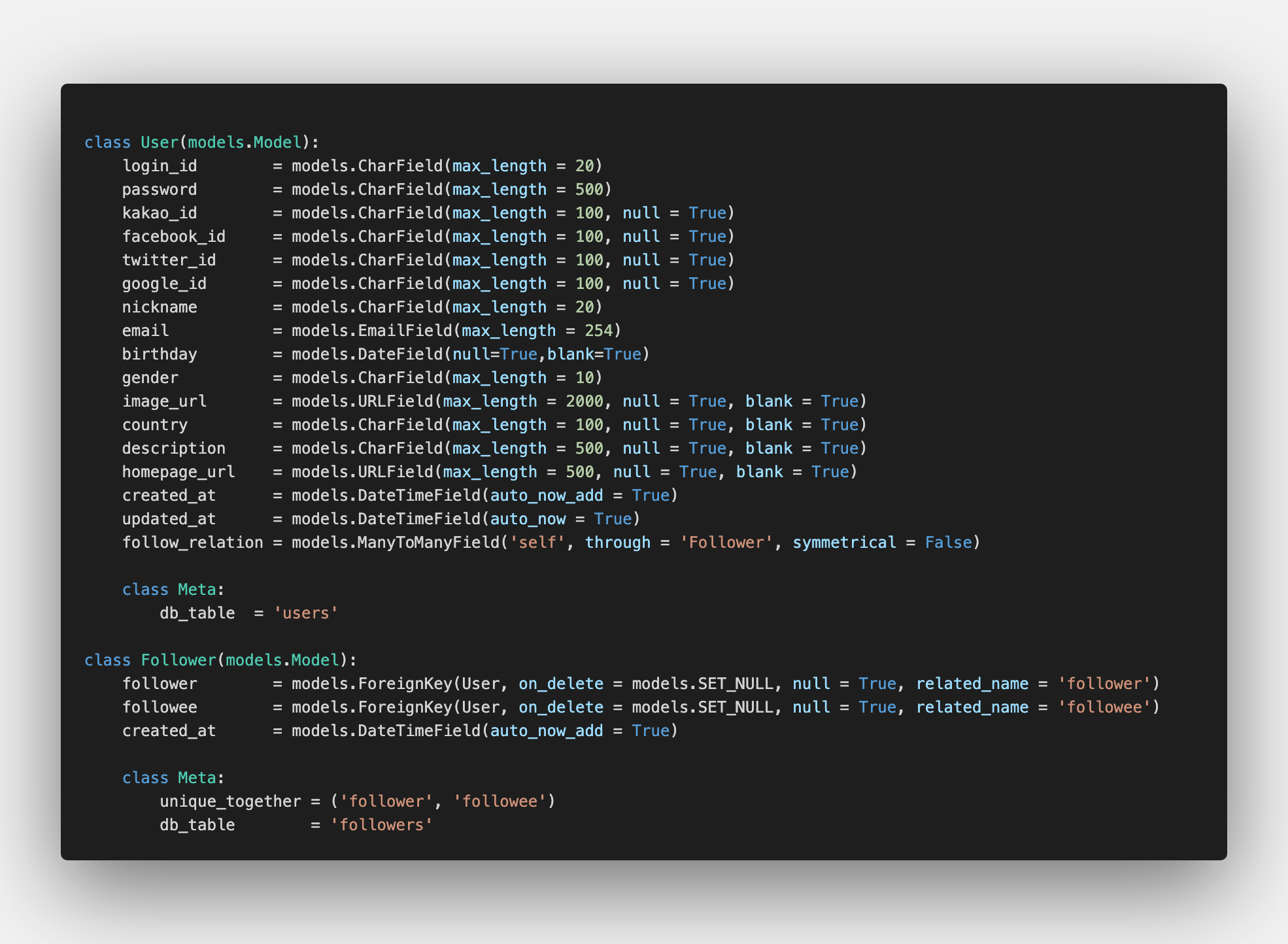
데이터 모델링 자체도 처음이었지만, 같은 모델을 두 번 참조하는 팔로워 모델은 더 새로웠습니다. 개념자체는 데이터 모델링을 하면서 깨달았지만 Syntax 적으로 어떻게 표현할지에 대한 부분이 이슈였습니다. 다행히 동기분에게 힌트를 얻어서 위와 같은 코드를 작성하 수 있었습니다.
자기 자신을 참조하고, 대칭 여부를 표현하고, 두 필드를 유니크 상태로 두어서 팔로워 관계를 표현할 수 있었습니다. 요긴하게 많이 쓰일 모델이겠죠?
이제 2차 프로젝트를 진행해야겠습니다. 2차 프로젝트는 다방 클론 입니다.
