위코드에서의 2차이자 마지막 프로젝트인 다내방 프로젝트가 끝났습니다. 1차에 이어 약 2주간 진행된 프로젝트에서도 백엔드 부분을 맡아서 진행했습니다.
DaNaeBang 프로젝트_Back-End
이번 프로젝트는 부동산 정보서비스인 다방을 클론하는 프로젝트였습니다. 위코드에서 진행된 나머지 2차 프로젝트들 중에서 유일하게 다방 프로젝트에 투표를 했어서 그런지 다방팀으로 배정 받아 프로젝트를 진행했습니다.
이 프로젝트의 목적은 복잡한 데이터구조를 가진 다방을 클론함으로써 모델링 구조에 대해 더 이해하고, 또 필터링과 위치정보 기반 기능 등의 핵심 기능을 다룰 수 있는 역량을 키우자였습니다.
개발 인원은 프론트엔드 개발자 3명과 저를 포함한 백엔드 개발자 3명이었고, 약 2주간 개발을 진행했습니다. 개발 깃허브는 아래에서 확인하실 수 있습니다.
데모 영상(유튜브 링크)
적용 기술은 아래와 같습니다. 세부 기능 구현은 위의 깃허브에서 확인해보세요! ERD와 API 문서도 확인하실 수 있습니다.
- Python, Django web framework
- Bcrypt
- JWT
- KAKAO / FACEBOOK social login
- MySQL
- AWS EC2, RDS
- Docker
- CORS headers
프로젝트에서 맡은 역할
백엔드 파트를 리드하는 역할을 하였고, 유저를 제외한 대부분의 기능 구현에 참여했습니다.
- 데이터 모델링
- 데이터 크롤링 / DB 업로더 작성
- 방 / 단지 전체 모델 작성
- 위치정보 기반 주변 시설 정보 필터링
- 매물 종류, 가격 등에 따른 방 매물 정보 필터링
- 지도 줌(zoom)에 따른 방 검색 반경 조절
- 단지 상세 뷰
- AWS EC2, RDS, Docker 배포
- 개발기능에 대한 유닛테스트
기록하고 싶은 코드/함수/로직
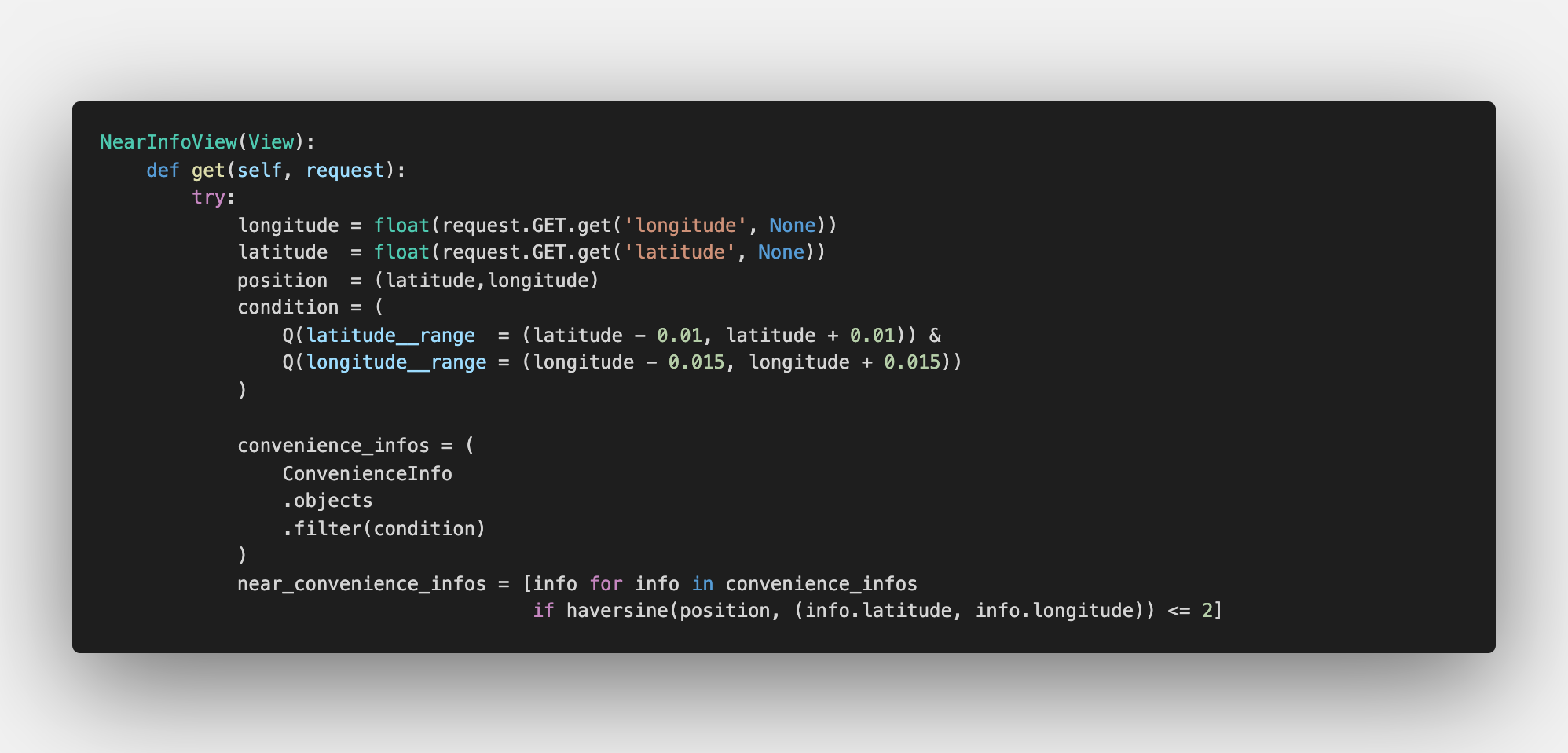
1) 근처 정보 뷰
근처 정보 뷰는 특정 위치를 위도와 경도로 찍었을 때, 설정한 반경 내의 주변 시설 정보를 불러와주는 역할을 합니다. 그런데 이 특정 위치는 위도와 경도에 따라 달라지기 때문에 주변 시설과의 거리를 미리 계산을 해둘 수가 없습니다. 그래서 반경 내의 시설을 필터링하려면 저장된 모든 시설들의 정보를 돌면서 거리 계산을 해줘야하는데요, 이때 비효율적인 쿼리가 돌아갑니다.
그래서 미리 거리를 계산 해놓은 것과 동일한 효과를 가져오는 방법을 생각해봤는데, 가져오려는 반경과 비슷한 범위의 시설들을 사전에 필터링 해놓고, 이 시설들에서만 돌면서 원하는 필터링을 적용하면 시간이 빨라질거라 생각했습니다.
이러한 생각으로 반경 2km의 시설을 찾아야한다고 하면, 특정 위치를 기준으로 상하좌우 +-1km 범위의 위도, 경도를 계산해서 필터링한 리스트를 미리 뽑아뒀습니다.
이렇게 하니 속도가 만족할만한 수준으로 빨라졌습니다.
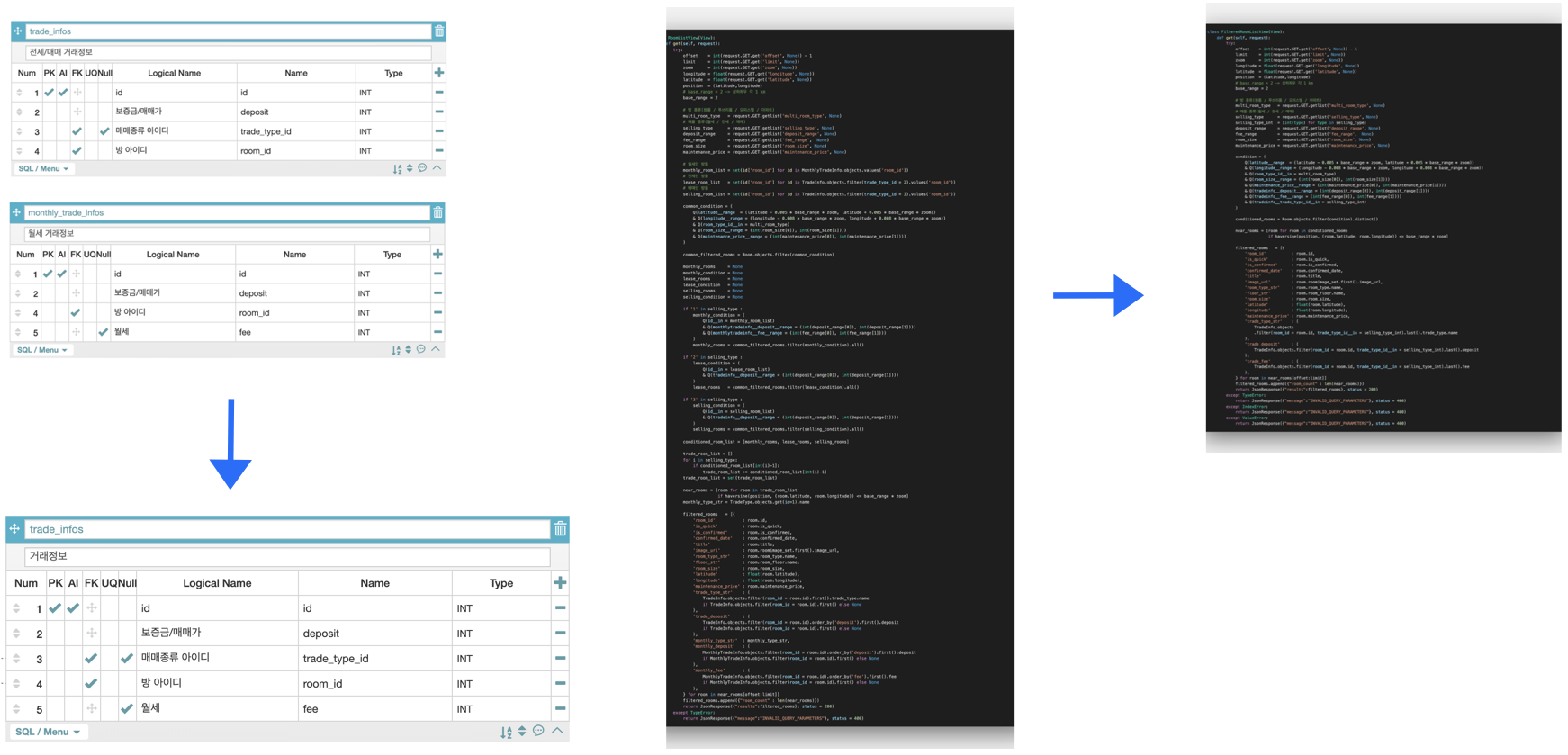
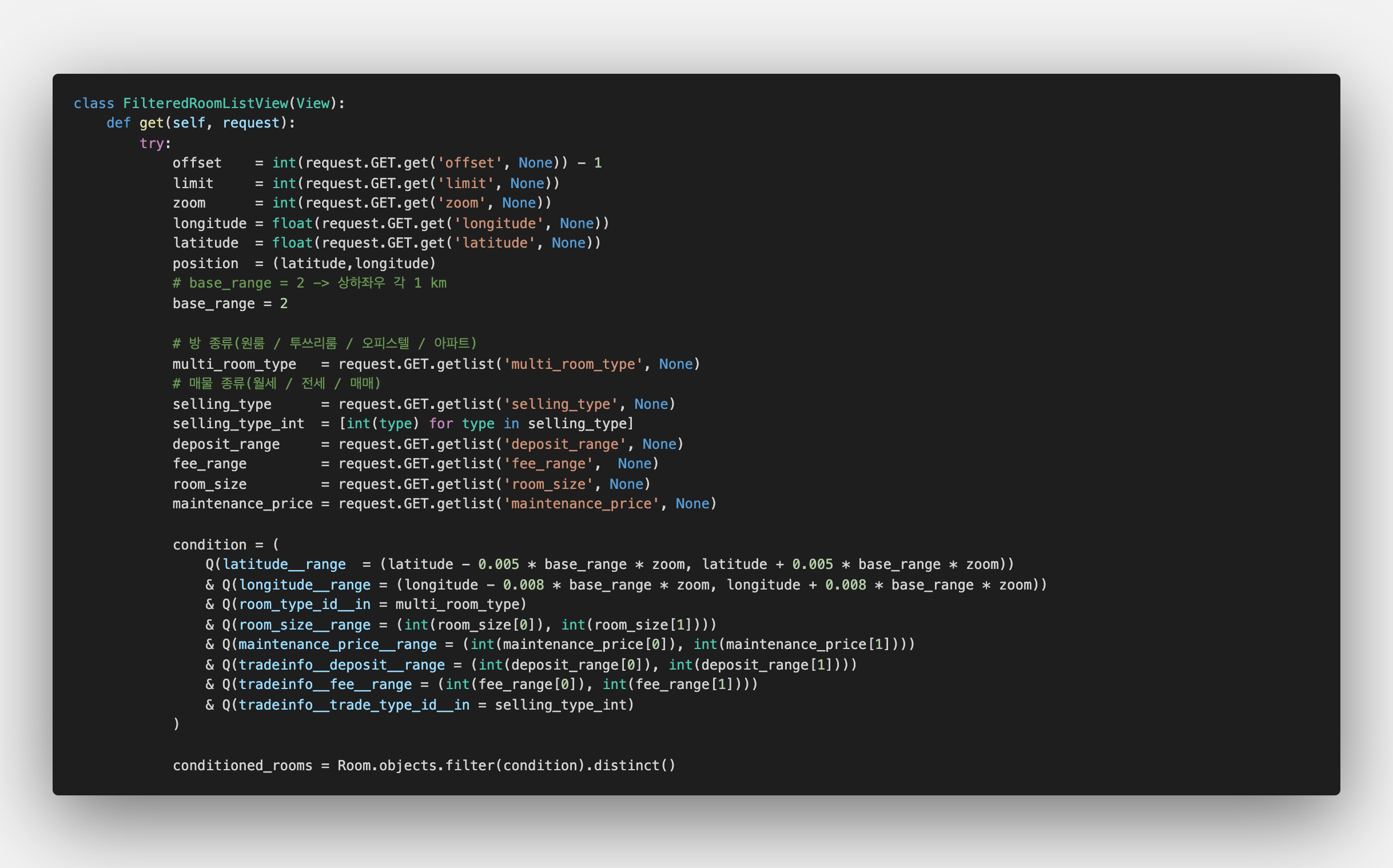
2) 필터링된 방 리스트 뷰
필터링된 방 리스트 뷰는 다방의 메인 기능으로 매물 종류, 방 종류, 가격 범위 등의 조건을 걸어 원하는 방을 찾는 기능 입니다. 이 뷰를 작성하면서 느낀점은 데이터 모델링을 할 때 테이블 간의 관계 뿐만 아니라 기능 구현도 신경쓰면서 해야한다는 점이었습니다.
처음에는 방의 거래정보가 담긴 테이블을 보증금만 있는 매매/전세 테이블과 fee까지 있는 월세 테이블로 나눴습니다. 나중에 월세의 정보를 가져오고자 할 때 다른 필터링 없이 바로 테이블에서 가져오면 편할거라는 생각도 있었고, 전세 매매에는 담기지 않는 fee 필드가 모두 null로 들어가 낭비가 될거라는 생각도 있었습니다.
그런데 아래의 이미지의 왼쪽 코드처럼 필터 자체가 너무 복잡하게 구현되었고 이에 따른 필터 속도도 많이 느렸습니다. 안 바꾸고 그대로 사용할 수도 있었지만, 필터링 검색 자체가 다방의 핵심 기능이기 때문에 이 기능에 맞춰서 모델링 구조를 바꾸는게 좋겠다는 판단이 들어 왼쪽처럼 두 개의 테이블을 하나의 테이블로 합쳐서 한 번에 lookup 할 수 있게 바꿨습니다.
그 결과 오른쪽 코드처럼 불필요한 절차들이 줄어 속도가 개선되었습니다.
회고
잘한점
-
1차 프로젝트 때보다 속도에 대해 좀 더 고민했고, 실제로 필터링, 좌표 검색 부분에서 개선을 했습니다. 이전에는
prefetch_related같은 부분에 신경을 썼다면 이번에는 로직 구조 자체에서 효율성을 추구할 수 있는 부분을 더 고민했습니다. -
ERD에 따른 모델 작성을 먼저 다 해두고, 데이터베이스 업로더를 처음에 잘 구축해둬서 DB 때문에 문제를 겪는 일이 거의 없었습니다.
-
EC2에 서버를 일찍 올려두고, master 브랜치를 계속 업데이트해가며 진행해서 프론트에서 서버 때문에 문제를 겪는 일을 적게 했습니다.
-
현실적인 대안을 찾으려고 노력했습니다. 프론트에서 사용하는 지도 API가 제공하는 기능에 동 단위 등 지역 별로 클러스터를 묶을 수 있는 기능이 없었고, 이 때문에 다방처럼 미리 DB에 동, 구, 시 단위로 만들어 프론트에 API를 제공하는 방식을 사용할 수 없었습니다. 지도 API에서는 지도가 움직일 때마다 주변에 있는 방들을 묶어주는 방식으로 클러스터를 생성해서, 미리 데이터를 만들어 놓을 수가 없었거든요. 그렇다고 그때 그때 생긴 클러스터에서 몇십 몇백개의 방 아이디를 POST로 Request body에 받아서 뿌려주자니, 방 리스트를 조회하는 뷰에 GET을 안쓰는게 마땅치 않았습니다.
그래서 타협한게 프론트에서 클러스터의 최소 수준을 방 10개 전후로 조절하고, 이를 쿼리에 담아 getlist 형식으로 받기로 했습니다. 최선의 방법인지는 모르겠지만 어느 정도의 타협을 찾으려고 노력했습니다.
아쉬운점
-
유닛테스트를 처음 진행해봐서 시간을 많이 쓰게 되었고, 이 때문에 1차 프로젝트에 비해 많은 기능을 구현하지 못했습니다. 처음 2차 프로젝트를 시작했을 때는 1차때보다 더 익숙해졌으니 더 많은 기능을 구현해볼 수 있겠구나 싶었는데, 유닛테스트라는 시간의 장벽을 마주하면서 현실은 다르다는걸 느꼈습니다. 그럼에도 불구하고 유닛테스트를 하면서 좀 더 잘짜인 코드를 만들 수 있었습니다.
-
구현한 기능을 프론트에서 다 보여주지 못해서 아쉬웠습니다. 백엔드에서는 유닛테스트를 도입하고, 프론트도 2차때부터 리덕스라는 신문물을 접하면서 기능 구현 속도가 생각보다 빠르지 못했습니다. 그래서 구현한 기능을 프론트에서 보여주지 못하는 경우가 생겼습니다. 시간을 더 가지고 기능을 완성하기로 했지만, 아무래도 프론트에 의존해야하는 부분이 많다는걸 깨닫고 조금이라도 프론트 부분을 공부해서 목업으로라도 만들 수 있는 실력을 갖추면 좋겠다고 생각했습니다.
-
제가 진행하지 않은 SMS 보내기 기능, 페이스북 로그인 등의 코드에 대해 관심을 가지지 못했습니다. 맡은 기능의 구현에 집중하다보니 다른 분야(?)의 코드는 잘 확인하지 못했습니다. 시간을 두고 올라온 코드를 공부해야겠습니다.
이후
이제 위워크 안에서의 자리가 정해진 위코드 생활은 이번 주말로 끝이 납니다. 1, 2차 프로젝트를 하면서 많이 성장했다는걸 느끼고, 이를 토대로 기업에 나가서도 잘해야겠죠! 브랜디에서는 장고가 아닌 플라스크를 사용한다고 해서 미리 책이라도 몇자 읽고 가야겠습니다.
다들 화이팅!

잘 보앗 읍니다 ^^