- 이번 글은 'Django http & 크롤링 기초 _ 네이버 블로그 리스트 긁어오기' 에서 진행한 크롤링 데이터를 내가 원하는 곳에 CSV로 저장하고, 또 그걸 읽어서 HTTP로 응답하는 법을 다룹니다.
전체 완성 코드는 블로그 맨 아래에 두고, 필요한 부분만 위로 가져와서 설명하려고 합니다. CSV 읽기/쓰기 코드는 search_list/views.py에 작성했습니다. 데이터를 불러올 때 바로 저장하고, HTTP에 응답할 때 바로 가져다쓰려고요!
CSV 파일 쓰기
먼저 CSV를 다루기 위해 CSV를 임포트 해와야합니다. 이제 우리는 CSV를 요리할 수 있는 능력을 갖추게 되었습니다.
# csv 저장용 임포트
import csv
앞서 불러온 네이버 블로그 크롤링 데이터를 이제 CSV에 저장해보겠습니다. 저장은 with open 방식을
사용했습니다. 다른 방식도 있는데, 그 방식을 사용하면 파일을 저장하기 위해 open하고, 또 close 하는 과정을 거쳐야해서 좀 더 편리한 방식을 선택했습니다.
with open('./csv/blog_lists.csv', mode='w') as blog_lists:with open(<파일명>, <모드 설정>) as 저장할 변수이름: 이렇게 명령어가 시작되며, 우리가 만질 파일을 열어서 특정 변수로 컨트롤 하겠다는 뜻 입니다.
이 메서드로 감싸진 Scope가 한 번 끝나면 파일 저장 프로세스가 완료됩니다. 메서드를 부를 때마다 파일명을 바꾸지 않는 이상 계속 덮어씌우는 작업이 진행되기 때문에 모든 작업은 이 Scope 안에서 진행되어야 합니다. 전 처음에 데이터 리스트를 이 메서드 밖에서 for문으로 돌렸는데, 계속 덮어씌워져서 마지막 데이터만 남더라구요. 제가 경험했으니 여러분은 이런 경험을 피하시면 됩니다. 참고로 파일은 없으면 생성이 되지만, 경로는 없으면 FileNotFoundError가 뜨니 경로에 있는 디렉토리는 먼저 만들어주세요!
각각의 요소를 살펴보자면, <파일명>은 우리가 저장하고자 하는 csv 파일명을 적으면 됩니다. 그런데 파일명만 적으면 우리가 manage.py를 실행하는 메인 폴더에 저장이 됩니다. 이게 싫어서 원하는 곳에 저장하는 방법을 찾아봤는데, 그냥 파일명 앞에 원하는 경로를 추가하면 됐습니다. 생각보다 간편해서 좋더라구요. 근데 생각해보면 당연히 저렇게 하면 되는 것 같기도...
<모드 설정>에 들어갈 모드들은 아래와 같습니다.
<조누스의 걸음마 개발 로그> 퍼옴
mode 작성할 때, r(읽기), w(쓰기), a(추가하기) 세가지 중 하나와, t(텍스트), b(바이너리) 둘중 하나와 반드시 결합해야 하며, 나머지는 optional하게 사용 가능하다.
mode : 파일이 열리는 모드
‘r’: 읽기 용으로 열림(기본값)
‘w’: 쓰기 위해 열기, 파일을 먼저 자른다.
‘x’: 베타적 생성을 위해 열리고, 이미 존재하는 경우 실패
‘a’: 쓰기를 위해 열려 있고, 파일의 끝에 추가하는 경우 추가한다.
‘b’: 2진 모드(바이너리 모드)
‘t’: 텍스트 모드(기본값)
‘+’: 업데이트(읽기 및 쓰기)를 위한 디스크 파일 열기
‘U’: 유니버설 개행 모드(사용되지 않음)
csv.writer(blog_lists)는 CSV 작성기로 열어놓은 파일을 컨트롤하겠다는 의미고, .writerow()를 통해 한줄 한줄 데이터를 저장하기 시작합니다.
blog_writer = csv.writer(blog_lists)
blog_writer.writerow(["post_title", "posting_date","blog_url"]) # 필드명을 만들고 싶어서 추가
for list in zip(post_title, posting_date, blog_url):
SearchList(
post_title=list[0].text,
posting_date=list[1].text,
blog_url=list[2].text,
).save()
blog_writer.writerow([list[0].text, list[1].text, list[2].text])
return HttpResponse(status=200)데이터의 한줄 구분은 크롤링 데이터와 동일하게 하고 싶어서, DB에 저장하는 for문 아래에서 한줄씩 CSV를 쓰도록 했습니다. for문 전에 따로 한줄을 먼저 써놓은 이유는 그냥 제가 시트에서 필드명을 출력하고 싶어서 입니다. 필드명을 따로 안넣으면 필드명 자리에도 블로그 데이터가 들어가서 보기싫더라고요~
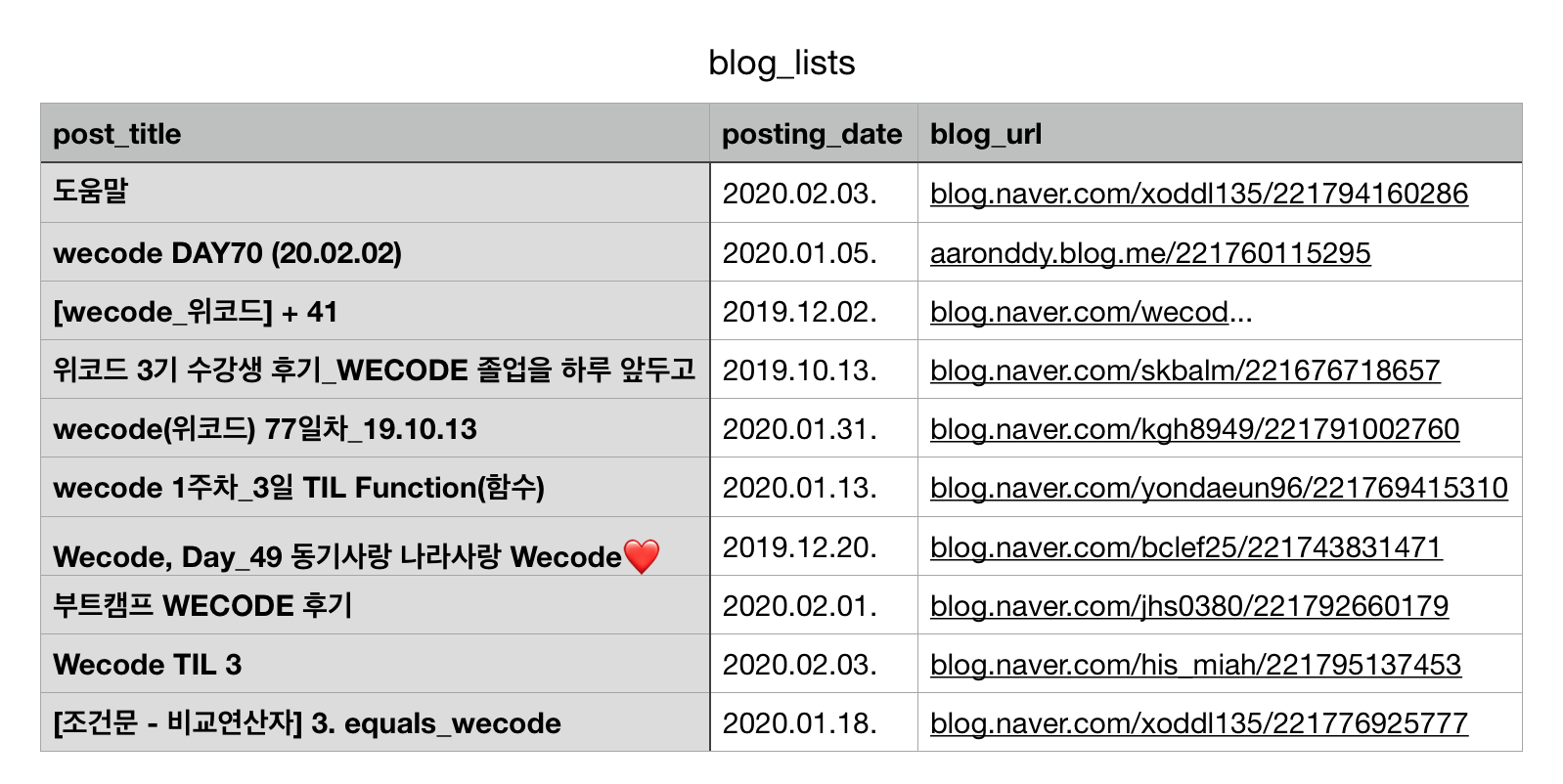
CSV 파일 읽기
이제 방금 만든 CSV 파일을 읽어서 HTTP요청에 응답해보겠습니다. 크게 달라지는건 없고, 모드를 w에서 r 읽기 모드로 바꾸면 됩니다. 그리고 writer에서 reader로 바꿔서 파일을 읽어주면 됩니다.
def get(self, request):
result = []
with open('./csv/blog_lists.csv', mode='r') as blog_lists:
reader = csv.reader(blog_lists)
for list in reader:
result.append(list)
return JsonResponse({'search list' : result}, status=200)
reader라는 변수에 저장된 데이터는 <_csv.reader object at 0x10ae516d0>와 같은 객체로 json으로 변환할 수 없는 형태 입니다. 그래서 우리는 result라는 빈 리스트를 만들고, 여기에 각 데이터 한줄 한줄을 넣어서 json response로 보내줍니다.
이렇게 완성된 후 데이터를 요청하면 아래와 같이 짜잔하고 성공합니다. 끝! 수고하셨습니다.
$ http -v http://localhost:8000/search-list/query
GET /search-list/query HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Host: localhost:8000
User-Agent: HTTPie/2.0.0
HTTP/1.1 200 OK
Content-Length: 1161
Content-Type: application/json
Date: Wed, 12 Feb 2020 01:41:05 GMT
Server: WSGIServer/0.2 CPython/3.8.1
X-Content-Type-Options: nosniff
X-Frame-Options: DENY
{
"search list": [
[
"post_title",
"posting_date",
"blog_url"
],
[
"도움말",
"2020.02.03. ",
"blog.naver.com/xoddl135/221794160286"
],
[
"wecode DAY70 (20.02.02)",
"2020.01.05. ",
"aaronddy.blog.me/221760115295"
],
[
"[wecode_위코드] + 41",
"2019.12.02. ",
"blog.naver.com/wecod..."
],
[
"위코드 3기 수강생 후기_WECODE 졸업을 하루 앞두고",
"2019.10.13. ",
"blog.naver.com/skbalm/221676718657"
],
[
"wecode(위코드) 77일차_19.10.13",
"2020.01.31. ",
"blog.naver.com/kgh8949/221791002760"
],
[
"wecode 1주차_3일 TIL Function(함수)",
"2020.01.13. ",
"blog.naver.com/yondaeun96/221769415310"
],
[
"Wecode, Day_49 동기사랑 나라사랑 Wecode❤️",
"2019.12.20. ",
"blog.naver.com/bclef25/221743831471"
],
[
"부트캠프 WECODE 후기",
"2020.02.01. ",
"blog.naver.com/jhs0380/221792660179"
],
[
"Wecode TIL 3",
"2020.02.03. ",
"blog.naver.com/his_miah/221795137453"
],
[
"[조건문 - 비교연산자] 3. equals_wecode",
"2020.01.18. ",
"blog.naver.com/xoddl135/221776925777"
]
]
}
참고자료
- Reading and Writing CSV Files in Python - real python
- python 크롤링 : csv 파일 만들기 - commune
- 파이썬 - CSV 파일 만들기 - 조누스의 걸음마 개발 로그
전체 코드
# 뷰 작성용 임포트
import json
from .models import SearchList
from django.views import View
from django.http import HttpResponse, JsonResponse
# 크롤링용 임포트
import requests
from bs4 import BeautifulSoup
# csv 저장용 임포트
import csv
# 뷰 작성 시작
class SearchListView(View):
def post(self, request):
SearchList.objects.all().delete()
data = json.loads(request.body)
# HTTP GET Request
req = requests.get(
f'https://search.naver.com/search.naver?where=post&sm=stb_jum&query={data["query"]}')
# HTML 소스 가져오기
html = req.text
## html을 python 객체로 파싱
soup = BeautifulSoup(html,'html.parser')
post_title = soup.select(
' dl > dt > a'
)
posting_date = soup.select(
'dl > dd.txt_inline'
)
blog_url = soup.select(
'dl > dd.txt_block > span > a.url'
)
with open('./csv/blog_lists.csv', mode='w') as blog_lists:
blog_writer = csv.writer(blog_lists)
blog_writer.writerow(["post_title", "posting_date","blog_url"])
for list in zip(post_title, posting_date, blog_url):
SearchList(
post_title=list[0].text,
posting_date=list[1].text,
blog_url=list[2].text,
).save()
blog_writer.writerow([list[0].text, list[1].text, list[2].text])
return HttpResponse(status=200)
def get(self, request):
result = []
with open('./csv/blog_lists.csv', mode='r') as blog_lists:
reader = csv.reader(blog_lists)
for list in reader:
result.append(list)
return JsonResponse({'search list' : result}, status=200)
