이전에 배워본 Django http와 크롤링을 동시에 사용해보고자 합니다.
이번 작업의 사전 파트는 아래 글들을 살펴보시면 됩니다.
- Django - 회원가입/로그인 앱(app) 생성 - Django 프로젝트 생성, http 사용
- 파이썬 - 빌보드 차트 크롤링하기 - BeautifulSoup으로 크롤링
먼저 완성된 프로젝트의 트리구조를 보면 아래와 같습니다. 전 blog_search_list_scrap이라는 이름으로 프로젝트를 생성했습니다.
blog_search_list_scrap
├── blog_search_list_scrap
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── db.sqlite3
├── manage.py
└── search_list
├── __init__.py
├── admin.py
├── apps.py
├── migrations
├── models.py
├── tests.py
├── urls.py
└── views.py
모델
먼저 모델을 만들어보겠습니다. 제가 크롤링하고 싶은 정보는 블로그 제목과 포스팅 날짜, 블로그 url입니다.
각각의 정보를 post_title, posting_date, blog_url로 정의하고 CharField 필드값을 주었습니다.
# search_list.models.py
from django.db import models
class SearchList(models.Model):
post_title = models.CharField(max_length = 200)
posting_date = models.CharField(max_length = 100)
blog_url = models.CharField(max_length = 500)
created_at = models.DateTimeField(auto_now_add = True)
updated_at = models.DateTimeField(auto_now = True)
class Meta:
db_table = 'search_lists'뷰
이번 블로그에서는 뷰 작성이 제일 중요합니다. 먼저 기본적으로 뷰를 작성할 때 쓰이는 모듈들과 크롤링에 사용하는 모듈들을 구분해서 임포트했습니다.
# 뷰 작성용 임포트
import json
from .models import SearchList
from django.views import View
from django.http import HttpResponse, JsonResponse
# 크롤링용 임포트
import requests
from bs4 import BeautifulSoup
post 요청이 들어오면, 먼저 기존에 저장되어있던 SearchList 데이터를 지웠습니다. id 값까지 리셋되진 않지만 일단 요청이 들어온 검색어의 검색결과만 반환하고 싶었습니다.
# 뷰 작성 시작
class SearchListView(View):
def post(self, request):
SearchList.objects.all().delete() # 기존 SearchList 데이터 삭제
그리고 난 후, requests를 통해 블로그 검색 페이지를 불러올 때는, post 요청때 던진 query 정보가 검색 url에 들어가도록 f-strings를 사용했습니다. 처음에 저 HTML 소스를 가져올 때 req.text를 req.txt로 써놓고 계속 안된다고 시간 버린거 생각하면 정말... 정말 한글자 한글자 꼼꼼히 잘 봐야합니다.
data = json.loads(request.body)
# HTTP GET Request
req = requests.get( # post요청때 던진 query 정보를 담음
f'https://search.naver.com/search.naver?where=post&sm=stb_jum&query={data["query"]}')
# HTML 소스 가져오기
html = req.text
## html을 python 객체로 파싱
soup = BeautifulSoup(html,'html.parser')
이제 블로그 검색 페이지에서 selector를 이용해 정보를 가져올 차례입니다.
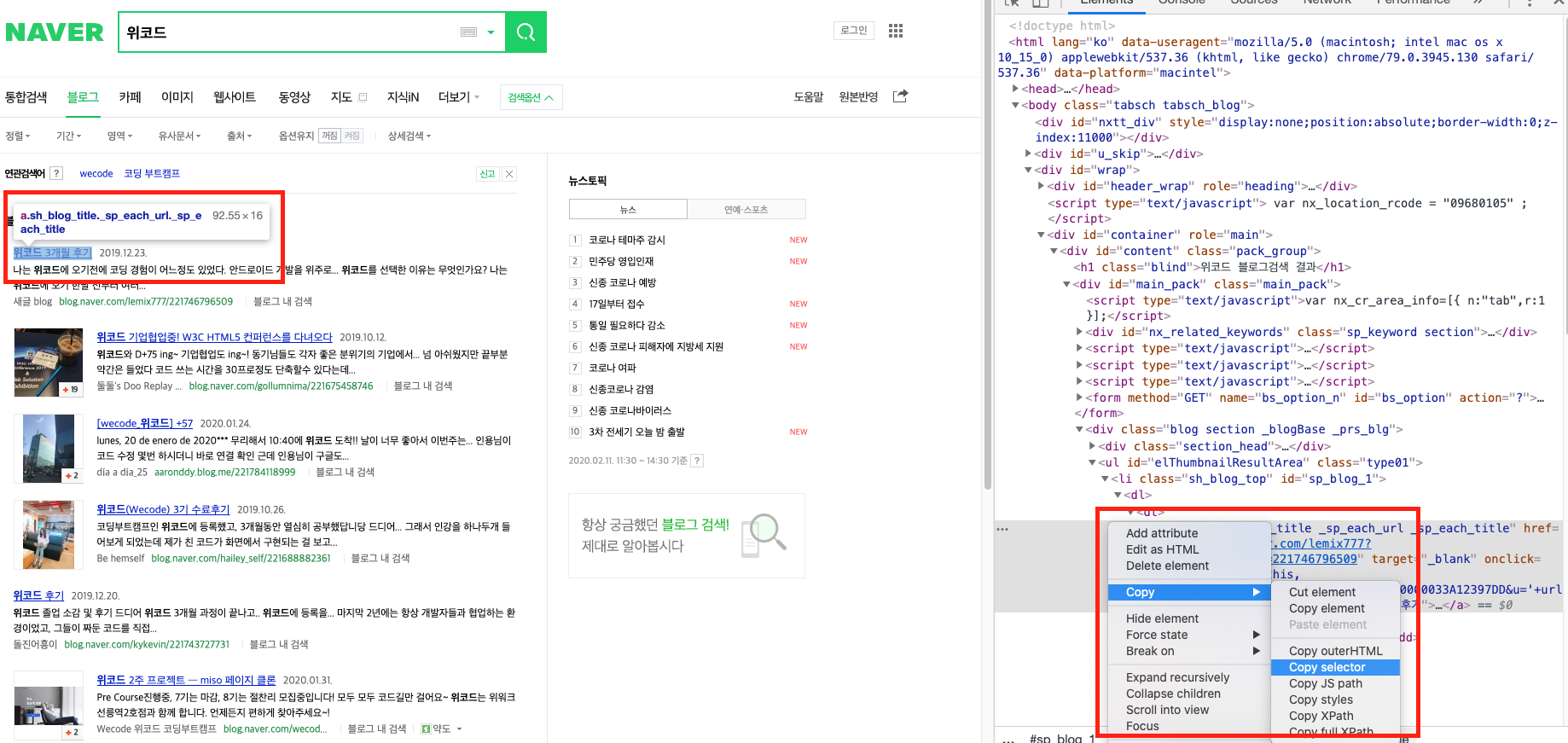
위의 selector를 복사해오면 #sp_blog_1 > dl > dt > a가 나오는데, 이대로 적용하면 첫 번째 블로그만 나옵니다. 앞의 #sp_blog_1을 지우면 첫 페이지 10개의 블로그가 모두 수집되게 됩니다. 해당 selector 들을 타고 들어와서 만나게 될 대상을 추적하면서 결과를 상상해보면 조금 쉬워집니다.
## html을 python 객체로 파싱
soup = BeautifulSoup(html,'html.parser')
post_title = soup.select(
'dl > dt > a.sh_blog_title._sp_each_url._sp_each_title'
)
posting_date = soup.select(
'dl > dd.txt_inline'
)
blog_url = soup.select(
'dl > dd.txt_block > span > a.url'
)이렇게 수집된 데이터들을 zip 을 이용해 하나의 리스트로 만들고, for문을 돌면서 요소 하나씩 DB에 저장해줍니다. 그리고 나서 처리가 완료되었다는 status=200을 응답해주면 됩니다.
for item in zip(post_title, posting_date, blog_url):
SearchList(
post_title=item[0].text,
posting_date=item[1].text,
blog_url=item[2].text,
).save()
return HttpResponse(status=200)
다음은 get 요청시 응답해 줄 검색 리스트를 반환해야합니다. 현재까지 저장된(매 post 마다 10개씩만 저장) 딕셔너리형 객체를 리스트로 변환해 응답해주면 됩니다. 여기서 SearchList.objects.all()을 쓰면 객체가 반환되어 Json 이 읽을 수 없는 형태가 되니 꼭 values()를 사용해주세요!
def get(self, request):
return JsonResponse({'search list' : list(SearchList.objects.values())}, status=200)완성된 뷰 코드는 아래와 같습니다.
# 뷰 작성용 임포트
import json
from .models import SearchList
from django.views import View
from django.http import HttpResponse, JsonResponse
# 크롤링용 임포트
import requests
from bs4 import BeautifulSoup
# 뷰 작성 시작
class SearchListView(View):
def post(self, request):
SearchList.objects.all().delete()
data = json.loads(request.body)
# HTTP GET Request
req = requests.get(
f'https://search.naver.com/search.naver?where=post&sm=stb_jum&query={data["query"]}')
# HTML 소스 가져오기
html = req.text
## html을 python 객체로 파싱
soup = BeautifulSoup(html,'html.parser')
post_title = soup.select(
'dl > dt > a.sh_blog_title._sp_each_url._sp_each_title'
)
posting_date = soup.select(
'dl > dd.txt_inline'
)
blog_url = soup.select(
'dl > dd.txt_block > span > a.url'
)
for item in zip(post_title, posting_date, blog_url):
SearchList(
post_title=item[0].text,
posting_date=item[1].text,
blog_url=item[2].text,
).save()
return HttpResponse(status=200)
def get(self, request):
return JsonResponse({'search list' : list(SearchList.objects.values())}, status=200)경로
경로는 생략!
실행
이제 만든 프로그램에 http 요청을 보내보겠습니다. 먼저 코로나바이러스라는 쿼리를 넣어 post 요청을 보냅니다. 그러면 아래와 같이 저장에 성공합니다.
$ http -v http://localhost:8000/search-list/query query=코로나바이러스
POST /search-list/query HTTP/1.1
Accept: application/json, */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Content-Length: 55
Content-Type: application/json
Host: localhost:8000
User-Agent: HTTPie/2.0.0
{
"query": "코로나바이러스"
}
HTTP/1.1 200 OK
Content-Length: 0
Content-Type: text/html; charset=utf-8
Date: Tue, 11 Feb 2020 09:33:46 GMT
Server: WSGIServer/0.2 CPython/3.8.1
X-Content-Type-Options: nosniff
X-Frame-Options: DENY
이제 get 요청으로 저장된 데이터를 요청하면 완료! 참 쉽죠? 하하
$ http -v http://localhost:8000/search-list/query
GET /search-list/query HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Host: localhost:8000
User-Agent: HTTPie/2.0.0
HTTP/1.1 200 OK
Content-Length: 3073
Content-Type: application/json
Date: Tue, 11 Feb 2020 09:34:42 GMT
Server: WSGIServer/0.2 CPython/3.8.1
X-Content-Type-Options: nosniff
X-Frame-Options: DENY
{
"search list": [
{
"blog_url": "elanfriends.blog.me/...",
"created_at": "2020-02-11T09:33:46.952Z",
"id": 52,
"post_title": "도움말",
"posting_date": "4일 전 ",
"updated_at": "2020-02-11T09:33:46.952Z"
},
{
"blog_url": "blog.naver.com/ipudo/221795011257",
"created_at": "2020-02-11T09:33:46.962Z",
"id": 53,
"post_title": "코로나 바이러스 막는 식이요법",
"posting_date": "2020.02.03. ",
"updated_at": "2020-02-11T09:33:46.962Z"
},
{
"blog_url": "blog.naver.com/comma628/221804352449",
"created_at": "2020-02-11T09:33:46.963Z",
"id": 54,
"post_title": "우한폐렴(신종 코로나바이러스)이 위험한 이유",
"posting_date": "8시간 전 ",
"updated_at": "2020-02-11T09:33:46.964Z"
},
......(생략)
]
}
응용해서 사용하고 싶은데 위 코드 전체 복사해서 실행하면
File "/workspace/Django/search_list.models.py", line 28
soup = BeautifulSoup(html,'html.parser')
^
TabError: inconsistent use of tabs and spaces in indentation
오류가나는데 실행은 어떻게 해야되나요 ?