이번에는 파이썬을 활용해 빌보드 차트의 차트 정보를 크롤링(스크래핑) 해보려고 합니다.
가상환경 생성 및 세팅
스크래핑을 하기 위해서는 파이썬과 requests, BeautifulSoup 라이브러리가 필요합니다. 다른 프로젝트와 구분하기 위해, 크롤링을 위한 새로운 가상환경을 설정하고 그 안에 위의 프로그램들을 세팅하겠습니다.
저 같은 경우는 미니콘다를 사용해 가상환경을 생성했습니다. 중간에 나오는 질문에 'y'를 택하면 설정이 완료됩니다.
$ conda create -n scrap python=3.8 # 'scrap'이라는 python3.7 환경의 가상환경 생성
~~~
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate scrap
#
# To deactivate an active environment, use
#
# $ conda deactivate이제 가상환경에 들어가 필요한 라이브러리들을 설치하겠습니다. 참고로 bs4는 BeautifulSoup4의 약자입니다. 아래와 같은 메시지가 뜨면 설치 완료!
$ conda activate scrap # scrap 가상환경에 진입
$ (scrap) pip install bs4 requests # scrap 안에서 pip를 활용해 bs4와 requests 설치
~~~
Successfully installed beautifulsoup4-4.8.2 bs4-0.0.1 chardet-3.0.4 idna-2.8 requests-2.22.0 soupsieve-1.9.5 urllib3-1.25.8
그럼 이제 크롤링 코드를 본격적으로 작성해볼까요? 이번에 크롤링을 해 볼 대상은 빌보드 차트 Hot 100 입니다.
requests와 BeautifulSoup을 활용해 정보 가져오기
먼저 크롤링에 사용할 라이브러리 모듈들을 임포트 해줍니다. requests 라이브러리는 HTTP 요청을 해주는 역할을 하며, BeautifulSoup는 HTML로부터 우리가 원하는 데이터를 뽑아낼 수 있게 도와줍니다.
import requests
from bs4 import BeautifulSoup`requests`는 `html`정보를 불러온 후 `req.text`를 통해 파이썬이 이해할 수 있도록 문자열(str) 객체를 반환합니다. 하지만 이 문자열 객체로는 의미있는 정보를 추출하기 어렵습니다.
## HTTP GET Request
req = requests.get('https://www.billboard.com/charts/hot-100')
## HTML 소스 가져오기
html = req.text
이 점을 보완하고자 우리는 `BeautifulSoup`을 이용합니다. `BeautifulSoup`는 `requests`가 변환한 문자열 정보를 파이썬이 이해할 수 있는 객체 구조로 변환(Parsing, 파싱) 해줍니다. 이 덕분에 우리는 `html`로부터 의미있는 정보를 뽑아낼 수 있게 됩니다.
## BeautifulSoup으로 html을 python 객체로 파싱. 두 번째 인자에는 어떤 parser를 이용할지 명시함
soup = BeautifulSoup(html, 'html.parser')
파싱된 정보에서 우리가 원하는 정보를 뽑기 위해서는 `soup.select()` 메서드를 사용합니다. 이 메서드는 CSS selector를 통해 html 요소들을 찾아냅니다. 아래의 `select` 안에 들어간 요소는 순위의 CSS selector 인데요, 실제로 빌보드 차트에 가서 찾아보겠습니다.
rank = soup.select(
'li > button > span.chart-element__rank.flex--column.flex--xy-center.flex--no-shrink > span.chart-element__rank__number'
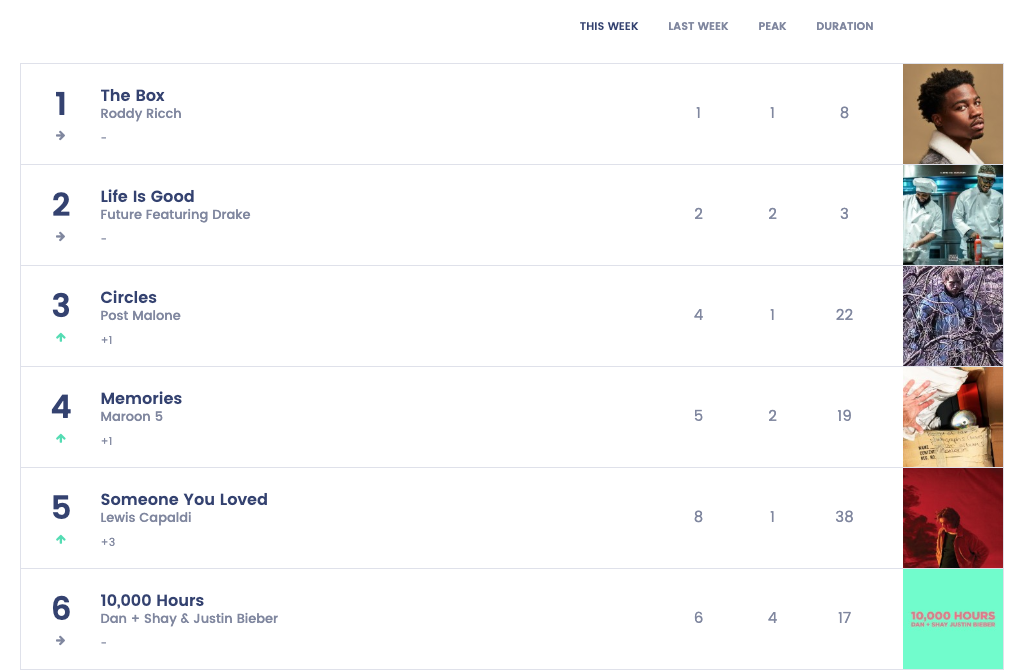
)먼저 브라우저(저는 크롬)의 개발자 도구를 엽니다. 맥의 경우 `f12`버튼으로 열 수 있습니다. 그리고 1번에 표시된 이미지를 클릭합니다. 1번의 기능으로 홈페이지 내 특정 부분을 클릭하면, 해당 부분의 `elements`소스를 볼 수 있습니다. 그리고 2번과 같이 크롤링을 하고 싶은 대상을 클릭합니다. 이번에는 순위와 노래 제목, 가수를 크롤링 할 예정으로 일단 순위를 선택했습니다. 그리고 나서 3번의 소스로 가서 다음의 작업을 진행합니다.
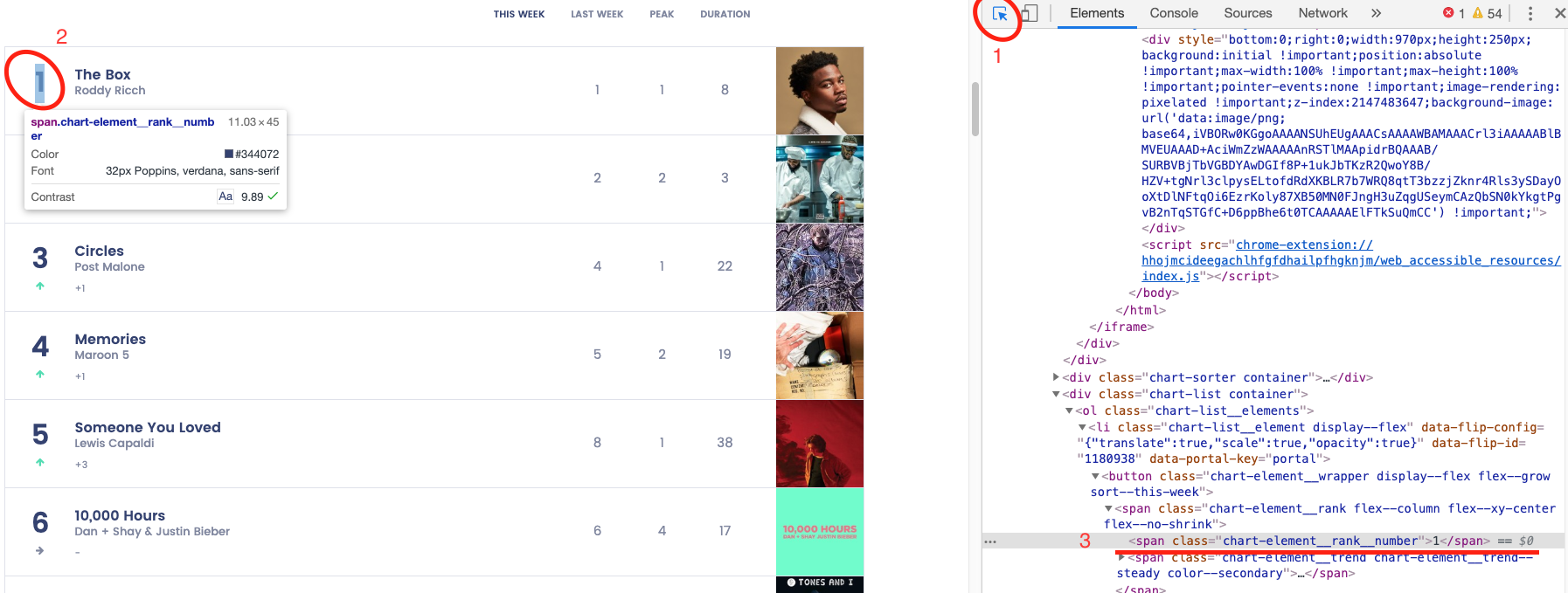
해당 소스 위에서 오른쪽 클릭을 하면 CSS selector를 복사할 수 있는 메뉴가 나타납니다. 복사를 진행합니다.
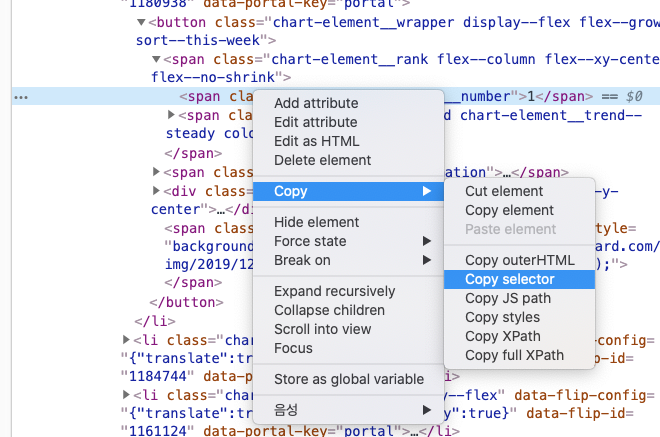
복사한 내용은 아래와 같습니다. 근데 뭔가 다릅니다.
# 복사해 온 내용
#charts > div > div.chart-list.container > ol > li:nth-child(1) > button > span.chart-element__rank.flex--column.flex--xy-center.flex--no-shrink > span.chart-element__rank__number
# 코드에 들어갈 내용
'li > button > span.chart-element__rank.flex--column.flex--xy-center.flex--no-shrink > span.chart-element__rank__number'일단 `li` 앞 부분은 우리가 가져오고 싶은 요소에 영향을 미치지 않으므로 지웁니다. 그래도 `li:nth-child(1)`는 실제로 들어갈 내용인 `li`랑은 다른데요. 이대로 코드를 작성하면 `rank`는 아래 한줄의 html 코드만 불러옵니다. 하지만 우리가 원하는건 1~100위의 전체 리스트인데요, 이러기 위해서는 `:nth-child(1)`처럼 제한을 두지 말고 리스트 전체를 불러와야 합니다. 그래서 나머지를 지우고 `li`만 남깁니다.
## li:nth-child(1)로 불러왔을 때
$ (scrap) python bills.py
[<span class="chart-element__rank__number">1</span>]`li`만 남기면 이렇게 전체 리스트가 불러와집니다.
## li로 불러왔을 때
$ (scrap) python bills.py
[<span class="chart-element__rank__number">1</span>, <span class="chart-element__rank__number">2</span>, <span class="chart-element__rank__number">3</span>, <span class="chart-element__rank__number">4</span>,......]
이제 우리가 결과적으로 뽑고 싶은 순위, 제목, 가수 리스트를 뽑아봅시다. rank처럼 song과 singer도 select를 통해 리스트 형태로 데이터를 뽑아왔다고 가정하고, 다음과 같이 music_chart 배열에 정보를 저장해줍니다.
.text는 soup의 메서드인데, html형식으로 담긴 데이터에서 텍스트 정보만 빼와주는 역할을 합니다. 여기서 텍스트는 순위, 노래 제목, 가수이름을 의미합니다.
music_chart = []
for item in zip(rank, song, singer):
music_chart.append(
{
'rank' : item[0].text,
'song' : item[1].text,
'singer': item[2].text,
}
)
for i in music_chart:
print(i)참고로 zip은 동일한 개수로 이루어진 자료형을 묶어 주는 역할을 하는 함수입니다. 지금은 순위와 노래, 가수가 모두 동일한 개수로 이루어져서 zip을 쓰면 되지만, 만약 개수가 다르다면 zip_longest을 사용하면 됩니다. 이걸 쓰면 디폴트 값을 주어 숫자를 맞출 수 있습니다.
zip은 이렇게 쓰입니다.
$ list(zip([1, 2, 3], [4, 5, 6]))
[(1, 4), (2, 5), (3, 6)]이렇게 완성된 코드로 크롤링을 실행하면 아래와 같이 차트 리스트가 출력됩니다.
python bill.py
{'rank': '1', 'song': 'The Box', 'singer': 'Roddy Ricch'}
{'rank': '2', 'song': 'Life Is Good', 'singer': 'Future Featuring Drake'}
{'rank': '3', 'song': 'Circles', 'singer': 'Post Malone'}
{'rank': '4', 'song': 'Memories', 'singer': 'Maroon 5'}
{'rank': '5', 'song': 'Someone You Loved', 'singer': 'Lewis Capaldi'}
.....
크롤링 성공!
전체 코드는 아래에 달아두겠습니다.
출력된 내용을 DB에 담는 방법은 다음 포스팅에서 작성하겠습니다.
참고
- requests와 BeautifulSoup으로 웹 크롤러 만들기
- 크롤링 세션(by 지훈님)
- beautiful soup document kor
전체 코드
import requests
from bs4 import BeautifulSoup
from sqlalchemy import *
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship, sessionmaker
from sqlalchemy.sql import *
engine = create_engine('sqlite:///music.db')
Base = declarative_base()
class Music(Base):
__tablename__ = 'musics'
id = Column(Integer, primary_key=True)
rank = Column(String(50))
song = Column(String(50))
singer = Column(String(50))
Music.__table__.create(bind=engine, checkfirst=True)
Session = sessionmaker(bind=engine)
session = Session()
req = requests.get('https://www.billboard.com/charts/hot-100')
html = req.text
soup = BeautifulSoup(html, 'html.parser')
rank = soup.select(
'li > button > span.chart-element__rank.flex--column.flex--xy-center.flex--no-shrink > span.chart-element__rank__number'
)
song = soup.select(
'li > button > span.chart-element__information > span.chart-element__information__song.text--truncate.color--primary'
)
singer = soup.select(
'li > button > span.chart-element__information > span.chart-element__information__artist.text--truncate.color--secondary'
)
music_chart = []
for item in zip(rank, song, singer):
music_chart.append(
{
'rank' : item[0].text,
'song' : item[1].text,
'singer': item[2].text,
}
)
for i in music_chart:
print(i)
for element in music_chart:
result = Music(rank = element['rank'],
song = element['song'],
singer = element['singer'],
)
session.add(result)
session.commit()
request = session.query(Music).all()
for row in request:
print(row.rank,'|', row.song,'|' ,row.singer)